Every Agile team has to deal with whatever they've put out in the wild next to their "regular" work. How to handle the - by definition - unknown load of production emergencies when you're trying to achieve a stable pace? You can deal with emergencies by performing triage to either reject, defer or accept. You can set up a buffer to absorb some of the uncertainty, and finally you should make sure that you take the time to reduce the number of emergencies by building quality in. If you find you are mostly doing maintenance, you can consider doing Kanban.
The Context
In ye olden days of waterfall projects I never had to deal with that horror of horrors, maintenance. I'd be part of a team building something new, and you could keep going on until the end of the project. It was the maintenance department that would have to deal with the nonsense I had created. Ah, those were the days... all the fun without the hangover afterwards :-)
But Agile teams, or in fact any team that starts delivering early and often (in my later waterfall days I'd already started to figure out that maintenance pretty much starts after the first two weeks... :-) ) deliver long before it's even possible to hand the project over - if at all. The nature of frequent delivery means that the team has to deal with all issues that arise themselves. The first reason is because they are the ones who can do it, the second is that you want to integrate fixes into the team's work anyway: they still need to deliver new versions of that same software...
In my consultancy work I've seen this issue come up with every single Agile team I've known, so this is not a unique situation for a small number of teams. All Agile teams have learn how to deal with this issue!
The Problem

In a Scrum team, the problem will generally surface after one or more Sprints where a number of "production incidents" or similar unplanned mayhem took up so much of the team's time that they did not achieve their planned Sprint goal. The result is that a team has a hard time planning for the next Sprints. The first problem is that they do not know their "real" Velocity, the second is that they have to somehow factor in the - by definition unpredictable - production incidents.
But watch out, there is a pitfall hidden in the above paragraph. Predictability is not the end goal in Agile! Predictability is important to know when a release is shipped, and to know how to pace the team. But I've seen too many cases where teams try to "predict harder" when they should be adapting better. When dealing with the unpredictable, the focus should be on adaptation first, not on more planning beforehand. That would be a return to The Way Of The Waterfall...
The Goal
So there we have it: the goal is to be able to absorb a reasonable amount of uncertainty, striking a balance between robustness and speed.
The Solutions
Before I present some solutions, let me state this right away: if the amount work of unplanned production incidents is significant compared to the "regular" work, there is no way you can achieve sufficient stability. You'll need to fix the root causes of all those production issues first. More on that later.
Solution 1: Perform Triage - and Reject
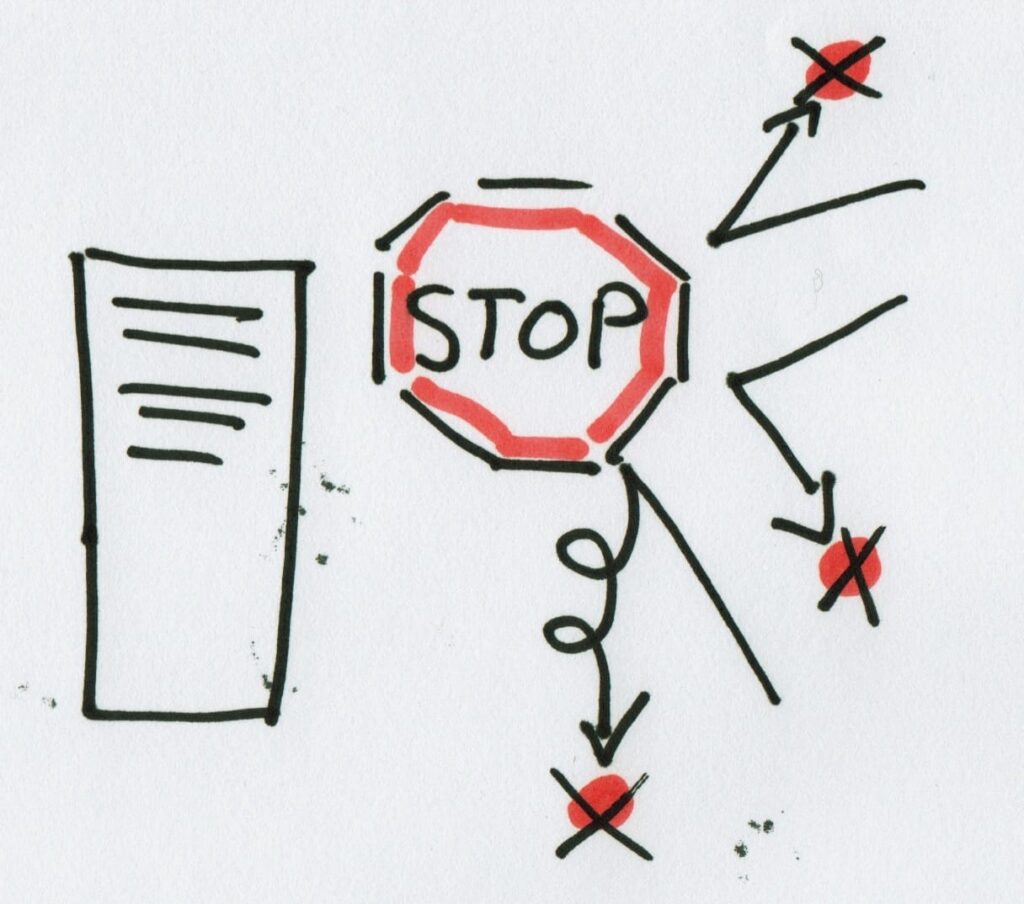
The first thing to check is if you want to fix that production issue at all. This is not as silly as it might seem at first. There are so many cases where a production emergency is not an emergency at all, and should not even have been brought in in the first place! Some examples of "noncidents":
- Sales storms in with "the deal of the century": "If we get feature X in NOW, we can win over customer X!". In my experience this is always due to an uneducated and undisciplined Sales department. The root cause here is that Sales promised things they shouldn't have, and they need to save their own skin now. It is ALWAYS possible to wait two weeks for a new feature.
