Blog
LLM Fine-tuning Challenge at NeurIPS


LLM Fine-tuning
NeurIPS 2023 featured a challenge to efficiently fine-tune open-source LLM models on public datasets. We participated in this challenge. If you are considering fine-tuning LLMs, there are some things to consider: Infra, Data, Base Model, Training, Inference and Evaluation. In this blog post, we share some practical considerations.
The challenge
The goal of the challenge is to find out what works and doesn't work when fine-tuning LLM models. To evaluate these models, the benchmarking tool HELM is used. The tasks for a public leaderboard are a wide range of known tasks and the private leaderboard contains holdout tasks. The challenge is set up as follows:
- The base model needs to be from a list of approved open-source models.
- Data needs to be publicly available and human-generated (or by an open source & whitelisted LLM within your time budget).
- The model needs to be fine-tuned within 24 hours on a single GPU (A100 40GB or 4090 24GB).
- Training should be reproducible.
- Inference should take < 2 hours.
For more info here are links to the official website and the starterkit with code.
Our approach
Our data-centric approach revolved around collaboration, experimentation and quick iteration. Collaboration was key as we wanted to share our findings and learn from each other. Therefore we started with setting up infrastructure. Before we started training, we evaluated some base models to find the most suitable ones. We set up a workflow to evaluate and train models, then used this to quickly iterate on our approach. From there iterate... eval... train... eval... train... eval...
Infra
Why start with infra? We want to collaborate, experiment in parallel, share findings and be able to continue from each other's checkpoints. So we need to share data, models and scripts efficiently.
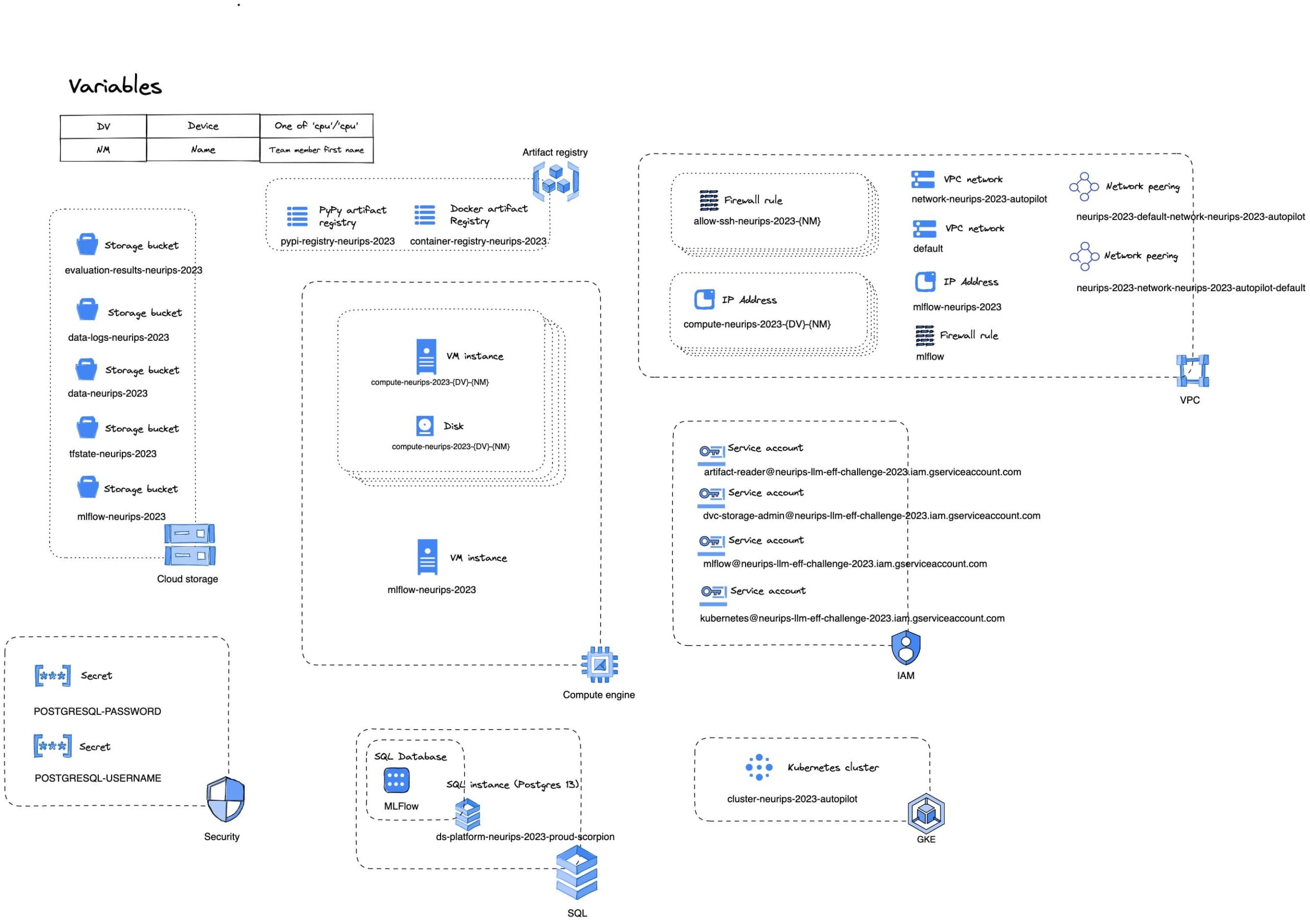
What do we need to collaborate? In short experiment tracking... In detail, we used MLFlow in combination with:
- Data storage and versioning
- Model storage and versioning
- Script versioning
To speed up experimentation, we want to run multiple experiments in parallel and have a quick feedback loop. So we built a Kubernetes cluster, that could run evaluation and training jobs.
