Blog
Binning MapType, Keeping Yield. How Variant Delivered 10x Speed for Semiconductor Test Logs in Databricks

"The fine art of data engineering lies in maintaining the balance between data availability and system performance."
Ted Malaska
At Melexis, a global leader in advanced semiconductor solutions, the fusion of artificial intelligence (AI) and machine learning (ML) is driving a manufacturing revolution. By deploying predictive analytics and intelligent automation, the company optimizes production yields, preempts equipment failures, and ensures the precision demanded by automotive and industrial applications. Central to this transformation is the testlogs data set —a mission-critical dataset generated during the functional validation of semiconductor wafers and dies.
The Data Challenge
Each month, Melexis generates terabytes of testlogs data, a volume that underscores both the complexity of modern semiconductor manufacturing and the imperative for rapid, reliable analytics. These datasets form the backbone of quality assurance (QA) decisions. Hence, timely insights are paramount.
The Data Platform: Databricks
Melexis manages its testlogs data on Databricks, a cloud based data platform that lets you run data pipelines and machine learning models at scale. It is built on top of Apache Spark, a distributed computing engine for big data processing. Databricks promises to deliver fast, reliable analytics on large datasets.
The Performance Paradox
Despite Databricks’ promises, queries on 1TB of testlogs data crawled for over 4 hours—far exceeding the 1-hour SLA required for timely production decisions. Even more perplexing: DuckDB, a lightweight single-node engine, outpaced Databricks on smaller subsets. Scaling compute resources provided temporary relief but at unsustainable costs, with benchmarks revealing a linear scalability issue:
4 workers × 4 hours = 16 workers × 1 hour = 1TB processedThe root cause? A deceptively simple design choice: the MapType column storing test measurements.
The Hidden Cost of Flexibility
The measurements column—a flexible key-value map capturing hundreds of dynamic test parameters—proved to be a query execution nightmare. While its flexibility avoided managing hundreds of sparse, dynamic columns in a wide table format, it masked a critical bottleneck: linear key searches at scale.
Let’s dissect the problem, starting with the original testlogs table.
The Original Testlogs Table
Table Schema
The testlogs table has the following simplified schema:
| Column | Data Type | Description |
|---|---|---|
| lot_id | string | Identifier for the production lot. |
| test_outcome | string | Result of the test (e.g., PASSED, FAILED). |
| measurements | map<string, string> | Key-value pairs of test parameters (e.g., voltage, temperature, error codes). |
Example Data:
| lot_id | test_outcome | measurements |
|---|---|---|
| lot_001 | PASSED | {param1 -> "1.0", param2 -> "HT2"} |
| lot_002 | FAILED | {param1 -> "1.5", param3 -> "true"} |
| lot_003 | PASSED | {param2 -> "FX8", param4 -> "40-23"} |
Why MapType?
The measurements column used Spark’s MapType for two key reasons:
- Schema Flexibility: Hundreds of dynamic test parameters (e.g.,
param1,param2) could be added without altering the table schema. - Semi-Structured Storage: Measurement values have varying types (e.g., doubles, booleans, strings). By casting these values to strings we essentially create a schema-on-read approach.
This design avoided the maintenance nightmare of managing 1,000+ columns for every possible test parameter. However, it came with a hidden cost: query performance.
Choosing between flexibility or performance is a classic data engineering dilemma.
The Query: Normalizing the Map
Analysts needed to compare specific parameters across tests. For example, to analyze param1 (a numeric value) and param2 (a categorical code) for multiple test results, requires the following query:
SELECT
lot_id,
test_outcome,
CAST(measurements["param1"] AS DOUBLE) AS param1, -- Extract as double
measurements["param2"] AS param2 -- Leave as string
FROM testlogs
Output:
| lot_id | test_outcome | param1 | param2 |
|---|---|---|---|
| lot_001 | PASSED | 1.0 | HT2 |
| lot_002 | FAILED | 1.5 | NULL |
| lot_003 | PASSED | NULL | FX8 |
In practice, this query would typically involve hundreds of parameters and millions of records. However, the core principal remains the same: extract specific keys from the map and cast them to their correct data types.
