Blog
Sie brauchen immer noch keinen Feature Store

Als Berater haben Sie es mit einer Vielzahl von Tools und Implementierungen zu tun, die nicht alle gut gemacht sind. Einmal habe ich 6 Monate damit verbracht, eine Feature-Store-Implementierung zu refaktorisieren. Das war notwendig, weil sowohl die Wahl des Designs als auch die Implementierung falsch waren. Bei der Implementierung handelte es sich um eine überentwickelte, benutzerdefinierte Feast-Implementierung, die nicht unterstützte Backend-Datenspeicher verwendete. Der Ingenieur, der die Implementierung vorgenommen hatte, hatte das Unternehmen bereits verlassen, als ich dazukam. Es war meine Aufgabe, entweder die Implementierung zu korrigieren oder die Lösung neu zu entwerfen. Dies führte dazu, dass ich die Probleme verstand, die Feature Stores lösen, und die verschiedenen Ansätze zur Lösung dieser Probleme.
Bei dieser Recherche habe ich den besten Blog über Feature-Stores gefunden. Leider konzentriert sich der Blog-Beitrag nur auf Train-Serve-Skew. Feature-Stores lösen mehr als nur Zug-Serve-Verzerrungen. Andere Inhalte über Feature-Stores werden oft von Feature-Store-Anbietern geschrieben. Diese Inhalte konzentrieren sich auf die jeweilige Feature-Store-Implementierung. Dieser Blog konzentriert sich auf die Prinzipien der Technologie und die wichtigsten Probleme, die ein Feature Store löst. Dies sind die vier Gründe, warum man einen Feature Store einführen sollte:
- Verhindern Sie die wiederholte Entwicklung von Funktionen
- Verhindern Sie wiederholte Berechnungen
- Abrufen von Funktionen, die nicht durch Kundeneingabe bereitgestellt werden
- Lösen Sie die Schieflage zwischen Zug und Service
Diese Probleme werden von dem angesprochen, was wir als "Offline- und Online-Funktionsspeicher" bezeichnen. Diese Art von Feature Store ist die fortschrittlichste und komplexeste Implementierung. Der Begriff "Feature Store" hat in verschiedenen Kontexten eine unterschiedliche Bedeutung. Dieser Blogbeitrag hilft Ihnen zu verstehen, was ein Feature Store ist, erklärt, wann Sie einen brauchen und zeigt alternative Lösungen auf. Lassen Sie uns zunächst besprechen, was wir mit den vier oben genannten Punkten meinen und wie sie sich auf Ihre Arbeit auswirken, bevor wir uns mit den Lösungen beschäftigen.
Probleme mit dem Feature Store
Verhindern Sie die wiederholte Entwicklung von Funktionen
Die bewährte Praxis der Softwareentwicklung lautet: "Wiederhole dich nicht"(DRY). Das gilt auch für die Logik der Funktionsentwicklung. Die gemeinsame Nutzung von Funktionen durch verschiedene Teams in einem Unternehmen verkürzt die Zeit bis zur Produktion von Modellen. Funktionen, die von einem Team entwickelt wurden, können von einem anderen wiederverwendet werden. Dies wird immer wichtiger, wenn ein Unternehmen skaliert und mehr Modelle für maschinelles Lernen in der Produktion einsetzt. Die unterschiedliche Berechnung von Funktionen in verschiedenen Modellen kann zu Problemen führen. Es kann die Zuverlässigkeit und Fairness für den Kunden beeinträchtigen und sogar gegen gesetzliche Auflagen verstoßen. Ein typischer Fall ist, wenn gesetzliche Auflagen Sie dazu zwingen, Merkmale auf eine bestimmte Weise zu berechnen.
Bei der gemeinsamen Arbeit an Features sind die Datenreihenfolge und die Auffindbarkeit von größter Bedeutung. Die Datenabfolge verdeutlicht, aus welchen Datenquellen und -umwandlungen ein bestimmtes Feature stammt. Eine Funktion ist auffindbar, wenn sie leicht zu finden und zu verstehen ist. Sie möchten zum Beispiel wissen, welche Werte es annehmen kann. In diesem Blogbeitrag geht es nicht um die Datenherkunft oder die Auffindbarkeit. Dennoch sind sie als Folge der Zusammenarbeit erwähnenswert.
Verhindern Sie wiederholte Berechnungen
Wenn die Anzahl der Modelle wächst, werden sie immer mehr Funktionen berechnen. Dies erhöht den Bedarf an Rechenleistung und Ihre Kosten. In einem naiven Setup werden die Merkmale jedes Mal (neu) berechnet, wenn Sie ein neues Modell trainieren. Dieselben Merkmale können sogar von vielen Modellen berechnet werden, die von verschiedenen Teams gepflegt werden. Dies treibt die Berechnungskosten in die Höhe. Dies ist ein häufiges Problem, insbesondere bei der Arbeit in Cloud-Umgebungen.
