Blog
Building Resilient Public Networking on AWS: Part 4

Region Evacuation with static anycast IP approach
Welcome back to our comprehensive "Building Resilient Public Networking on AWS" blog series, where we delve into advanced networking strategies for regional evacuation, failover, and robust disaster recovery. Here’s a summary of our journey so far:
- Revisiting Networking Concepts from the Client’s Perspective: If you missed our foundational networking concepts in the first installment, catch up here. We established the essentials for our discussions.
- Deploy Secure Public Web Endpoints: We explored deploying a web server and securing its public endpoint on AWS, including DNS management with Route 53 and integration with third-party DNS hosting providers. Find the detailed guide here.
- Region Evacuation with DNS Approach: Our third post discussed deploying web server infrastructure across multiple regions and reviewed the DNS regional evacuation approach using AWS Route 53. Explore the details here.
- Region Evacuation with Static Anycast IP Approach: In this fourth blog post, we will deploy the web server infrastructure across multiple regions and explore region evacuation using AWS Global Accelerator with a static anycast IP approach. We’ll examine its benefits and considerations.
- Client’s TCP Persistent Connections and Why This Could Be a Problem: Concluding our series, we’ll address common HTTP client behaviors—TCP persistent connections. Understand why neglecting this can lead to potential failure of previously discussed approaches.
Moreover, we’ve prepared a GitHub repository to complement this blog series. It provides Infrastructure as Code (IaC) using AWS Cloud Development Kit (CDK), allowing you to deploy and manage the necessary infrastructure effortlessly.
Introduction
In this fourth blog post, we will continue our journey by deploying our web server infrastructure across multiple regions (us-east-1 and us-west-2), focusing on region evacuation using the static anycast IP approach provided by AWS Global Accelerator.
We will utilize Infrastructure as Code (IaC), and the corresponding code for this blog post can be found here. For those new to AWS CDK or needing a refresher, we recommend starting with this guide on “Getting started with the AWS CDK”.
