Blog
adfPy: an intuitive way to build data pipelines with Azure Data Factory

In a previous post, we took a look at how to dynamically generate Azure Data Factory (ADF) resources. In that approach, our base premise was to use YAML files containing configuration to generate ADF pipelines using a custom Python script with Jinja2 templating. While it worked, it was still a bit cumbersome and presented some problems in terms of development flow. In this post, we'll be showing how adfPy, an open source project, solves most of these problems and aims to make the development experience of ADF much more like that of Apache Airflow.
Recap: Why do we want to do this?
Dynamically generating data pipelines is something that many of us will want to do at some point when working with any pipeline orchestration tool, be it Azure Data Factory or something else. It reduces the amount of work needed to add new data pipelines (for adding new data source ingestion pipelines for example), and it ensures that all pipelines behave in a similar way. Moreover, the configuration we propose to use tends to be easier to understand and work with for non-technical people. As in our previous post, we will look at a relatively simple example:
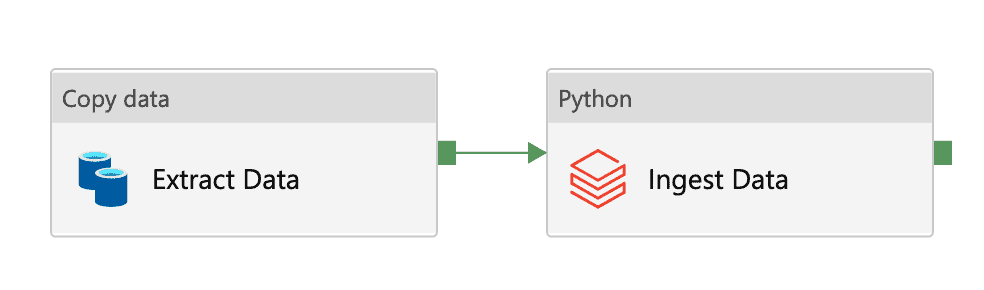
In words, this pipeline performs the following steps:
- Fetch the data from the source database
- Place the data in the landing zone
- Ingest the data into our Data Lake using the schema information provided
The configuration for this is YAML, and looks as follows:
meta:
name: my_data
trigger:
frequency: "@daily"
dataFlowSettings:
source:
dataset: source
landing:
dataset: landing
path: "dbfs:/landing"
ingested:
dataset: ingested
path: "dbfs:/datalake"
dataDefinitions:
tables:
- table: my_table
schema: my_schema
database: my_database
target:
uniqueIdColumns:
- id
database: target_database
table: target_table
columns:
- source:
name: id
type: VARCHAR2(3)
target:
name: id
type: string
nullable: false
- source:
name: value
type: VARCHAR2(4)
target:
name: value
type: string
nullable: trueUsing this information, we want to be able to programmatically generate the ADF pipeline. Re-iterating the requirements from our previous blogpost:
- Configuration of pipelines is stored in version control, in some easy-to-read format. For the scope of this blogpost, we’ll narrow this down to YAML but you can use any file-format you like.
- Creation and removal of pipelines should be automated based on the configuration mentioned in point 1
- Updating of pipelines should be easy. Instead of having to change N pipelines, we want to be able to change the template, which is then automatically reflected in the pipelines.
Introducing adfPy
adfPy is an open source Python package that enables you to interact with Azure Data Factory in an elegant, pythonic way. It also includes tooling to ensure reliable deployment of your ADF resources to ADF (including removal). Its syntax has been made to mimic that of Apache Airflow as much as possible, as this allows for clean pipeline definitions in code.
Azure Data Factory Python SDK
Azure has a Python SDK available for ADF. It is, however, rather verbose and not very nice to work with. To create the pipeline discussed above, the required code would be:
import os
import pathlib
from datetime import datetime
import yaml
from azure.identity import ClientSecretCredential
from azure.mgmt.datafactory import DataFactoryManagementClient
from azure.mgmt.datafactory.models import (
BlobSink,
OracleSource,
CopyActivity,
DatasetReference,
DatabricksSparkPythonActivity,
PipelineResource,
PipelineReference,
ActivityDependency,
ScheduleTrigger,
ScheduleTriggerRecurrence,
TriggerResource,
TriggerPipelineReference
)
def load_yaml(path):
with open(path, 'r') as file:
return yaml.safe_load(file)
config = load_yaml(f"{pathlib.Path(__file__).parent}/pipeline_config.yml")
dataFlowSettings = config["dataFlowSettings"]
dsin_ref = DatasetReference(reference_name=dataFlowSettings["source"]["dataset"])
dsOut_ref = DatasetReference(reference_name=dataFlowSettings["landing"]["dataset"])
extract = CopyActivity(name='Extract data',
inputs=[dsin_ref],
outputs=[dsOut_ref],
source=OracleSource(),
sink=BlobSink())
ingestion_parameters = [
"--source_path",
dataFlowSettings['landing']['path'],
"--data_schema",
config["dataDefinitions"]['tables'],
"--target_path",
dataFlowSettings['ingested']['path']
]
ingest = DatabricksSparkPythonActivity(
name="Ingest Data",
python_file="my_ingestion_script.py",
parameters=ingestion_parameters,
depends_on=[ActivityDependency(activity="Extract data", dependency_conditions=["Succeeded"])])
subscription_id = os.environ["AZURE_SUBSCRIPTION_ID"]
resource_group = os.environ["AZURE_RESOURCE_GROUP_NAME"]
data_factory = os.environ["AZURE_DATA_FACTORY_NAME"]
credentials = ClientSecretCredential(
client_id=os.environ["AZURE_SERVICE_PRINCIPAL_CLIENT_ID"],
client_secret=os.environ["AZURE_SERVICE_PRINCIPAL_SECRET"],
tenant_id=os.environ["AZURE_TENANT_ID"],
)
adf_client = DataFactoryManagementClient(credentials, subscription_id)
pipeline = PipelineResource(activities=[extract, ingest])
trigger_scheduler_recurrence = ScheduleTriggerRecurrence(frequency="Day",
interval=1,
start_time=datetime.now(),
time_zone="UTC")
trigger = TriggerResource(
properties=ScheduleTrigger(recurrence=trigger_scheduler_recurrence,
pipelines=[TriggerPipelineReference(
pipeline_reference=PipelineReference(
reference_name=f"{config['meta']['name']}-native"))],
)
)
pipeline_create_output = adf_client.pipelines.create_or_update(resource_group,
data_factory,
f"{config['meta']['name']}-native",
pipeline)
trigger_create_output = adf_client.triggers.create_or_update(resource_group,
data_factory,
f"{config['meta']['name']}-native-trigger",
trigger)
Moreover, even if you have this code, it still will not delete resources if you were to remove the code from your codebase. All of these features are taken care of by adfPy, as will be shown below.