GPU availability
The first challenge we faced was GPU availability. To get started we used T4 development machines, but eventually we needed to switch to A100 machines. These are notoriously hard to get. Creating the training job for the Kubernetes cluster helped. The job manager would request a GPU and if it was not available it would wait and automatically try again. But we still needed to test our setup before we could kick off the training job. We found that there was one specific region with decent availability and acceptable latency. So we used that for our A100 development machines.
Workflows
We explained some of the components before. Let's look at how they fit together.
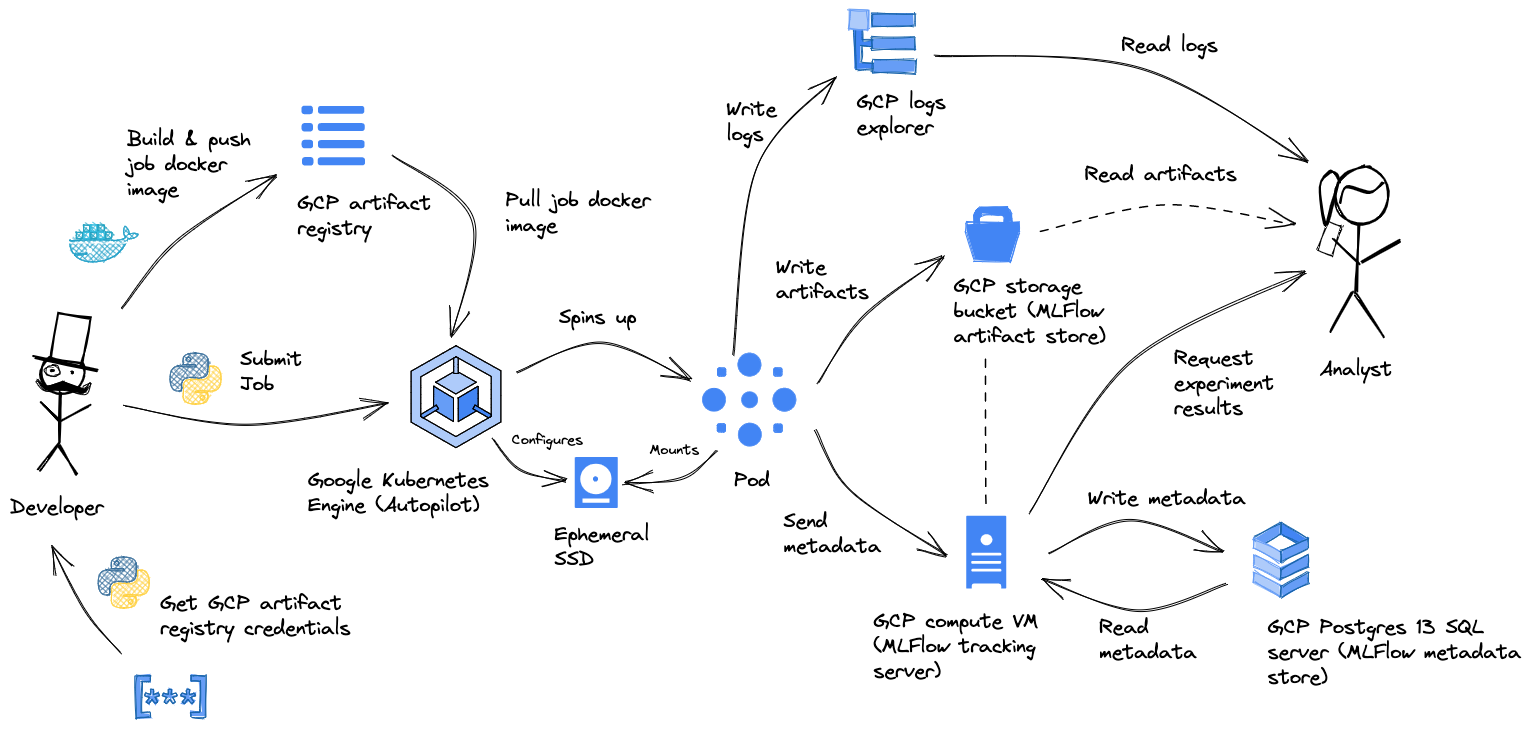
A T4 development machine is used to test quickly with a small model and a small dataset. If successful, the setup is scaled up on an A100 dev machine. Then the experiment is run on the Kubernetes cluster. Results are logged to MLFlow and the model is stored in the model registry. The final evaluation is done on the HELM benchmark. At first on our own cluster, as there was no official public leaderboard for some time. But later when it became available, also on the official leaderboard, to compare with other teams.
Costs
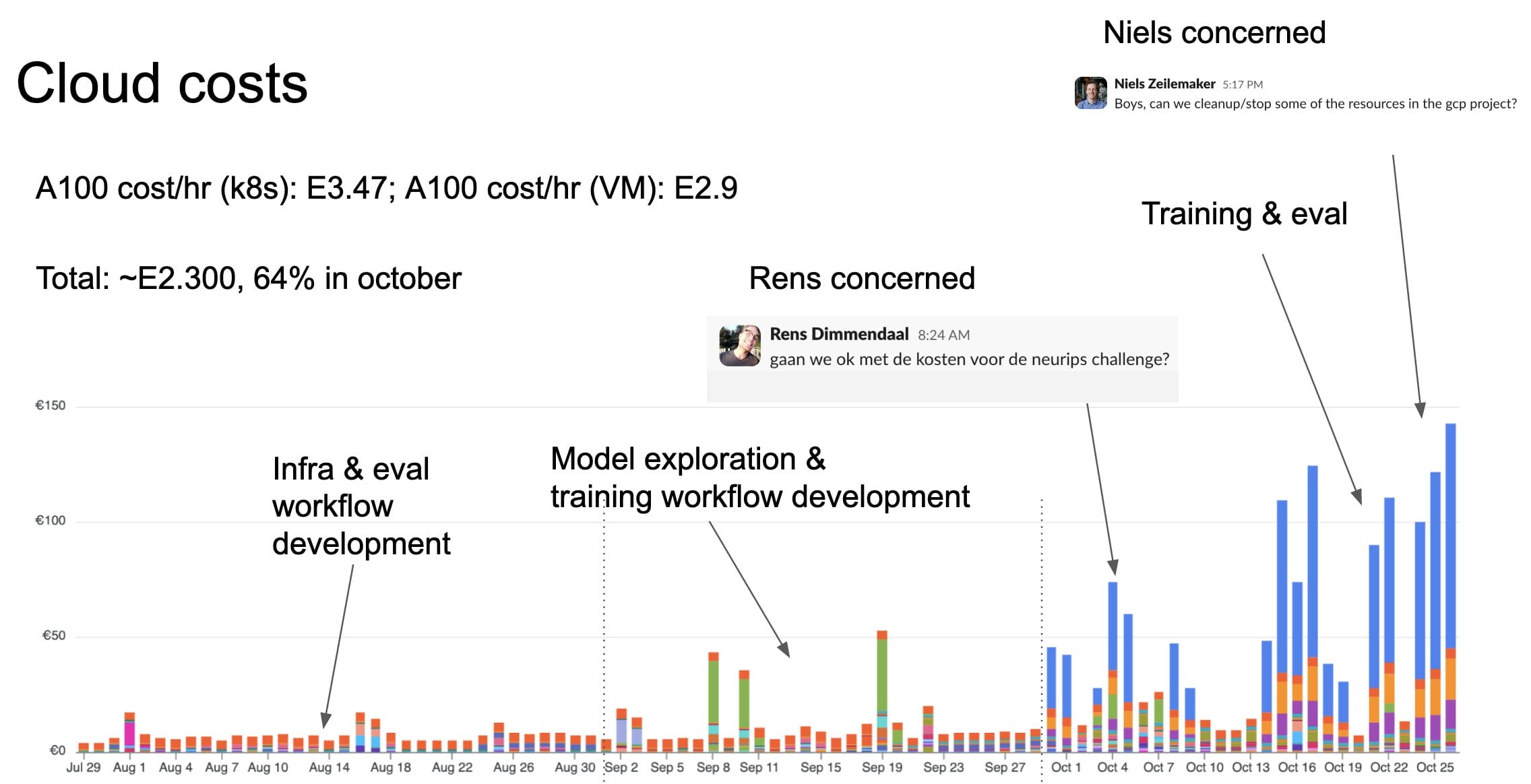
The total costs for this project were less than 2.5k euros. Most of which was spent on A100-enabled Kubernetes pods.
