
Why fine-tune?
Large Language Models (LLMs) are impressive generalists. They perform increasingly well on a wide range of tasks; achieving human-level or even superhuman-level performance on many benchmarks. However, being good at everything can come at a cost. These so-called Foundation models have billions of parameters and require a vast amount of GPUs to train- or run. Unaffordable for most - so we consume LLMs from APIs instead - which comes with its own considerations like cost, privacy, latency or vendor lock-in. This is not the only option. When only specialist capabilities are required, generalist capabilities can be sacrificed in favor of domain-specific knowledge, allowing us to get away with smaller models. Smaller models require less compute and can achieve similar- or even better performance than larger models on specific tasks [1]. With enough data available, we can specialise existing models ourselves. This is fine-tuning.
What is fine-tuning?
Fine-tuning is a process where we take a pre-trained model and continue training it on a new dataset, typically with a smaller learning rate. This allows the model to adapt to the specific characteristics of the new data while retaining the general knowledge it gained during the initial training. In practice, this often involves further training the top layers of the model while freezing the lower layers, which helps to preserve the learned features from the original training.
So, how to finetune ourselves? Let's figure that out!
How to finetune yourself ✓✓
Enough talking! Let's get practical. Let's fine-tune a model on our own hardware. We have access to the following setup:
- HP Z8 Fury
- 3x NVIDIA RTX 6000 Ada GPUs
Our goal is: to finetune a model and benchmark it with MMLU Pro, math category.
So in order to start fine-tuning, we need to decide on the following:
1. Fine-tuning framework: Axolotl
There are several fine-tuning frameworks: Axolotl, Unsloth and torchtune. We choose Axolotl for its ease of use and its rich out-of-the-box examples.
In Axolotl's first fine-tune example, you only need to execute a one-line command to fine-tune a Llama3.2 model:
axolotl train examples/llama-3/lora-1b.yml
The fine-tuning dataset and method are all defined in the YAML file.
2. Model choice
The first question we asked is how large a model can we fine-tune given 3 GPUs. One NVIDIA RTX 6000 Ada GPU has 48 GB, so in total we have around 150 GB.
Under the hood, Accelerate is used. We need to figure out, however, how big of a model we can train on the available GPUs. To calculate the memory usage based the amount of model parameters, Zachary Mueller's slides offer a convenient formula.
Take Llama 3 8B model for example, which has 8 billion parameters. Each parameter is 4 bytes, so the model needs roughly 8 × 4 GB. Further, the backward pass take 2× the model size, and optimizer step takes 4× the model size, which consumes the highest memory during fine-tuning.
