Blog
MLOps: why and how to build end-to-end product teams

Machine Learning Operations (MLOps) climbed in popularity over the past few years with the promise to apply DevOps to Machine Learning. It strives to streamline the arduous process of creating robust, reliable and scalable machine learning systems that are ready to face end-users.
Yet, despite its promise, as of 2022 it’s estimated that less than 20% of machine learning models are brought into production.
Why can so few companies bring ML models to production, and even fewer do so reliably and efficiently?
A gap between data science and IT prevents your ML models from reaching production
Data science teams are great at staying close to the business, finding and tackling business challenges with data-driven solutions.
A quick and iterative approach to ideation and exploration, the first phases of the machine learning life cycle (see Figure 1), is the fastest way to achieve results for business stakeholders. Teams that excel at this have been rewarded, and rightfully so.
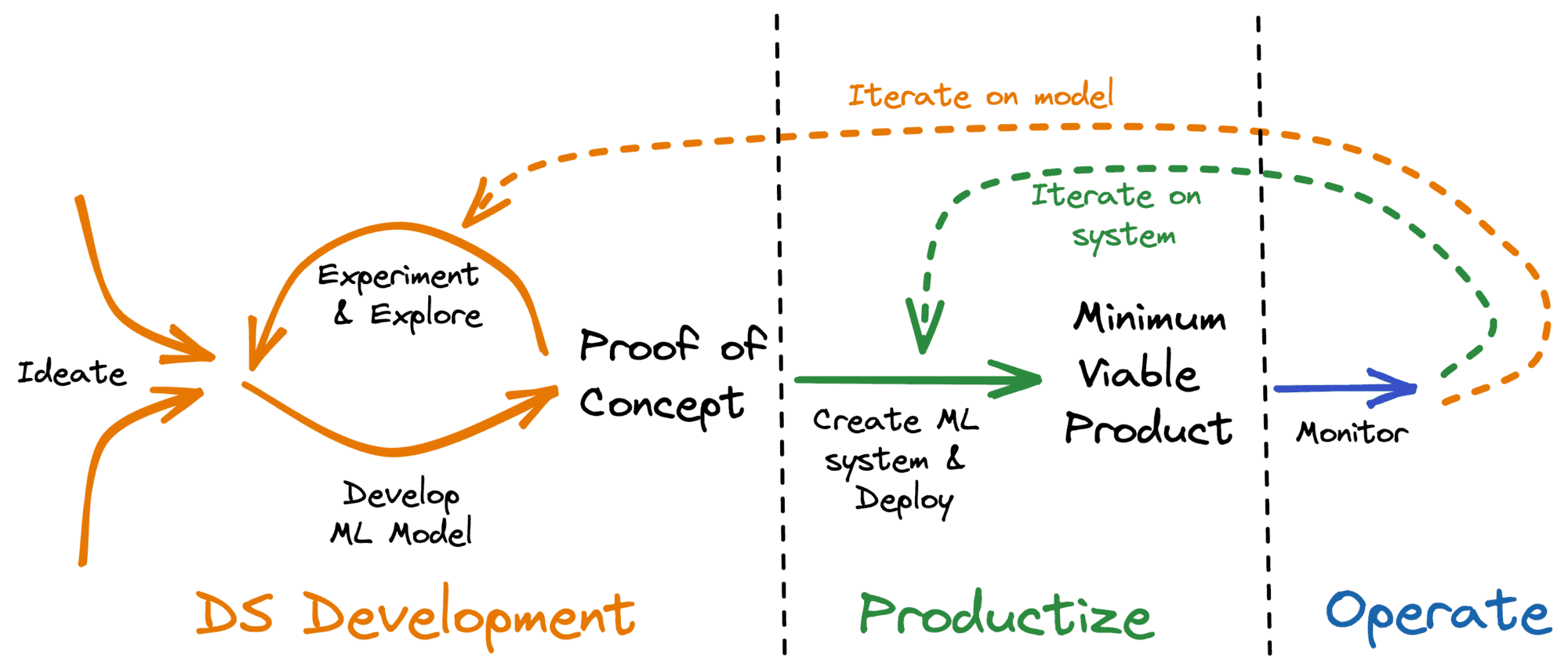
Figure 1: Typical life cycle of a data science product
Once a proof-of-concept (PoC) has been developed however, many teams hit a brick wall, unable to turn ML models into systems that run in production and add value to the business.
