
Vertex AI pipeline caching
Caching is a useful feature provided by many tools, Vertex AI pipelines included. Caching provides the ability to save what is needed later to skip repeated computations. Skipping computations reduces costs and speeds up development. Vertex AI caches the output of pipeline steps in Vertex ML Metadata using a cache key. If caching is enabled for a pipeline step, the cache key is used to match an earlier pipeline step execution. The pipeline step execution of your current pipeline will be skipped and the cached output will be used. Only pipelines with the same name will share the cache.
The cache key is a unique identifier defined as a combination of the following pipeline step properties:
- Pipeline step's inputs: These inputs include the input parameters' value and the input artifact id.
- Pipeline step's output: This output definition includes output parameter names and output artifact names.
- Component's specification:
- the image
- commands (including their order)
- arguments (including their order)
- environment variables
Caching can be enabled on pipeline task or job level. Caching on pipeline level has three possible options:
- True: enable caching for all pipeline steps in this run
- False: disable caching for all pipeline steps in this run
- None: defer caching to pipeline steps in this run
Caching on step level has two possible options:
- True: enable caching for a pipeline step
- False: disable caching for a pipeline step
By default pipeline cache on job level is configured to deferring to step level. Caching is enabled by default on pipeline step level. This results in caching being enabled by default for all steps in a pipeline.
Examples
We can use different modes of caching. Let's dive into the three options together:
Caching enabled
We can enable caching on pipeline level, as can be seen in the script below. We disabled cache on pipeline step level. But, the cache was used because we overwrote it on pipeline job level.
import google.cloud.aiplatform as aip
from kfp.v2 import compiler, dsl
@dsl.component()
def add(x: int, y: int) -> int:
return x + y
@dsl.pipeline(
name="test-pipeline"
)
def test_pipeline():
x = add(1, 2)
x.set_caching_options(False)
y = add(x.output, 3)
compiler.Compiler().compile(
pipeline_func=test_pipeline,
package_path="test.json",
)
job = aip.PipelineJob(
project=GCP_PROJECT_ID,
location=GCP_REGION,
display_name="test-pipeline",