Das Speichern Ihrer Features in einem Feature Store zur späteren Verwendung ist eine gute Möglichkeit, um wiederholte Berechnungen zu vermeiden. Features werden in einer Feature-Engineering-Pipeline berechnet, die Features in den Datenspeicher schreibt. So können Ihre Teams Modelle trainieren, ohne jedes Mal die Schritte der Datenvorbereitung zu wiederholen. Das Berechnen von Merkmalen bei jedem Trainingslauf kann Stunden dauern. Dies verlangsamt den Entwicklungsfortschritt und Ihre Fähigkeit, ein Modell zu iterieren. Die Wiederverwendung gespeicherter Merkmale hilft, schneller zu iterieren. Dies erhöht die Geschwindigkeit Ihrer Modellentwicklung.
Dieses Muster reduziert die Berechnungskosten und verkürzt die Zeit bis zur Produktion der Modelle. Der Feature Store kann mit anderen Teams in Ihrem Unternehmen gemeinsam genutzt werden. Die Teams verbringen weniger Zeit mit der Entwicklung und Pflege von Funktionen. Dadurch wird die Zeit bis zur Produktion der Modelle noch weiter verkürzt.
Abrufen von Funktionen, die nicht vom Verbraucher bereitgestellt werden
Ein Funktionsspeicher kann verwendet werden, um Funktionen abzurufen, die nicht vom Verbraucher Ihres Modells bereitgestellt werden. Das bedeutet, dass es einen Dienst gibt, der Ihr Modell konsumiert und einige, aber nicht alle Eingabefunktionen bereitstellt. Dies ist nur in Online-Serving-Szenarien relevant, wie in diesem Blogbeitrag erläutert. In Online-Serving-Szenarien ist es üblich, dass die Verbraucher eine Teilmenge von Merkmalen zur Verfügung stellen. Oder, der Verbraucher stellt nur einen Identifikator (z.B. eine Kunden- oder Artikel-ID) zur Verfügung, für den eine Vorhersage gemacht werden soll. In den folgenden Abschnitten wird dies näher erläutert.
In diesem Blogbeitrag wird von Online- und Offline-Serving gesprochen. Wenn Sie den Unterschied nicht kennen, lesen Sie bitte diesen Blog-Beitrag über Serving-Architekturen für maschinelles Lernen.
Wie wird Ihr Modell ausgestattet sein?
Nehmen wir an, Sie sind ein Data Scientist, der in einer Modellentwicklungsumgebung arbeitet. Sie haben vollständigen Zugriff auf alle historischen Daten. In dieser Umgebung bereiten Sie Merkmale vor. Sie trainieren ein Modell mit diesen Merkmalen. Sie setzen das Modell in der Produktion ein, wenn das trainierte Modell Wert verspricht. In diesem Beispiel stellen Sie das Modell online bereit. Die Modellnutzer stellen die Modellmerkmale als Eingabe für das Modell bereit. Das Modell erstellt Vorhersagen für einen oder mehrere Dienste. Sie haben zwei Optionen für die Inferenz:
- Der Verbraucher berechnet die Merkmale, die Ihr Modell als Eingabe benötigt
- Der Verbraucher sendet die Rohdaten und berechnet die Merkmale während der Inferenzzeit.
- Sie verwenden einen Funktionsspeicher, um Funktionen abzurufen, die nicht vom Verbraucher bereitgestellt werden
Was ist, wenn eine neue Funktion hinzugefügt werden muss?
Das unten stehende Diagramm zeigt ein Beispiel, bei dem mehrere Dienste ein Modell konsumieren. Außerdem berechnet der Verbraucher die Funktionen. Es wird schwieriger, Funktionen hinzuzufügen oder zu entfernen, da Ihr Modell mit seinen Verbrauchern gekoppelt ist.
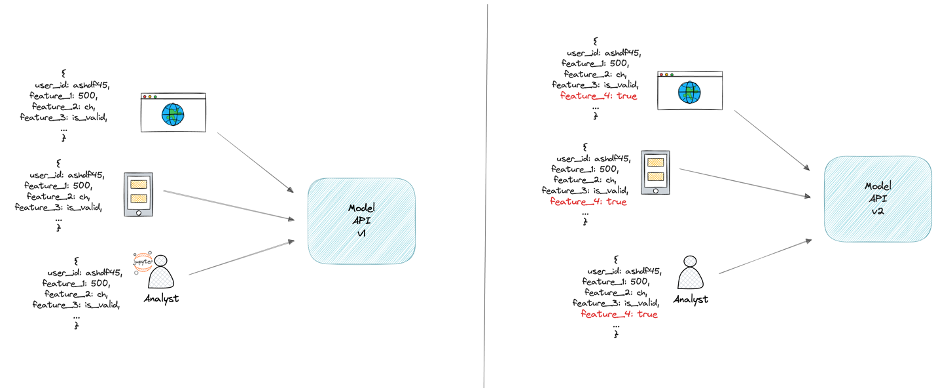
Wenn Sie Funktionen ändern, müssen alle Dienste, die Ihr Modell nutzen, diese Funktion übernehmen. Sie müssen zwei Versionen Ihrer Modelle unterstützen, um die Geschäftskontinuität zu gewährleisten. Ihr Modell ist mit seinen konsumierenden Anwendungen gekoppelt. Das bedeutet, dass jede Änderung an Ihrem Modell eine Änderung an seinen Verbrauchern bedeutet. Änderungen an Ihrem Modell werden so zu einem Albtraum. Darüber hinaus besteht das Risiko von Zug-um-Zug-Verzerrungen. Die Verbraucher berechnen die Merkmale wahrscheinlich anders als Ihr Modell zum Zeitpunkt des Trainings. Dies führt zu einer Schieflage beim Trainieren und Bedienen.