We will explore the benefits and drawbacks of this technique and compare it with the DNS region evacuation approach using Route 53 that we discussed in our previous blog post. We will also see how this new method can overcome most of the disadvantages we identified with the previous approach.
Without further ado, let’s get into the business!
Architecture Overview
The accompanying diagram visually represents our infrastructure’s architecture, highlighting the relationships between key components. While the CDK stacks deploy infrastructure within the AWS Cloud, external components like the DNS provider (ClouDNS) require manual steps. These steps are clearly marked in the following diagram.
One of the key differences between the approach in this post and the previous one is that here, the Application Load Balancers (ALBs) are private, so the only element exposed directly to the Internet is the Global Accelerator and its Edge locations.
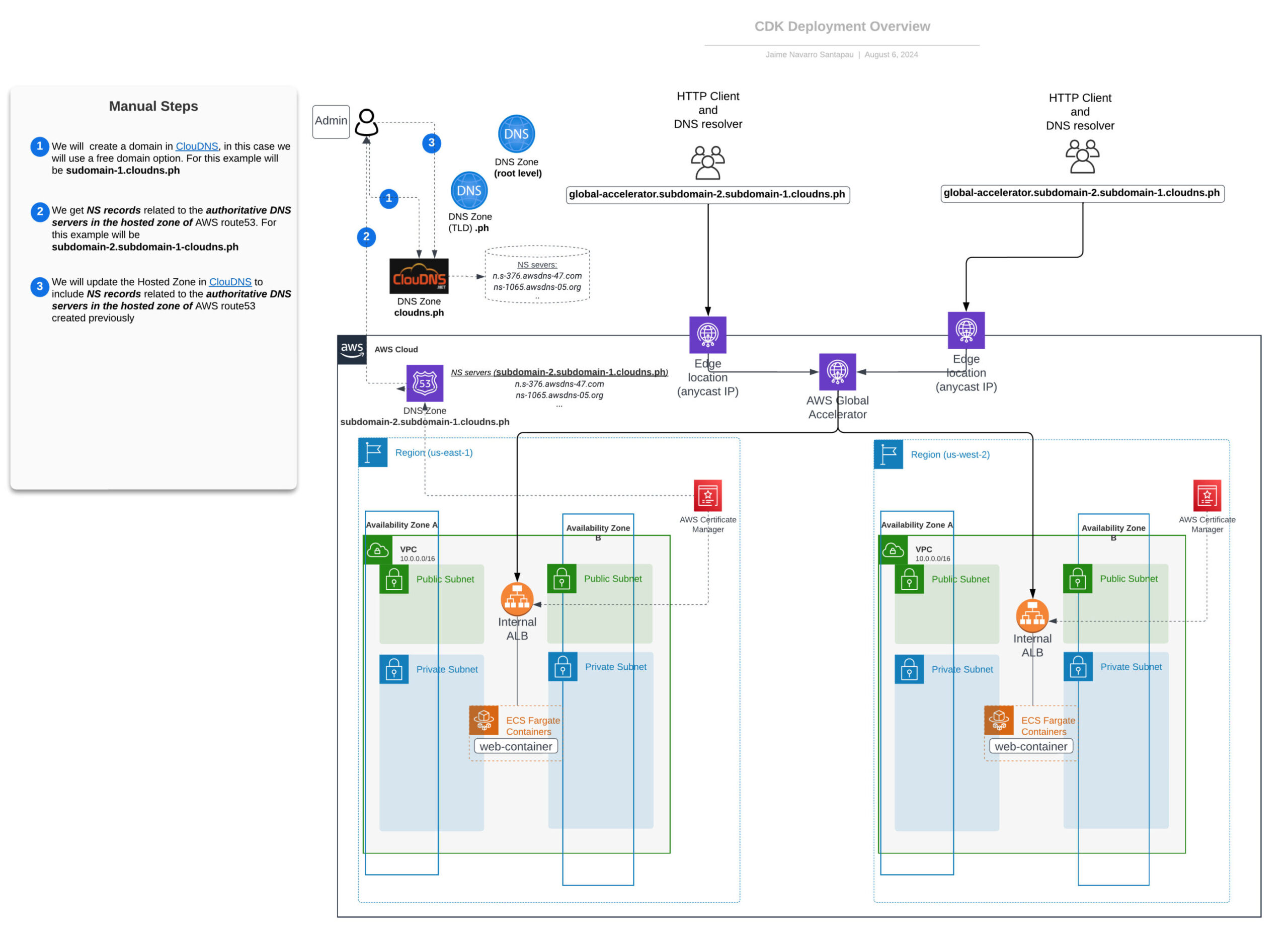
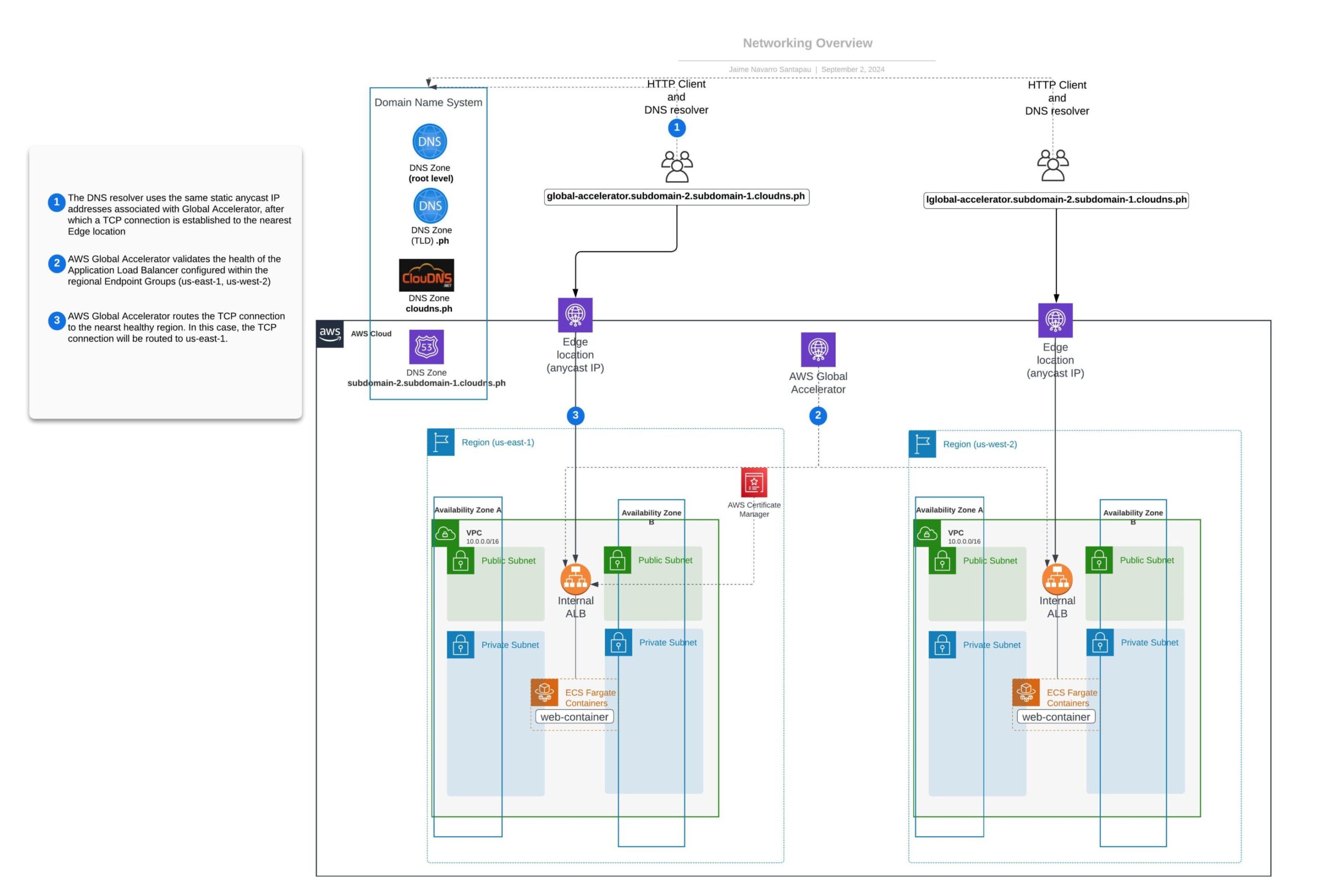
Networking Overview – Static Anycast IP using Global Accelerator
AWS Global Accelerator provides two static anycast IPs. An anycast IP is a network addressing and routing methodology in which a single IP address is shared by servers in multiple locations called Edge locations. Routers direct packets addressed to these IPs to the nearest location using their normal decision-making algorithms, typically the lowest number of network hops.
This setup ensures that clients always connect to our application using the nearest AWS Edge location, from the Edge location the TCP connection will travel inside the AWS network reducing the number of hops and consequently the latency for that connection.
In this segment, we explain how AWS Global Accelerator uses static anycast IPs to route user traffic to the optimal regional endpoint based on health and network conditions. The included diagram helps visualize the traffic flow enhanced by this setup.
Deployment Steps and Validations