Variable
The largest costs were for the GPU machines. A100s aren't cheap, 3.47 euros/h on k8s and 2.9 euros/h for the compute instances (dev machines). Fortunately, we only needed to pay when we ran experiments.
Fixed
Since we opted for a simple setup of our MLFlow server. The machine was not very expensive (13 euros/month), but was always on. Of course, the backend relied on some storage. Overall storage was not a significant cost, but is something you want to keep an eye on with LLM projects.
Storage
The data versioning was a critical component for our collaboration. A simple yet efficient custom setup for blob storage was used. It enabled us to quickly share the latest curated versions and lineage of data used for experiments.
Data
Data is the most important part of LLM fine-tuning, as it is for any machine learning project. Our key learnings regarding data are:
- Match data to task and balance between tasks
- Quality over quantity
- Format prompts
Datasets
The evaluation is done on HELM tasks. The first hurdle to pass is a subset of the HELM tasks. The holdout tasks will consist of logic reasoning type of multiple-choice Q&A scenarios as well as conversational chat tasks. To match these tasks we used the following datasets:
| Dataset | Source |
|---|---|
| openai/prm800K | https://github.com/openai/prm800k |
| databricks/databricks-dolly-15k | https://huggingface.co/datasets/databricks/databricks-dolly-15k |
| timdettmers/openassistant-guanaco | https://huggingface.co/datasets/timdettmers/openassistant-guanaco |
| duckai/arb | https://github.com/TheDuckAI/arb |
| metaeval/reclor | https://whyu.me/reclor/; https://openreview.net/pdf?id=HJgJtT4tvB |
| mandyyyyii/scibench | https://github.com/mandyyyyii/scibench; https://huggingface.co/datasets/xw27/scibench |
| metaeval/ScienceQA_text_only | https://huggingface.co/datasets/metaeval/ScienceQA_text_only |
| wenhu/TheoremQA | https://github.com/wenhuchen/TheoremQA |
| TigerResearch/tigerbot-kaggle-leetcodesolutions-en-2k | https://huggingface.co/datasets/TigerResearch/tigerbot-kaggle-leetcodesolutions-en-2k |
| hendrycks/MATH | https://github.com/hendrycks/math |
| GAIR/lima | https://arxiv.org/abs/2305.11206 |
Quality over quantity
For LLM fine-tuning (and training), the quality of the data is more important than the quantity. Therefore we deduplicated the datasets and removed low-quality data. The deduplication methodology was based on the cosine similarity used in Open Platipus.
Prompt format
Prompt formats can make a big difference. Adding some N-shot examples helped, as did telling the model to expect examples. Adding “n ### End” to the prompt screwed up the results. The end token worked for LitGPT, but not for Transformers library. For multiple-choice questions, we added an optional input to force the model to choose between one of the available options.
Base Model
There are plenty of open-source LLM models to choose from. For the competition, it explicitly needed to be a base model. Instruct and chat versions were not allowed.
Model Selection
The model selection was done in two steps. First, we looked at public benchmarks that roughly matched the HELM tasks. That gave us a list of candidate models. We evaluated those on the HELM benchmark.
Key learnings:
- In the landscape of all LLM models, some base models are generally better than others. Hence the pre-screening.
- Within the "good" models, different base models have different tasks they perform well on. Hence the evaluation on HELM.
Our main candidates were LlaMa2 (7B and 13B) and Mistral-7B.
Dev Models
To develop quickly we selected a smaller model to test with. We used Facebook's Opt-350M model. This model is small enough to run on a T4 and has a reasonable inference time. We used this model to test our setup and to quickly iterate on our approach. Our hypothesis was that if an approach did not improve the performance of the Opt-350M model, it would not improve the performance of the larger models either. After all, it would be a waste to spin up an A100 and waste money and time on some stupid bug in your code.