Problem Analysis: Why MapType Became the Bottleneck
On first glance, the MapType looks like a efficient data format. Spark’s MapType is memory efficiently stored in binary format. In addition, the keys and values are seperated into two arrays, allowing skipping of unneeded values. However, the keys and values are stored in the order of insertion and are therefore unsorted. This means that finding a key is very inefficient: Spark has to iterate through the keys array until a match is found.
Here is a simplified representation of the MapType binary format: 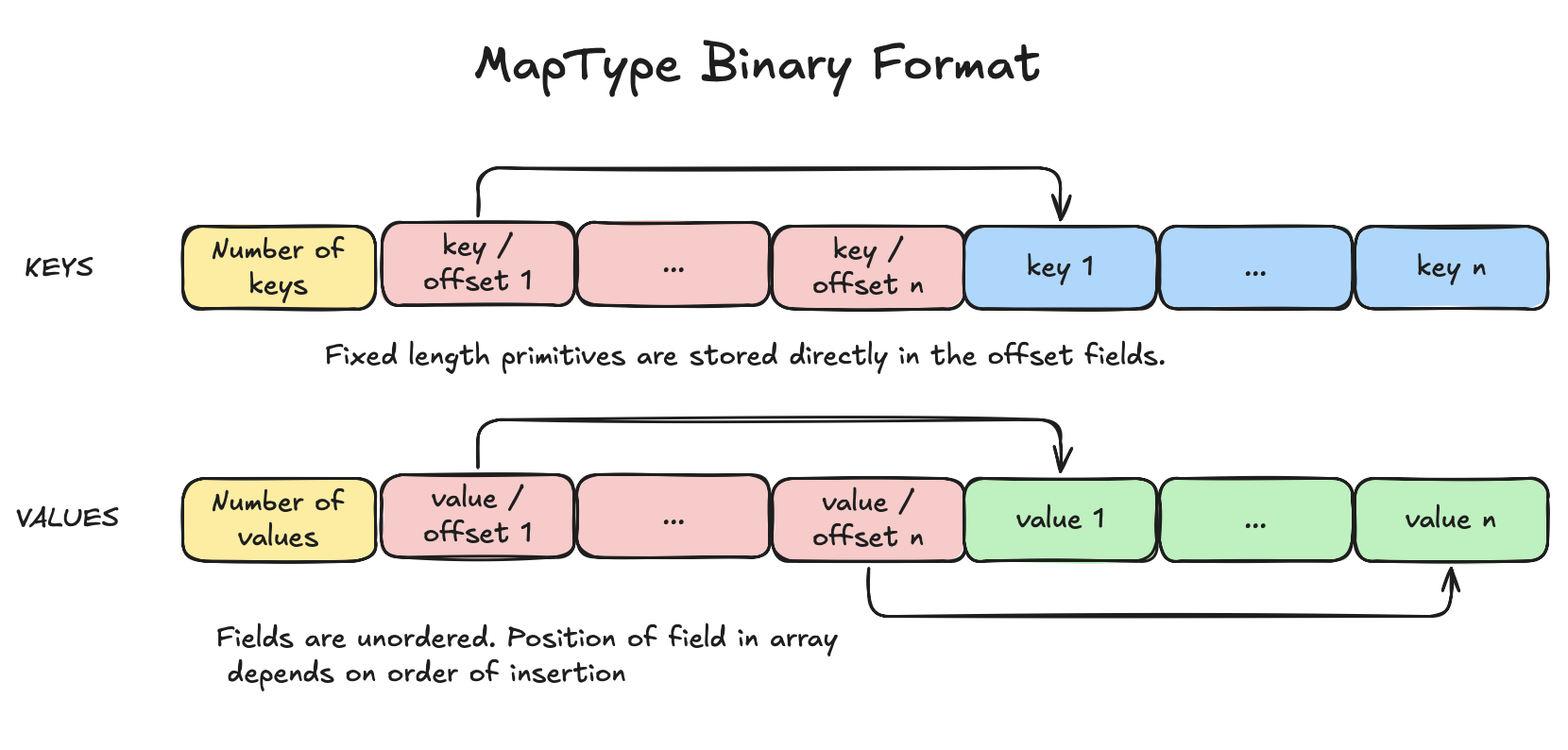
The keys array consists of a header and a number of keys field that specifies the number of keys inside the array. In addition, it contains "key or offset" fields that point to the start of the key in the key offset field. If the key is of a fixed length primitive type such as integer, float or boolean, then the key is stored directly in the key field. The values array is similar to the keys array. If a key is found, then its value can be found by jumping to the same index of the value offset field within the values array. Based on that offset, the value can be read.
