Blog
Putting the Factory in Azure Data Factory: Dynamically generated Pipelines

Azure Data Factory (ADF) is a commonly used, managed Azure service that allows users to define (data) pipelines. These pipelines vary in their complexity from very simple data fetching logic to complicated pipelines that require significant effort to build and maintain. One of the challenges we often encounter is that of dynamically generating ADF entities (e.g. pipelines, triggers, datasets). In this post, we'll take a look at a few of the options we've seen used in various settings and compare them to see which approach makes most sense for you.
Why do we want Dynamically generated Pipelines?
Before we dive into how we approached this problem, it's important to actually explain why we want these Dynamically generated Pipelines, and what exactly we mean with this term. In ADF, all pipelines are stored in Azure Resource Manager (ARM) templates. These templates are written in JSON and can be either written manually (which is rather tedious) or extracted via the Azure UI. Generally speaking, if you interact with Azure in any way, chances are that your command (whether it's an az cli or azure powershell command) translates to a REST call, which in turn creates the ARM templates.
While powerful, ARM templates require extensive knowledge of Azure (components). We want to control our pipelines with something that's easy to understand without any ADF knowledge. A good example is YAML;
meta:
name: my_data
trigger:
frequency: daily
dataFlowSettings:
source:
dataset: source_dataset
landing:
dataset: landing_dataset
path: "dbfs:/landing"
ingested:
dataset: ingested_dataset
path: "dbfs:/datalake"
dataDefinitions:
tables:
- table: my_table
schema: my_schema
database: my_database
target:
uniqueIdColumns:
- id
database: target_database
table: target_table
columns:
- source:
name: id
type: VARCHAR2(3)
target:
name: id
type: string
nullable: false
- source:
name: value
type: VARCHAR2(4)
target:
name: value
type: string
nullable: trueThis YAML provides the information necessary to perform a number of steps in ADF:
- Fetch the data from the source database
- Place the data in the landing zone
- Ingest the data into our Data Lake using the schema information provided
In addition to this, the YAML file requires little to no knowledge of ADF, making it possible to ask less technically inclined people to provide this kind of configuration. This can be especially helpful within organizations where these less technically-inclined people have the largest amount of domain knowledge, which is invaluable when ingesting data.
Apart from the fact that writing ARM templates isn't a lot of fun, we also often see that a lot of pipelines are very similar. Being programmers at heart, this piques our interest, as it suggests that we can somehow parameterise a single pipeline, and re-use this pipeline with different parameters. This is what we mean by dynamically generated pipelines: Instead of requiring each pipeline to be a bespoke, custom one, we re-use pipelines and parameterise them with any data-source-specific configuration required.
ADF does offer support for Pipeline Templates, but these are somewhat limited in functionality. When creating a new pipeline instance with a given Pipeline Template, ADF makes a full copy of the Template. This means that if the Template changes, any changes would need to be manually reflected in the pipeline instance. Unfortunately, there is no clear and obvious mechanism to ensure synchronization between Template and instance. This would mean that if a template needs to be changed for some reason and you want to see these changes reflected in the pipeline instances, you would need to recreate all pipeline instances.
What are we trying to achieve?
What we want is:
- Configuration of pipelines is stored in version control, in some easy-to-read format. For the scope of this blogpost, we'll narrow this down to YAML but you can use any file-format you like.
- Creation and removal of pipelines should be automated based on the configuration mentioned in point 1
- Updating of pipelines should be easy. Instead of having to change N pipelines, we want to be able to change the template, which is then automatically reflected in the pipelines.
What are our options?
Although the need for dynamically generated pipelines tends to be common, there is more than one way to approach this. Each of these approaches has good and bad sides, and the right option for you will depend on your situation. To structure the discussion, we've split the options over two categories:
- Templating Options This covers how the pipeline configuration is read from files and used to dynamically create the ADF pipelines.
- Deployment Options Once the pipelines have been rendered, there are also still a number of ways to actually deploy the created pipelines to ADF. This choice has implications and therefore warrants some extra attention.
Templating Options
We will make heavy use of Jinja2 for the templating. Jinja is a very nice templating engine that allows us to inject values into document templates to produce the final document.
Our goal is to take some YAML and, together with prepared Jinja-templated ARM templates generate the appropriate ARM templates. The Jinja rendering itself is very simple. In pseudo-python it's something like this:
for config_file in path:
# load the yaml
config = load_yaml_config(config_file)
# render the jinja template with the config from yaml
with open(jinja_template) as file:
template = Template(file.read())
rendered_template = template.render(**config)
# write out the final document (e.g. ARM template)
with open(target_path) as target:
target.write(rendered_template)There are two main options for this in terms of what to template
Option 1: Full pipeline templating
The first, and perhaps most obvious approach, is to render each and every pipeline independently. This means a 1-to-1 mapping from each YAML configuration file to each ADF pipeline. The advantage of this approach is that by separating each pipeline in ADF, they are easier to monitor individually. As an example, we use the YAML shown above and combine it with a Jinja-templated pipeline to create a fully rendered ADF pipeline. The pipeline is a simple, yet relevant, one that fetches data from an Oracle database, stores this in a landing zone, and then triggers a Databricks job to ingest the data into the data lake.
