Blog
Introducing SodaBricks

Implementing Quality Checks on your Databricks Tables
Data quality remains one of the biggest challenges in Databricks, particularly due to two issues: the lack of centralized data quality rules and limited monitoring and alerting. Checks are often implemented inconsistently across notebooks or jobs, creating duplicated logic and uneven standards. Even when checks exist, proactive monitoring or automated alerts are frequently missing, allowing data issues to go unnoticed until they cause downstream failures.
Soda Core is a powerful open-source tool for implementing data quality checks, but it comes with some limitations. Configuration files must be managed manually across environments, visibility is limited to local or CI/CD outputs, and scheduling requires external orchestration tools. Results are not stored centrally, making it difficult to track data health over time. Integration with Databricks can also be complex, often requiring additional setup for authentication or service principals.
Soda Cloud addresses many of these challenges with dashboards and alerting, but it’s a SaaS platform, meaning some organizations avoid it due to compliance restrictions or cost concerns.
SodaBricks strikes a middle ground: it combines Soda’s powerful checks with a robust, GitHub-driven deployment on Databricks. Analysts can define checks in YAML, version them in Git, validate them, and deploy through automated workflows. Results live in a single table. A dashboard makes data-quality monitoring accessible, consistent, and scalable.
Why Data Checks Are Important
When working in Databricks, it’s easy to assume that once data has landed in a table, it’s “ready to use.” In reality, data can arrive late, contain unexpected values, or even fail to meet basic assumptions. Without systematic checks in place, these issues can silently propagate downstream into reports, dashboards, and models — eroding trust in your data.
Implementing automated data checks on top of your tables can help to:
- Detect issues early: Data problems are identified closer to the source, before they propagate further into your system.
- Maintain reliability: Automated checks provide confidence that pipelines are running as expected and that data is trustworthy.
- Strengthen governance: Validating rules like uniqueness, null handling, and referential integrity makes compliance and auditability easier.
- Improve scalability: As more teams and pipelines rely on shared data, systematic checks reduce the risk of one faulty dataset affecting many consumers.
SodaBricks provides a way to embed these checks into your Databricks tables in a standardized, best-practice-driven manner — so quality isn’t an afterthought, but part of the design.
Today, many teams handle data quality by writing their own SQL or Python tests directly in Databricks, or by adopting external tools such as dbt, which comes with a set of built-in tests. While these approaches can be effective, they often require custom setup, maintenance effort, and knowledge of the underlying platform. SodaBricks complements these options by offering a consistent and Databricks-native way to manage checks. This significantly lowers the barrier to implementing reliable data quality practices, while avoiding an extra control plane such as Soda Cloud
Quick Example: SodaBricks in Action
When using SodaBricks, you are required to create just two configuration files and a single workflow run. Here’s the flow:
- Define your checks in a YAML file.
- Configure how you want them deployed in another YAML file.
- Trigger the GitHub workflow.
SodaBricks will then automatically generate parameterized Databricks notebooks with the checks, builds a "Databricks Asset Bundle (DAB)" with jobs to run them, and deploys the whole stack to your workspace.
Here’s a minimal example of what the configuration files could contain:
checks configuration:
cron_schedule: "0 0 0 * * *"
result_metric_table: "example_catalog.example_schema.results_table"
checks:
- source_table_name: "example_catalog.example_schema.example_table_to_test"
soda_cl_checks:
- row_count > 0
infrastructure configuration:
create_cluster: true
dbx_workspace_url: "https://adb-myworkspace.azuredatabricks.net"
Once you’ve defined your configuration files, you simply commit and push them to GitHub. This will automatically trigger the workflow, generating the notebooks and deploying the stack into Databricks.