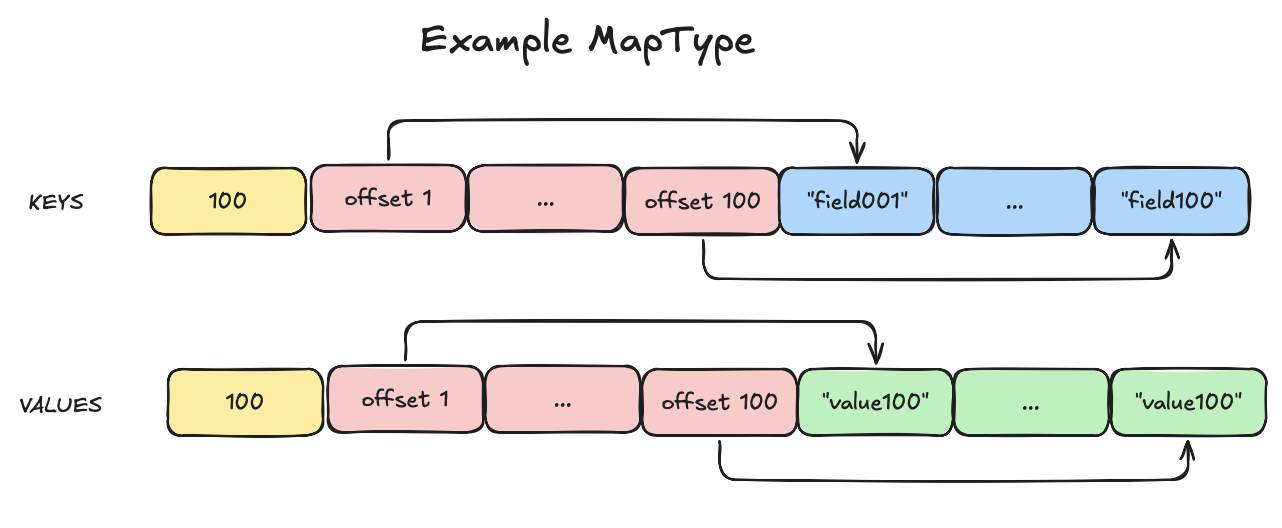
The linear key search problem
Iterating through the key array until a match is found is an O(n) operation per row. For each row, it's like reading a dictionary cover-to-cover to find a word. This works for small dictionaries, but for large ones, it's inefficient. In worst case scenarios, the number of checks equals to the number of keys in the map. This happens also when the key is not present in the map, a common occurrence in the testlogs data.
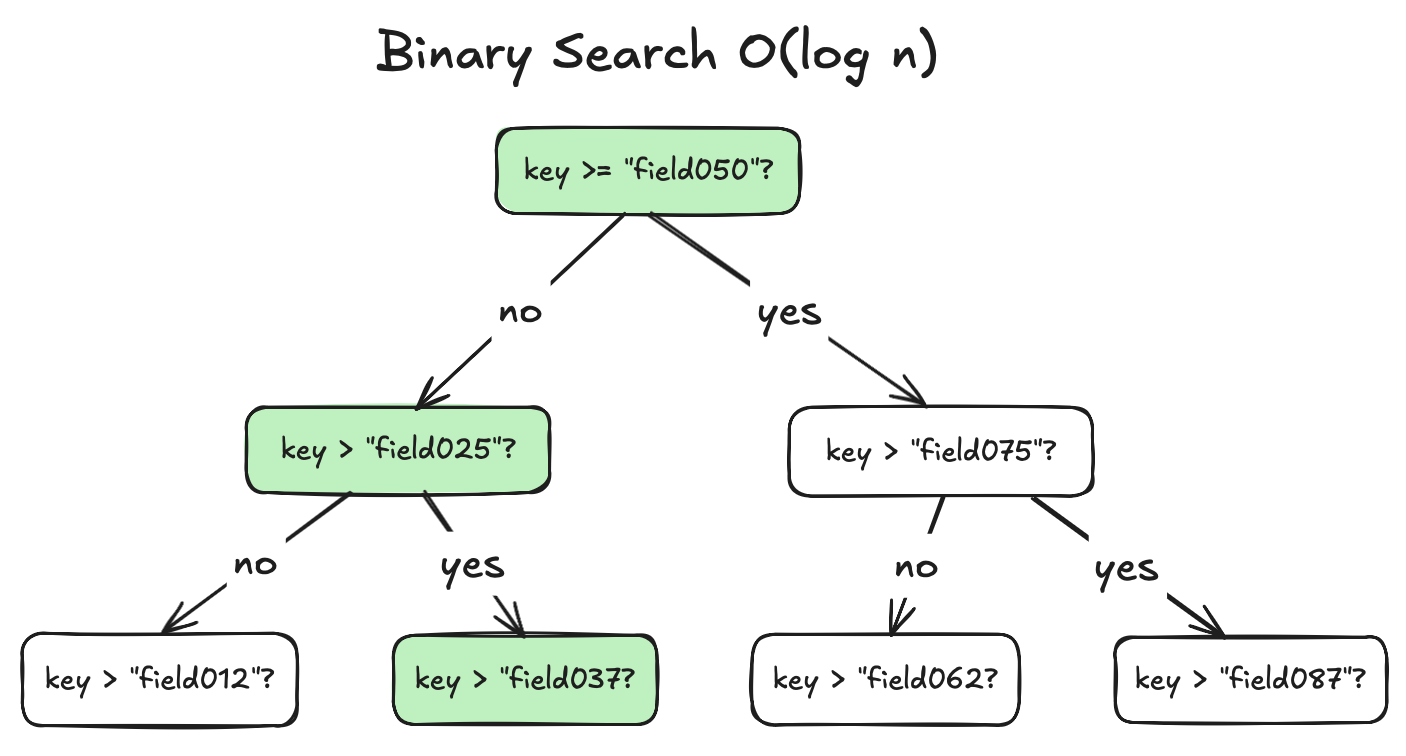
In below example, it takes 82 checks to find field number 42 in a map with 100 fields. 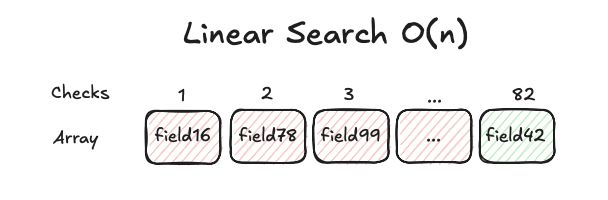
The Scalability Trap
- Data Volume: 1TB of testlogs = ~1 billion rows.
- Keys per Map: ~1000 parameters per row.
- Total Key Comparisons: 1 billion rows × 1000 keys = 1 trillion comparisons.
Even with Spark’s optimizations, this drowns the cluster in unnecessary work. For instance, we noticed that the CPU's become totally saturated during queries. This makes matters worse, because under high load, tasks spend most of their time waiting in line rather than executing.
The bottleneck was clear: linear key searches at scale.
The Solution: VariantType
Recently Databricks introduced a new data type: VariantType. Available in Databricks from runtime 15.3 and in the Spark 4 preview, this data structure promises to be up to 8x faster than extracting data from a JSON string. The question, however, is whether VariantType is also faster than MapType. This is not being mentioned anywhere. On the surface, it seemed like a good fit because, like MapType, it allows for schema flexibility. In contrast to MapType's schema on write, it uses a schema-on-read approach. For our case, this was a good fit, because for the testlogs data we needed to cast the values to their correct types anyway. This would therefore save us the overhead of casting from string to the correct datatype. Eager to find an alternative to the slow MapType, we decided to put VariantType to the test.