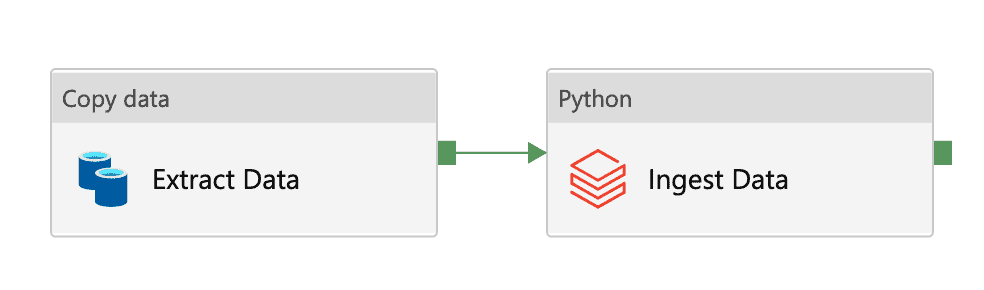
Please note that due to the verboseness of the ARM templates, we have chosen to exclude parts that are not relevant for this blogpost. As such, these examples are not expected to work out of the box in ADF.
{
"name": "{{ meta['name'] }}_pipeline",
"properties": {
"activities": [
{
"name": "Extract Data",
"type": "Copy",
"typeProperties": {
"source": {
"type": "OracleSource",
"oracleReaderQuery": {
"value": "@variables('Query')",
"type": "Expression"
},
"queryTimeout": "02:00:00"
},
},
"inputs": [
{
"referenceName": "{{ dataFlowSettings['source']['dataset'] }}",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "{{ dataFlowSettings['landing']['dataset'] }}",
"type": "DatasetReference"
}
]
},
{
"name": "Ingest Data",
"type": "DatabricksSparkPython",
"dependsOn": [
{
"activity": "Extract Data",
"dependencyConditions": [
"Succeeded"
]
}
],
"typeProperties": {
"pythonFile": "dbfs:/my_ingestion_script.py",
"parameters": [
"--source_path",
" dataFlowSettings['landing']['path'] ",
"--data_schema",
"{{ dataDefinitions['tables'] }}"
"--target_path",
"{{ dataFlowSettings['ingested']['path'] }}",
]
}
}
]
}
}Combining this Jinja-templated ADF Pipeline with the YAML shown gives us the following "final" ARM template for our ADF pipeline:
{
"name": "my_data_pipeline",
"properties": {
"activities": [
{
"name": "Extract Data",
"type": "Copy",
"typeProperties": {
"source": {
"type": "OracleSource",
"oracleReaderQuery": {
"value": "@variables('Query')",
"type": "Expression"
},
"queryTimeout": "02:00:00"
},
},
"inputs": [
{
"referenceName": "source_dataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "landing_dataset",
"type": "DatasetReference"
}
]
},
{
"name": "Ingest Data",
"type": "DatabricksSparkPython",
"dependsOn": [
{
"activity": "Extract Data",
"dependencyConditions": [
"Succeeded"
]
}
],
"typeProperties": {
"pythonFile": "dbfs:/my_ingestion_script.py",
"parameters": [
"--data_path",
"dbfs:/landing",
"--data_schema",
"[{'table':'my_table','schema':'my_schema','database':'my_database','target':{'uniqueIdColumns':['id'],'database':'target_database','table':'target_table'},'columns':[{'source':{'name':'id','type':'VARCHAR2(3)'},'target':{'name':'id','type':'string','nullable':false}},{'source':{'name':'value','type':'VARCHAR2(4)'},'target':{'name':'value','type':'string','nullable':true}}]}]"
"--target_path",
"dbfs:/datalake",
]
}
}
]
}
}While the actual replacement is trivial this is very powerful when working with many different data sources that all require similar (or perhaps identical) steps. Instead of bundling all datasets into one pipeline (which makes failure handling and retrying a pain) this neatly gives you a separate pipeline for each data source you configure. In this example, we're using a Pipeline ADF resource, but the same logic and approach can of course also be applied to other ADF resource types (e.g. Datasets, Triggers, etc.). This leads us nicely to the other option...