Architecture of Our Solution
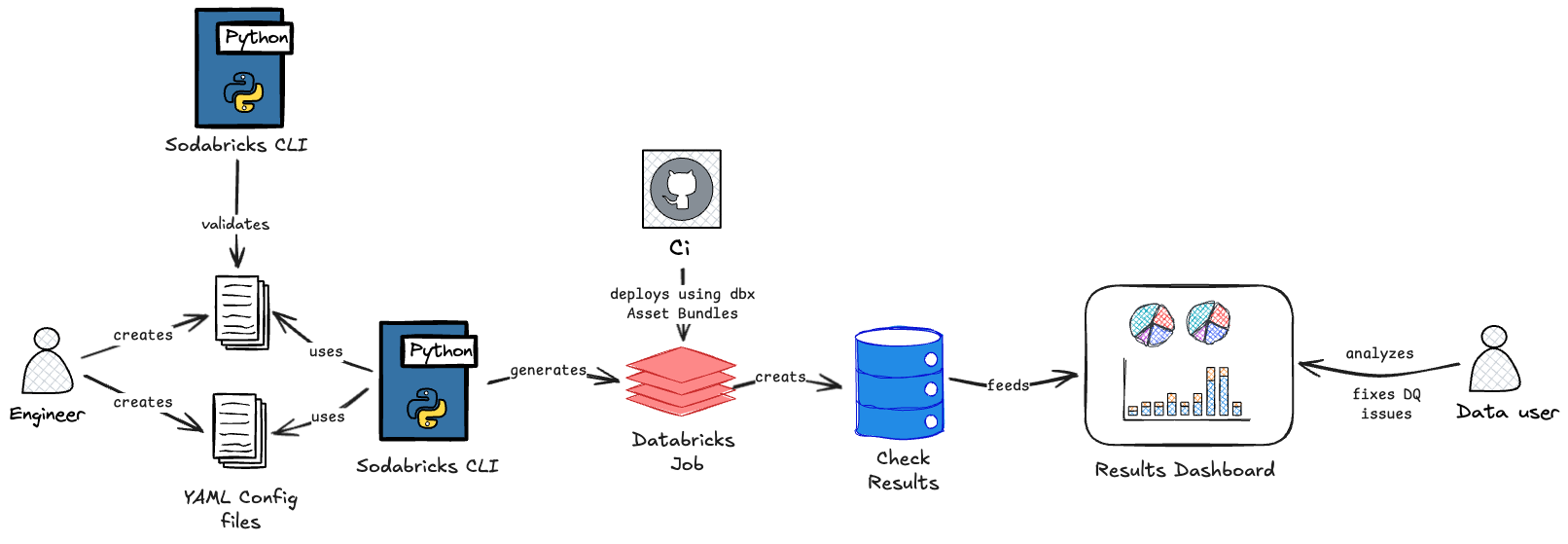
Behind the simple workflow, SodaBricks is built from several connected components that ensure data checks are easy to define, run, and monitor. At the core are configuration files that describe the checks, automatically generated notebooks that execute them, and dashboards that present results. These pieces are tied together into deployable jobs through Databricks Asset Bundles, with additional commands available for running checks locally during development.
Configuration Files
Configuration is the main (and only) input users provide to SodaBricks. It is intentionally split into two parts — infrastructure and Soda checks — to keep responsibilities separate and clear. This split makes it possible for different teams (for example, engineers and analysts) to work in parallel, while ensuring that the checks themselves remain easy to understand, even for non-technical users.
We also provide a custom validation command, so users can verify their configuration files before deploying them. This helps detect mistakes early and enforces the expected structure.
Infrastructure Configuration
The infrastructure file handles Databricks setup: workspace details and cluster configuration. The supported fields are:
- dbx_workspace_url: the Databricks workspace URL to deploy to.
- create_cluster: whether SodaBricks should create a job cluster for each job.
- cluster_id: optional, the ID of an existing cluster to use instead of creating a new one.
- cluster_key: optional, the name of the cluster if SodaBricks is creating one.
- spark_version: optional, the Spark version to use when creating a cluster.
- node_type: optional, the node type to use when creating a cluster.
create_cluster: true
cluster_key: "sodabricks_job_cluster"
spark_version: "16.3.x-scala2.12"
node_type: "Standard_F4"
dbx_workspace_url: "https://adb-2940475086103197.17.azuredatabricks.net"
Checks Configuration
The checks file focuses on data quality rules. It is designed to be accessible to non-technical users. Supported fields include:
- cron_schedule: the schedule of the job, expressed in Quartz cron format (as required by Databricks).
- result_metric_table: the path of the table where results will be stored. We expect at least the catalog to exist already.
- checks: the list of checks to apply to each table. Each entry contains:
- source_table_name: the name of the table to validate.
- soda_cl_checks: the list of SodaCL checks to perform.
cron_schedule: "0 0/5 * * * ?"
result_metric_table: "sodabricks_dev.test_data.results"
checks:
- source_table_name: "sodabricks_dev.test_data.manual_test_data"
soda_cl_checks:
- row_count > 0
- missing_count(id) = 0
- max_length(amount) = 10000000000
- failed rows:
name: amount is 0
fail condition: amount = 0.0
samples limit: 20
Notebooks
From the checks configuration, SodaBricks automatically generates a Databricks notebook. Each notebook follows a consistent structure with three main steps:
- Run Soda CLI checks against the specified tables.
- Parse the results into a structured format that is easier to consume.
- Store the results in a table, making it possible to track data quality over time.
The execution schedule for each notebook is defined in the configuration file. To run these notebooks, SodaBricks creates a Databricks job (and, if needed, a job cluster with the required libraries). Multiple jobs can be created — one for each checks configuration file — ensuring that different sets of checks can run independently and on their own schedules.
