
The cloud imperative
Different organizations have different reasons to move to public cloud and AWS in particular. At Xebia, we often hear (Managed Services) customers name the following reasons:
- Security - C-level and IT-executives understand that the required level of investment in security is phenomenal these days and only feasible at hyperscale
- Cost - the scale at which the leading cloud providers operate provides them with tremendous economies of scale which they pass on to customers
- Productivity - by adopting public cloud, organizations can achieve productivity gains allowing them to deliver more value to the business without having to increase headcount
- Modernization - public cloud gives organizations easy access to technology which they need to modernize their application landscape and deliver value to customers
- Flexibility - the elasticity of the public cloud enables organizations to scale up and down whenever they need to
- Agility - time to market is vastly reduced by having a platform at your disposal which offers the required capabilities and resources whenever a business opportunity presents itself
Increasingly, the public cloud is being seen as the new normal and this - in itself - can be seen as another compelling reason to move to the public cloud. The question isn’t ‘if’ and ‘why’ anymore but ‘when’.
Platform delivery
The way organizations build and deliver public cloud-based platforms can vary depending on the expected outcome. If the focus is solely on reducing the cost of existing workloads, the obvious choice would be to offer a small set of centrally managed codified patterns which will allow application teams to stand up the environments they need. On the other hand, if the mission is to get access to technology to extract value from the large amounts of data the organization has but it is unclear exactly which technology will work best, the organization may decide to deliver the platform in an entirely different manner. In the latter case, it is unlikely that a central team would be able to establish a proven pattern for the problem at hand. Most likely, giving a platform-consuming team fairly unrestricted access to the tools the platform has to offer, will yield the best results.
Whatever the desired outcome or use case is, there is likely to be a gap between what the public cloud provider has to offer by default and the organization’s enterprise IT policies and standards. The platform, as it is offered within the organization, must address this gap. At one end of the spectrum we already mentioned restricting teams by providing centrally managed and codified patterns. The central team ensures that the patterns include configurations or additions that guarantee compliance with enterprise standards. While this seems like an attractive approach, it may not work in all use cases. One example of such an exception has already been given: the data team which is still looking for the best technology to suit their use case and for which no enterprise standards have yet been established. Another issue with restricting teams to only use predefined patterns, is that there is an assumption that all the required patterns can be captured and centrally provided. What if this assumption does not hold true?
By providing guardrails, teams that consume the platform can be given more freedom. Instead of placing controls at the level of the pattern, controls can be placed at the level of the components which make up the pattern. Teams which define their own patterns, will be tested at the component level and provided (early) feedback. An example which should speak to many is to test file systems for having the correct method of encryption configured. Centrally provided patterns are measured against these same standards. All the components which comprise those patterns must also pass these compliance tests individually for the pattern to be compliant as a whole.
One size does not fit all
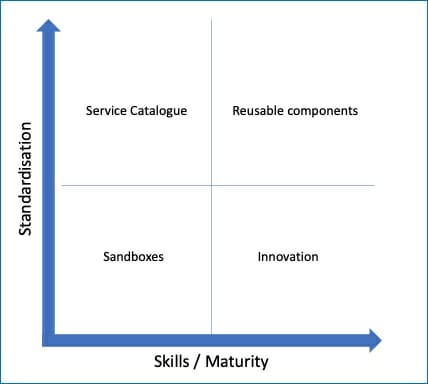
Diagram 1: Standardization versus Skills
Of course, how organizations offer the platform to teams will also depend on the maturity of the teams. The reality is that in large and even small organizations, skills and maturity will vary across teams. The requirements with respect to skills and maturity will also vary according to the use case.
As the diagram to the right illustrates, low skills and maturity in a team does not exclude them from having a high degree of freedom as long as the workload justifies this. The example given here is a sandbox used to experiment and build skills. It is also entirely conceivable that mature teams use components as a building block for their patterns or contribute building blocks to the community.
The bottom line is that when you consider offering a public cloud platform within your organization, there are a number of requirements that need to be addressed. First of all, you will have to address the reasons for moving to the cloud in the first place. At the same time, the platform should take into consideration that different use cases and teams have different requirements. One size does not necessarily fit all.
The operating model
The adoption of public cloud seems largely to coincide with another major development in the IT-industry: the shift towards DevOps. Many will argue that public cloud or cloud in general actually facilitates DevOps. While there is certainly a lot of merit to this argument, moving towards DevOps is definitely not a necessary condition for successfully adopting public cloud. In reality, some teams may have already embraced DevOps before moving to public cloud. Other teams may be considering the move. And there may be some teams for which there is no business case or imperative to adopt the DevOps way of working.
