What is NodeJS? The NodeJS five-word sales pitch from their own website is “Evented I/O for V8 Javascript”. We’ll get to what that means exactly in the How. NodeJS, in a few more words, is a server-side application framework with a focus on high concurrent performance. Applications written for Node run in a single-threaded, event-based process. Node is an open source project initially conceived and developed by Ryan Dahl in early 2009, and has been in active development ever since. Joyent, Dahl’s employer, is backing and sponsoring the project.
Before we go in-depth, let’s explain what’s probably the core point of NodeJS - event-based I/O.
Historically, you write a simple application like this:
puts(“Please enter your name: “); var name = gets(); puts(“Hello, “ + name);
The core part of this is the “gets()” call. What it effectively does is block the whole application until the user enters some data. Often, data is retrieved from external sources like databases in a similar fashion:
var results = db.query(“select x from y”);
The program, like when using gets(), will hold at this line until the db.query() method returns, which in turn contacts the database server, fires the query, and waits for the response. The key words in this are ‘hold’ and ‘waits’ - the program, effectively, twiddles its thumbs while waiting for user input or a response from the database server. Event-based programming approaches this in a different matter. When calling the blocking operation, you pass it an additional argument: a block of code to execute when the operation has completed. Instead of waiting for a reply from the user or the database, the application continues its execution. This flow is pretty easy with Javascript. Here’s how the two operations above look like when written in an event-based fashion in Javascript:
puts("Enter your name: ");
gets(function (name) {
puts("Hello, " + name);
});
db.query("select x from y", function (result) {
// use result
});
The important part is the extra argument you pass to the blocking methods. You’re basically telling the method: “Okay, you do this, and when you’re done, execute this method”. Meanwhile, the ‘main’ application continues to run while a background process waits for user input or the database to return its result. When the above is executed, the process will execute the query and process its result even while it waits for user input. Similarly, it can process the entered user input while it’s still waiting for the database query to return a result. NodeJS is built around this approach. Because it never blocks when doing I/O, it executes code quickly. We’ll go for a more in-depth look at this in the Why section.
Why
Why evented I/O? The short answer: Latency. Take a look at the following table, which lists the amount of CPU cycles it takes to access data:
| L1 cache | 3 cycles |
| L2 cache | 14 cycles |
| RAM | 250 cycles |
| DISK | 41,000,000 cycles |
| NETWORK | 240,000,000 cycles |
What does this mean? Effectively, it means that classic, blocking processes twiddle their thumbs for 41,000,000 CPU cycles while waiting for something from disk to load. Those processes can’t do anything else while they twiddle their thumbs, so in the case of a webserver, other requests get paused until the application has received its data. The classic solution for this problem: Add moar processes. When one process twiddles its thumbs waiting for data, the other process can take over and handle the next request. With 200 processes available for handling requests, consumers never have to wait long in the queue for their request to be handled by the next freed process. But it has its limits. Hard limits, even, which have been the source of many outages in the past. What if there’s a big delay on the network for whatever reason? What if there’s more new requests coming in per second than the database can process? The 200 processes each block once they reach the point where they retrieve data from the network, and once they’re all occupied, the webserver simply stops serving requests, users time out, and Twitter trends with messages like “IS #SOMESITE.COM DOWN? #FML”. How does Node solve this? Well, to put it simply, it doesnt’t twiddle its thumbs. It goes ‘Alright underlying system, give me this information from the network. I’ll go do something useful, lemme know when you’re done aight? Aight.’ And then it proceeds to do something useful, like handle the next request. It’s the ‘lemme know when you’re done’ that contains the core of NodeJS’s performance. Instead of waiting for something to be retrieved (blocking), it continues to run (non-blocking). No precious CPU cycles get wasted that way waiting. Because it doesn’t block, there’s also a greatly reduced need for running multiple processes. It just keeps going, regardless of how many requests it has to handle. When it receives a bazillion requests, it doesn’t run out of processes or some other arbitrary limit, it just handles each one, one by one. It handles each event as it’s triggered, one at a time, and it does so very rapidly. It’s like ordering food. You step up to the counter of your local fast food store, and order a hamburger. Classically, you stand there and wait until the chef is done and the person serving gives you your order, while others queue up neatly behind you. In the multi-threaded approach, the store hires more serving personnel and chefs that can each handle one customer at a time. In the non-blocking approach, the servant smiles, says “Alright sir, please pick a seat, your order will be brought to you when it’s done. Next!”. And so it continues. The servant passes the order to the kitchen, the kitchen prepares your burger, and a pretty serving girl brings you your hamburger when it’s done. The queue passes the counter quickly, because everything the servant does is take the people’s order and pass it along. If only fast food stores actually worked like this.