Without the skills and expertise to create production-grade software, these data science teams turn to an IT/Ops department to productize their solutions. Yet, handing over a PoC to an Ops team is anything but smooth.
What ends up happening is one of 3 things:
- The data science model is handed over to IT. IT runs it without understanding it (black box), often neglecting monitoring and maintenance of the contents of this black box. When the model performance starts to degrade, nobody notices or feels responsible to fix it.
- The data science model is rebuilt by an IT team, who end up investing lots of time and effort. The business must wait months (or years) before the model is usable. If improvements are needed along the way, or after, the IT team lacks the skills to include them. This restarts the handover process.
- The model is never moved to production: its true value never materializes.
Why handovers are problematic in data science
Handovers form a problematic bottleneck which prevents models from reaching production for 3 reasons:
- Machine learning systems are complex
- Machine learning systems are immature at the time of handover
- The two sides of the handover speak different languages
Let’s dive in.
Reason 1: Machine learning systems are complex
A machine learning product has multiple moving parts: model, data, and code. Each component evolves and every evolution might require changes in other parts: the code requires bug fixes or the data drifts? The model might need to be retrained. The data gains a new dimension or loses an existing one? New code must be written and the model should retrained.
These three moving parts result in machine learning systems consisting of many different components, as highlighted in the figure below. This complexity increases handover difficulty and likelihood of failure.
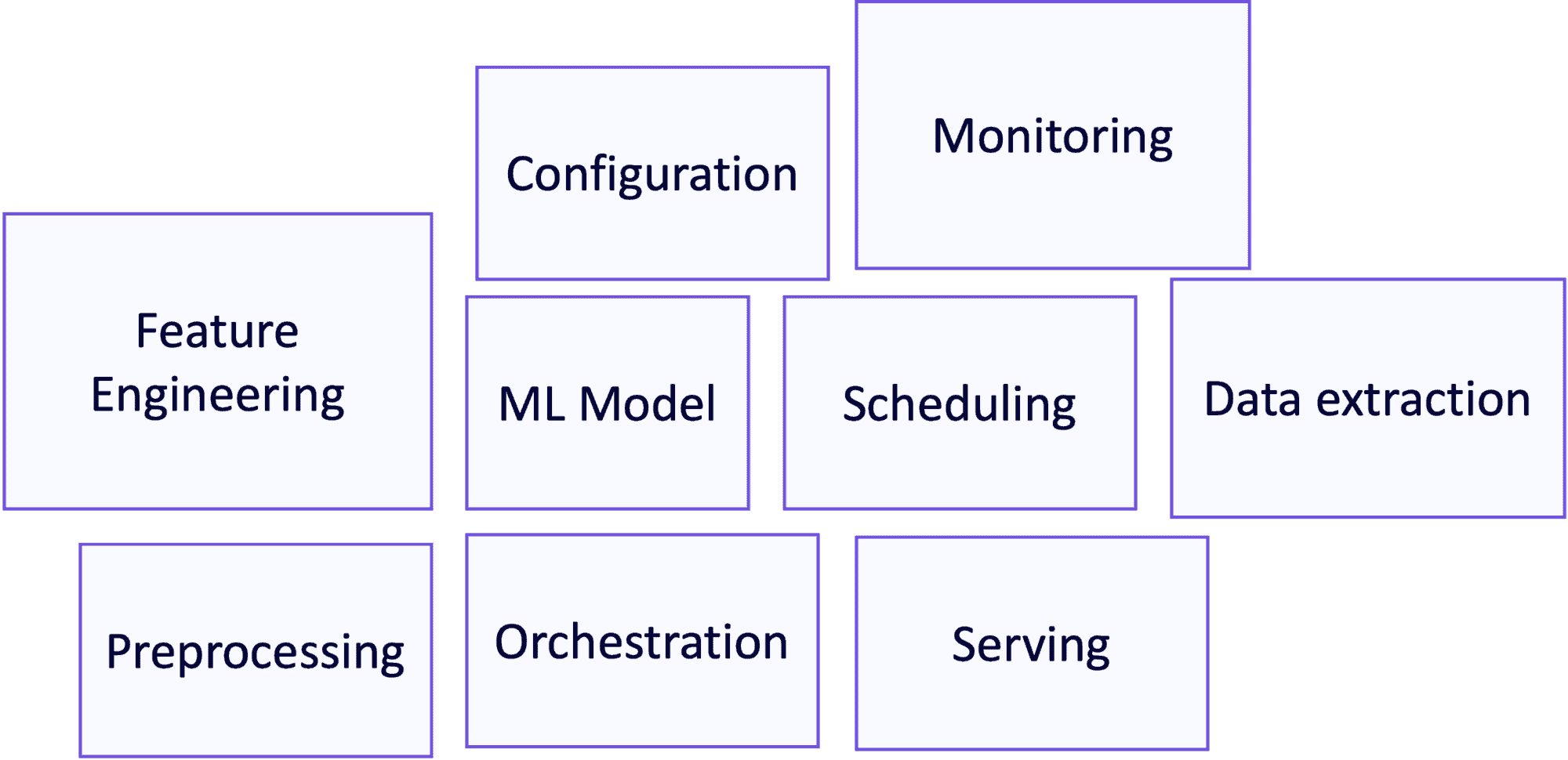
Figure 2: Components in a typical ML system
Reason 2: Machine learning systems are immature at the time of handover
Data scientists often lack the skills to design and build mature, well-engineered machine learning products.