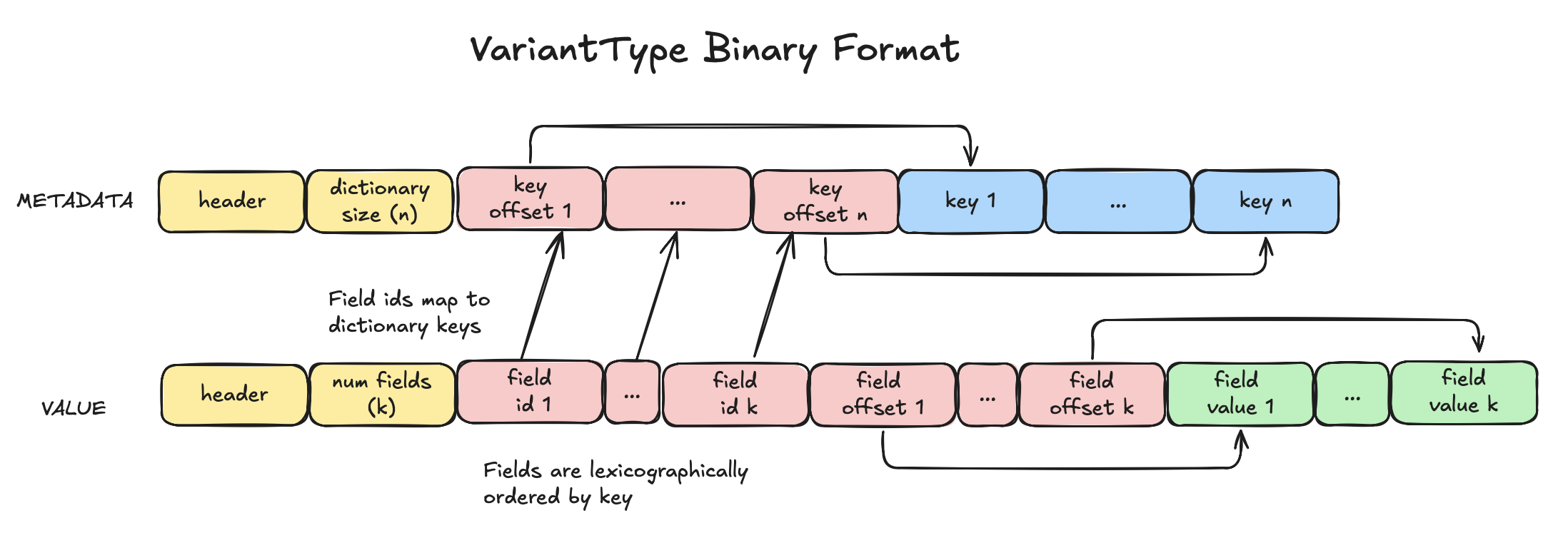
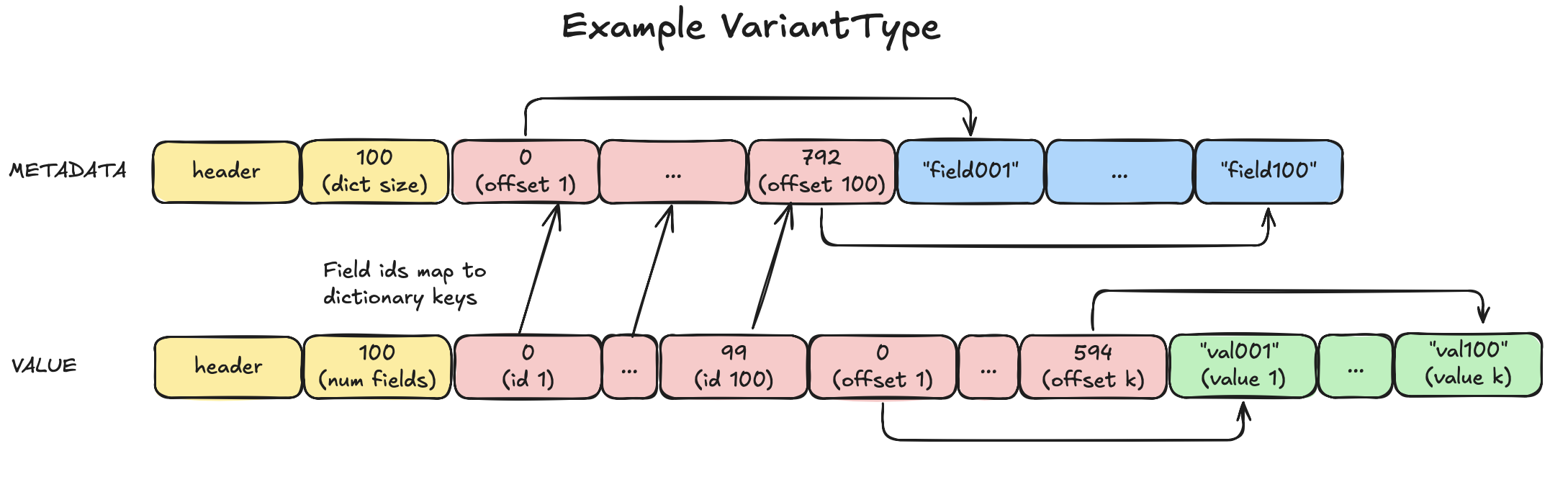
As you can see, the VariantType’s encoding is quite similar to the MapType encoding. However, the keys and values are stored in lexicographically sorted order. This enables binary search, which has a time complexity of O(log n) instead of O(n). For a 100-element map, this reduces the maximum number of comparisons to 7 (log₂(100) ≈ 6.64) versus 100 for linear search.
