Blog
Boost your ADF productivity with Terraform

Introduction
This blog post will explore how Azure Data Factory (ADF) and Terraform can be leveraged to optimize data ingestion. ADF is a Microsoft Azure tool widely utilized for data ingestion and orchestration tasks. A typical scenario for ADF involves retrieving data from a database and storing it as files in an online blob storage, which applications can utilize downstream.

Example ingestion process using ADF
ADF provides a GUI allowing users to easily create pipelines connecting various data sources with their targets. This click-based development approach may seem accessible compared to high-code alternatives. However, it also presents the risk of inefficiently consuming significant development time. To address this, we'll propose an efficient development method that minimizes development time by utilizing parameters and deploying triggers using Terraform, aligning with two software development best practices.
A quick note: This blog is intended for data enthusiasts with some experience in Data Factory. It will require a basic understanding of the concepts used in ADF. If you're new to ADF, consider it a starting point for discovering its potential.
Software development best practices
DRY (Don't Repeat Yourself)
DRY is a fundamental principle in software development that emphasizes avoiding the repetition of code or logic. It promotes code reusability, maintainability, and readability by ensuring that each piece of knowledge or functionality within a software system is represented in only one place.
Adhering to the don't repeat yourself (DRY) principle, we say:
similar datastore -> similar ingestion pipeline
KISS (Keep It Simple, Stupid)
KISS is a design and development principle that advocates for simplicity in software design, architecture, and implementation. The idea behind the KISS principle is to keep solutions as simple as possible without sacrificing functionality or effectiveness.
Adhering to the KISS principle, we say:
Every pipeline has as few activities as needed (preferably 1) Every pipeline has a clear goal (preferably only copying data)
Goal
This blog post aims to provide a way to use ADF by using parameters and triggers created by Terraform that adhere to the mentioned software development best practices, resulting in fewer clicks, faster development times, and enabling less technical people.
We do this by:
- Making a split between what we want to do and how we want to do it:
- What we want to do: Move data from a data store to a storage container at a specific schedule.
- How we want to do it: A pipeline with (preferably) one or more activities using data sets and linked services in ADF.
Having that split allows less technical users to understand and possibly contribute to "what we want to do" without worrying about "how we want to do it."
- Create reusable pipelines: we don't need to repeat ourselves (similar datastore â similar ingestion pipeline).
We've split up our workflow with ADF into two parts:
Building dynamic pipelines using parameters
The benefit
How we want to do it: a pipeline with one (preferably) or more activities using data sets and linked services in ADF.