Training
The training was relatively straightforward. Although there are a lot of options and hyperparameters, there are plenty of papers with ablation studies that provide a decent starting point. Our key learnings around training are:
- Use QLoRA, but don’t fine-tune all attention layers. The open platypus paper has some good defaults.
- To balance performance with compute costs, you should only fine-tune for a single epoch. After this, the model is already very good at the fine-tuned tasks.
The combination of QLoRA and single epoch training was good enough for us to get a decent training and inference time. There are plenty of further training methods to try out. We provide an overview at the end of this blog.
Epochs
There is not much to gain beyond the first epoch. According to the superficial alignment hypothesis, LLMs actually gain their knowledge during pre-training. Finetuning simply aligns that knowledge in such a way that it can be used for interacting with end-users in a desired way. After processing 20% of the dataset the model is already very good at this.
The following image shows the loss for one of our earlier training runs. The marginal gains on the eval loss quickly diminish after the first epoch, from ~0.890 after epoch 1 to ~0.876 after epoch 2.
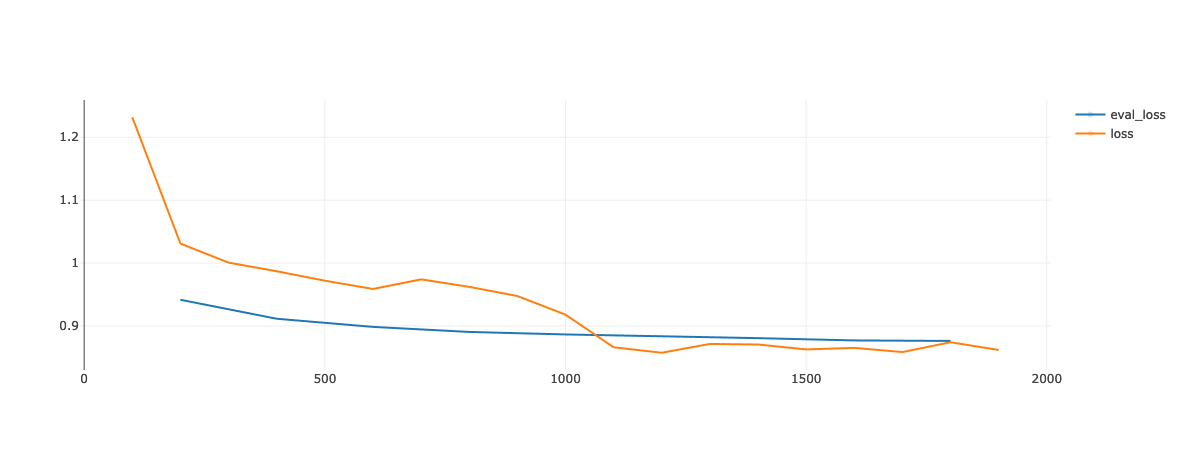
Since the goal of the challenge is efficient finetuning we decided to stop training after one epoch. Furthermore, this blog shows that finetuning for multiple epochs can be unstable.
QLoRA
Our goal is to fine-tune efficiently. We want to use as little compute as possible, while still getting good results. We found that QLoRa is a good way to do this.