You can also use this model size estimator tool to estimate the memory usage based on your own model choice.
For example, we cannot fine-tune a DeepSeek V2 model, because the memory usage is above 3 TB, as shown below:
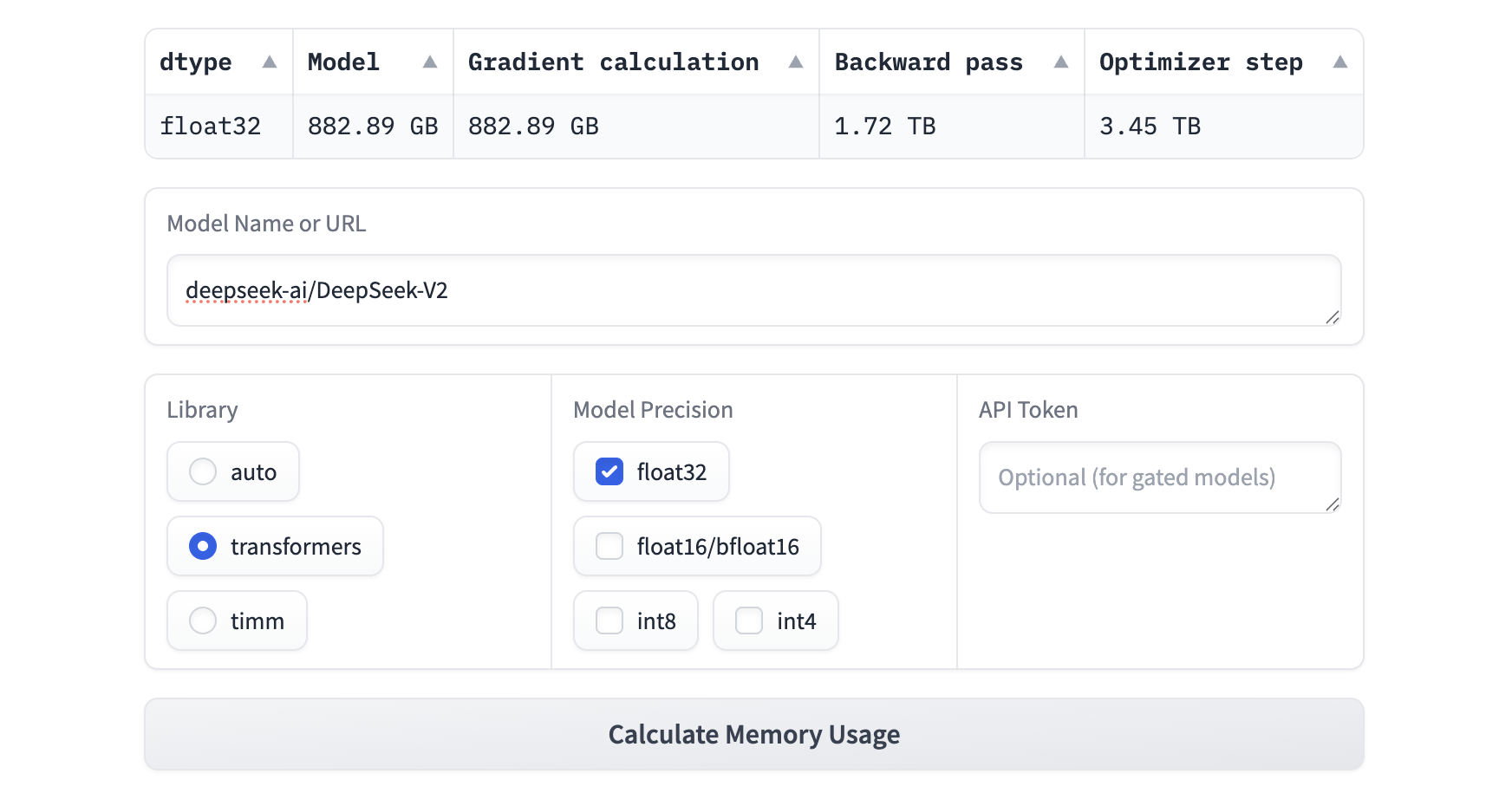
Based on the memory limit, we choose Gemma-2-2B to fine-tune and dip into the fine-tuning techniques.
The reason we choose a Gemma model is that we want to use a relatively small model to fine-tune for a specific task to prove that a fine-tuned smaller model can outperform the larger models in a specific domain.
3. Benchmarking dataset: MMLU-Pro
For the benchmarking dataset, we use the MMLU-Pro dataset. It has 14 categories of questions, ranging from math, physics, biology to business and engineering. For each question, there are 10 options to choose from for one correct answer. When it comes to the dataset split, it has 70 rows for validation and 12k rows for test. The validation dataset is used to generate CoT (Chain of Thought) prompts for the test dataset. Together, they form the prompts to benchmark your model.
The MMLU-Pro leaderboard shows the benchmarking results for an abundance of models. For example:
Since only the overall accuracy is reported for Gemma 2- or 3- models, we also want to know the specific accuracy for math.
The benchmarking script can be found in MMLU-Pro's GitHub repository. For example, if we want to evaluate a local model, we can reference this script:
modelis<repo>/<model-name>from Hugging Face.selected_subjectscan beallfor all categories, ormathfor a specific category.
python evaluate_from_local.py \
--selected_subjects $selected_subjects \
--save_dir $save_dir \
--model $model \
--global_record_file $global_record_file \
--gpu_util $gpu_util
We ran the above script for --selected_subjects math, we get the below results:
Next, we want to fine-tune a smaller Gemma model to improve the accuracy of math above 0.107.
4. Training dataset: AceReason-Math
We use NVIDIA's AceReason-Math dataset to fine-tune our model. It is a training dataset with 49.6k math reasoning questions. Instead of giving a list of options, the dataset comes in the format of one question and one correct answer.
In order to use this question/answer format to fine-tune a model in Axolotl, we need to check what instruction tuning formats are provided. This alpaca_chat.load_qa format perfectly matches our training dataset. So we can update our fine-tuning YAML file as below:
datasets:
- path: /data/nvidia_ace_reason_math.parquet
type: alpaca_chat.load_qa
One thing to pay attention to is that we also need to match the dataset column names to question and answer, so we rename the original problem column to question.
