
When designing your data lake, there a lot of aspects that guide the design. In this blog we’ll look at how we can compose a data lake from a very small component called a ‘data segment’. Lets take a look!
The Data Segment
The data segment is a small component that is a building block for data lakes.
The data segment provides streaming ingestion, streaming transformation, streaming aggregation and data persistence capabilities. It also provides buffering, data encryption, access control, backup & recovery and message replay capabilities.
The most important aspect of the data segment is that it is highly composable. Lets meet the data segment.
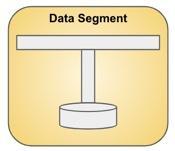
A Data Segment consists of the following three elements:
- A pub-sub channel,
- A wire-tap channel,
- Data persistence
Data Layer
Data segments are grouped into a Data Layer. Each data segment is responsible for a data domain.

Data Lake
A Data Lake is a grouping of data layers and can get arbitrary wide or high. Each Data Layer is fully isolated from other Data Layers.
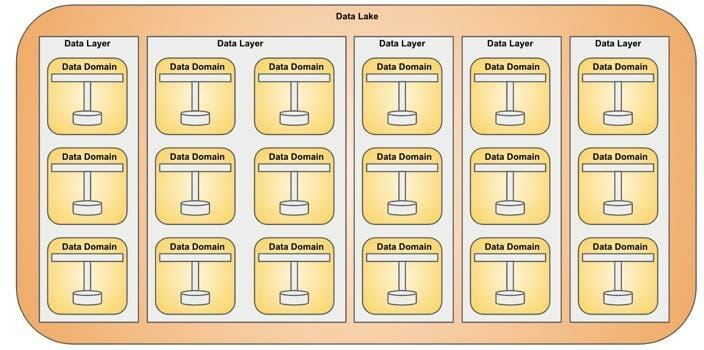
Connecting Data Segments
The Data Lake acts as a platform for Data Segments, and provides infrastructure, message routing, discovery, and connectivity capabilities to Data Segments. Data segments are wired together depending on the message routing requirement.
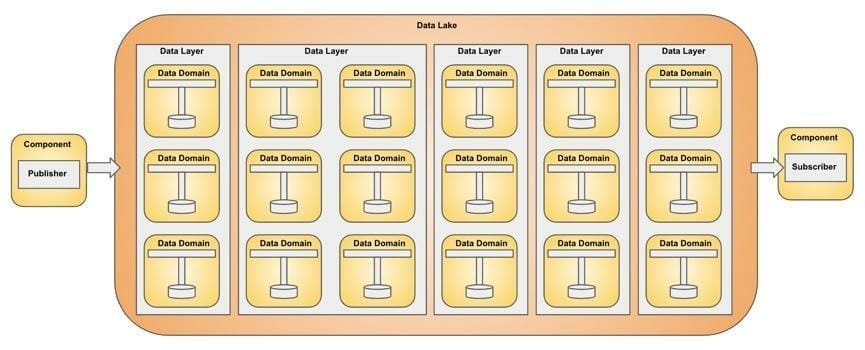
Component Integration
Components like publishers and subscribers integrate with the Data Lake. The Data Lake is responsible for routing the message to the appropriate Data Segment.
Cloud Service Provider
Cloud service providers provide services that are a match for implementing Data Lakes. For example, AWS provides messaging and persistence services that can be used to implement Data Segments and Data Lakes.
AWS Technical Mapping
The Data Lake can be implemented in AWS with the following technical mapping:
| Data Segment Component | Amazon Service (preferred) | Alternative |
| — | — | — |
| pub-sub channel | Amazon Kinesis Stream | Amazon SNS, Amazon SQS |
| write-tap channel | Amazon Kinesis Data Firehose | Amazon Lambda, EMR, Amazon Fargate |
| data persistence | Amazon S3 | Amazon EFS |
CloudFormation Implementation
An implementation of the Data Segment is a CloudFormation desired state configuration shown below. The data segment is consists of Amazon Kinesis Stream for the pub-sub channel, Amazon Kinesis Data Firehose for the wire-tap channel and Amazon S3 for data persistence.