LoRA
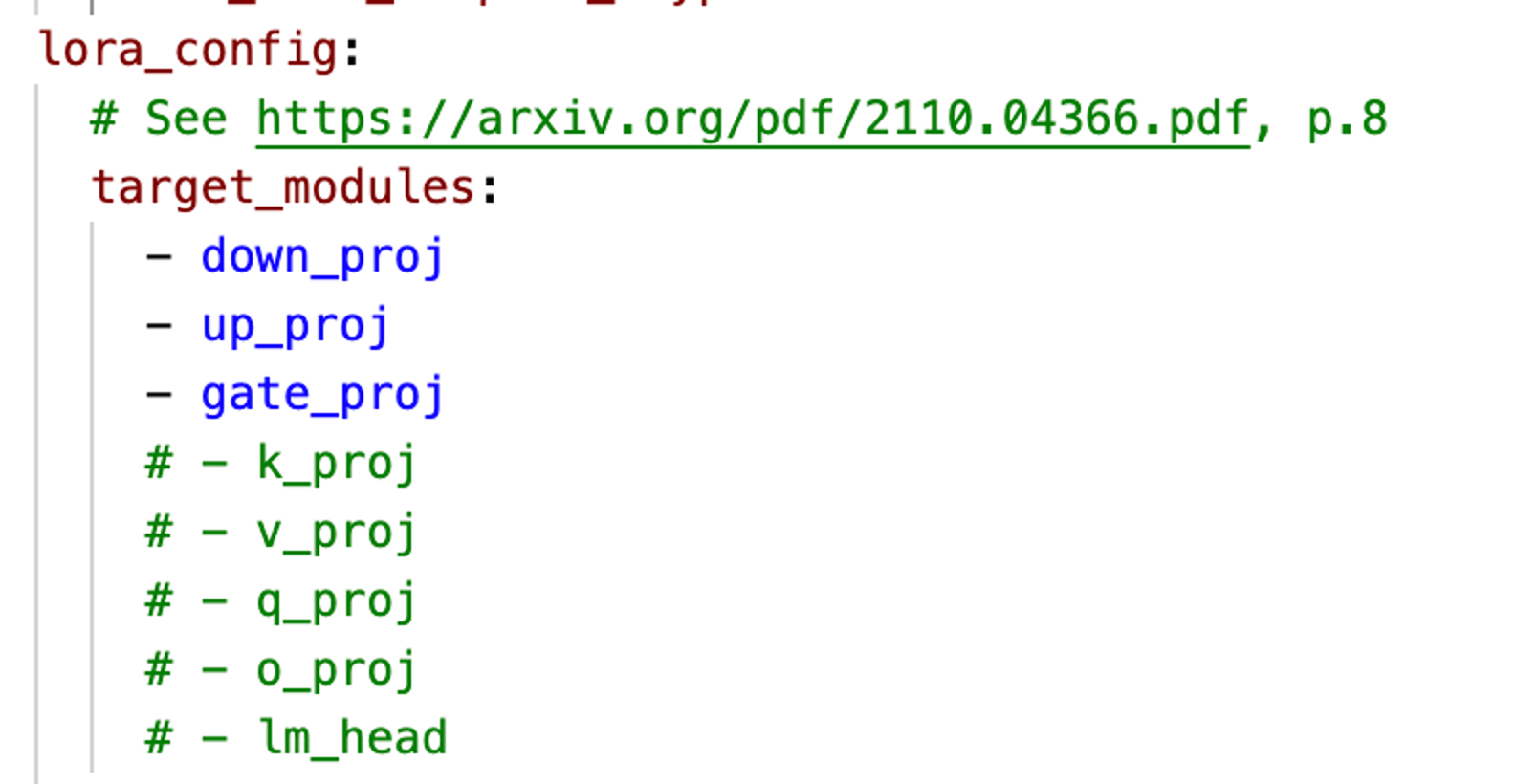
LoRA adds low-rank adapters to the attention layers of the model. This means the original layers are frozen and only the adapters are trained. The number of training parameters can be reduced further by limiting the number of attention layers LoRA is applied to. We follow the approach of He et al. (2021) and only fine-tune the down, up and gate projection layers.
| Model | Trainable parameters | All parameters | Trainable parameters(%) |
| Llama2-13b | 36,372,480 | 13,052,236,800 | 0.28% |
| Mistral-7b | 28,311,552 | 7,270,043,648 | 0.39% |
VRAM
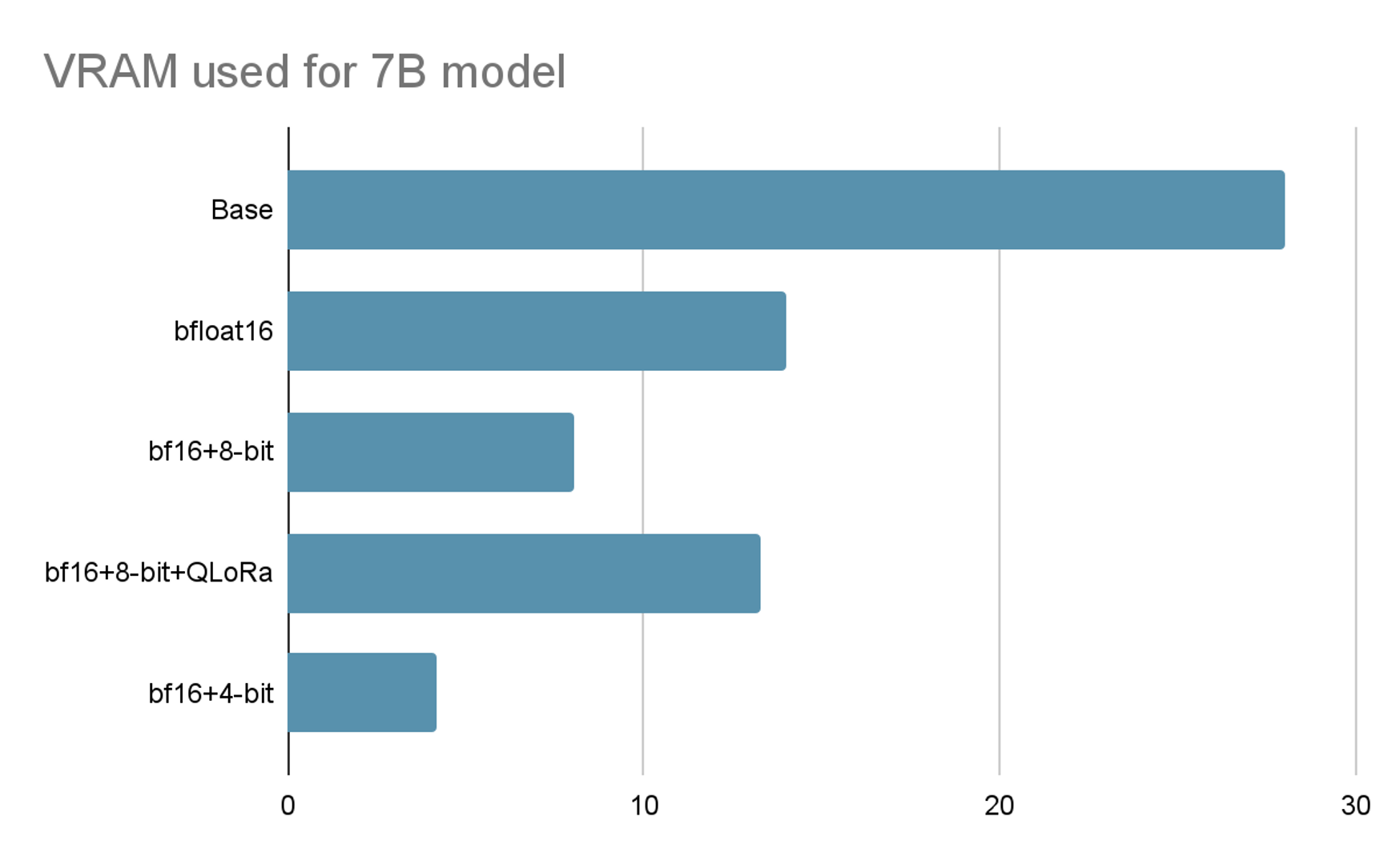
As a rule of thumb: a model with X billion params will take up ~4X VRAM in float32 precision. Using bfloat16 is ~2X. Using bfloat16 + 8-bit quantization uses ~1.1X. But merging the QLoRa model weights back in at inference time blows things up to ~1.8X (bf16+8bit+QLoRA in the figure). The best thing is to merge and dump to disk, then load at inference time. This, too, requires a lot of VRAM.
Torch optimization
While QLoRA is a good way to fit an LLM model on a single GPU, you should also consider other optimizations to speed up training and improve memory utilization. You can find a full list of tricks here.
Grouping by length
GPU FLOPS utilization is not optimal when training on sequences of different lengths. Text sequences can be padded, but that leads to a lot of wasted compute. Instead, you can group sequences by length and pad each group separately. This way, you can reduce the amount of padding and increase the utilization of the GPU. However, this results in unstable training.
