Don't be a lonely document": That is a famous quote of Emil Eifrem. Last week at Graphconnect he repeated it once again, together with the assignment to tweet about the conference. That inspired me to start scraping twitter on the keywords "neo4j" and "graphconnect" and put it into Neo4j. Are people really connecting?
In my first setup, I tried to fetch tweets realtime with logstash, publish the stream to Kafka, and have a Spark Streaming job running to process every tweet and insert it into Neo4j.
You can use the following logstash configuration to do just that.
input {
twitter {
consumer_key => "foo"
consumer_secret => "bar"
oauth_token => "baz"
oauth_token_secret => "qux"
keywords => ["graphconnect", "neo4j", "GraphConnect"]
}
}
output {
kafka {
codec => plain {
format => "%{message}"
}
topic_id => "tweets"
}
}
The next step is the Spark Streaming job. I had an old test project that does exactly that. For some code examples take a look at: https://github.com/rweverwijk/twitter-to-neo4j
Low laptop battery forced me to abandon this little experiment, but it didn't leave my mind.
Later at home, I searched for a new solution to collect all the tweets with the selected keywords. I created the following simple python script to search for tweets and store the JSON in a file:
import tweepy import time import json ckey = 'foo' csecret = 'bar' atoken = 'baz' asecret = 'qux' OAUTH_KEYS = {'consumer_key': ckey, 'consumer_secret':csecret, 'access_token_key':atoken, 'access_token_secret':asecret} auth = tweepy.OAuthHandler(OAUTH_KEYS['consumer_key'], OAUTH_KEYS['consumer_secret']) api = tweepy.API(auth) def limit_handled(cursor): while True: try: yield cursor.next() except tweepy.TweepError as e: print(e.error_msg) time.sleep(15 * 60) def search(keyword): # Extract the first "xxx" tweets related to "fast car" with open('tweets_friday.json', 'a') as the_file: for tweet in limit_handled(tweepy.Cursor(api.search, q=keyword, since='2017-05-09').items()): the_file.write(json.dumps(tweet._json) + 'n')
Now, the real fun could begin: Loading the tweets in Neo4j. The selected structure is very simple. As I'm particularly interested in people that connect, I will look for Twitter users and the mentions in tweets. Next to that, I want to make a difference between the original writer of a tweet and retweeters. This will give the following structure:
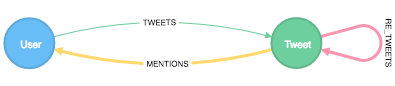
The input data is in JSON format. I prefer using Python to read this data, extract the fields that I want to store, and store it to Neo4j. The following code snippet does just that:
import json from neo4j.v1 import GraphDatabase import time def store_tweet(tx, tweet): neo4j_params = {"user_id": tweet['user']['id'], "user_name": tweet['user']['name'], "tweet_id": tweet['id'], "tweet_text": tweet['text'], "tweet_time": time.strftime('%Y-%m-%d %H:%M:%S', time.strptime(tweet['created_at'],'%a %b %d %H:%M:%S +0000 %Y')), "mentions": tweet['entities']['user_mentions'] } tx.run(""" MERGE (u:User {uid: $user_id}) on create set u.name = $user_name MERGE (t:Tweet {uid: $tweet_id}) on create set t.text = $tweet_text, t.time = $tweet_time MERGE (u)-[:TWEETS]->(t) WITH t, $mentions as mentions unwind mentions as mention MERGE (u:User {uid: mention.id}) on create set u.name = mention.name MERGE (t)-[:MENTIONS]->(u) """, neo4j_params) def process_file(file_name): with GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "test")) as driver: with open(file_name, 'r') as the_file: with driver.session() as session: with session.begin_transaction() as tx: for line in the_file: tweet = json.loads(line) store_tweet(tx, tweet) if 'retweeted_status' in tweet: store_tweet(tx, tweet['retweeted_status']) retweet_data = { 'tweet_id': tweet['id'], "retweet_id": tweet['retweeted_status']['id'] } tx.run(""" MATCH (t:Tweet {uid: $tweet_id}) MATCH (r:Tweet {uid: $retweet_id}) MERGE (t)-[:RE_TWEETS]->(r) """, retweet_data) process_file('tweets_friday2.json')
Let's see what we can find in Neo4j now.