- Some stakeholders "upgrade" normal requests to production emergencies in an attempt to bypass the negotiations around the backlog. "It's a blocking issue that I can't get that feature!". "Oh? Did the system crash? Is something not working?". "Well... no, but it's a real blocker for my work!". That stakeholder may have a genuine need, but that does not make it a production emergency.
So solution 1 is: a strong Product Owner who performs triage on all production issues. If it's a real production issue then by all means fix it. But I can guarantee that you'll find a good number of issues that should not be emergencies at all... BTW, a Product Owner performing triage in this way is what James Coplien calls a Firewall in his organizational patterns book.
Solution 2: Perform Triage - and Defer the fix until at least the next Sprint
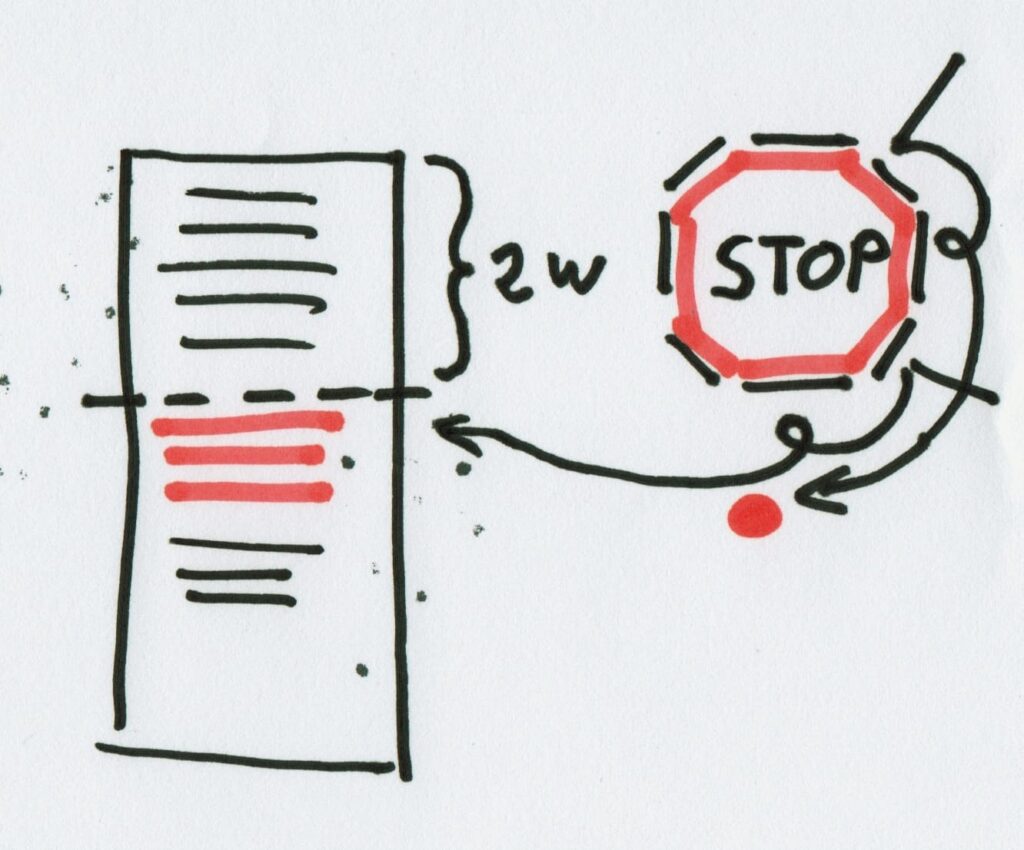
"We found this really big problem! We need it fixed right now!". "Sure, we'll get right on it. How long has this issue been in the system?". "Well, for over a year, but we just found out about it!". "It's been in there for a year? ...And you can't wait two more weeks for a fix?"