Berechnen von Merkmalen während der Inferenz
Die zweite Option leidet unter den meisten der Probleme der ersten. Modell und Verbraucher sind immer noch eng miteinander verbunden. Die Verbraucher müssen alle Daten und nicht nur die Funktionen bereitstellen. Das macht die Schnittstelle zwischen Modell und Verbraucher komplex. Die Verbraucher müssen aktualisiert werden, wenn ein neues Merkmal hinzugefügt wird, das neue Eingabedaten erfordert. Durch die Bereitstellung der Rohdaten für ein Merkmal wird die Wahrscheinlichkeit einer Verzerrung zwischen Training und Service verringert. Dieses Muster führt zu neuen Problemen bei Funktionen, die viele Daten zur Berechnung benötigen. Die Anfrage kann sehr groß werden und die Berechnung von Vorhersagen kann langsam werden.
Diese suboptimalen Muster zeigen, dass eine dritte Option erforderlich ist: ein Funktionsspeicher, aus dem Daten abgerufen werden, die nicht vom Verbraucher bereitgestellt werden. Später in diesem Blog-Beitrag zeigen wir verschiedene Möglichkeiten, dies zu implementieren.
Lösen Sie die Schieflage zwischen Zug und Service
Train-Serve-Skew ist einer der häufigsten Fehler beim maschinellen Lernen in der Produktion. Train-Serve-Skew tritt auf, wenn die Verteilung der Eingabedaten zum Zeitpunkt des Servings anders ist als zum Zeitpunkt des Trainings. Dies wird häufig durch den Unterschied zwischen der Trainings- und der Serving-Umgebung verursacht. Die Trainingsumgebung ist die Umgebung, in der das Modell entwickelt wird. In dieser Umgebung bereiten Sie Daten und Merkmale vor. In der Serving-Umgebung des Modells berechnet Ihr Modell Vorhersagen für seine Konsumenten.
Die Anwendung einer anderen Datenverarbeitungslogik beim Training als beim Servieren führt wahrscheinlich zu unterschiedlichen Merkmalswerten, die dem Modell zur Verfügung gestellt werden. Unterschiedliche Merkmalswerte bedeuten eine unterschiedliche Verteilung der Merkmale zwischen Training und Service. Das bedeutet, dass eine Schieflage zwischen Training und Auslieferung auftritt. Infolgedessen wird Ihr Modell zum Zeitpunkt des Servings schlechter abschneiden als zum Zeitpunkt des Trainings. Train-Serve-Skew tritt vor allem bei der Online-Auslieferung auf.
Beispiel für die Schieflage von Zügen und Diensten
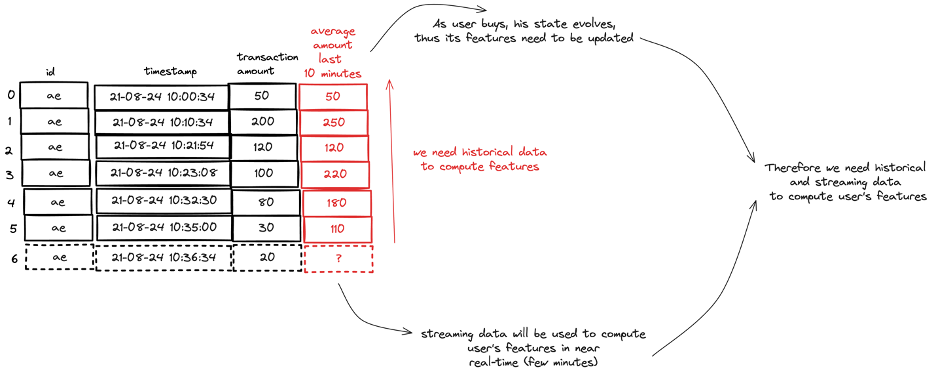
Schauen wir uns ein Beispiel an, um zu veranschaulichen, wie es in Ihrem maschinellen Lernsystem zu einer Verzerrung zwischen Training und Service kommen kann. Nehmen wir die Betrugserkennung als Beispiel. Ihr Betrugserkennungsmodell kann zustandsabhängige Merkmale verwenden. Ein zustandsabhängiges Merkmal ist ein Merkmal, das sich mit jedem Ereignis ändert. Ein Datenwissenschaftler hat z.B. eine Funktion erstellt, die den durchschnittlichen Transaktionsbetrag für eine Kreditkarte in den letzten 10 Minuten errechnet. Dies ist in der Abbildung unter diesem Absatz dargestellt. Jede Transaktion ist ein Ereignis, und die Funktion für den Durchschnittsbetrag ändert sich mit jeder Transaktion. In einer Online-Serving-Umgebung bedeutet dies, dass Ihr Modell die neueste Ansicht der Merkmale benötigt. Stateful Features müssen in Echtzeit aktualisiert werden, wenn neue Daten eintreffen.