Binary Search
Binary search locates a key by comparing it to the middle element of the array. If the key is smaller, the search continues in the left half; if larger, it continues in the right half. This repeats until the key is found. Once located, the corresponding value can be retrieved using the same index in the value offset array.
The benchmark results are staggering
The faster binary search algorithm of VariantType means it's likely going to outperform the linear search of MapType on larger maps. To benchmark this, a synthetic dataset was created and the time to access all keys was measured on dataset with 1,000 records. To measure the effect of the number of keys, the number of keys was varied from 1 to 10,000.
The results were clear: VariantType outperformed MapType by ~5x on a dataset with 10k keys.
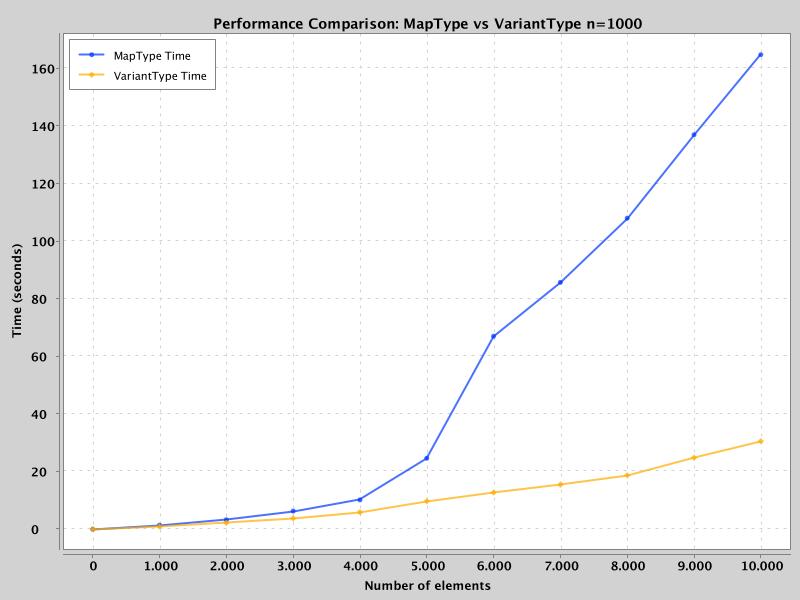
Ran on local mode on Apple M4 with 10 cores and 30GB of RAM.
VariantType significantly outperforms MapType as the number of keys increases. At around 6,000 keys, MapType’s performance degrades rapidly due to CPU saturation and task queuing—a behavior also observed in production environments where CPUs were consistently at 100% utilization. The reason? Linear search is more CPU-intensive, requiring far more comparisons.
The downsides of VariantType
VariantType has some drawbacks compared to a MapType with root-level keys only:
-
Higher storage and memory overhead: For example, 1,000 rows with 10,000 elements occupy ~1.25x more space (590MB vs. 471MB). Note that VariantType storage becomes more efficient with deeply nested structures, as its binary format stores keys only once (unlike JSON strings, which repeat keys).
-
Slower writes: Encoding VariantType took ~20% longer in benchmarks due to the complexity of its binary format.