As we progress through this blog post series, we build upon the knowledge and insights gained from previous posts. Therefore, the step-by-step deployment and validation guide is omitted here. However, you can access this guide by following the Deployment Steps and Validations Guide link in our GitHub repository.
Region Evacuation with Static Anycast IP Approach Using Global Accelerator
After deploying the necessary infrastructure using the provided guidelines, we will show a basic example of how to evacuate a region (in this case, us-east-1) using AWS Global Accelerator.
There are different approaches to evacuate a region using AWS Global Accelerator. But to keep this example as simple as possible, we will use a built-in feature of AWS Global Accelerator that routes traffic to the healthy endpoints.
In the following sections we will review this step-by-step region evacuation example.
Step 1 - Review which is your closest AWS region
Before simulating a failure, it’s essential to identify your closest AWS region. This step ensures that your TCP connections will be rerouted to a healthy region, allowing you to verify that the region evacuation process functions as expected.
To determine your closest region, you can use the following curl command, which sends a request to the AWS Global Accelerator and returns the region to which your request is routed:
curl https://global-accelerator.subdomain-2.subdomain-1.cloudns.ph
{
"MessageResponse": "Region: us-east-1. HTTP Response code: 200. Delay response: 0 seconds.",
"SocketRequest": "::ffff:10.0.182.85:18630",
"HeadersRequest": {
"x-forwarded-for": "188.26.219.81",
"x-forwarded-proto": "https",
"x-forwarded-port": "443",
"host": "global-accelerator.subdomain-2.subdomain-1.cloudns.ph",
"x-amzn-trace-id": "Root=1-66d47933-0264d457365086415ea1c500",
"user-agent": "curl/8.7.1",
"accept": "*/*"
},
"HeadersResponse": {
"x-powered-by": "Express"
}
}In this example, because we are based in Europe, the closest region is identified as us-east-1. This is why, in the next step, we will simulate a failure in that region.
Step 2 - Simulating Failure (us-east-1)
To simulate a failure in a region, we will stop the containers in that region (in our case, it will be us-east-1). As a result, our ALB will become unhealthy and start returning an HTTP 503 error code when attempting to reach our web server.