Why Javascript?
You write NodeJS in Javascript, and a significant part of the Node standard library is written in Javascript as well. Why’s that? What makes Javascript the best solution for this problem? It’s not like Javascript is the only language with first-class functions, closures, etcetera. There’s a few reasons for this that I know of, and there’s probably more that I don’t mention. First, event handling, callbacks and asynchronous behavior are at its core. It’s been used in this fashion for years in its natural habitat, the browser. Opening a file or network resource and passing that method a callback isn’t that different from triggering an AJAX-call with a callback - in fact, it’s exactly the same. The browser is inherently asynchronous, as pretty much every piece of logic relies on user input, network I/O, or something simpler as a timed event - each of those would block the execution of the script if it was done with blocking operations, and that’s the last thing you want in a user-experience heavy application like a webbrowser. Event handling is at the core of both Javascript as a language and as a way of thinking for Javascript developers, which is another important reasoning behind using Javascript: It’s familiar to many developers. Javascript is a bit of a ninja amongst programming languages - most people don realize it’s one of the most-used programming languages out there. Its popularity has boosted significantly over the last decade, with the rise of AJAX, highly interactive and responsive web applications, streaming updates, and big companies like Google pushing web applications as a primary platform for all kinds of applications. At the core of all that is Javascript. There simply is no other language for client-side development on the web, as opposed to a bazillion languages and frameworks on the server side. Because of this, there’s a huge amount of Javascript knowledge and experience out there, which makes the language itself not a major problem when moving it to the server side. A third, but debatable reason, is that it’s an easy language. No big architectures, deeply-nested object hierarchies, complex syntax, or twenty different syntaxes to achieve effectively the same thing. I don’t want to start a language war though, so I won’t go into this argument further. The final reason I can think of: Code re-use. Node knows Javascript, and so does your browser, so the two sharing code makes a lot of sense. There’s also a third: JSON. A lot of webservices these days offer JSON as an output format, and it’s quite a popular data exchange format. Javascript is JSON, so having it both on the server and clientside is a big plus. Then there’s back-end storage systems like MongoDB, which also employ JSON as a data exchange (and sometimes even storage) language. Nothing makes more sense than using JSON and Javascript together, and the ability to create and handle JSON objects in its native language is very much a plus. With that out of the way, we go to the next question - why is a NodeJS application single-threaded?
Why single-threaded?
I see you thinking. If Node is so fast in a single thread, why not combine the two advantages and make it multi-threaded? Well first off, it wouldn’t be significantly faster, and a better argument, it would make your application (as well as Node itself) a lot more complex. You’d have to deal with multiple threads trying to access the same resource, decide which thread gets to handle the next event, and I’m sure those of you with real-life experience in big, concurrent software can think of a whole list of problems that need to be solved in a multi-threaded application. The advantages of a single-threaded application is that the processor doesn’t have the overhead of context switching (when one thread gets CPU time while the other’s paused). There’s no heap allocations or forks or startup sequences that need to be done when creating a new thread. Besides that, there’s of course the obvious advantage of not needing to program with concurrency in the back of your head. Less headache, less hard-to-track bugs, less specific knowledge and understanding needed, etc. But what about modern-day hardware? The mainstream CPU builders don’t build single-core processors anymore, it’s all fancy dual-, quad-, hexa- and octacores these days, with even more cores and special-purpose components to be added in the nearby future. Well, that’s not a problem. Whilst a Node program is single-threaded, there’s nothing stopping you from creating multiple Node processes and running them side-by-side, each using a single core. Put a loadbalancer or reverse proxy like nginx in front of it , either on the same server or externally, and you’re done. You could even use another Node process as a loadbalancer. Of course, you’d have to be using a back-end storage system that can handle concurrent requests (i.e. from multiple Node processes) in order to be able to do that. So now you know a number of “whys”, and you may wonder the “how” - How does Node achieve all this? We’ll look at that in the next section.