template_path="test.json",
pipeline_root=f"{GCS_BUCKET}/pipeline",
enable_caching=True,
)
job.submit(service_account=SERVICE_ACCOUNT)
In the first run we see both steps being executed. This is indicated by the green checkmarks next to steps.
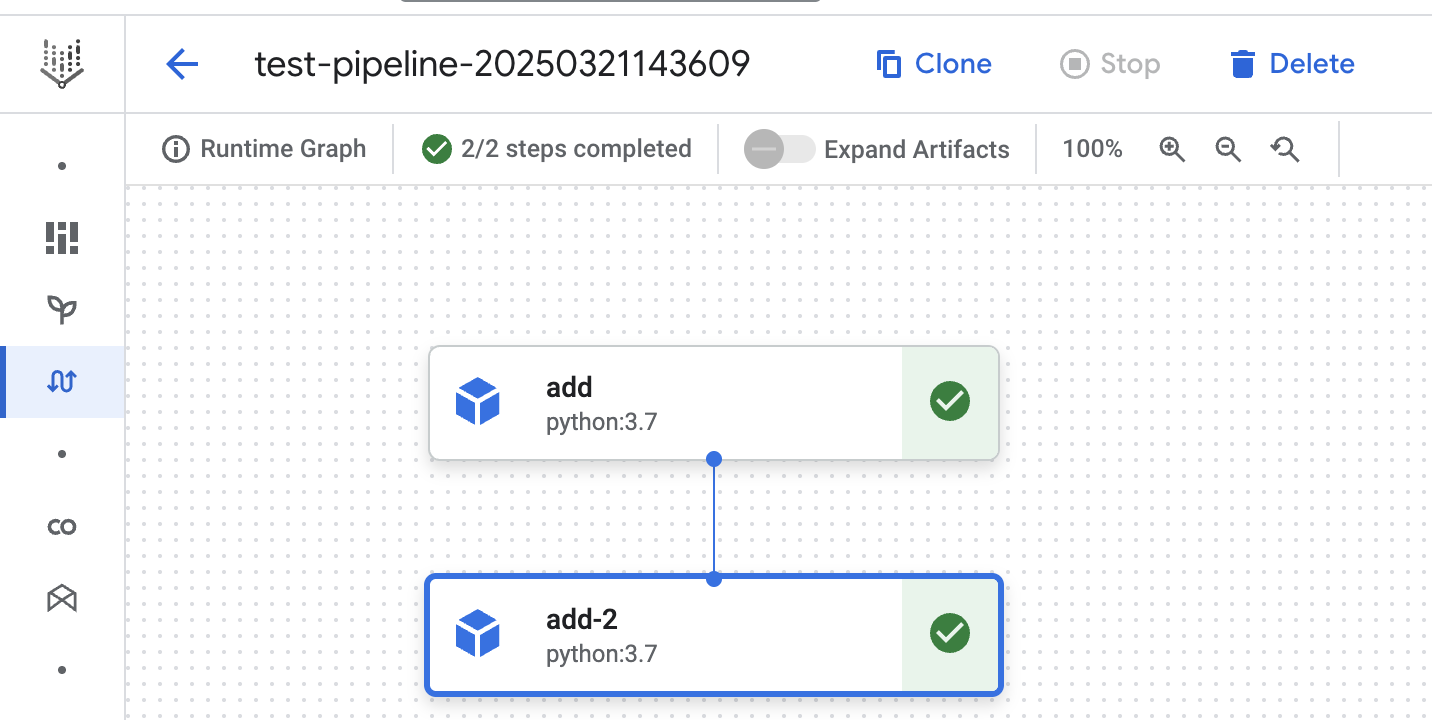
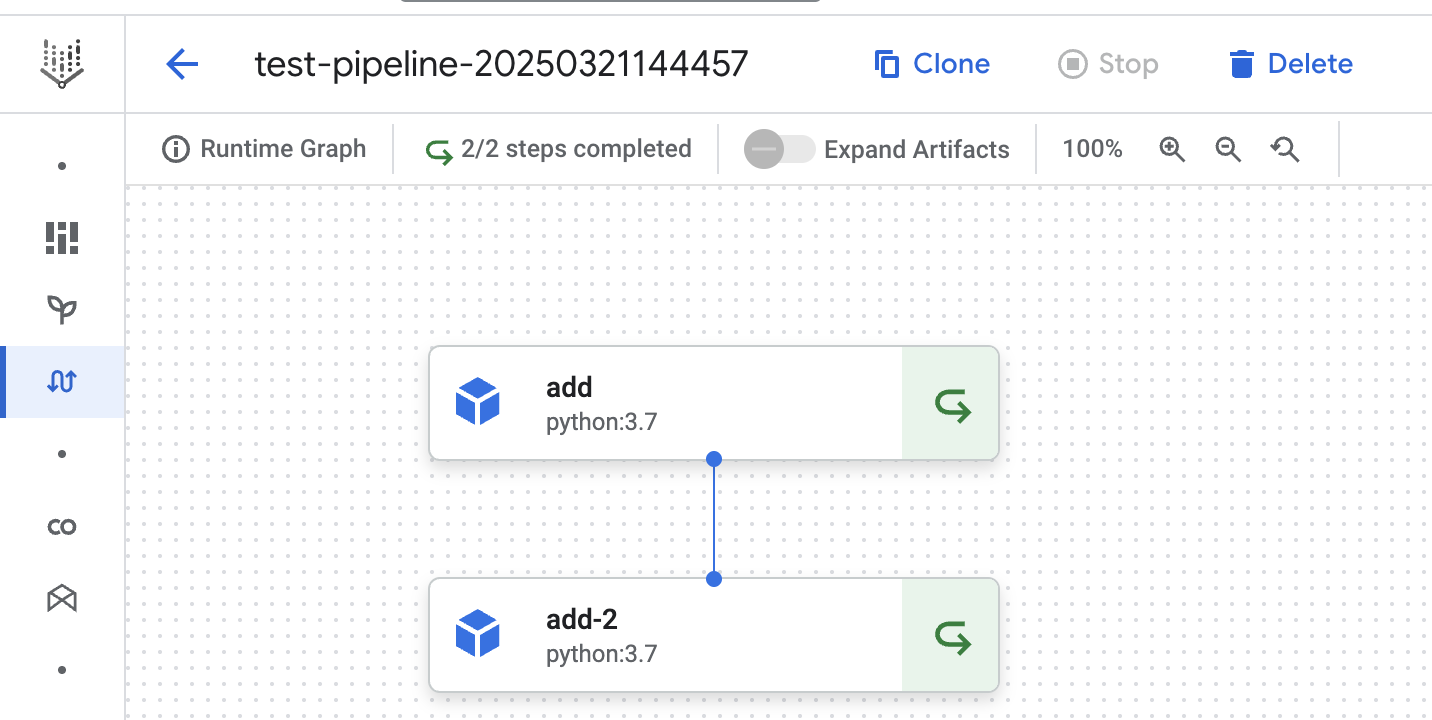
In the second run we see both steps use the cached result. Even the step (by using the set_caching_options method) for which we explicitly disabled cache. This shows the pipeline level cache setting overwrites the pipeline step level cache setting.
Caching disabled
When we disable pipeline cache, we can observe the same behavior. The pipeline job level setting overwrites the step level setting. See the python script below where the cache is disabled and the cache is enabled on pipeline step level.
import google.cloud.aiplatform as aip
from kfp.v2 import compiler, dsl
@dsl.component()
def add(x: int, y: int) -> int:
return x + y
@dsl.pipeline(
name="test-pipeline"
)
def experimentation_pipeline():
x = add(1, 2)
x.set_caching_options(True)
y = add(x.output, 3)
compiler.Compiler().compile(
pipeline_func=experimentation_pipeline,
package_path="test.json",
)
job = aip.PipelineJob(