Während der Entwicklung verwenden wir interaktive Notebooks und fragen historische Daten ab, die in einem Data Lake oder Warehouse gespeichert sind. Beim Übergang zur Produktion wandeln wir diese Logik in Batch-Pipelines um. Alle Daten sind verfügbar, so dass die Erstellung von zustandsabhängigen Funktionen mit Hilfe von Fensterfunktionen ganz einfach ist.
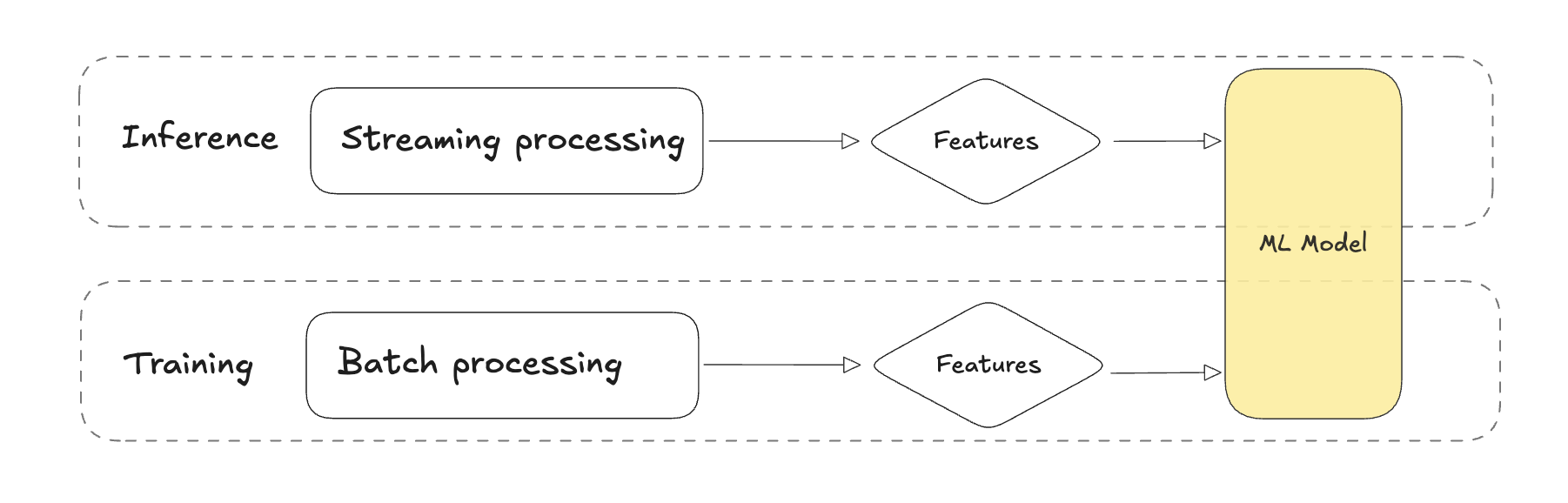
Zum Zeitpunkt der Inferenz stellen wir unsere Modelle online in einer Produktionsumgebung bereit. Zum Zeitpunkt der Ableitung muss dieselbe Logik angewendet werden. Sie muss schnell sein, denn wir wollen die aktuellste Sicht der Welt mit allen Daten bis zum Zeitpunkt der neuen Transaktion. Ihre Streaming Inference Pipeline ist wahrscheinlich eine andere Anwendung. Diese Anwendung verwendet möglicherweise eine andere Technologie als Ihre Trainingspipeline. Eine Technologie, die für die Berechnung von zustandsabhängigen Merkmalen mit schnellen Antwortzeiten optimiert ist. Zusammenfassend lässt sich sagen, dass bei einer Trennung von Trainings- und Serving-Logik eine Änderung in einem der beiden Bereiche zu einem Train-Serve-Versatz führen kann. Um dies zu verhindern, müssen alle Änderungen synchronisiert werden.
Lösungen
Für jede der oben beschriebenen Herausforderungen gibt es verschiedene Lösungen. Einige der Lösungen sind vielleicht nicht das, was Sie unter einem Feature Store verstehen würden, daher der Titel dieses Artikels. Dies zeigt, dass es alternative Lösungen gibt, die keinen Feature Store erfordern. Die Anwendbarkeit der einzelnen Muster hängt von Ihrer Model-Serving-Architektur ab. Einige der Muster können miteinander kombiniert werden. Ein Muster kann die Unzulänglichkeiten des anderen abdecken, um die Herausforderungen, die ein Feature Store lösen soll, besser zu bewältigen. Diese Kombinationen werden in den folgenden Abschnitten näher erläutert.