How: Under the hood
So how does it work? What makes the Javascript execute fast enough to compete with other solutions? How does it interact with the system it runs on? NodeJS is built on top of V8, Google’s Javascript engine that also powers the Chrome browser, which sported the fastest Javascript execution speeds and pretty much put Javascript performance right up in front when it came to comparing browsers, turning speed into a major marketing for browsers. But V8 can also run outside of the browser, and, being an open source project, has been extended to create NodeJS. Node adds a thread pool (using libeio), event loop (libevent), and fancy things like DNS resolving and cryptography. On top of that are a bunch of Node bindings for I/O (sockets, HTTP, etc). Finally, a standard library to do pretty much everything you need written in pure Javascript is built on top of that. Have a picture:
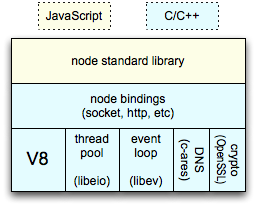
If you’re curious about the inner workings of Node, the Node code is plain old open source and can be cloned out of the Github repository.
A Node application
The pleasant thing about NodeJS is that, effectively, it’s just a script interpreter - you create a .js script, call ‘node script.js’, and it runs. It (probably) compiles the script in the background, but as a developer, you hardly even realize that - it just starts. In your script, you usually set up the environment, load some libraries, and set up a listener of sorts - for example, a HTTP server. Here’s an example of the most basic HTTP webserver, using NodeJS’s own internal library, with comments explaining what each line does:
// Include the HTTP module. NodeJS implements the CommonJS standard for defining
// standalone application modules and libraries.
var http = require('http');
// Create the HTTP server. We pass it a callback function that gets executed whenever
// a request is received.
var server = http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello Worldn');
});
// Start the server, have it listen to incoming connections on the given hostname and port.
server.listen(1337, "127.0.0.1");
// Let the developer know we’re up and running.
console.log('Server running at https://127.0.0.1:1337/');
The above example illustrates a few things: Basic method calls (http.createServer, console.log), passing callback methods (function(req, res)), the Node require system (require ‘http’), and Javascript’s object type to create a map of parameters to return to the caller. This code can be executed simply by calling ‘node app.js’ on the commandline. The message informing the user that the server is running appears, and the server is up and running. It’s really that simple.
When
Now that you know what Node is and what makes it tick, you might have a good idea about where you can use it for. It’s most used as a web application back-end, but you can use it for pretty much any application, although the emphasis will remain on I/O - there’s probably better languages and solutions for, for example, scientific calculations or business rule processing or whatever else. In practice though, many of today’s (web) applications fall into the I/O category - users requesting data, users adding and editing data. NodeJS is not a golden hammer. It’s not the best-performing solution, it’s not the one-size-fits-all solution, and I don’t recommend you shoehorn it into your next project just because I’m telling you it’s awesome. With that out of the way, here’s a few use cases Node can be used for and can excel at:
- Generic web framework. It’s got all the things you need - server-side logic, connectors for back-end systems (like databases), file serving, template parsing (with a wide variety of template languages), authentication, you name it.
- Highly concurrent websites - high-volume webservices, varying loads, etc.
- Highly concurrent connections - for example, websockets with many clients sending and receiving data.
- Back-end systems dealing with files. Example: GitHub’s Nodeload, which prepares Git repositories for download by compressing them into tarballs. It calls git archive, waits, then streams the result back to the user using Node’s stream API’s. (output I/O is also I/O and can benefit from evented I/O). See https://github.com/blog/900-nodeload2-downloads-reloaded.
I’m sure there’s plenty of use cases Node can excel at. If you’re curious to where Node is used for these days, take a look at Projects, Applications and Companies using Node in the NodeJS wiki on Github. Next time, we’ll dive deeper into the Node ecosystem and take a closer look at the wide range of interesting projects currently being developed with and for Node. The accompanying XKE session will have the participants actually play with these, so keep an eye out on the agenda.
Written by

Freek Wielstra
Freek is an allround developer whose major focus has been on Javascript and large front-end applications for the past couple of years, building web and mobile web applications in Backbone and AngularJS.
Our Ideas
Explore More Blogs




Contact