Option 2: Trigger-only templating
A somewhat hidden feature in ADF is the ability to parameterize Triggers. Triggers are normally used to specify what event should result in a pipeline run. The parameterization of Triggers is hidden in the sense that it does not show up if you create a Trigger via the 'Manage' UI, but does if you create a Trigger directly from the Pipeline 'Author' UI (if your Pipeline has parameters)
Using this 'hidden' feature, the approach would be to create a single pipeline that is configurable via ADF pipeline parameters. The values for these parameters are set in the ADF Triggers. The templating mechanism is similar to that used for the full pipeline templating option described above, but does mean you will have a single ADF pipeline which takes parameters to distinguish between datasets. This makes monitoring slightly different, as you are dependent on the Trigger name rather than the Pipeline name.
{
"name": "{{ meta['name']}}_trigger",
"properties": {
"annotations": [],
"runtimeState": "Stopped",
"pipelines": [
{
"pipelineReference": {
"referenceName": "singleton_pipeline",
"type": "PipelineReference"
},
"parameters": {
"source_dataset": "{{ dataFlowSettings['source']['dataset']}}",
"landing_dataset": "{{ dataFlowSettings['landing']['dataset'] }}",
"landing_path": "{{ dataFlowSettings['landing']['path'] }}",
"ingested_path": "{{ dataFlowSettings['landing']['path'] }}",
"data_schema": "{{ dataDefinitions['tables'] }}"
}
}
],
"type": "ScheduleTrigger",
"typeProperties": {
"recurrence": {
"frequency": "Minute",
"interval": 15,
"startTime": "2021-12-10T12:04:00Z",
"timeZone": "UTC"
}
}
}
}The main difference is how the YAML configuration is passed. The rendering is plain Jinja. In this case, however, we render the values into a Trigger, which then passes the values onto a singleton pipeline as parameters. This pipeline then uses these parameters to perform the desired logic.
Deployment Options
Once we've created our ARM Pipelines/Triggers, we'll need to get them into ADF (you can't do this rendering within ADF unfortunately). In order to do this, we have identified 2 approaches, though there are undoubtedly more.
Option 1: Terraform
One option to deploy the pipelines once they've been templated is to use Terraform. Terraform is a popular infrastructure-as-code tool that allows developers to write declarative configuration to deploy and manage their infrastructure. There is also good support for various Azure services, including Azure Data Factory. The code for a single pipeline would be something like this:
resource "azurerm_data_factory_pipeline" "test" {
name = "acctest%d"
resource_group_name = azurerm_resource_group.test.name
data_factory_name = azurerm_data_factory.test.name
activities_json = <<JSON
[
{
"name": "Append variable1",
"type": "AppendVariable",
"dependsOn": [],
"userProperties": [],
"typeProperties": {
"variableName": "bob",
"value": "something"
}
}
]
JSON
}Terraform uses state to store its view of the world while comparing it with what's in place on Azure. This also means that it will take care of all CRUD operations on your ADF resources, so you don't need to manually remove/create pipelines. Deploying your pipeline in this way is very easy to integrate into any existing Terraform code and can be integrated well into CI/CD pipelines. One downside of this approach is that it does automatically put ADF in live mode rather than git-backed mode (docs). This means that any changes you might make in the ADF UI are not stored in a git repository. Having said that, it doesn't mean that your code isn't in git. Your YAML, rendered ARM resources and your Terraform is still safely stored in git.
Option 2: Pre-commit hook
The major downside of using Terraform to deploy your templated pipelines is that it forces you to use ADF live mode. While this may be acceptable for some use cases, the git support can be very useful in many situations. To get around this limitation, one approach is to actually run the templating functionality before every commit. As we're engineers and like automation, this can then be put into a pre-commit hook. This template rendering can be seen as a 'compilation' step of sorts. By integrating it into a pre-commit hook, we get a few nice things:
- We keep the git-backing in place for ADF, allowing for version controlled ADF resources.
- We don't need any magic hackery where a CI/CD pipeline needs to push into any repository independently.
- The pipeline rendering is still automated, and can't be accidentally forgotten by the user.
Your pre-commit script could be something like this:
python render_adf_resources.py
git --no-pager diff --name-only adf_resources
git add adf_resourcesThe main downside of this approach is that it's generally considered bad practice to change the contents of a git commit from a pre-commit hook. It means that your git configuration setup actually edits your commit after you have authored it, which can lead to questionable results. In this case, the only directories affected are those used directly by ADF, but the point is still valid.
So, which option is the 'winner'?
It depends! :-) Each option has upsides and downsides, and you'll need to balance the features that are most important for you. We hope this blogpost helps and inspires you to make this choice and we're curious to hear about your own creative solutions to this problem.
Our Ideas
Explore More Blogs




Contact