One of the most compelling arguments to move towards a DevOps way of working is to improve agility by removing dependencies. In a traditionally organized IT department, application development and IT infrastructure and operations are often strictly separated. Inevitably, handoffs have to take place between development and operations as code moves towards production. By making a single team responsible for development and operations, this impediment can largely be removed.
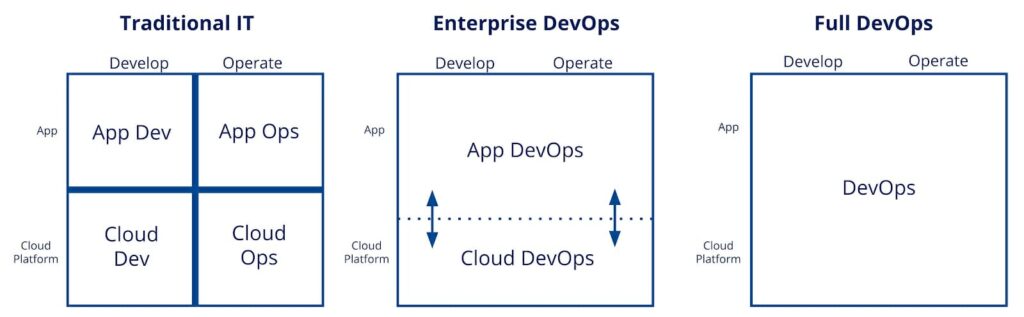
Diagram 2: Three levels of DevOps
So why not tackle another problem at the same time? We are referring to an often expressed frustration by teams which is that they have to raise requests or tickets for infrastructure. Introducing a self-service capable platform can make all the difference. But what about day-two operations? It’s one thing being able to stand up the environments needed to take a new application or feature to production. Keeping the environment stable, performant and secure is an entirely different matter. The cloud has definitely made this task a lot easier by supporting a cattle versus pets approach and by embracing infrastructure as code. But the reality is that some teams just aren’t there yet.
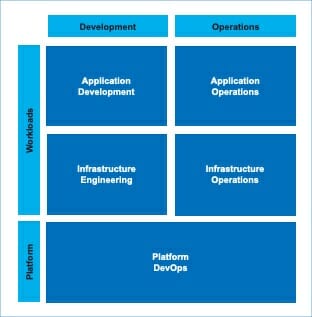
Diagram 3: Development versus Operations
Diagram 3 is a graphical representation of the areas where challenges may arise as described earlier. Since public cloud based platforms tend to be fairly new, it makes sense to make a single team responsible for building and operating the platform in line with recent trends in IT. Workloads (applications including the required infrastructure, data platforms, etc.) are likely a different matter. Some teams may already have assumed development and operations responsibilities for infrastructure and applications. Some teams may still be transitioning and some teams may never (want) to get there. If you accept this as a reality, the platform you serve has to be able to accommodate all of these different modes.
Transitioning
During the transition towards DevOps and public cloud, you should not only have a platform capable of supporting different operating models but also have the capacity in place to support teams using it. In addition to the platform team you may need temporary capacity to provide operations and engineering capabilities while teams mature until they are ready to assume full responsibility for their workloads. Once teams have achieved the desired maturity, you should also be ready to scale down this capacity.
Helping teams adopt the correct patterns with the lowest possible operational footprint will accelerate the journey. Teams will need coaching and training in this area which is something you should also plan for. Whether you build a fully functional Cloud Center of Excellence (CCoE), set up a cloud migration factory or inject ah-hoc skills during design stages will depend on your specific situation.
By introducing public cloud as a platform in your organization, you’re also introducing a cloud service provider into your vendor landscape. As a result, you may want to reconsider, retrain or rationalize the current capacity that delivers infrastructure. This could be an internal department or a vendor if this function was outsourced. If the current vendor also provides operational services, what is their position towards a new platform and shifting towards DevOps?
In itself, introducing a Cloud Service Provider into the vendor landscape and moving towards a consumption based model, requires a new set of skills. Closely monitoring cloud consumption, optimizing the purchase model, consolidated billing, encouraging teams to rightsize and adopt the right patterns and architectures from a financial perspective are just some of the skills popularly referred to as FinOps (learn about FinOps on our platform).
AWS Managed Cloud Services
We offer a broad portfolio of Managed Cloud Services as we see that organizations are on many different levels of maturity in their cloud journey. We work closely with customer application teams that consume these services to make sure that the cloud platform delivers what the application DevOps team needs in a controllable manner. What do you need from the AWS Managed Cloud? Find our cloud solutions here.
Written by
Thomas Wijntjes
In my role as a Marketing & Sales Specialist at Oblivion I get to combine the best of both worlds: staying on top of the latest cloud developments by listening to our customer’s challenges and using this input to create engaging content.
Contact