Use the AWS Console to update our Fargate task configuration:
- Open deployment configuration for you Fargate task
- Set the deployment config of “Desired tasks” to 0
- Click the button “Update” at the bottom of the page.
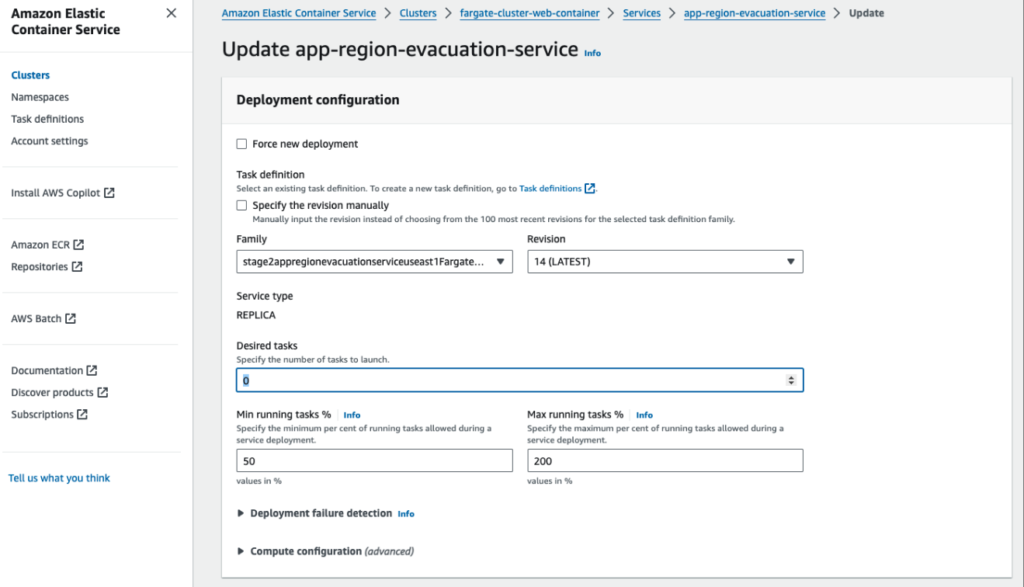
After a couple of seconds, the containers in this region will stop.
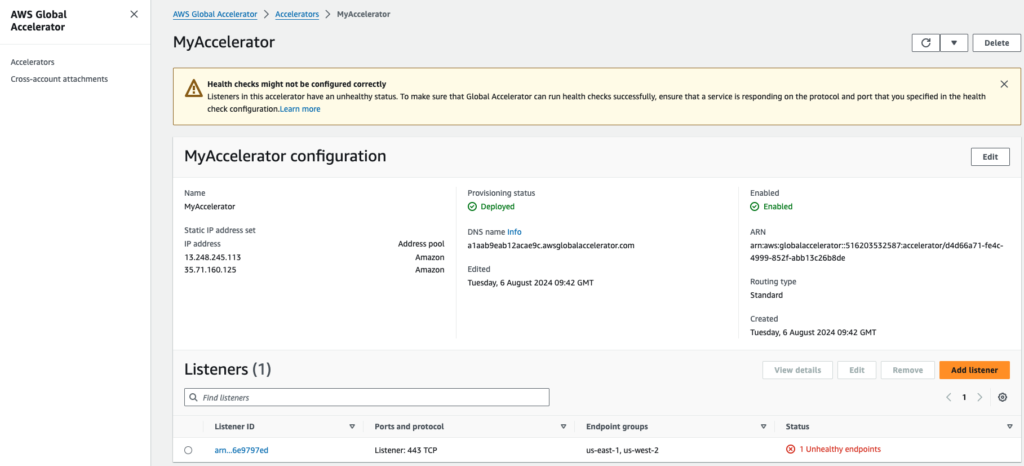
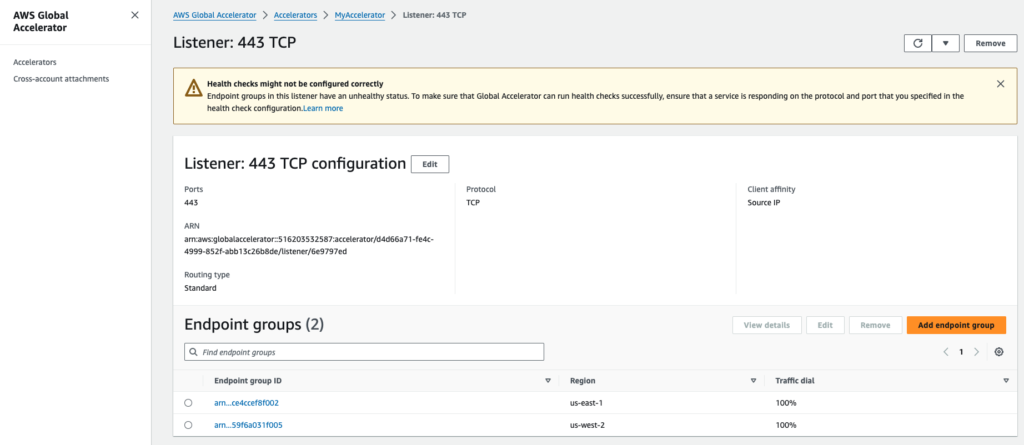
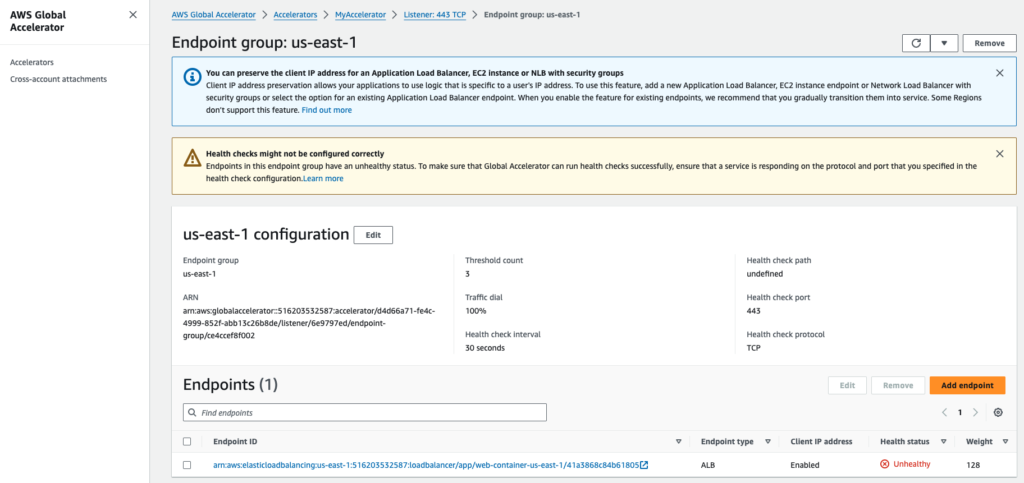
Step 3 – AWS Global Accelerator detects unhealthy ALB state
Once the containers are stopped, the ALB health checks will start to fail, and it will cause our ALB to be in an unhealthy state. This triggers AWS Global Accelerator to stop sending traffic to the unhealthy region and reroute it to the remaining healthy regions.
To review the state of Global Accelerator:
- Open the AWS Global Accelerator Dashboard
- Select your "Accelerator". In this case, the one with the name “MyAccelerator”.
- Check the "Listeners" tab to see the status of your endpoints. In this case, the listener for port 443 TCP.
- Open the "Endpoint Group" related to region us-east-1

Step 4 - AWS Global Accelerator Reroutes Traffic (to us-west-2)
To confirm that AWS Global Accelerator has stopped sending traffic to the unhealthy region (us-east-1) and has started rerouting traffic to the healthy regions, we can use a simple curl command:
curl https://global-accelerator.subdomain-2.subdomain-1.cloudns.ph
{
"MessageResponse": "Region: us-west-2. HTTP Response code: 200. Delay response: 0 seconds.",
"SocketRequest": "::ffff:10.0.241.224:63706",
"HeadersRequest": {
"x-forwarded-for": "188.26.219.148",
"x-forwarded-proto": "https",
"x-forwarded-port": "443",
"host": "global-accelerator.subdomain-2.subdomain-1.cloudns.ph",
"x-amzn-trace-id": "Root=1-66b1f8b0-296801ec6a94b4cb6a49145a",
"user-agent": "curl/8.6.0",
"accept": "*/*"
},
"HeadersResponse": {
"x-powered-by": "Express"
}
} The following diagram illustrates the final state of our networking setup after successfully evacuating the us-east-1 region.