First, let's take a quick look at the relationships within MENTIONS:
MATCH p=()-[r:MENTIONS]->() RETURN p LIMIT 50
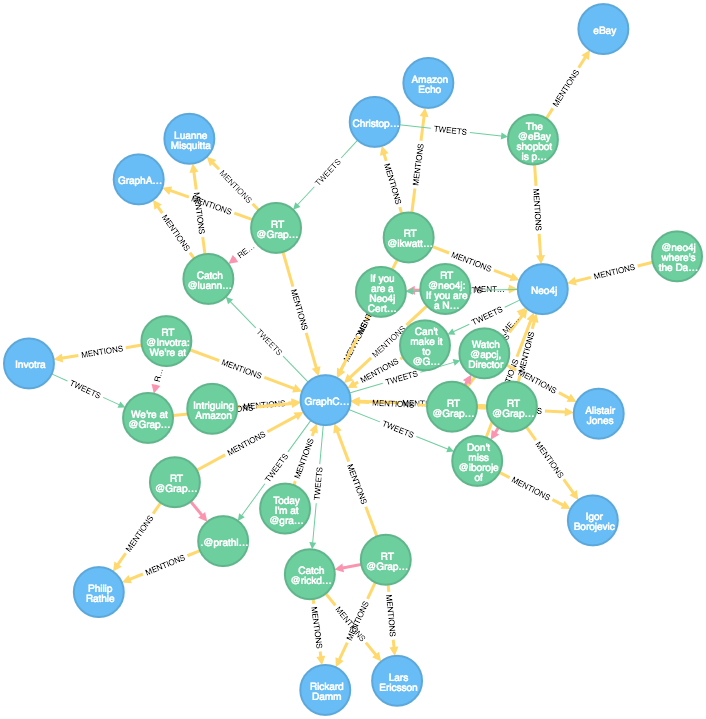
This looks quite nice already!
Let's find out which user is mentioned most:
MATCH (t:Tweet)-[r:MENTIONS]->(mentioned:User) RETURN mentioned.name, count(r) as numberOfMentions order by numberOfMentions desc limit 10
results in:
| user | numberOfMentions |
|---|---|
| Neo4j | 1014 |
| GraphConnect | 613 |
| Emil Eifrem | 236 |
| Jim Webber | 150 |
| ICIJ | 149 |
| Rik Van Bruggen | 99 |
| GraphAware | 88 |
| LARUS | 86 |
| Philip Rathle | 86 |
| CluedIn | 69 |
If we exclude organization accounts, the strongest influencers in the graph are Emil, Jim, and Rik. They most certainly were no lonely documents.
Let's continue exploring and find out who are writing the tweets containing mentions:
MATCH (u:User)-[:TWEETS]->(t:Tweet) RETURN u.name as user, count(t) as numberOfTweets order by numberOfTweets desc limit 10
| user | numberOfTweets |
|---|---|
| GraphConnect | 433 |
| Hakaishin Hokutosei | 379 |
| Neo4j | 244 |
| Yuxing Sun | 113 |
| Christophe Willemsen | 109 |
| Neo Questions | 85 |
| Bence Arato | 42 |
| Cedric Fauvet | 41 |
| Nigel Small | 38 |
| Mark Wood | 36 |
GraphConnect and Neo4j seem quite obvious, but I don't know Hakaishin Hokutosei and 379 seems to be a lot of tweets. What is this user tweeting about?
MATCH (u:User)-[:TWEETS]->(t:Tweet) where u.name = "Hakaishin Hokutosei" RETURN t.text limit 100
| t.text |
|---|
| RT @BenceArato: Major @neo4j milestones from version 3.0 to current to future plans #GraphConnect https://t.co/J99pXpSzV5 |
| RT @GraphConnect: .@jimwebber: #Neo4j doesn't do crazy JOINs or sets -- it simply chases pointersn#GraphConnect |
| RT @GraphConnect: .@jimwebber: Because #Neo4j is a native #graphdatabase and we own the whole stack, we can build to any clustering need… |
| RT @GraphConnect: .@jimwebber: #Neo4j 3.1 introduced security and Causal Clusteringn#GraphConnect |
| RT @GraphConnect: .@jimwebber: Causal Clustering, intro-ed in #Neo4j 3.1, can now span multiple data centersn#GraphConnect |
| RT @GraphConnect: .@jimwebber: #Neo4j 3.2 drivers are also more aware of Causal Clustersn#GraphConnect |
| RT @GraphConnect: .@jimwebber: #Neo4j 3.2 now is able to use #Kerberos, esp for those of you in #FinServ who are required to use itn#GraphC… |
| RT @matethurzo: Closing keynote of #graphconnect @jimwebber is always fun to watch #graph #graphdb #conferenceday #neo4j #devlife https://… |
| RT @mfalcier: Watching @neo4j #graphconnect Dr. @jimwebber 's talk from the sofa? Awesome! https://t.co/U0bCXGEd0D |
| RT @GraphConnect: .@jimwebber: Last year in London, #Neo4j 3.0 abolished the upper storage limit altogethern#GraphConnect |
Wait a second, every tweet is starting with "RT". Is he only retweeting, or do we have self-written as well?