In-model Vorverarbeitung
Diese erste Lösung stammt aus dem Blogbeitrag, auf den in der Einleitung verwiesen wird. Im Buch ML Design Patterns wird sie ausführlicher beschrieben. Das Muster löst die Train-Serve-Schieflage, indem es eine Vorverarbeitungslogik in den Modellcode integriert. Die gleiche Vorverarbeitungslogik wird während des Trainings wie in der Produktion angewendet.
In diesem Fall wird Ihr serialisiertes Modell die Vorverarbeitungslogik enthalten. Der Nachteil dieses Ansatzes besteht darin, dass die Vorverarbeitungslogik jedes Mal, wenn Sie das Modell aufrufen, für alle Rohdaten berechnet werden muss. Dies führt zu einem hohen Berechnungsaufwand, wenn Sie viele Experimente mit demselben Datensatz durchführen. Außerdem erhöht sich dadurch die Latenzzeit bei der Bereitstellung. Vor allem, wenn Ihr Modell aggregierte Merkmale über einen langen historischen Zeitraum berechnet. Die Berechnung des Gesamtwerts aller Transaktionen im letzten Jahr ist ein Beispiel für ein solches Merkmal.
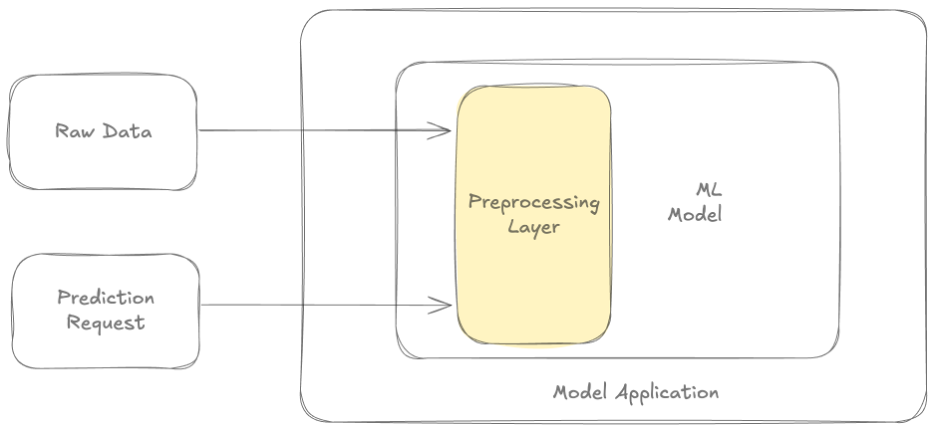 Bild angepasst von Do you really need a feature store?
Bild angepasst von Do you really need a feature store?
Löst:
- Schräglage des Zugs bedienen
Muster transformieren
Wir können die Vorverarbeitungslogik als separate Transformationsfunktion erstellen. Dadurch wird der Rechenaufwand des Musters "Vorverarbeitung innerhalb des Modells" vermieden. Die Transformationsfunktion wird in der Trainingspipeline und während der Online-Inferenz ausgeführt. Dies fördert die Verwendung der gleichen Logik beim Training und bei der Online-Inferenz. Die Verwendung dieses Musters reduziert das Risiko einer Schieflage zwischen Training und Inferenz.
Stellen Sie sich die Transformationsfunktion als eine Funktion vor, die aus einer Bibliothek importiert wird. Während des Trainings können wir die vorverarbeiteten Daten zur späteren Verwendung speichern. Dadurch wird vermieden, dass die gleiche Vorverarbeitungslogik erneut berechnet wird. Die meisten ML-Frameworks unterstützen das Transformationsmuster auf die eine oder andere Weise. Diese Lösung leidet unter dem gleichen Nachteil der Latenz wie die modellinterne Verarbeitung.
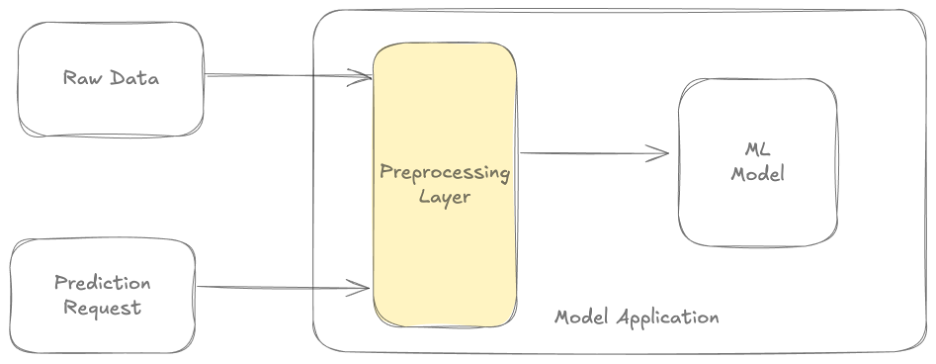 Bild angepasst von Do you really need a feature store?