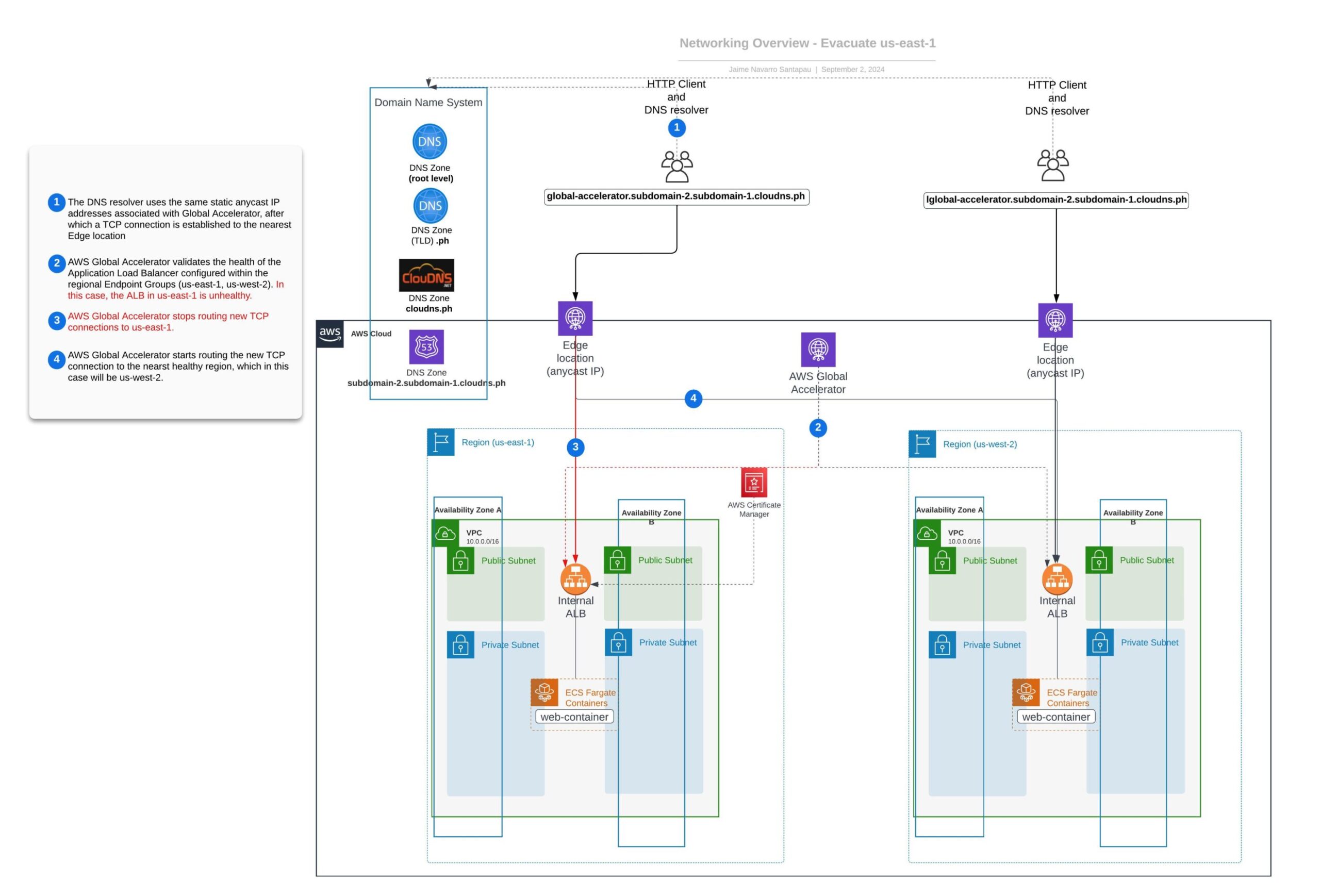
It's worth mentioning that this example is simplified for illustrative purposes. In real-world situations, you wouldn't want to stop containers in a region to start the region evacuation process.
That's why we will delve into more advanced strategies and solutions. Our Enhancements section explores other options to improve our original approach.
Advantages – Region Evacuation with Static Anycast IP Approach
Using Global Accelerator and its static anycast IP approach offers several advantages over the DNS-based region evacuation method with Route 53 discussed in our previous post, overcoming most the issues identified with that method.
- Improved Latency: All HTTP requests experience better latency because the traffic is routed through the AWS private network once it reaches the Edge location. Fewer hops on the Internet result in better and more consistent response times.
- Fine-Grained Traffic Control: AWS Global Accelerator allows for precise control over traffic routing. For example, you can route 80% of the traffic to one region. Traffic dials enable you to adjust the percentage of traffic directed to each AWS Region or endpoint group.