As stated above, we build pipelines and then schedule pipeline runs separately. This means we need to build pipelines so that we can reuse them as much as possible. This recycling of the same pipeline is made possible by parameterizing the pipeline objects. A parameter is a named entity that defines values that can be reused across various components within your data factory. Parameters can be utilized to make your data factory more dynamic, flexible, easier to maintain, and scalable.
To demonstrate the power of parameters, let's take the following example:
Data must be transferred from 2 SQL databases containing 5 tables to an Azure Blob Storage container. Every table needs to be transformed into a parquet, and its dedicated folder must be put inside a container. An Azure Key Vault is created to store any secrets. The databases look as follows:
hr
- contracts
- employees
sales
- customers
- inventory
- sales
The comparison of the amount of resources with and without parameters looks as follows:
| Resources | Without parameters | With parameters |
|---|---|---|
| Linked Services | 3 (1 for each database, 1 for blob) | 2 (1 for the databases, 1 for blob) |
| Datasets | 10 (1 for each table source/sink) | 2 (1 for SQL, 1 for blob parquet) |
| Pipelines | 5 (1 for each table) | 1 |
Visually this improvement looks as follows in ADF:
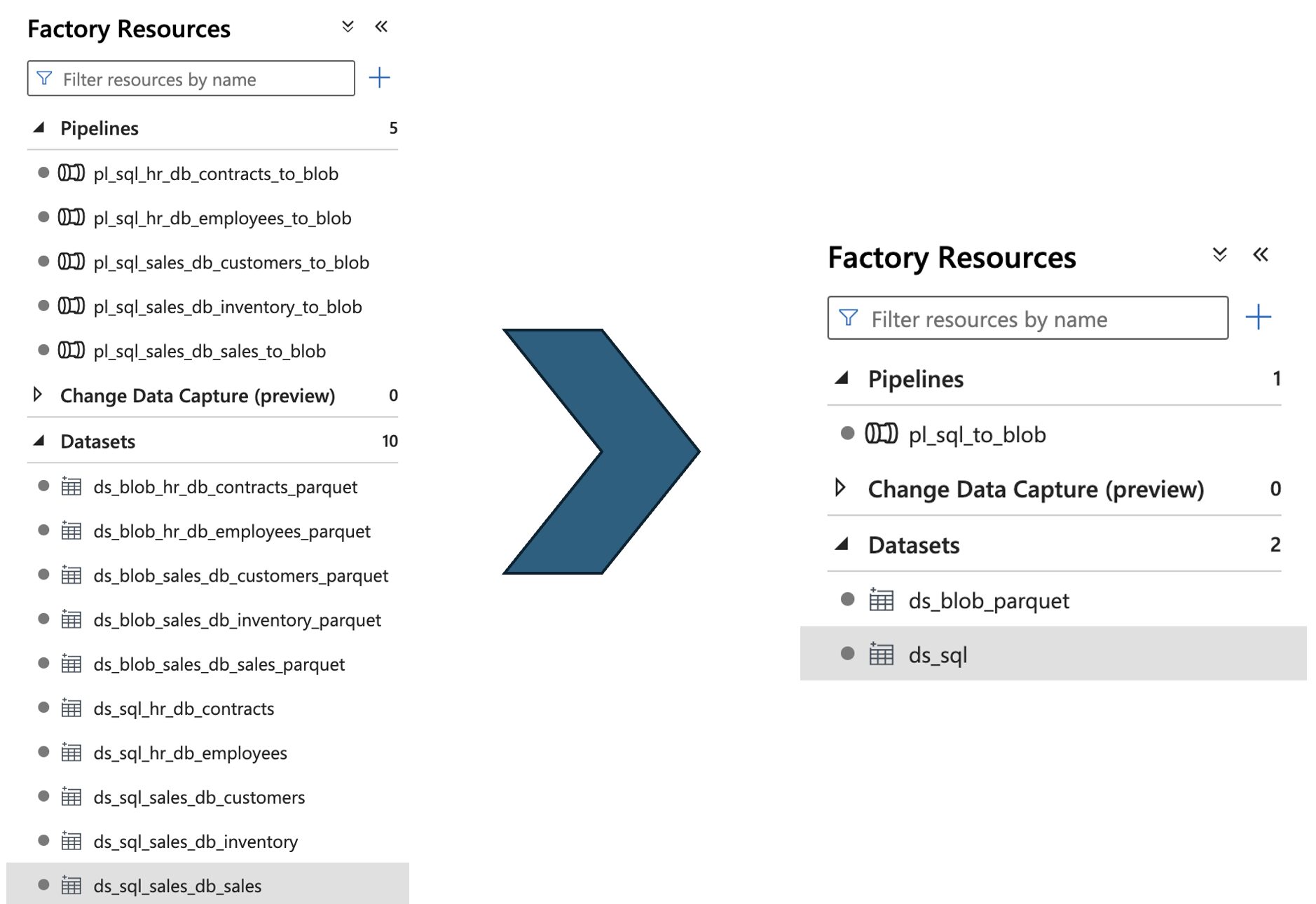
This is a vast improvement, even with just 2 SQL databases and five tables. Imagine the benefits when there are hundreds of tables! Adding a new table to the parameterized setup would not require changes in the pipeline definitions. This allows non-technical people also to load new tables, following the set guidelines of
Having that split allows less technical users to understand and possibly contribute to "what we want to do" without having to worry about "how we want to do it."
How does it work?
Using ADF, we'll create a pipeline and define parameters. You can find an explanation on pipeline parameters here.
So, where do we want to add parameters? Basically, everywhere! To ensure our pipelines are fully parameterized, we need to include parameters at various pipeline levels.
Pipeline parameters Pipeline parameters are high-level parameters that apply to the entire pipeline. These parameters can control various aspects of the pipeline execution, such as environment-specific settings, file paths, or processing options.
Dataset parameters Dataset parameters are used to make datasets within the pipeline more dynamic. By parameterizing datasets, you can modify the data source or destination details at runtime, making your data handling more flexible. This is particularly useful when dealing with multiple datasets that follow a similar structure but vary in detail, such as file names or connection strings.
Linked service parameters Linked service parameters allow you to configure connections to your data sources and destinations dynamically. These parameters make your linked services adaptable to different environments or scenarios, enhancing the overall flexibility of your pipeline.