5. Fine-tuning strategies: QLoRA, LoRA, FSDP, DeepSpeed
There are many techniques and libraries around that help make the fine-tuning process more efficient, many of which focussing on memory efficiency and performance. Most notably, these include LoRA, QLoRA, FSDP and DeepSpeed. Axolotl supports all of these techniques. DeepSpeed or FSDP can be used for Multi-GPU setups, of which FSDP can be combined with QLoRA.
So what are these techniques?
- LoRA (Low-Rank Adaptation) is a technique that allows us to fine-tune large models with fewer parameters by introducing low-rank matrices.
LoRA ... [reduces] trainable parameters by about 90%
- https://huggingface.co/learn/llm-course/en/chapter11/4
... this means, that we can fit more in memory and more easily fine-tune on consumer-grade hardware. Awesome!
-
QLoRA (Quantized LoRA) is an extension of LoRA that quantizes the model weights to reduce memory usage further.
-
FSDP (Fully Sharded Data Parallel) is a way of distributing work over GPUs.
FSDP saves more memory because it doesn’t replicate a model on each GPU. It shards the models parameters, gradients and optimizer states across GPUs. Each model shard processes a portion of the data and the results are synchronized to speed up training. - FullyShardedDataParallel (HuggingFace)
- DeepSpeed is a library that helps you do distributed training and inference supported by Axolotl.
Combinations of LoRA/QLoRA are used as an adapter in the Axolotl config in combination with FSDP for finetuning Gemma2/Llama3.1/Qwen2 on our limited amount of GPU resources ✓. Let's now see how to run the fine-tuning process! 🚀
6. Running the fine-tuning 🚀
Axolotl provides a list of Docker images for us to use out of the box. In order to use it, you can reference this Docker installation.
Since we have our development GPU infrastructure set up and managed by Argo, we create a Kubernetes job to run the fine-tuning process as below:
apiVersion: batch/v1
kind: Job
metadata:
name: axolotl
spec:
backoffLimit: 0
template:
metadata:
labels:
app: axolotl
spec:
restartPolicy: Never
containers:
- name: axolotl
image: axolotlai/axolotl:main-latest
command: ["/bin/bash", "-c"]
args:
- |
set -e
echo "Start training..."
axolotl train $YAML_FILE --num-processes $NUM_PROCESSES
echo "Merging the LoRA adapters into the base model..."
axolotl merge-lora $YAML_FILE --lora-model-dir=./outputs/out/
echo "Uploading the fine-tuned model to Hugging Face..."
huggingface-cli upload $MODEL_NAME ./outputs/out/merged/ .
securityContext:
privileged: true
runAsUser: 0
capabilities:
add: ["SYS_ADMIN"]
resources:
limits:
nvidia.com/gpu: 1
memory: "40Gi"
requests:
memory: "20Gi"
volumeMounts:
- name: axolotl
mountPath: /workspace/axolotl
- name: huggingface
mountPath: /root/.cache/huggingface
- name: dshm
mountPath: /dev/shm
volumes:
- name: axolotl
persistentVolumeClaim:
claimName: axolotl-pvc
- name: huggingface
persistentVolumeClaim:
claimName: huggingface-pvc
- name: dshm
emptyDir:
medium: Memory
sizeLimit: "10Gi"
The variables come from the config map defined in kustomization.yaml:
NUM_PROCESSESis the number of GPUs to useYAML_FILEis the YAML file from examplesMODEL_NAMEis the model name to upload to Hugging Face.
Results
After the fine-tuning is done, which takes roughly 2.8 hours, we can use python evaluate_from_local.py to evaluate the result, which is as below:
Compared to a non-fine-tuned Gemma-3-12B-it model based on math, the fine-tuned model improves the accuracy of math from 0.107 to 0.238 ✓.
Conclusion
In this blogpost we learned:
- What fine-tuning is and why it is useful.
- How to fine-tune a model on our own hardware using Axolotl.
- How to benchmark the fine-tuned model using MMLU-Pro.
- How to run the fine-tuning process in a Kubernetes job.
We successfully fine-tuned a model and benchmarked it with MMLU-Pro, math category. The results show that fine-tuning smaller models can lead to competitive performance on specific tasks, demonstrating the power of domain-specific knowledge in LLMs.
Finetuning is definitely not always the right approach - but if it is - it can be very powerful. Good luck in your own fine-tuning adventures! 🍀
Citations
Written by

Jeroen Overschie
Machine Learning Engineer
Jeroen is a Machine Learning Engineer at Xebia.
Our Ideas
Explore More Blogs

Let us explore some of the real-world use cases, emerging from this conversation, showing how generative AI is redefining what's possible.
Klaudia Wachnio



Contact