The main goal of data science is to quickly demonstrate value to the business. Data scientists mostly operate around notebooks, with quick feedback loops to showcase results to stakeholders.
These quick loops, however, might result in an untested and undocumented end-result. Moreover, knowledge about the model and why some choices have been made, might remain in the data scientist's head, and not be codified anywhere.
Once again a difficult handover, now due to lack of maturity.
Reason 3: The two sides of the handover speak different languages
Data science teams and IT teams differ in tools they use, processes they follow, and people they employ — the two sides have different frames of reference, making misunderstandings common.
Again, data scientists aim to quickly demonstrate value to the business. Speed is essential and tools reflect this tradeoff: Python, pandas, and Jupyter notebooks are all great for speed.
For data scientists, engineering is an afterthought compared to the exciting and challenging “science” work of exploring data, building models & discovering business value.
Engineers in IT, on the other hand, are focused on building reliable, scalable solutions. The less attention they require when running, the less on-call support is needed. The result? A stack focused on reliability: Spark, Scala, and other JVM based languages.
For these engineers, data scientists are a source of poor code. So why not just rewrite it?
You need data science product teams to do MLOps
Given these potential handover issues, the best way forward is to eliminate this handover altogether.
To simplify running machine learning systems in production, you should create end-to-end product teams with the skills, mandate, and responsibility for the entire machine learning life-cycle.
This has several benefits:
— Short communication lines between data scientists and engineers.
— Easy to formulate common grounds between all experts.
— Easy to monitor, maintain, and iterate on a model once it “shipped” to production.
Go from split DS Dev and Ops (Figure 3) to end-to-end data science product teams (Figure 4).