Solution 2 is an extension of Solution 1. An emergency might indeed be important to fix, but there's an important criterion to an emergency: it's only an emergency if it must be fixed in the current Sprint. If you can defer the problem to next Sprint, there is no problem! The team can pick it up as part of their regular process, plan it, build it, and deliver at the end of next Sprint. Again this is a Product Owner responsibility: next to the decision to reject, a good Product Owner will make sure that everything that can be deferred will be.
Solution 3: Reserve a buffer to deal with unexpected issues
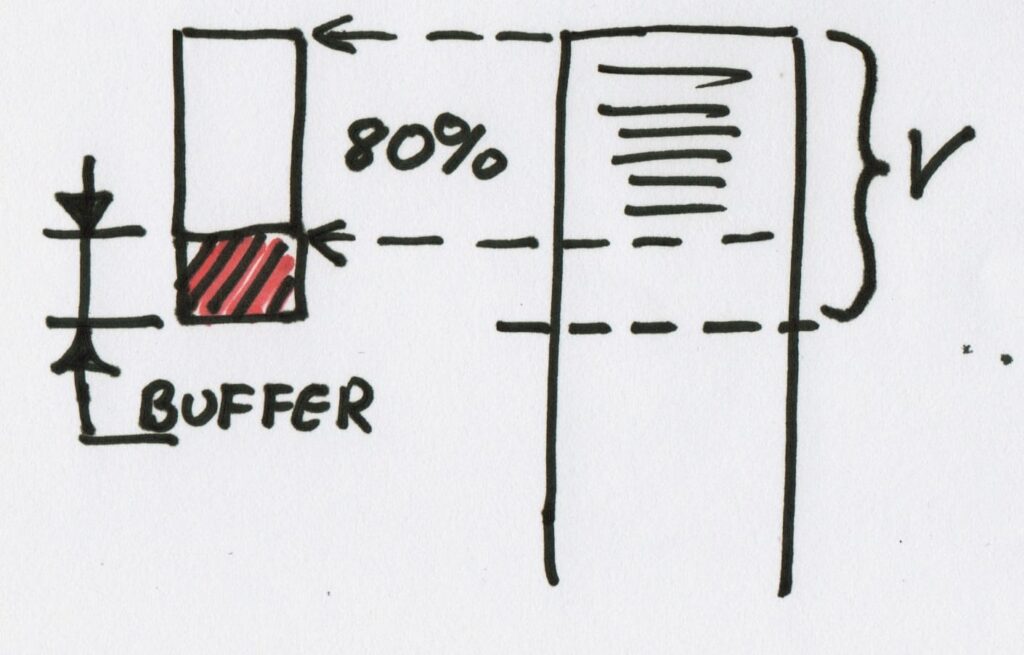
If you've done Solutions 1 and 2, whatever you're left with should be real issues that you have to fix as soon as possible. The best way I know to deal with this is to reserve a buffer of time or story points that is left unplanned. This works especially well if the historical workload of any issues coming up is reasonably stable. You do not know what you'll be doing, but you know how much effort it will take.
Watch out though, using a buffer can blow up in your face! The first danger is the size of the buffer. If the buffer is a significant percentage of the Sprint, say more that 1/5 of your velocity, then you'll end up with a big hole in your planning process. So follow Buffer Rule 1: the buffer is not for backlog items. Try to keep the buffer as small as possible.