Bild angepasst von Do you really need a feature store?
Löst:
- Schräglage des Zugs bedienen
- Verhindern Sie doppelte Berechnungen
Vorberechnete Merkmale
Eine wichtige Funktion eines Feature Store ist die Bereitstellung einer gemeinsamen API für Anwendungen zur Abfrage von Features. Sie können dieses Muster verwenden, wenn Sie Ihr Modell offline im Batch betreiben. Eine Pipeline wendet die Logik des Feature Engineering an und speichert die Features in einem Datenspeicher. Die Features im Datenspeicher können während des Trainings und der Bereitstellung verwendet werden.
Dieses Muster ist auch üblich, wenn ein Modell online angeboten wird. Der Kunde liefert einen Teil der Eingabedaten. Die Modellanwendung holt den Rest der Eingabedaten für das Merkmal aus einem Datenspeicher. Diese Merkmalsdaten können mit Teams in der gesamten Organisation geteilt werden. In diesem Abschnitt gehen wir davon aus, dass diese vorberechneten Merkmale nicht gemeinsam genutzt werden. Dies hilft, die Diskussion einzugrenzen. Ein einzelnes ML-Team berechnet diese Merkmale und verwaltet sie in einem Datenspeicher.
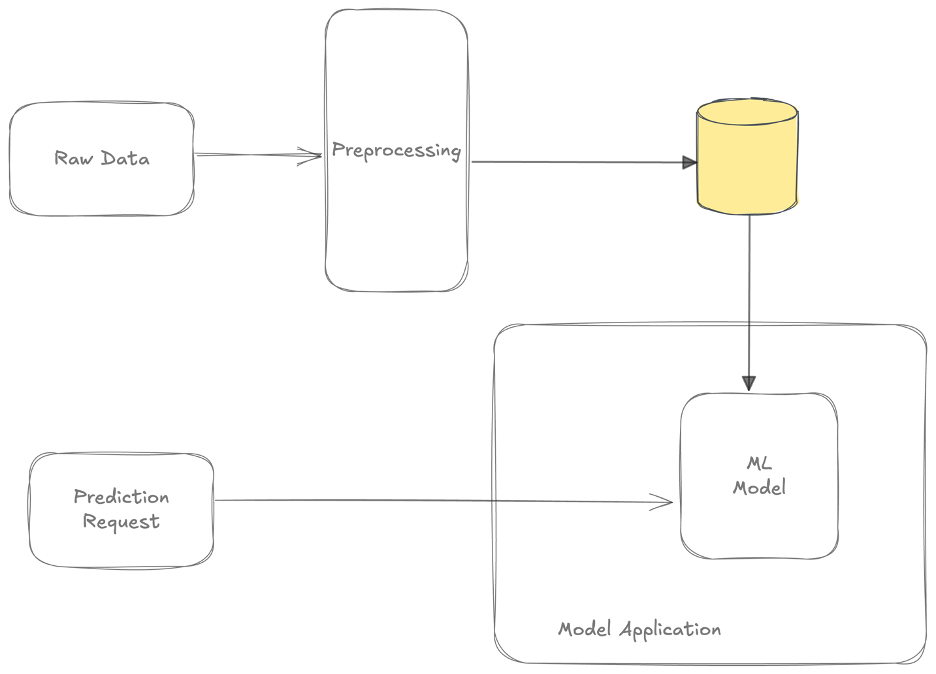
Dieses Muster wird häufig in Kombination mit Modellen angewendet, die im Batch-Verfahren trainiert wurden. Die Vorverarbeitung der Daten wird in regelmäßigen Abständen in Stapeln durchgeführt. Die Merkmale werden in der Regel in einen Key-Value-Datenspeicher geschrieben. Modelle können Merkmale mit geringer Latenz abrufen, was ideal für die Online-Bereitstellung ist. Wir nennen diese Merkmale Batch-Features. Der Nachteil der Batch-Features-Lösung ist, dass Ihre Feature-Daten veraltet sein können. Ihre Merkmale enthalten nur Daten bis zum letzten Mal, als Sie die Vorverarbeitung durchgeführt haben. Bei vielen Merkmalen ist dies jedoch kein Problem. Es ist zum Beispiel in Ordnung, die Gesamtsumme aller Transaktionen eines Tages einmal pro Tag zu berechnen. Fast alle Modelle, bei denen Merkmale abgerufen werden müssen, verwenden Batch-Merkmale.
Löst:
- Verhindern Sie doppelte Berechnungen
Funktionskatalog
Um wiederholte Entwicklungsarbeit zu vermeiden, brauchen wir keinen gemeinsamen Datenspeicher. Teams können Feature-Definitionen gemeinsam nutzen, um zu verhindern, dass sie das Rad neu erfinden. Auf diese Weise fördert ein Funktionskatalog die Zusammenarbeit. Werfen Sie einen Blick auf diesen Blogbeitrag über die Rationalisierung von Data Science Workflows.