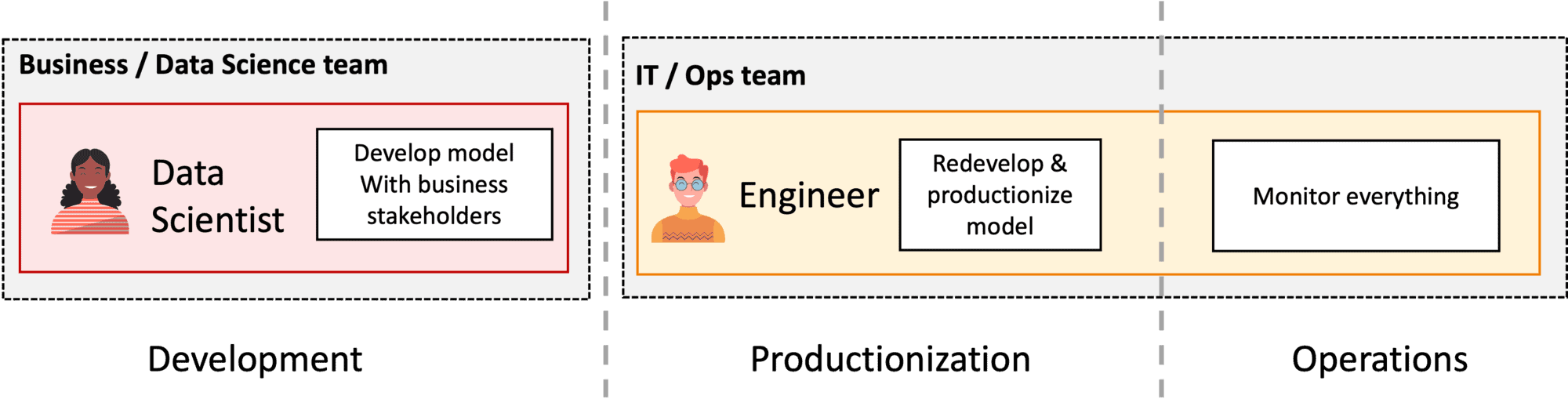
Figure 3: Team structure with split Data Science and Ops.
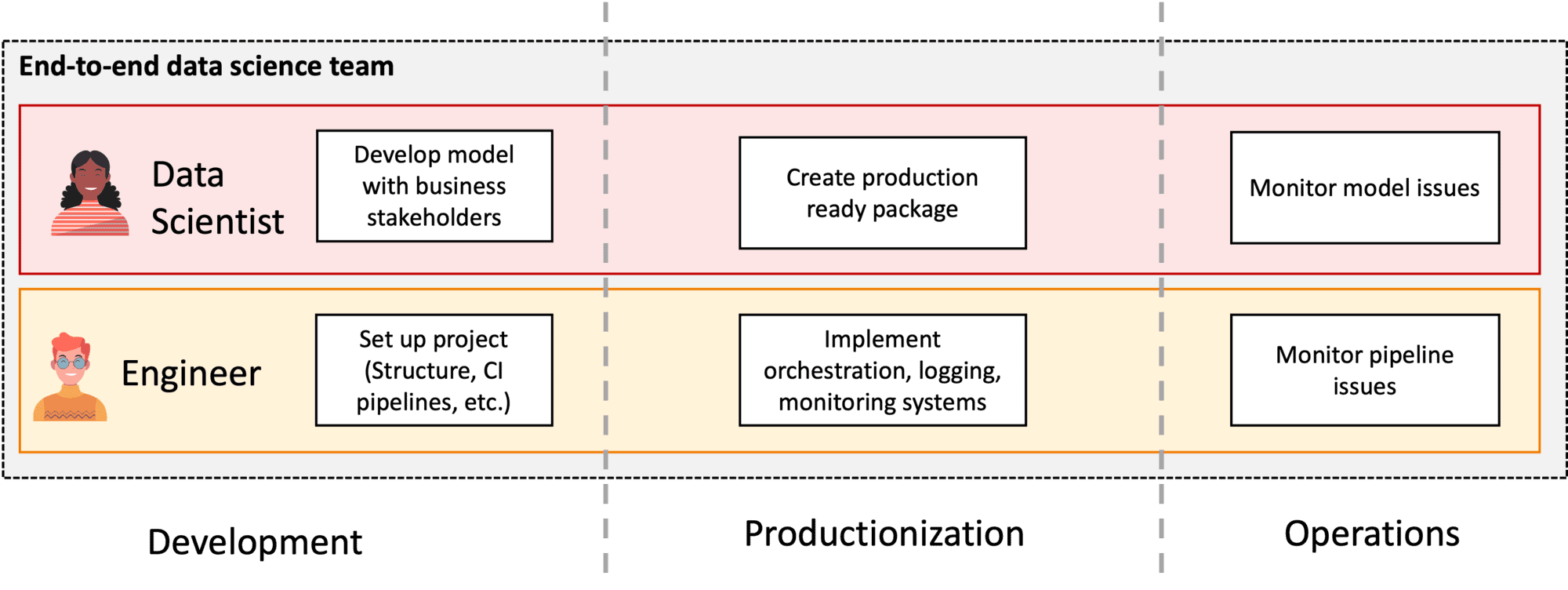
Figure 4: End-to-end data science product teams
Let’s take a closer look at the requirements to enable successful end-to-end teams:
- The right roles & skills to take ownership over ML products.