Defining your Pipeline
To define exactly the same pipeline with adfPy, the code would look like this:
import pathlib
import yaml
from azure.mgmt.datafactory.models import BlobSink, OracleSource
from adfpy.activities.execution import AdfCopyActivity, AdfDatabricksSparkPythonActivity
from adfpy.pipeline import AdfPipeline
def load_yaml(path):
with open(path, 'r') as file:
return yaml.safe_load(file)
config = load_yaml(f"{pathlib.Path(__file__).parent}/pipeline_config.yml")
dataFlowSettings = config["dataFlowSettings"]
extract = AdfCopyActivity(
name="Extract data",
input_dataset_name=dataFlowSettings["source"]["dataset"],
output_dataset_name=dataFlowSettings["landing"]["dataset"],
source_type=OracleSource,
sink_type=BlobSink,
)
ingestion_parameters = [
"--source_path",
dataFlowSettings['landing']['path'],
"--data_schema",
config["dataDefinitions"]['tables'],
"--target_path",
dataFlowSettings['ingested']['path']
]
ingest = AdfDatabricksSparkPythonActivity(name="Ingest Data",
python_file="my_ingestion_script.py",
parameters=ingestion_parameters)
extract >> ingest
pipeline = AdfPipeline(name=config["meta"]["name"],
activities=[extract, ingest],
schedule=config["meta"]["trigger"]["schedule"])There are a few things of interest here:
- The trigger is now directly fetched from the YAML, and immediately connected to the Pipeline.
- Dependencies between tasks are very easily set using the bitshift operators (
>>or<<), similar to the approach taken in Apache Airflow. - There is no mix of pipeline definition and deployment logic here. To deploy the adfPy pipeline, you would use the
adfpy-deployCLI (see below). This also makes integrating the deployment into a CI/CD pipeline considerably easier. - adfPy strips down a lot of the internal Azure SDK's class hierarchy to obfuscate most of this from the pipeline developer. This makes life (and the code) considerably easier to read and write.
- For the sake of transparency, all adfPy resources are named after native SDK entities prefixed with
Adf. In that way, it's always easy to understand what ADF resource will be created by any adfPy resource.
Deploying your Pipeline
Once you've defined your adfPy resources, you'll want to deploy them to ADF. To do this, you can make use of the included deploy CLI:
adfpy-deploy --path my_pipelines/This does a couple of things:
- Parses all adfPy resources found in the provided path (
my_pipelinesin this case). - For each resource: either create or update the equivalent native ADF resource.
- Any resources that are found in ADF that are not in the provided path will be deleted. This is optional behaviour intended to make your codebase serve as the single source of truth and avoid drift. This can be disabled or further configured to suit your use case.
It's worth noting that if you use either the native Azure SDK or adfPy to deploy/manage your ADF resources in this way, you cannot use GIT mode anymore. This means that you will be using live mode in the Azure Portal. In our opinion, this is not necessarily problematic, as management of your resources is pushed into code, making it much easier to work with programmatically.
Customizing adfPy
While adfPy aims to be 'batteries-included', we appreciate that we can't cover all use cases. Moreover, allowing users to add and customize (pipeline) components to suit their use cases better is, in our view, a strength rather than a weakness. To this end, we fully support the customization and extension of adfPy. To add a custom Activity, simply extend the AdfActivity class (code). The same holds for the AdfPipeline class and other Adf* classes included in adfPy. Of course, we welcome contributions, so if you believe your custom Activity may be useful to other, we would be more than happy to see a Pull Request to add this functionality.
Caveats
There are a few things to note regarding the use of adfPy:
- Currently a limited subset of activities has been implemented. It's relatively easy to extend adfPy with your own activities, however, and more will be added in future.
- At the moment only the ScheduledTrigger type is supported as trigger. Support for other trigger types is on the roadmap.
- Resources like Datasets and/or Linked Services are not included in adfPy at the moment.
Conclusion
adfPy is a pythonic, elegant interface for working with Azure Data Factory. In this post, we looked at a relatively simple ETL pipeline with only 2 activities. We showed the code of the native SDK versus the one offered by adfPy. adfPy is not suited for all environments and use cases and cannot replace ADF's "no-code" interface for developing ETL flows. However, it can be used as a very powerful, code-first approach to developing and managing data pipelines in ADF; something which is considerably harder to do with any other approach.
To learn more about adfPy, take a look at the docs or the repo and feel free to reach out to learn more!
Our Ideas
Explore More Blogs




Contact