Let's see:
MATCH (u:User)-[:TWEETS]->(t:Tweet) where u.name = "Hakaishin Hokutosei" and not (t)-[:RE_TWEETS]->() RETURN count(t)
| count(t) |
|---|
| 0 |
So we need to separate tweets from retweets to make a difference between original writers and retweeters:
MATCH (u)-[r1:TWEETS]->(t) where not (t)-[:RE_TWEETS]->() optional match (u)-[:TWEETS]->(rt)-[r2:RE_TWEETS]->() RETURN u.name, count(distinct r2) as numberOfReTweets, count(distinct r1) as numberOfTweets order by numberOfTweets desc
| u.name | numberOfReTweets | numberOfTweets |
|---|---|---|
| GraphConnect | 238 | 195 |
| Neo4j | 65 | 179 |
| Yuxing Sun | 0 | 113 |
| Neo Questions | 0 | 85 |
| Mark Wood | 4 | 32 |
| Bence Arato | 18 | 24 |
| Carina Birt | 3 | 23 |
| Marlon Samuels | 0 | 20 |
| Daily Tech Issues | 0 | 16 |
| Andres L. Martinez | 1 | 15 |
| Neo4j France | 11 | 15 |
| Louis Dubruel | 0 | 15 |
| Nigel Small | 23 | 15 |
| Adam Hill | 5 | 15 |
| Rik Van Bruggen | 1 | 15 |
What are the most popular tweets?
MATCH (rt)-[r2:RE_TWEETS]->(t)[:TWEETS]-(u) RETURN u.name AS user, t.text, count(rt) AS numberOfRetweets ORDER BY numberOfRetweets DESC
| user | t.text | numberOfRetweets |
|---|---|---|
| Mar Cabra | Work with @ICIJorg from DC, Paris or Madrid for 6 months making sense of complex data and graphs thanks to @neo4j's… https://t.co/Z0rR3Rt7zV | 20 |
| ICIJ | Interested in using data to find stories? Want to join ICIJ's next project? Apply for the Connected Data Fellowship https://t.co/LUdsjWKwRJ | 18 |
| William Lyon | Democratizing Data at @AirbnbEng w/ Dataportal, a new tool for scaling data search and discovery powered by @neo4j nnhttps://t.co/e12fHuA26M | 18 |
| Pat Patterson | Visualizing & Analyzing Salesforce Data with #StreamSets Data Collector & @Neo4j https://t.co/DunEFtAPyO Thx for gr… https://t.co/pXwBISQtme | 18 |
| ICIJ | Exciting announcement: We're now hiring a Neo4j Connected Data Fellow! More info & how to apply here: https://t.co/knjHKgyQiz #GraphConnect | 17 |
| Dr. GP Pulipaka | Announcing Neo4j in the Microsoft Azure Marketplace (Part I). #BigData #DataScience #Neo4J #Azure #Analytics… https://t.co/1XEqQHgedu | 16 |
| Kursion | #GraphConnect Neo4j 3.2 ready to download today https://t.co/QZu3XvAjts | 15 |
So the most popular tweets are about ICIJ and there Connected Data Fellowship, or the new Neo4j version.
Last but not least: What are the tweets that received the most retweets and can be declared winners of the least "lonely document" award (if that would be a real award):
MATCH (rt)-[r2:RE_TWEETS]->(t)[:TWEETS]-(u) RETURN u.name as user, count(rt) as numberOfRetweets order by numberOfRetweets desc
Rik van Bruggen
Or as my dear friend Rik would say. "Maybe I'm the most lonely document and that's the reason why I tweet that much about Neo4j, I don't have any hobbies. ;) "
Our Ideas
Explore More Blogs




Contact