- A platform team that can enable the data science product team
- The right organizational environment to make data science in production a success.
Requirement 1: The right roles & skills to take ownership over ML products
In a data science product team, at least two roles are present: data scientists and machine learning engineers.
Data scientists are primarily focused on the model itself, whereas ML engineers focus on the system as a whole. Together, they share responsibility for the entire machine learning life cycle:
- Development
- Productization
- Operations
During development, the data scientists explore, the data and the problem space, and build models to solve the business problem. The machine learning engineers help them by providing software engineering guidance, best practices, and setting up the continuous integration (CI) pipelines.
During productization, the data scientists focus on refactoring their PoC model into a production-ready (Python) package, while the machine learning engineers focus on setting up orchestration pipelines and monitoring. Effectively, the engineers transform the machine learning model into a machine learning system.
Data scientists might lack some skills necessary to write production quality code, in that case it’s great that there are engineers around who can coach them.
Finally, during operations, data scientists focus on monitoring the model, whereas machine learning engineers focus on monitoring the rest of the system.
Requirement 2: A platform team that can enable the data science product team
A good platform team helps scale data science efficiently across multiple product teams.
Without it, the product team might take on too many responsibilities and spread its members across too much expertise areas: machine learning, data, and platform knowledge are all needed to provide the needed infrastructure and raw data.
In large organizations with multiple data science teams, reusability becomes a key factor. A machine learning platform team can support product teams to more efficiently create their products.
Creating and maintaining such a platform, however, is not as easy as just contracting a vendor and purchasing their latest ML platform. With this approach, you still haven’t set your individual product teams up for success in running machine learning in production.
The challenge lies in the following trade-off: How to ensure the platform provides high-enough level abstractions to be easy to work with, while being flexible enough to the individual needs for each use-case?
The golden path and paved path models (as popularized by Spotify) are practical frameworks to approach this. According to Spotify, "The idea behind having Golden Paths is not to limit or stifle engineers, or set standards for the sake of it. With Golden Paths in place, teams don’t have to reinvent the wheel, have fewer decisions to make, and can use their productivity and creativity for higher objectives. "
These golden and paved paths rely heavily on the creation of templates & tutorials to empower teams, whilst giving them freedom to adjust when required for specific use cases.
Like their data science counterparts, these platform teams are product teams themselves. Both the platform and the data science team are responsible for building and operating production-grade products and then operating them (see Figure 5).
