

Most of the online resources suggest to use Azure Data factory (ADF) in Git mode instead of Live mode as it has some advantages. For example, ability to work on the resources as a team in a collaborative manner or ability to revert changes that introduced bugs. However, the way that git mode is implemented is not taking advantage of the infrastructure as code (IaaC) approach. One of the aspects of IaaC is being able to reason about the state of deployed resources just by looking at code. Unfortunately, when Git integration is enabled, it is not the main branch that shows you the resources, but rather an auto-generated adf_publish branch. This branch is implemented using ARM templates, which are quite verbose and not human-friendly. You can take a look at this example from Microsoft which only contains one activity. Now imagine that you have dozens of pipelines with complex activities, several datasets and linked services. An alternative to that would be to use Terraform to deploy ADF pipelines.
We want to show how to mitigate the shortcomings of the ADF’s Git mode and still benefit from advantages of the code stored in source control. In order to achieve this, we’ll use Terraform to deploy both ADF (in Live mode) and its resources. This implies that the Terraform code is stored in the Git repo. Next to that, we’ll show how to circumvent some of the limitations that Azure’s Terraform provider has when it comes to more complex pipelines.
Using our method, one can simply look at the code (or specific tagged version of it) and tell for sure what is deployed.
There is one limitation for using Terraform though. Currently, azurerm Terraform provider doesn’t allow for creation of "complex" pipelines. By "complex" we mean the pipeline that contain any other variables than of type string. But for that we have a workaround.
Prerequisites for Terraform ADF pipelines
If you, like us, are using CI/CD pipeline to provision the resources, you probably are using service principal on your build agent. In order to use one solution that works both locally during debug/testing and on the build agent, you will need to have the service principal credentials.
Also, this only works on Bash, so make sure to have it installed.
The fileset approach
As mentioned, we didn’t start from scratch, but already had existing pipelines in JSON format and a process to generate them. Having this in mind, we decided that these resources would stay as-is. This separation allows Platform and Data Engineering parts of the team to be as efficient as possible and use languages they are the most used to. Platform engineers can use Terraform to provision resources and take the most out of it, while data engineers can work and edit the pipelines in the same format as they are represented in ADF. In the image below you can see how the pipelines and triggers (resources that will stay in json format) were stored in our case.
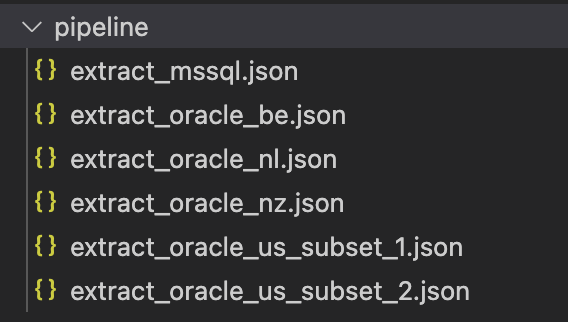
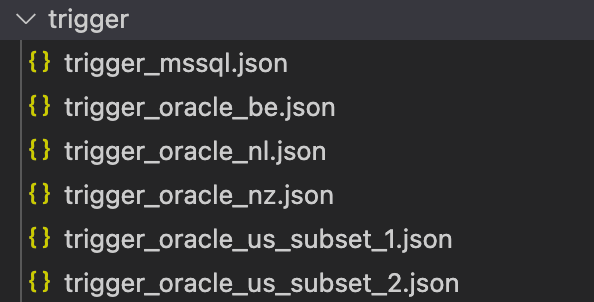
Since we managed to migrate other resources, such as linked services and datasets, directly to the Terraform code, we could get rid of these files:
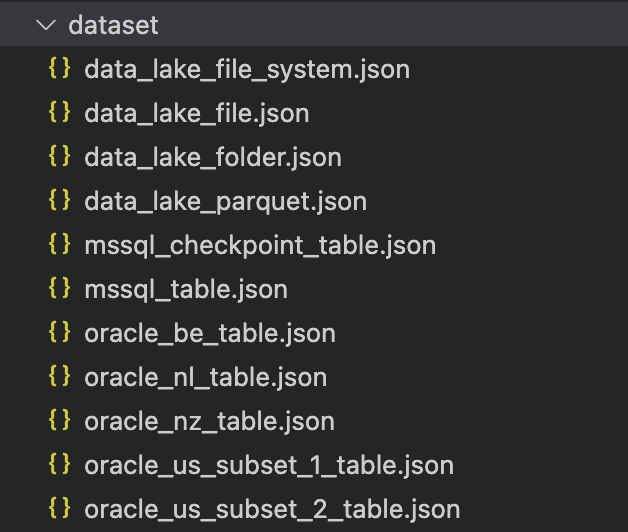
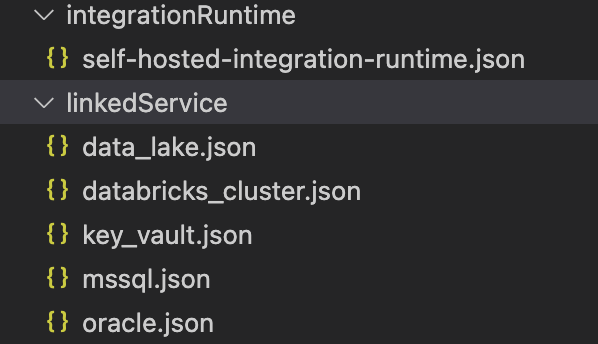
Our approach will make sure that every time a data engineer would generate new pipelines (or modify existing ones), Terraform code would automatically pick them up and deploy them.