- Client Affinity: Client affinity ensures that the same client is always routed to the same region. By activating client affinity, TCP connections from a specific device will consistently reach the same region.
- Faster Failover: The failover mechanism with Global Accelerator is faster than the DNS latency record approach. It doesn’t rely on HTTP clients to start using new IPs for the domain to apply the region evacuation effectively. Instead, the new TCP connections are routed from the backend side to the healthy region. In real-life examples, regional evacuation with Global Accelerator can be completed in about 4 minutes.
- Increased Security: In this deployment, only the Global Accelerator is exposed to the internet, while the ALBs remain private.
- Consistent IP Addresses: Clients always connect using the same IP address, because AWS Global Accelerator exposes static anycast IPs, simplifying DNS management.
Disadvantages – Region Evacuation with Static Anycast IP Approach
While the static anycast IP approach using AWS Global Accelerator offers significant advantages, it is not without its drawbacks
- In the event the AWS control plane goes down, you won't have the chance to update traffic dials, not from AWS Console nor using CLI, which means that you won’t be able to tell AWS Global Accelerator to evacuate a region.
- Here some more details about AWS Global Accelerator SLA to be able to understand the impact of the previous drawback
- Control plane availability design is 99.9%. Which means that the control plane can be down for 8 hours and 45 minutes per year or 43 minutes per month.
- Data plane availability design is 99.995%. Which means that the data plane can be down for 26 minutes per year or 2 minutes per month.
- Here some more details about AWS Global Accelerator SLA to be able to understand the impact of the previous drawback
- Cost Implications: Global Accelerator might lead to increased costs due to its pricing structure, which involves a fixed hourly rate plus additional charges for the amount of data transferred through the service.
Enhancements and Automation
In this section, we will focus on how we can improve our solution to evacuate a region automatically to meet the requirements in a production environment.
CloudWatch Alarm Integration with Global Accelerator Endpoints
Integrating CloudWatch Alarms with Global Accelerator presents a notable advancement to our setup – it allows us to detect a wide range of issues.
In our example, our CloudWatch Alarms are fed by metrics generated by our ALB, but we could use any other metric that we thought could be more relevant. The beauty of this solution is its flexible nature - our CloudWatch Alarm could use any relevant metric to decide whether a region evacuation is necessary, giving us more robust control over when and why to initiate the evacuation.
To aid in understanding this setup and the AWS services needed, a detailed diagram is provided below illustrating the required interaction between CloudWatch Alarms, Event Bridge, Lambda function, and AWS Global Accelerator during an automated region evacuation process.