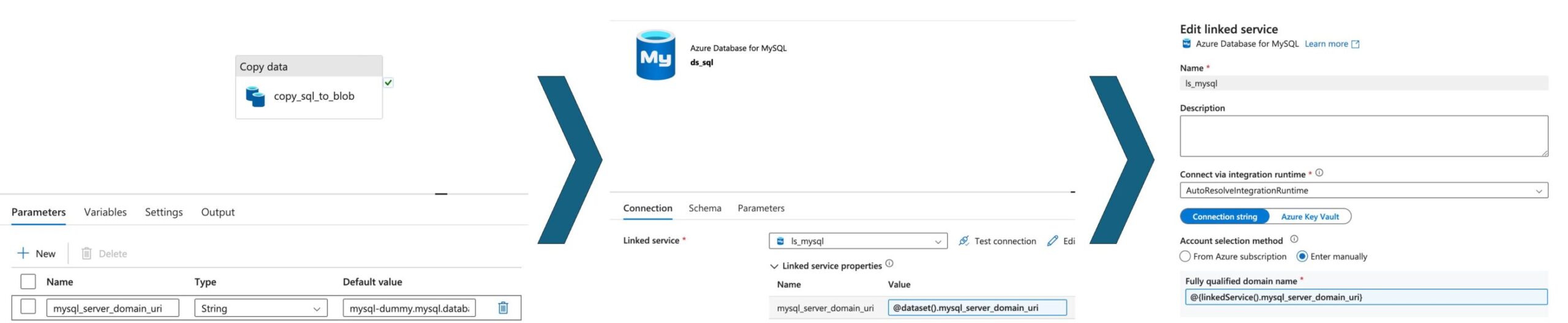
Passing Parameters: Pipeline -> Dataset -> Linked Service
Parameters can flow seamlessly from the pipeline level to datasets and linked services in a fully parameterized data pipeline. This hierarchical parameter passing ensures that each pipeline component can adapt dynamically based on the parameters provided at the start of the pipeline execution. The image below shows how the parameter mysql_server_domain_uri is passed to the pipeline, which passes it to the dataset, which uses it at the end of the Linked Service to connect the SQL server.
Scheduling pipelines using Terraform
So far, we've looked at coding best practices and how they relate to parameters. Now that we know how to create dynamic and reusable pipelines, it's time to look at their scheduling. Scheduling pipelines is done in ADF through triggers. Triggers are mechanisms that automate the execution of data pipelines based on specific conditions, e.g., at a specific time.
Creating triggers for each dataset, especially across multiple environments, can be time-consuming and error-prone when using only the ADF GUI. Maintaining consistency between environments becomes challenging, and mistakes can quickly occur due to the click-based development approach.
In this blog, we'll show you how to create these triggers using Terraform instead of the ADF GUI. Some advantages of using Terraform over the GUI are:
Consistency: Terraform scripts ensure your infrastructure is consistently deployed across different environments (development, testing, production).
Version Control: With Terraform, your infrastructure configurations can be stored in version control systems like Git, making it easier to track changes, collaborate with team members, and roll back to previous versions if needed.
Repeatability: Terraform allows you to automate the deployment process, reducing the time and effort required to set up and configure ADF pipelines in different environments.
Ease of Use with YAML Files: ADF triggers can be defined using YAML files, which makes the configuration more accessible to less technical team members. YAML's human-readable format simplifies setting up and modifying triggers, enabling team members without deep technical expertise to add data sources.
Requirements
- Knowledge of Terraform
- Terraform authenticated for your Azure environment
- A parameterized ADF pipeline
How does it work?
Terraform is used to deploy and manage the triggers in an Azure Data Factory. The main.tf file (described here) is used to:
- Read trigger configurations from the
trigger_info.yamlfiles as described here - Create Azure Data Factory triggers objects based on the configuration
Deployment can be done locally or using an automation tool, such as Github Actions or Azure DevOps.
Creating a trigger_info.yaml
One trigger_info.yaml file needs to be created for each data source and for each environment of this data source for which you want to pull data.