project=GCP_PROJECT_ID,
location=GCP_REGION,
display_name="test-pipeline",
template_path="test.json",
pipeline_root=f"{GCS_BUCKET}/pipeline",
enable_caching=False,
)
job.submit(service_account=SERVICE_ACCOUNT)
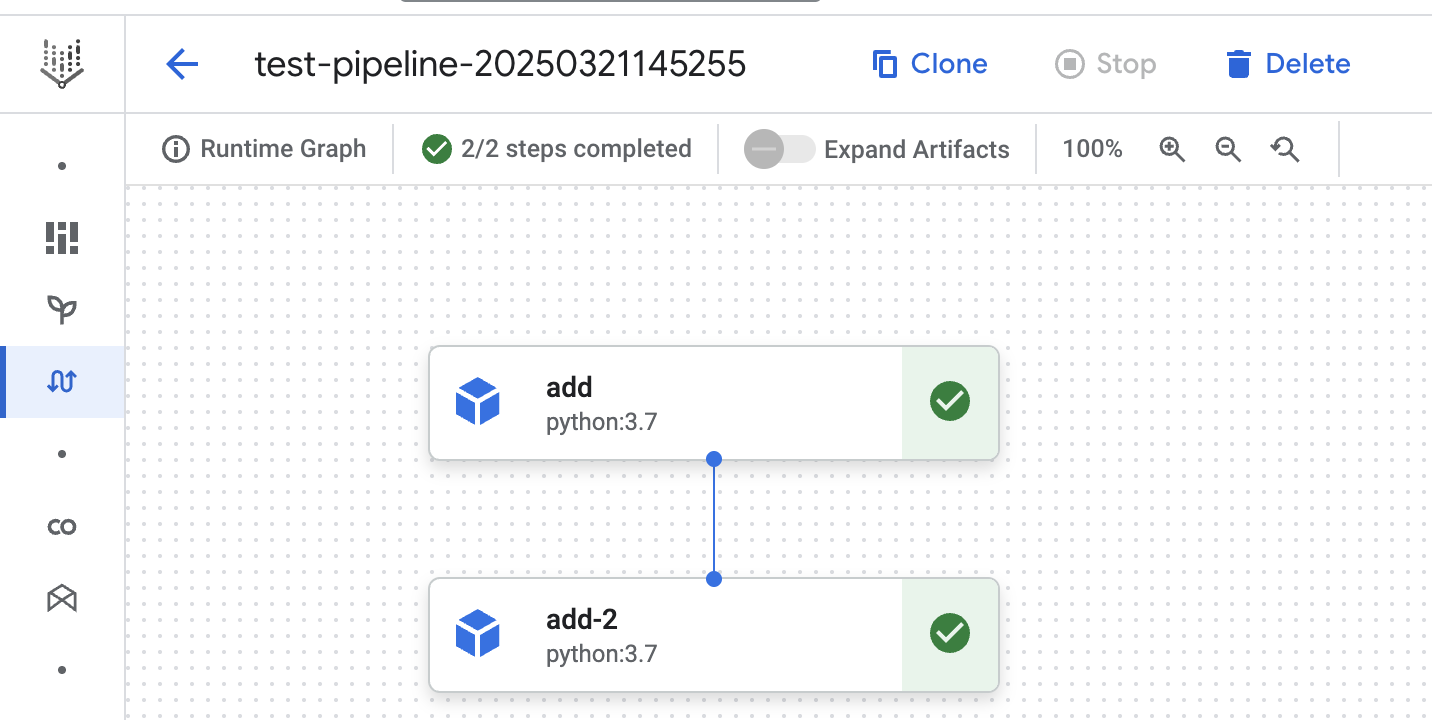
We can see both steps being executed in the third pipeline run below. This shows the cache is not used for either step. It could have reused the step from the runs above, but we told Vertex AI not to.
Caching deferred
Defer caching is the third option. This tells Vertex AI pipelines (enable_caching = None) to explicitly defer caching to the pipeline steps. Vertex AI pipelines by default defer caching to pipeline steps. Additionally, pipeline steps have caching enabled by default. This means Vertex AI pipelines have caching enabled by default.
Caching is explicitly deferred in the script below.
import google.cloud.aiplatform as aip
from kfp.v2 import compiler, dsl
@dsl.component()
def add(x: int, y: int) -> int:
return x + y
@dsl.pipeline(
name="test-pipeline"
)
def experimentation_pipeline():
x = add(1, 2)
x.set_caching_options(True)
y = add(x.output, 3)
compiler.Compiler().compile(
pipeline_func=experimentation_pipeline,
package_path="test.json",