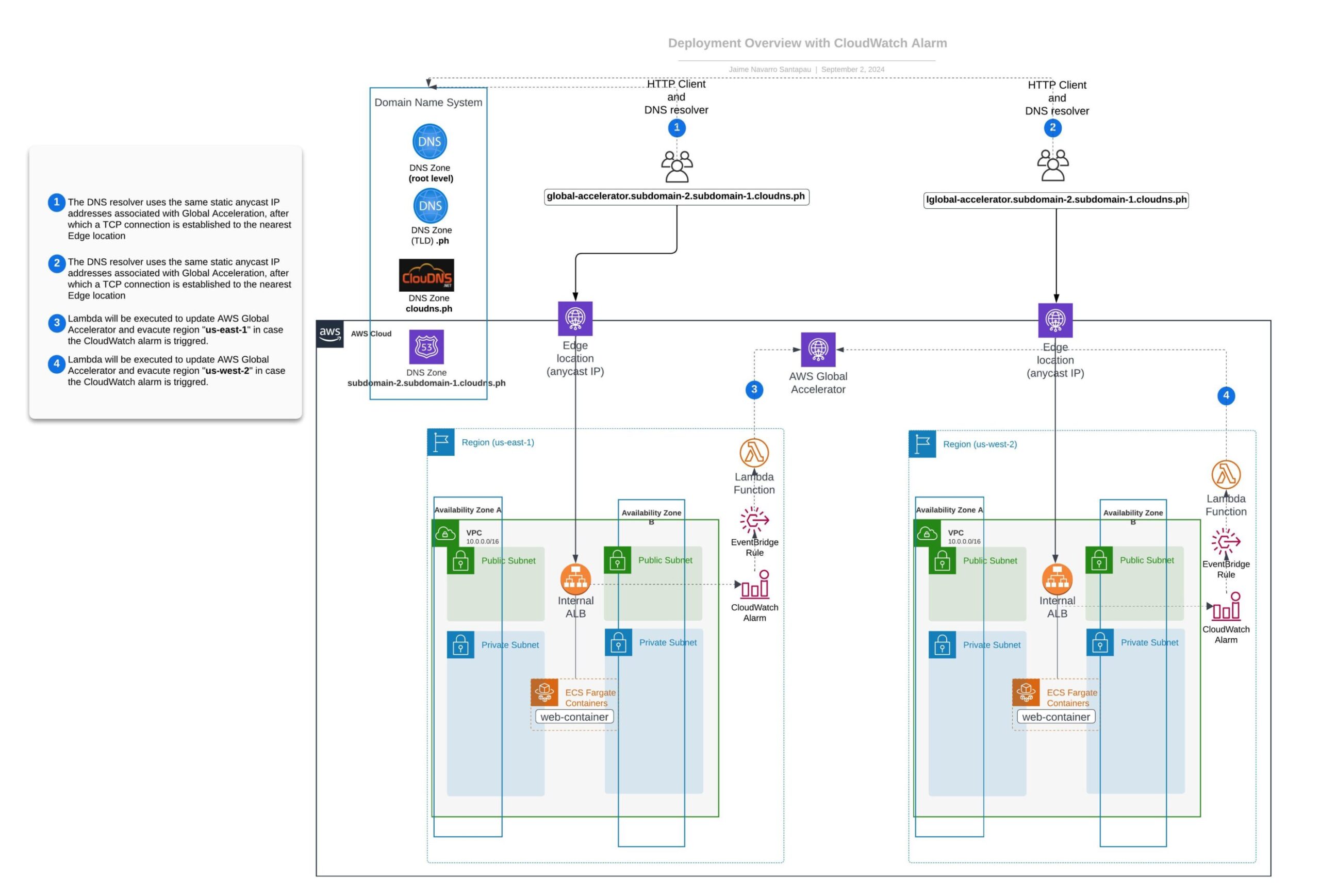
When CloudWatch Alarms detect a threshold breach (indicative of an unhealthy region), the following sequence is triggered:
- Alarm Activation: The specific CloudWatch Alarm changes its state to 'ALARM'.
- EventBridge Rule: This rule catches the alarm state change and triggers a designated AWS Lambda function.
- Lambda Function Invocation: The function executed will adjust the AWS Global Accelerator's traffic dials, ceasing traffic routing to the affected region and redirecting it to a healthier alternative.
By leveraging these automated enhancements, organizations can ensure a more precise, efficient, and timely response to regional disruptions, thus maintaining high availability and performance across distributed environments.
Conclusion and What's Next
We have now discussed two powerful approaches to regional evacuation on AWS. Our next post will conclude this series by examining the implications of TCP persistent connections and how overlooking this common client behavior can undermine even the most robust networking strategies.
Stay tuned for more insightful discussions and practical examples in the final installment of our series. Until then, we encourage you to experiment with the techniques covered and explore the resources below for deeper understanding.
Additional Resources
- AWS CDK Getting Started: This guide introduces essential AWS CDK concepts and outlines the installation and configuration process.
- AWS Global Accelerator Documentation: Explore the intricacies of AWS Global Accelerator with the official documentation, covering its features and configurations.
- AWS ACM Documentation (ACM) Documentation: Access the official AWS documentation for AWS Certificate Manager to explore features, use cases, and best practices.
- AWS Route 53 Documentation: Dive into the intricacies of AWS Route 53 with the official documentation, covering DNS management and domain registration.
- ClouDNS Documentation: Refer to the official ClouDNS documentation for detailed insights into their DNS hosting services and configurations.
- GitHub Repository for Practical Examples: Explore the GitHub repository used in this blog post series to access practical examples and infrastructure as code (IaC) configurations.
Written by
Jaime Navarro Santapau
I'm a Senior DevOps Engineer with over 18 years of experience starting as a Software Engineer followed by Backend Software Development Lead. Currently, I manage complex infrastructure and deliver scalable solutions. Proficient in cloud platforms like AWS and Azure, containerization technologies (Docker, Kubernetes), and automation tools. Proven track record in driving successful DevOps implementations, streamlining workflows, and improving team collaboration. Strong expertise in CI/CD pipelines, monitoring, and scripting languages.
Our Ideas
Explore More Blogs


From Spec to Code: Building Software with Spec Kit
This article walks through the full workflow, from installation to a working implementation, covering both greenfield projects and extending an...
Hidde de Smet, Emanuele Bartolesi


Contact