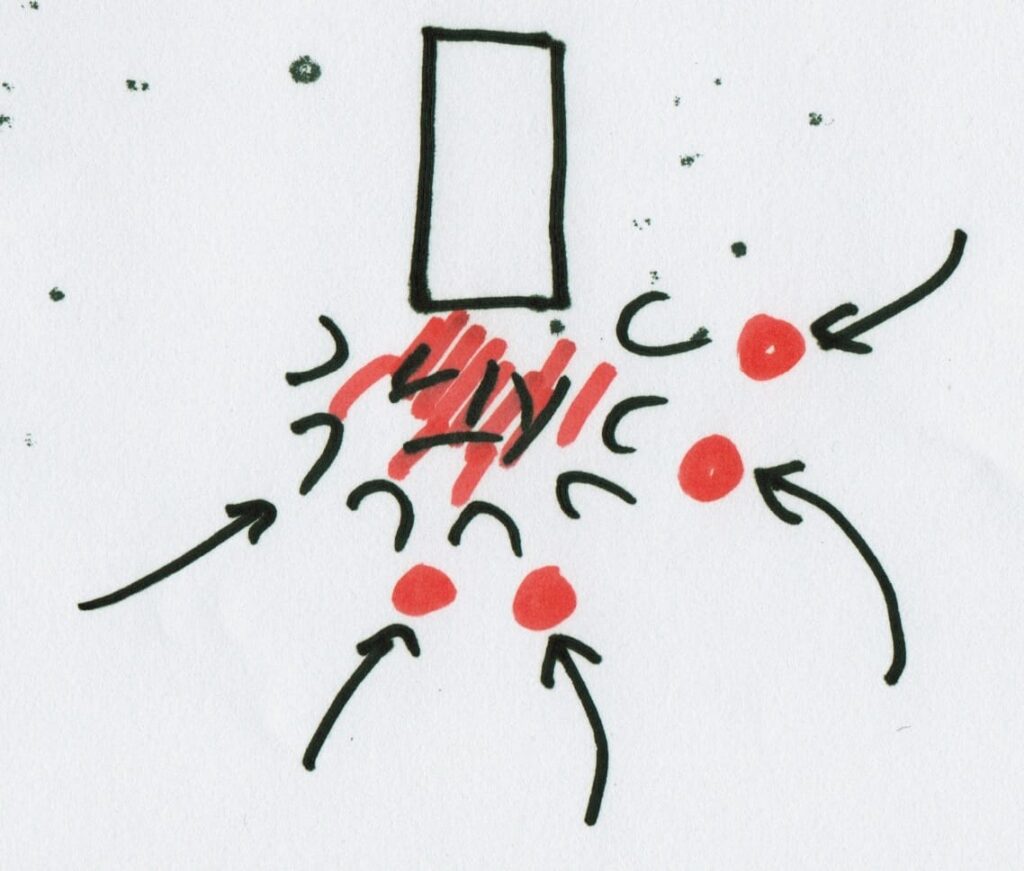
The second danger with using buffers is what I already discussed in Solution 1: the moment your stakeholder smell a workaround in the regular process, you can be sure they'll dive onto it. A buffer really, really needs to be protected from unintended use. So perform good triage!
The third danger is buffer overflow. Just like in a computer this leads to blowing up the process. If the buffer is used, you'll need to track how much of the buffer has been used, otherwise you'll be in for a surprise at the end of the Sprint.
Solution 4: Fix root causes, improve quality
This solution is presented as number 4 because the first three are in logical order when you're trying to control the damage, but in the end you'll want to do the most important thing of all: fix issues so they stay fixed, build in quality so that you don't have emergencies at all!. Now this is something we should be doing anyway, and is not unique for Agile projects: you want to do this in any project! But there is an extra Buffer Rule that is relevant in this respect (Credit goes to Jeff Sutherland on this one, I learned this rule when we do CSM trainings). Buffer Rule 2: If you overflow the buffer, abort the Sprint. If you have such issues that you can not even keep emergency work limited to a small buffer, you have no business trying to make progress building in features. Abort, use the Sprint to fix underlying root causes, and try again next Sprint. Coincidentally, Buffer Rule 2 also works wonders for all those stakeholders trying to "upgrade" their own agenda: "do you really want that issue fixed now? The team estimates that this is two points of work, and this would overflow the buffer. We would have to abort the Sprint, and you also would not get those other user stories you asked for! Oh... um. Well, I guess it isn't that much of a problem..." (And it wasn't... Real story!).
Extra: Size the team right
Team size is not a central focus in dealing with emergencies, but it is a factor to be aware of. A small team performs better because it has less overhead, but it is less robust against losing members. A small team is less robust against things like illness or something that pulls a team member away like... production emergencies maybe?. On a 10 person team losing one person "only" means a hit of about 10% in productivity (this is a simplified calculation of course, this assumes all team members are totally replaceable on a moments notice), in a three person team losing that same person would already mean a whopping 33%! The sweet spot tends to be around 7-9 people. Small enough to reduce overhead, large enough to absorb some production loss.
And finally... consider using Kanban instead of Scrum
If you find that your team is doing more maintenance than "new stuff", you might consider using Kanban instead. This is because the granularity of Kanban is stories, not Sprints. If there is a production emengency the is already an intrinsic shorter wait for it to be picked up because of this. Kanban is about flow, while Scrum is about iterations. The two styles are close enough that I've seen a Scrum team transition into "flow mode" when they scaled down and only did maintenance, and went back to Scrum when a new release was planned, and they scaled up again.
In Conclusion
Every Agile team has to deal with whatever they've put out in the wild next to their "regular" work. You can deal with emergencies by performing triage to either reject, defer or accept. You can set up a buffer to absorb some of the uncertainty, and finally you should make sure that you take the time to reduce the number of emergencies by building quality in. If you find you are mostly doing maintenance, you can consider doing Kanban.
Written by
Serge Beaumont
Our Ideas
Explore More Blogs




Contact