)
job = aip.PipelineJob(
project=GCP_PROJECT_ID,
location=GCP_REGION,
display_name="test-pipeline",
template_path="test.json",
pipeline_root=f"{GCS_BUCKET}/pipeline",
enable_caching=None,
)
job.submit(service_account=SERVICE_ACCOUNT)
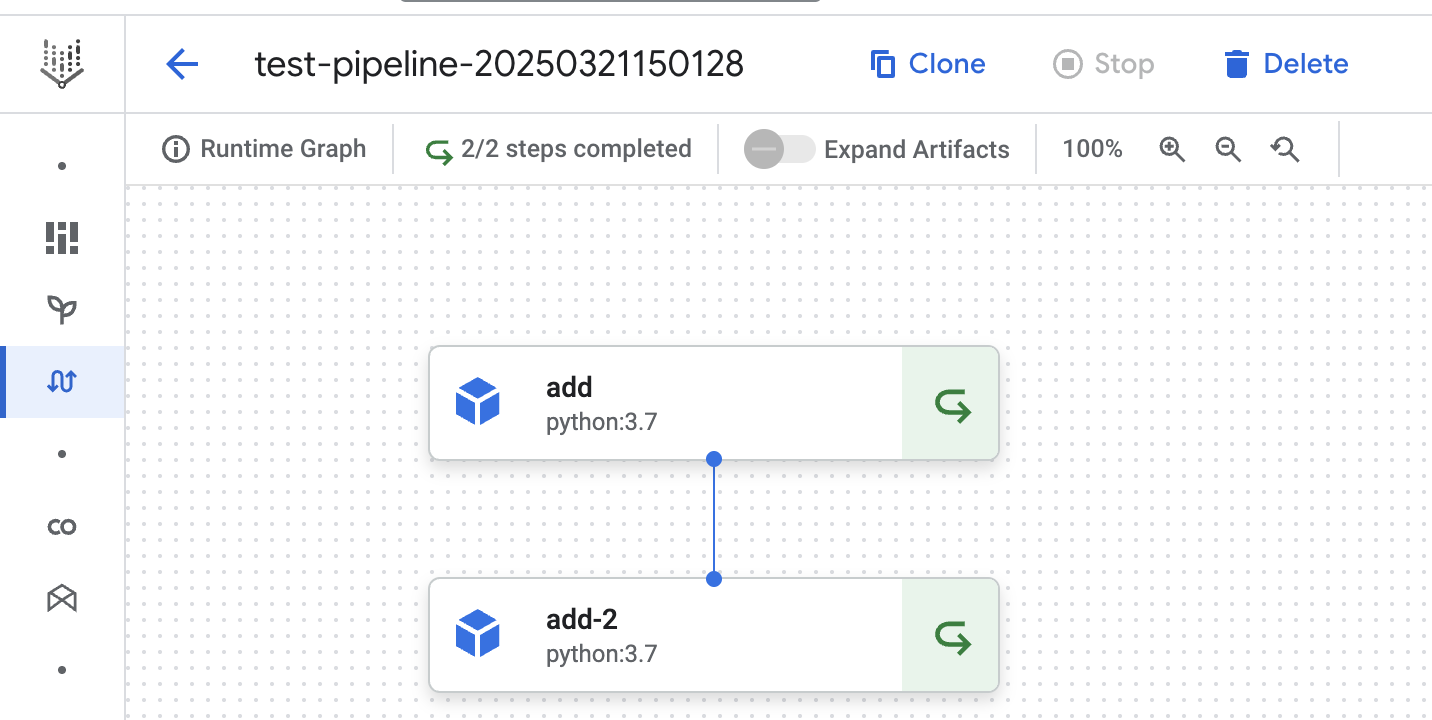
In this fourth run we can see pipeline step cache is used for both steps. We explicitly configured the first add step to use cache. The result of the previous pipeline run is used in the first add step. The same happened for the second add-2 step, because caching is enabled by default.
@dsl.component()
def add(x: int, y: int) -> int:
return x + y
@dsl.pipeline(
name="test-pipeline"
)
def experimentation_pipeline():
x = add(1, 2)
y = add(x.output, 3)
y.set_caching_options(False)
compiler.Compiler().compile(
pipeline_func=experimentation_pipeline,
package_path="test.json",
)
job = aip.PipelineJob(
project=GCP_PROJECT_ID,
location=GCP_REGION,
display_name="test-pipeline",
template_path="test.json",
pipeline_root=f"{GCS_BUCKET}/pipeline",
enable_caching=None,
)
job.submit(service_account=SERVICE_ACCOUNT)
In the run below we can see the cached result from the first step is used. The second step of the pipeline is executed.