Both teams should focus on serving their customers.
For the platform team, the use-case teams are their customers. For the use-case team, these customers are the business stakeholders who require a data science product.
Close & quick customer feedback cycles both help to iteratively building customer-focused products that provide real value to the company.
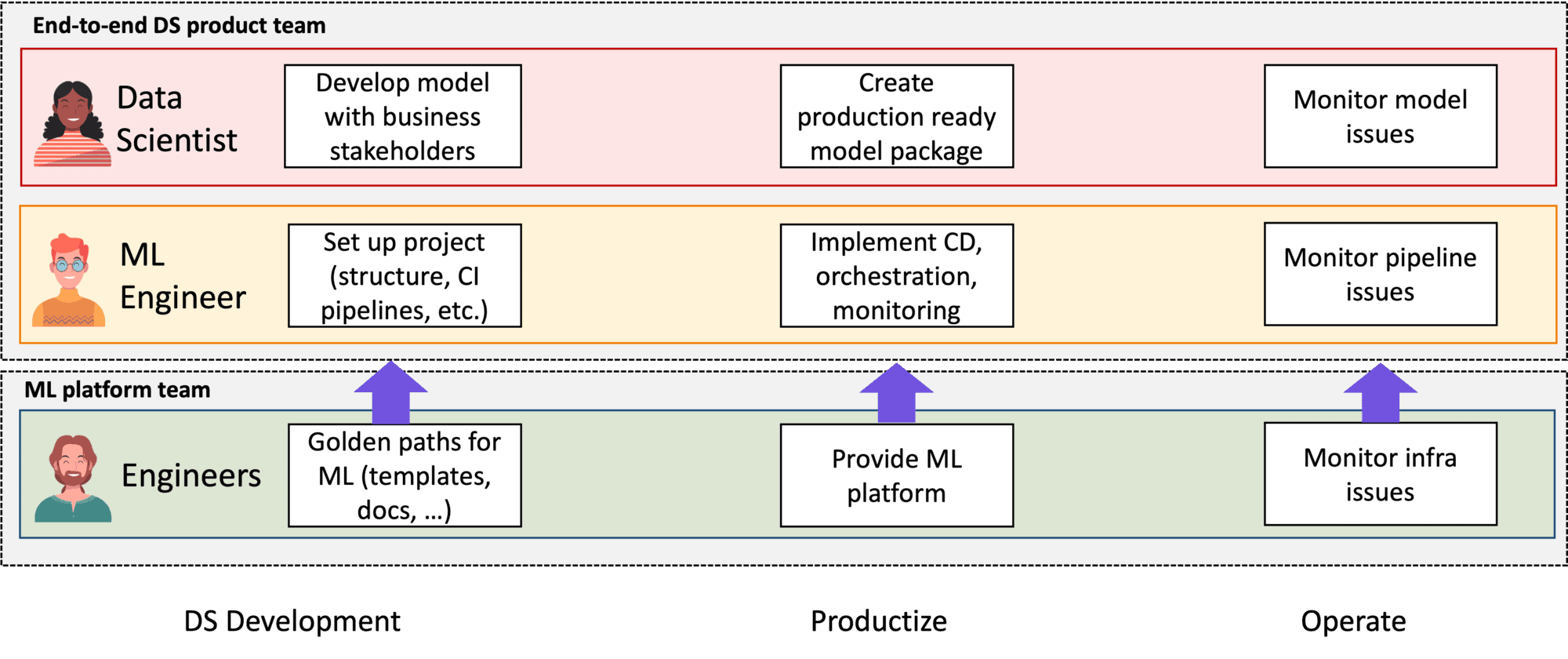
Figure 5: Team structure of data science product team with a platform team
Requirement 3: The right organizational environment to make data science in production a success.
Data science often happens at the intersection of business and IT. Having the right organizational surroundings of the team is therefore essential for their success.
They need to be as close to the business as possible yet should also be a well-respected member of the IT organization.
Why data science product teams need to be close to the business
Data Science product teams collaborate closely with their business stakeholders, who can often provide valuable domain input. This collaboration ensures the team builds solutions that the business wants, trusts, and which ultimately provide value.
Failing to do that results in business stakeholders using Excel-based forecasts rather than more powerful and accurate data science-based models because of trust & communication issues.
Why data science product teams need to be part of IT
Machine learning products are one of the many components within an IT infrastructure, and they should be treated as such.
Failing to consider these teams as part of IT risks failure of integration within the standard IT infrastructure.
Take one of our customers as an example, where their engineers and data scientists worked in a single team, looking to take end-to-end ownership over their ML products. Yet, the team was not considered part of IT, which prevented them to build & run their products within the standard IT systems. This forced them to do handovers to another department.
These organizational challenges are often complex, unique to each organization, and hard to solve.
It is important to be aware that they might exist and in which position data science teams might be in. Being nimble as an organization and keeping communication lines as short as possible are generic tips that often apply here as well.
Conclusion: A holistic view is the key to MLOps
When reading about MLOps, many tools and platform terms are often introduced: feature stores, experiment tracking & model registries to name a few.
Many companies then focus on these components when attempting to improve their MLOps capabilities.
However, tooling and tech are only part of the problem. MLOps revolves around people, processes, and the organization as a whole.
The key to succeeding at MLOps is to focus on building teams with the end-to-end capabilities and responsibilities required to build and operate production-grade machine learning solutions.
Are you interested to learn more about the specifics of setting up data science use-case teams and platform teams? Stay tuned for the next blogs that will explore this in more detail.
Written by
Daniel Willemsen
Daniel is a Machine Learning Engineer at GoDataDriven. He focuses on helping teams move their data science use-cases through the entire machine learning life-cycle: from ideation to production and maintainance.
Our Ideas
Explore More Blogs




Contact