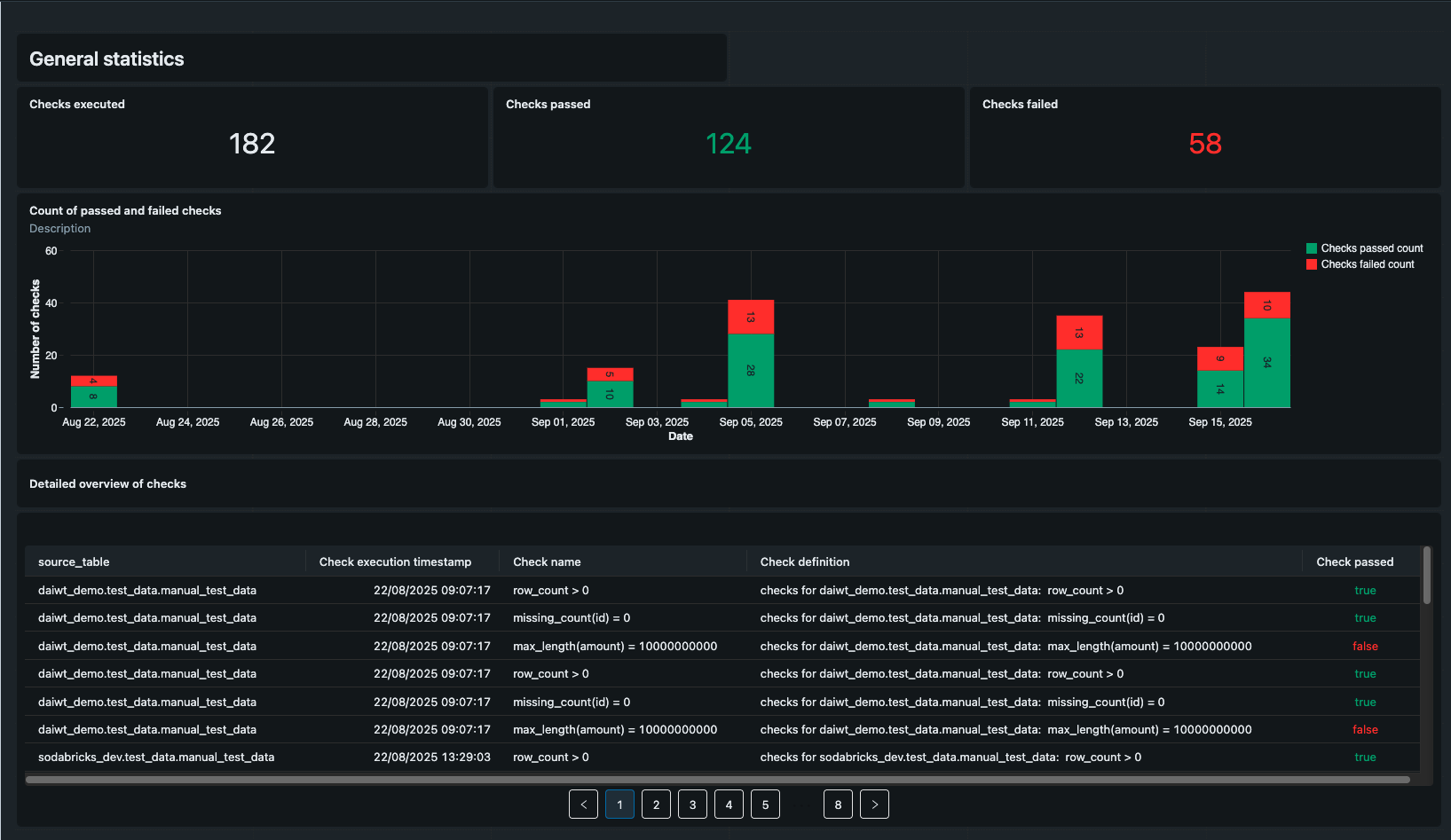
Dashboard
The results of each Soda check are stored in a table, declared in the checks configuration file, which enables tracking data quality over time. Using this data, SodaBricks generates a templated Databricks dashboard that summarizes the outcomes of all tests. The dashboard is designed to be accessible to non-technical users, providing clear visual insights into the health of the data being monitored and making it easy to spot trends or recurring issues.
Github Workflow
Part of SodaBricks is a GitHub workflow that packages and ships the user-generated code to Databricks for execution. The workflow consists of the following steps:
- Validate checks and infrastructure files to ensure the configuration is correct and well-strcutured.
- Generate Databricks Asset Bundle (DAB) artifacts required for deployment.
- Deploy the bundles via Databricks CLI to create/refresh jobs to execute notebooks..