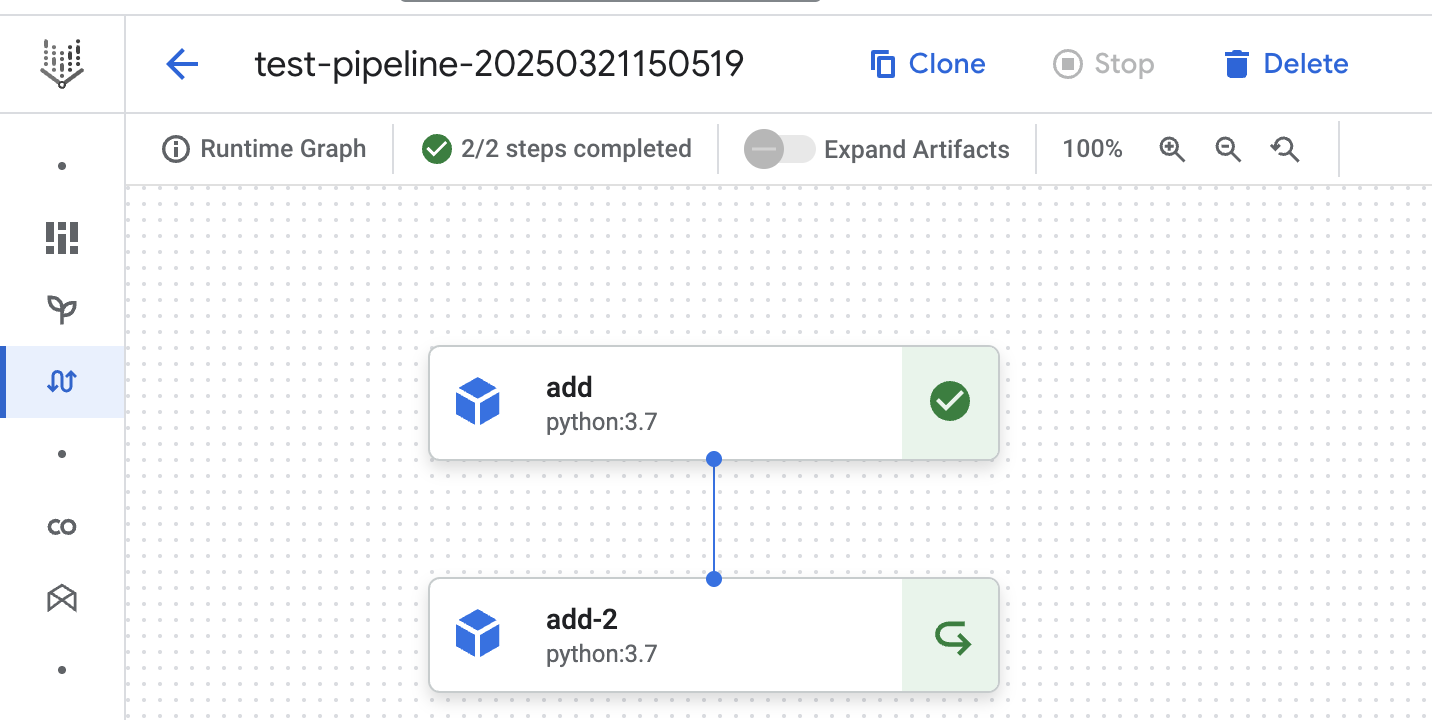
Caching caveats
There are some caveats that you must be aware of when you enable caching in Vertex AI pipelines. - Vertex AI pipelines claims pipeline steps don't use cache when the image changes. This is true if you change the image name or the image tag. However, this does not work when you push a new image with the same tag. Say you use the test-image:1.2.3 image. The tag of the image is 1.2.3. When you push a new image for test-image, you may expect this new image will be used in your pipeline step. However, this is not the case. Vertex AI will not check the underlying SHA256 sum (determines image uniqueness) with the last image with tag 1.2.3. - Vertex AI pipelines cannot pick up changes in external data (e.g. BigQuery (BQ) data). It knows about the data source, but not the data in that source. Say the first step in your pipeline depends on a BQ dataset and has caching enabled. Rerunning the pipeline will skip the first step despite a change to your data dependency.
Conclusion
For the reasons listed above I would recommend disabling cache on the pipeline level as a default. Pipeline caching helps when you're rerunning the same pipeline multiple times in short succession. Say you're training a machine learning model with the same feature set trying out different models. In this case you want to reuse your feature computations and only run the training step. When you're running a production pipeline your pipeline steps will have unique outputs each run. Therefore, you would disable pipeline caching in this pipeline to avoid the caveats listed above.
Banner image by Pixabay
Written by
Roy van Santen
Our Ideas
Explore More Blogs




Contact