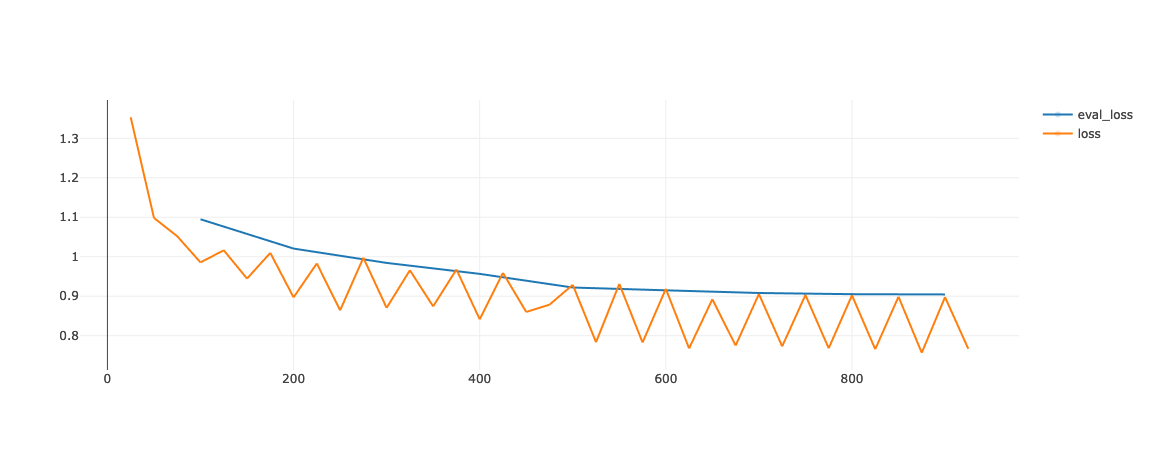
The figure above shows one of the earlier training runs. The training loss is very unstable. We expect this to come from the fact that we finetune on a wide range of tasks. Grouping by length in our case also means roughly grouping by task. At the end of a batch, the loss is evaluated for the examples in the batch. This means that if the model performance varies per task, the training loss is going to fluctuate per task.
This in itself does not have to be harmful. However, it shows that this process potentially updates the model for a specific task per batch, which can make for unstable training. It might be mitigated by using larger batch accumulation (more observations per forward pass before an update step).
Inference
During inference, we learned the following.
LoRA
Squash adapters back into attention layers make inference faster and more memory efficient. However, it can hurt performance, especially if you have domain-specific tasks.
Quantization
Be mindful of too much quantization. In practice, 4-bit inference saves you ~40-50% VRAM compared to 8-bit. But performance is also worse . . .
| Metric | 4-bit | 8-bit |
| MMLU EM accuracy | 0.497 | 0.655 |
| TruthfulQA accuracy | 0.333 | 0.889 |
| MMLU ECE calibration | 0.688 | 0.278 |
| MMLU EM Fairness | 0.497 | 0.623 |
| TruthfulQA Fairness | 0.333 | 0.889 |
Pre-processing prompts
Pre-processing incoming requests is very important and can be task-specific.
Post-processing results
As is post-processing responses, simple .strip() does wonders for your score. It helps remove newline and end-of-response tokens.
Results
We placed 11 (top 25%) on the public leaderboard of the 4090 track.
Bias
Originally we scored poorly on the bias metric in the public leaderboard. So we added a dataset for debiasing: CrowS-Pairs. As you can see in the table our "Bias Mean Win Rate" was still only 0.42 after adding this dataset.
| Metric | CrowS-Pairs | + Temp. Incr. |
| Public ranking | 14 | 11 |
| Bias Mean Win Rate | 0.42 | 0.58 |
Therefore we tested an adjustment during inference. We increased the temperature from 0.3 to 0.7. The Bias mean win rate bumped up from 0.42 to 0.58! The idea behind this quick fix is that underrepresented races or genders correspond to tokens with a lower probability if the model is biased. By increasing the temperature the model oversamples tokens with relatively low probability. Thereby decreasing the bias.
Our hypothesis is that all open-source base models that were whitelisted for this competition are biased. A quick fix at inference time is not a sustainable solution. With the idea that during finetuning the model learns to align its knowledge, we think that a more sustainable way to tackle the bias is at pretraining.
Further reading on bias:
What is next?
We will be at NeurIPS 2023 and join the workshop that is hosted for this competition. You can expect another blog post with our learnings from the winners of the competition.
Future work
At the same time, there are a lot of topics we would like to explore further:
- Flash attention and v2.
- Transfer adapters trained on smaller models and apply them to bigger base models, like in the Platipus paper or Microsoft-Phi.
- More elaborate training tricks (e.g. in update steps).
- Specific prompts for the training data.
- MeZO: More memory efficient training with only forward passes: paper, repo.
- Combining models, e.g. in an ensemble.
- Multiple adapters with their own strengths: Multi LoRA.
- More elaborate tricks during inference (e.g. modifying prompt when input contains examples).
- Hardware-specific optimization (e.g. TensorRT).
- Measure and experiment with performance drop from merging FP16 adapters with NormalFloat weights.
- Further reading on LLM evaluation
Written by

Jetze Schuurmans
Machine Learning Engineer
Jetze is a well-rounded Machine Learning Engineer, who is as comfortable solving Data Science use cases as he is productionizing them in the cloud. His expertise includes: AI4Science, MLOps, and GenAI. As a researcher, he has published papers on: Computer Vision and Natural Language Processing and Machine Learning in general.




Contact