Ein Feature-Katalog bietet einen zentralen Ort, an dem alle Feature-Definitionen definiert werden. Ein Feature-Katalog wird als Code implementiert und in der Regel in Git gepflegt. Der Code kann von verschiedenen Teams importiert werden, um schnell mit einem neuen Modell zu beginnen. Feature-Definitionen im Code ermöglichen die Generierung von Datenabfolgen. Die Abhängigkeiten zwischen Funktionen zeigen, wie die einzelnen Funktionen erstellt werden. So wird jedem Data Scientist sofort klar, wie ein Feature berechnet wird. Wenn mehrere Teams an denselben Funktionen zusammenarbeiten, verbessert sich die Qualität. Außerdem wird der Einstieg für neue Datenexperten erleichtert.
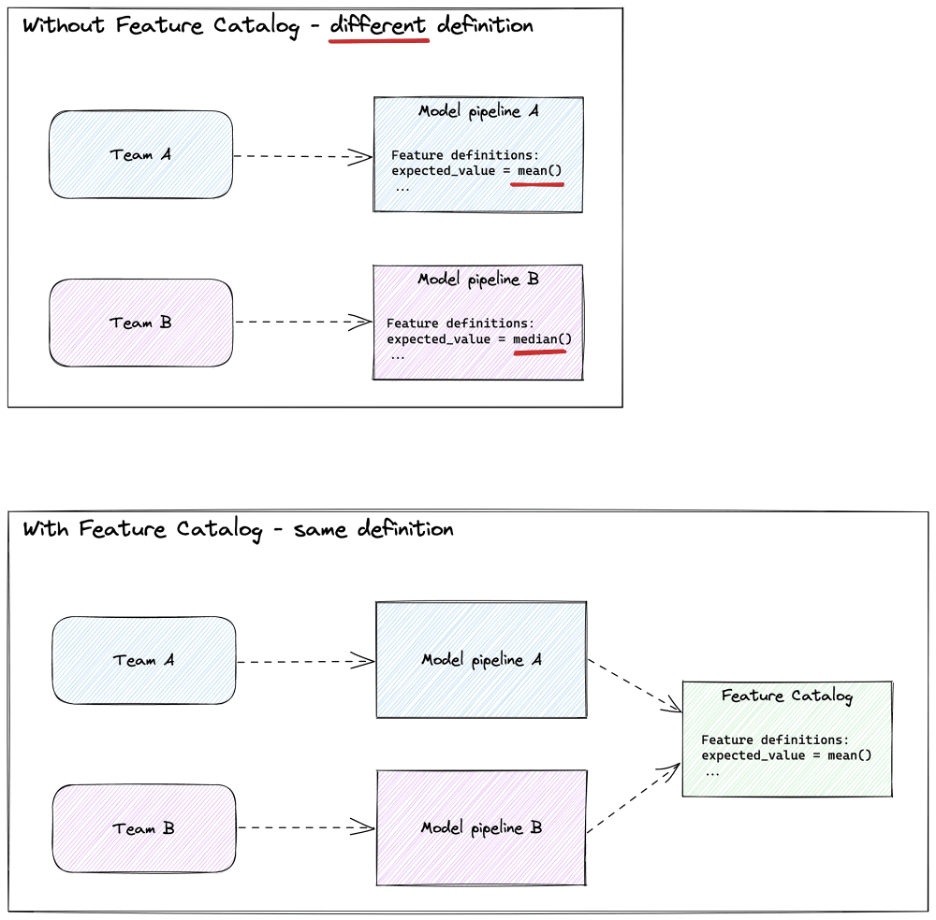
Nehmen wir an, ein neuer Datenwissenschaftler entwickelt ein Modell zur Vorhersage von Krediten. Das Modell automatisiert den Prozess der Kreditvergabe an neue Antragsteller. Das Unternehmen hat bereits ein anderes Modell zur Betrugserkennung in Produktion. Dieses Modell berechnet die Merkmale auf der Grundlage des historischen Zahlungsverhaltens. Es ist wahrscheinlich, dass sich das historische Zahlungsverhalten auf den Kreditstatus des Antragstellers auswirken wird. Wir können die Implementierung der Merkmale in dem neuen Modell wiederverwenden. Dies ist für den Data Scientist von großem Vorteil, da die Modellentwicklung beschleunigt wird.
Der Vorteil der Verwendung eines Funktionskatalogs ist die lose Kopplung zwischen den Teams. Dennoch fördern wir die Wiederverwendung. Die Teams teilen eine Abhängigkeit auf Code-Ebene. Es ist einfach, Migrationsstrategien für den Fall zu implementieren, dass sich die Funktionslogik grundlegend ändert. Jedes Team kann die Version des Funktionskatalogs in seinem eigenen Tempo aktualisieren.
Dieses Muster wird in der Regel verwendet, wenn Modelle offline im Stapel verarbeitet werden. Bei Online-Modellen können Sie jedoch einen Feature-Katalog verwenden, indem Sie ihn mit dem Transform-Muster kombinieren.