The workflow is triggered automatically whenever users commit and push their configuration files to GitHub. Once it completes, all checks are available as jobs and notebooks in the Databricks workspace, and a templated dashboard is created to visualize the results. This automation ensures a smooth, repeatable process from configuration to monitoring.
CLI Commands for Local Development
SodaBricks provides three commands that can be run locally to help set up and test configurations before deployment:
init
Generates the required YAML configuration skeleton for SodaBricks, giving users a starting point for both infrastructure and checks configuration.
validate
Checks the structure and content of the configuration files:
- Ensures file formats are correct (using Pydantic validation).
- Verifies that referenced tables exist (requires local authentication credentials to Databricks).
generate context
Creates the configuration for Databricks Asset Bundles, including:
- Notebooks to execute the checks
- Jobs configuration
- Dashboard configuration
This command is also used by the GitHub workflow during deployment. It fills in pre-defined templates to generate notebooks, jobs, and dashboards. Note that generate_context does not deploy the Asset Bundle — the GitHub workflow handles the actual deployment via the Databricks CLI.
Working with SodaBricks
Assumption
SodaBricks makes a few assumptions about its users. We expect users to be already familiar with the SodaCL check syntax and able to define data quality rules required for the data. In addition, users should be comfortable navigating the Databricks UI and able to provide some configuration details needed for deployment.
Prerequisites
Before getting started with SodaBricks, there are a few setup steps required to provide functionality that the project itself does not cover. These steps depend on your environment and, in some cases, may involve configuration in your cloud provider.
- Create a Service Principal with the correct permissions (required). Jobs created by SodaBricks should run under a service principal. Depending on your setup, creating and configuring this principal may require cloud provider access. The service principal must have: all privileges on the catalog where the results table will be written and read permissions on the tables being checked, specifically:
SELECTon the table andUSE_SCHEMAandUSE_CATALOGon the schema and catalog of the table - Create a Databricks Catalog (optional). If you choose to store results in a new location, you may need to create a Databricks catalog beforehand. This step is not handled by SodaBricks, since it often requires cloud-level access (for example, linking an external location in a storage account). If you already have a suitable catalog, you can skip this step.
Repository and Workflow Setup
To make SodaBricks work smoothly, some initial engineering setup in GitHub is required. This setup ensures that the workflows can deploy correctly to Databricks and that users can collaborate safely across environments.
Working with SodaBricks relies heavily on GitHub Actions. For this reason, the project requires a dedicated GitHub repository. In this repository, set up four environments: development, test, acceptance, and production. Each environment must include specific variables and secrets:
DATABRICKS_CLIENT_ID: the ID of the service principal used to execute actionsDATABRICKS_CLIENT_SECRET: the secret of the service principal
The SodaBricks GitHub workflow will automatically deploy to the development environment for any pull request opened against the main branch. We recommend configuring the repository so that:
- Developers can create feature branches from main.
- Merging is blocked if the deployment workflow fails.
Deployments to test, acceptance, and production occur automatically whenever changes are merged into main. Finally, it’s a good idea to set up, or clearly document, the infrastructure configuration file in a way that allows non-technical users to test and deploy their checks with minimal friction.
Built-in Best Practices
SodaBricks is designed not only to simplify data quality checks, but also to embed best practices that help teams maintain reliable, maintainable pipelines. Three key areas where these best practices are applied include:
Git/Version Control
All configuration files and code live in Git, ensuring that changes are tracked and auditable. This encourages collaboration across teams, allows for code review, and provides a clear history of changes to both infrastructure and checks. Why it matters: Teams can confidently make updates knowing they can review, revert, or trace changes, reducing errors and improving accountability.
Good Quality (Python) Code
The generated Python and YAML code follows clear, consistent patterns that are easy to read and maintain. Validation commands further enforce correct structure and content before deployment. Why it matters: Clear, maintainable code reduces the likelihood of mistakes, speeds up onboarding for new team members, and ensures that checks remain understandable over time.
Databricks Asset Bundles Deployment
By using Databricks Asset Bundles, SodaBricks enforces a repeatable, reliable deployment process. Notebooks, jobs, and dashboards are generated in a structured way and deployed consistently. Why it matters: Standardized deployments minimize manual errors, ensure consistency, make operations predictable, and ensure that all components of the data quality checks work together.
Extensible Framework
SodaBricks is designed to be extended with custom checks, rows samplers, and integrations while maintaining the core workflow and best practices. Why it matters: As data environments and requirements evolve, teams can adapt the framework to new use-cases without starting from scratch, protecting the initial investment in such a solution.
Written by
Marta Radziszewska
Data Engineer
Our Ideas
Explore More Blogs




Contact