To read and process a set of existing files, we use Terraform’s fileset function. Let’s see it in action. First, we add a local variable using fileset:
locals {
pipelines = { for value in fileset("./pipelines", "*.json") : value => jsondecode(file("./pipelines/${value}")) }
data_factory_id = "DATA_FACTORY_ID"
}This code iterates over all the json files stored in the pipelines folder and deserialises them. In your case, if your pipelines have to adhere to a certain naming convention or live in a different folder, you can modify the mask and/or location.
Ideally we’d like to use azurerm_data_factory_pipeline resource to manage the pipelines. Sadly, at the time of writing, we couldn’t just use azurerm_data_factory_pipeline since its field variables only allows for the map of string. Our pipelines, on the other hand, used variables of type array. To work around the bug, we used null_resource. Please note that this is only a temporary workaround and should not be used unless needed. When the bug will be fixed, this blog will be updated with the proper solution.
The null_resource workaround
locals {
...
tmp_files_location = ".terraform/tmp"
data_factory_name = "DATA_FACTORY_NAME"
rg_name = "RESOURCE_GROUP_NAME"
tenant_id = "YOUR_TENANT_ID"
}resource "null_resource" "pipelines" {
for_each = local.pipelines
triggers = {
on_change = "${md5(jsonencode(each.value))}"
tenant_id = local.tenant_id
data_factory_name = local.data_factory_name
pipeline_name = each.value.name
data_factory_resource_group_name = local.rg_name
}
provisioner "local-exec" {
when = create
command = <<-EOC
az login --service-principal -u $ARM_CLIENT_ID -p $ARM_CLIENT_SECRET --tenant "${local.tenant_id}"
az account set --subscription $ARM_SUBSCRIPTION_ID
az datafactory pipeline create --factory-name "${local.data_factory_name}" --name "${each.value.name}" --resource-group "${local.rg_name}" --pipeline @${path.root}/pipeline/${each.value.name}.json
EOC
interpreter = [
"bash",
"-c"
]
}
provisioner "local-exec" {
when = destroy
command = <<-EOC
az login --service-principal -u $ARM_CLIENT_ID -p $ARM_CLIENT_SECRET --tenant "${self.triggers.tenant_id}"
az account set --subscription $ARM_SUBSCRIPTION_ID
az datafactory pipeline delete --factory-name "${self.triggers.data_factory_name}" --name "${self.triggers.pipeline_name}" --resource-group "${self.triggers.data_factory_resource_group_name}" -y
EOC
interpreter = [
"bash",
"-c"
]
}
}We decided to not use azurerm_data_factory_pipeline at all, even for the initial resource creation. Mixing these two approaches would bring even more issues to the table. The main one is - having to use timestamp() trigger on null_resource and effectively re-create pipelines on every apply.
Using only null_resource allowed us to use md5 as a trigger in order to re-create pipelines once their file content changes. This approach means that we also need an ‘on destroy’ condition to delete pipelines when we run terraform destroy. As a consequence, we had to define variables in the trigger block as destroy-time provisioners cannot access external variables.
Once again, this is a workaround which will be removed once azurerm_data_factory_pipeline will support complex variables.
Conclusion
These snippets should give you a good starting point if you want to have advantages of both Git and Infrastructure As a Code. Of course, this is not universal and your use case might require some adjustments, but feel free to experiment. Nevertheless, as with all solutions, this approach has its pros and cons:
Pros
- It’s possible to deploy and rollback any version/tag of your pipelines
- Same as with Git mode integration:
- All the crucial workflows are stored in the source control
- It allows for incremental changes of data factory resources regardless of what state they are in
Cons
- It’s not possible to use multiple branches on the same ADF instance
- Engineers have to have the same environment variables exported on their local machine as the build agent if they want to test it locally
As mentioned before, the workaround is just a temporary fix until Azure comes with a solution for the bug. When they do, null_resource part should not be necessary anymore.
Written by
Valerii Matveev




Contact