Inside this yaml is all the information needed to create your pipeline trigger, as shown in this example below:
pipeline_name: pl_sql_to_blob
schedule:
frequency: Day
interval: 1
hours: [3]
datastore_parameters:
mysql_server_domain_uri: 'mysql-dummy.mysql.database.azure.com'
database_username: 'dummy_username'
storage_account_name: 'sa_dummy'
container: 'adf-triggers-blog'
key_vault_uri: 'https://kv-playground-ra.vault.azure.net/'
key_vault_sql_database_password_secret_name: 'mysql-dummy-password'
datasets:
- name: hr_contracts
dataset_parameters:
database: 'hr'
table: 'contracts'
- name: hr_employees
dataset_parameters:
database: 'hr'
table: 'employees'
The file consists of several different parts:
pipeline_name: The pipeline's name in Azure Data Factory (ADF) for which you want to create triggers.
schedule: Specifies the frequency (e.g., Day or Hour) at which the trigger should run, including the interval and time of execution. These settings are generic for all pipelines and are not dependent on pipeline-specific parameters.
datastore_parameters: Contains parameters specific to the datastore. Since these parameters are shared across all datasets, they must be defined only once. Note that we don't store secrets here directly, only a secret name for a secret to be retrieved from a key vault.
datasets: This field contains dataset-specific information. The SQL Server used in our example includes the database and table.
Note The schedule settings are generic across all pipelines, but the datastore_parameters and dataset_parameters are pipeline-specific. Together, these two must include all the parameters required by a pipeline.
Processing the trigger_info in main.tf
Now that we've defined our triggers in the trigger_info.yaml file, it's time to process that information and turn it into actual ADF triggers. The processing is done in the main.tf file. The goal of this file is that for every environment, every data source, and within that data source for every dataset, it will deploy an ADF Trigger resource with the set parameters as shown in this example below:
locals {
time_zone = "W. Europe Standard Time"
// Retrieve datastore configurations from YAML files
datastore_configs = {
for filename in fileset("env/${var.env_path}/datastores/*/", "*.yml") :
filename => yamldecode(file("env/${var.env_path}/datastores/*/${filename}"))
}
// Generate triggers based on datastore configurations
triggers = merge(flatten([
for filename, datastore in local.datastore_configs : [
for dataset in datastore.datasets : {
"${datastore.pipeline_name}_${dataset.dataset_parameters.database}_${dataset.dataset_parameters.table}" = {
"pipeline_name" = datastore.pipeline_name
"schedule" = datastore.schedule
"datastore_parameters" = datastore.datastore_parameters
"dataset_parameters" = dataset.dataset_parameters
}
}
]
])...)
}
// Retrieve the Azure Data Factory resource
data "azurerm_data_factory" "this" {
name = var.adf_name
}
// Create triggers based on the generated triggers
resource "azurerm_data_factory_trigger_schedule" "this" {
for_each = local.triggers
name = each.key
data_factory_id = data.azurerm_data_factory.this.id
time_zone = local.time_zone
interval = each.value.schedule.interval
frequency = each.value.schedule.frequency
schedule {
hours = lookup(each.value.schedule, "hours", [0])
minutes = lookup(each.value.schedule, "minutes", [0])
}
pipeline {
name = each.value.pipeline_name
parameters = merge([
each.value.datastore_parameters,
each.value.dataset_parameters
]...)
}
}
Explanation of the different sections:
Locals block: In the locals block, configurations from YAML files are processed into deployable triggers. The trigger name is implicitly set based on several parameters, ensuring consistent naming across all triggers. However, making the trigger name an explicit field in the configuration file could simplify identifying and managing trigger configurations.
Data block: In the data block we retrieve the information of the ADF resource that will be used.
Resource block: The resource block specifies the creation of resources, in this case, scheduled triggers in Azure Data Factory. It uses local variables and fetched data to dynamically configure and create each trigger, setting parameters like name, schedule, and pipeline details.
After everything has been set up, you can create the triggers by using the regular Terraform plan and apply.
Summary
In this informative blog post, we looked into the powerful combination of Azure Data Factory (ADF) and Terraform for optimizing data ingestion. We presented a setup that addresses the potential inefficiencies of the click-based development approach in ADF and offers a more efficient method using parameters and triggers created by Terraform. We aim to provide a solution that adheres to best practices, accelerating development times and empowering non-technical users to contribute effectively.
Written by
Rik Adegeest
Rik is a dedicated Data Engineer with a passion for applying data to solve complex problems and create scalable, reliable, and high-performing solutions. With a strong foundation in programming and a commitment to continuous improvement, Rik thrives on challenging projects that offer opportunities for optimization and innovation.




Contact