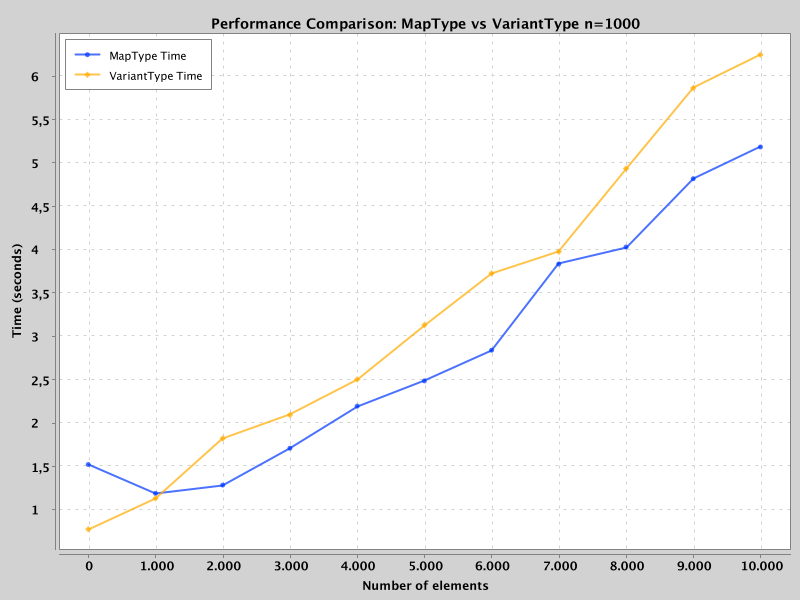
The reduced write performance makes sense, because Spark needs to sort the keys and also is a bit more complex than the MapType encoding.
For our use case, the performance gains far outweigh these downsides. We therefore migrated to VariantType for our testlogs table.
The results
- 10x faster query times: Queries on 1TB of data dropped from 4+ hours to 20 minutes.
- Happy analysts: Faster insights and interactive exploration. One analyst noted, “It’s so cool that I can now run
queries and get results in minutes.” - Higher business value: Analysts can now answer testlogs-related questions during engineering meetings—previously
impossible due to slow queries. - Cost savings: Reduced compute costs by avoiding linear scalability traps. Smaller clusters (e.g., single worker
nodes) now handle workloads that previously required 4+ nodes.
Alternatives considered
There were several other approaches tested and considered. I will shortly discuss them here.
Approaches Tested
- Liquid Clustering: No measurable performance gains for our key-lookup bottleneck.
- Added Partition Columns: Improved filtering speed marginally, but filtering wasn’t our critical path.
Alternatives Considered
- StructType: Too rigid for dynamic keys. Even dynamic struct creation on runtime requires looking up the parameters from somewhere, negating gains.
- JSON Strings: Slower than MapType. A lot of parsing overhead.
- Wide Schema Tables: Impractical for 1,000+ dynamic parameters. Schema management would become a nightmare.
- Split Tables: Managing 1,000+ tables for parameters? No thank you.
- Long (Narrow) Format: Requires pivoting/joining for horizontal analysis. Our tests showed 30-100x slower than Map/VariantType scans.
- Other binary formats such as Protobuf: Didn’t test, but it seems like variant type is a better fit, because it is built for Spark and is schema-on-read.
- Using other query engine: DuckDB was tried on small subset, but is single node and not optimized for these data sizes. Maybe SmallPond can be interesting for our use case, but it is not yet available in Databricks.
Learnings
- Data encoding matters: The right datatype can drastically impact performance.
- Schema flexibility vs. performance: VariantType strikes a balance, offering both flexibility and speed for semi-structured data.
- Benchmark early, benchmark often: Proactive benchmarking prevents production bottlenecks.
The future of VariantType
Databricks is optimizing VariantType further, including support for shredding—extracting fields from the binary format into separate columns.
Benefits include:
- More compact encoding.
- Min/max statistics for data skipping.
- Reduced I/O and CPU usage by pruning unused fields.
I hope you enjoyed reading this post. For questions, feel free to reach out. Benchmark code:
link to GitHub repo.
Written by
Daniël Tom
Daniël is a data engineer at Xebia Data. He gets energy from problem solving and building data applications. In addition, he likes to tinker with the latest data tools.




Contact