AWSTemplateFormatVersion: '2010-09-09'
content: blog-datasegment
Parameters:
DataSegmentName:
Type: String
Default: example-datasegment
Resources:
DataSegmentRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Statement:
- Effect: Allow
Principal:
Service: firehose.amazonaws.com
Action: sts:AssumeRole
Condition: {}
Path: /
Policies:
- PolicyName: Allow
PolicyDocument:
Statement:
- Effect: Allow
Action:
- s3:*
- kms:*
- kinesis:*
- logs:*
- lambda:*
Resource:
- '*'
DataSegmentBucket:
Type: AWS::S3::Bucket
Deliverystream:
Type: AWS::KinesisFirehose::DeliveryStream
Properties:
DeliveryStreamName: !Sub ${DataSegmentName}-firehose
DeliveryStreamType: KinesisStreamAsSource
KinesisStreamSourceConfiguration:
KinesisStreamARN: !GetAtt KinesisStream.Arn
RoleARN: !GetAtt DataSegmentRole.Arn
ExtendedS3DestinationConfiguration:
BucketARN: !GetAtt DataSegmentBucket.Arn
RoleARN: !GetAtt DataSegmentRole.Arn
Prefix: ''
BufferingHints:
IntervalInSeconds: 60
SizeInMBs: 1
CloudWatchLoggingOptions:
Enabled: true
LogGroupName: !Sub ${DataSegmentName}-s3-firehose
LogStreamName: !Sub ${DataSegmentName}-s3-firehose
CompressionFormat: UNCOMPRESSED
KinesisStream:
Type: AWS::Kinesis::Stream
Properties:
Name: !Sub ${DataSegmentName}-stream
ShardCount: 1
CloudWatchLogGroup:
Type: AWS::Logs::LogGroup
Properties:
LogGroupName: !Sub ${DataSegmentName}-s3-firehose
RetentionInDays: 30
CloudWatchLogStream:
Type: AWS::Logs::LogStream
DependsOn:
- CloudWatchLogGroup
Properties:
LogGroupName: !Sub ${DataSegmentName}-s3-firehose
LogStreamName: !Sub ${DataSegmentName}-s3-firehose
Outputs:
KinesisStreamName:
content: The name of the KinesisStream
Value: !Ref KinesisStream
KinesisStreamArn:
content: The ARN of the KinesisStream
Value: !GetAtt KinesisStream.Arn
DeliveryStreamName:
content: The name of the Deliverystream
Value: !Ref Deliverystream
DeliveryStreamArn:
content: The arn of the Deliverystream
Value: !GetAtt Deliverystream.Arn
BucketName:
content: THe name of the DataSegmentBucket
Value: !Ref DataSegmentBucket
A Publisher
The publisher is easy to implement with Go:
package main
import (
"github.com/binxio/datasegment/common"
"os"
)
func main() {
streamName := os.Getenv("KINESIS_STREAM_NAME")
if streamName == "" {
panic("KINESIS_STREAM_NAME not set")
}
partitionKey := "1"
sess := common.GetSession()
common.PutRecords(streamName, partitionKey, common.GetKinesis(sess))
}
A Subscriber
A subscriber is easy to implement with Go:
package main
import (
"github.com/binxio/datasegment/common"
"os"
)
func main() {
streamName := os.Getenv("KINESIS_STREAM_NAME")
if streamName == "" {
panic("KINESIS_STREAM_NAME not set")
}
shardId := "0" // shard ids start from 0
sess := common.GetSession()
common.GetRecords(streamName, shardId, common.GetKinesis(sess))
}
Common
The publisher and subscriber needs some common logic.
package common
import (
"encoding/hex"
"encoding/json"
"fmt"
"github.com/aws/aws-sdk-go/aws"
"github.com/aws/aws-sdk-go/aws/session"
"github.com/aws/aws-sdk-go/service/kinesis"
"log"
)
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
}
func GetSession() *session.Session {
sess, err := session.NewSession()
if err != nil {
panic(err)
}
return sess
}
func GetKinesis(sess *session.Session) *kinesis.Kinesis {
return kinesis.New(sess, aws.NewConfig().WithRegion("eu-west-1"))
}
func CreatePerson(name string, age int) Person {
return Person{Name: name, Age: age}
}
func SerializePerson(person Person) []byte {
data, err := json.Marshal(person)
if err != nil {
panic(err)
}
return []byte(string(data) + "n")
}
func CreateRecord(streamName string, partitionKey string, data []byte) *kinesis.PutRecordInput {
return &kinesis.PutRecordInput{
PartitionKey: aws.String(partitionKey),
StreamName: aws.String(streamName),
Data: data,
}
}
func PutRecords(streamName string, partitionKey string, svc *kinesis.Kinesis) {
for i := 0; i < 100000; i++ {
person := CreatePerson(fmt.Sprintf("dennis %d", i), i)
data := SerializePerson(person)
record := CreateRecord(streamName, partitionKey, data)
res, err := svc.PutRecord(record)
if err != nil {
panic(err)
}
log.Println("Publishing:", string(data), hex.EncodeToString(data), res)
}
}
func ProcessRecords(records *[]*kinesis.Record) {
for _, record := range *records {
log.Println(string(record.Data))
}
}
func GetNextRecords(it *string, svc *kinesis.Kinesis) {
records, err := svc.GetRecords(&kinesis.GetRecordsInput{
ShardIterator: it,
})
if err != nil {
panic(err)
}
ProcessRecords(&records.Records)
GetNextRecords(records.NextShardIterator, svc)
}
func GetRecords(streamName string, shardId string, svc *kinesis.Kinesis) {
it, err := svc.GetShardIterator(&kinesis.GetShardIteratorInput{
StreamName: aws.String(streamName),
ShardId: aws.String(shardId),
ShardIteratorType: aws.String("TRIM_HORIZON"),
})
if err != nil {
panic(err)
}
GetNextRecords(it.ShardIterator, svc)
}
Example
The example project shows an implementation of a Data Segment in AWS. The example can be created with ‘make create’ and deleted with ‘make delete’. To publish messages type ‘make publish’ and to launch one or more subscribers type: ‘make subscribe’.
Conclusion
The Data Segment is a primitive for creating Data Lakes. The abstraction helps in many ways, for determining the boundaries for data domains, for grouping data domains in layers and for isolating layers. Data segments provide real-time capabilities to the data lake by means of pub-sub messaging channels.
Data Segments make real-time stream processing possible by means of a back plane that the Data Lake provides. Data Segments plug into the back plane and receive data from and provide data to the Data Lake.
Data Segments can be added and removed arbitrarily which allows for a dynamically sized Data Lake. The real-time aspect by means of pub-sub makes the architecture ideal for designing real-time stateful applications like data platforms.
Written by
Dennis Vriend
Our Ideas
Explore More Blogs




Contact