Löst:
- Vermeiden Sie doppelte Arbeit bei der Entwicklung von Funktionen
Offline-Funktionsspeicher
Ein Offline-Feature-Speicher ist ein Feature-Register, in dem alle Features gespeichert werden. Er funktioniert wie ein gemeinsamer Datenspeicher. Sie können Feature-Definitionen untersuchen, die Abstammung überprüfen und Features abfragen. Features können aus Trainings- und Serving-Umgebungen abgefragt werden. Betrachten Sie es als ein Datenlager für Ihre Funktionen. Teams können Features für ihre Anwendungsfälle beitragen, gemeinsam nutzen und entdecken. Dies fördert die Wiederverwendung von Funktionen in verschiedenen Teams innerhalb einer Organisation. Wie der Name schon sagt, handelt es sich um einen Offline-Speicher, der also nicht für Online-Serving-Szenarien verwendet wird.
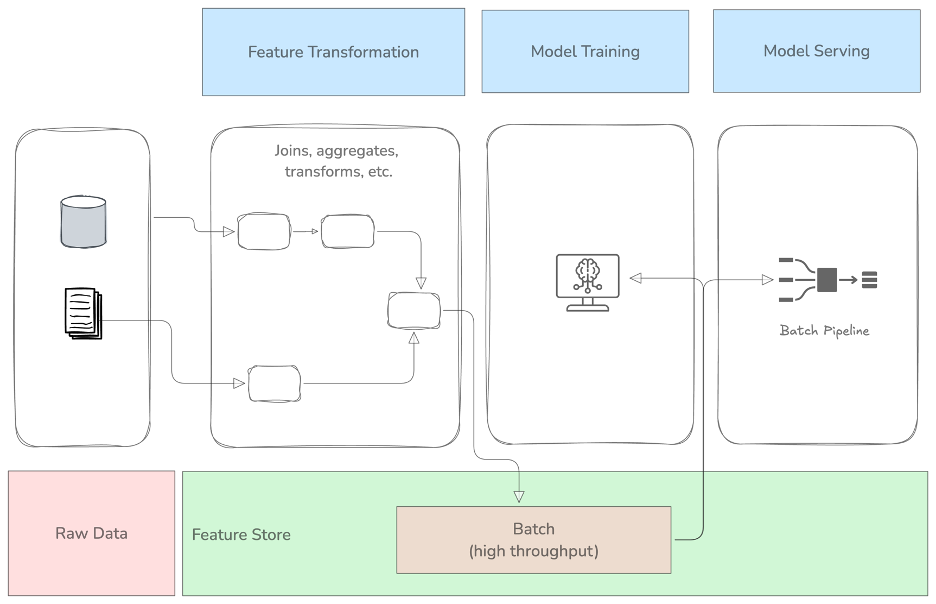 Die Rolle des Offline-Featurespeichers im Workflow des maschinellen Lernens
Die Rolle des Offline-Featurespeichers im Workflow des maschinellen Lernens
Die obige Architektur veranschaulicht die Gesamtarchitektur für einen Offline-Feature-Store. Sie zeigt, wie er in die Aufgaben eines Arbeitsablaufs für maschinelles Lernen integriert wird, angefangen bei den Rohdaten bis hin zur Modellierung.
Ein Offline-Feature-Store vereinfacht die Abfrage von Features für Entitäten, für die wir eine Vorhersage berechnen müssen. Er bietet eine einheitliche API, über die Sie einen Identifikator für eine Entität angeben können, und der Feature Store stellt die Features bereit, wie unten gezeigt.
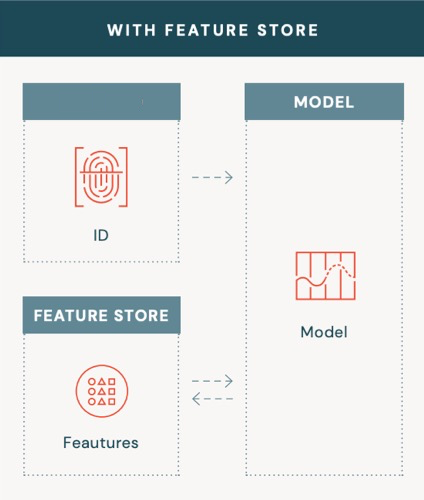
Bild aus Databricks' Comprehensive Guide to Feature stores
Unternehmen, die dieses Muster zur gemeinsamen Nutzung von Funktionen in verschiedenen Teams einsetzen, müssen sich dessen bewusst sein. Die gemeinsame Nutzung einer Datenquelle durch zwei Modelle schafft eine Datenabhängigkeit. Beide Modelle müssen eine Änderung vornehmen, wenn eines der Modelle eine Funktion ändern möchte. Die Versionierung von Funktionen ist zwar hilfreich, erfordert aber dennoch zusätzliche Koordination zwischen den Teams. Die Unterstützung mehrerer Versionen eines Merkmals bedeutet, dass es mehrfach berechnet werden muss. Damit ist das Argument hinfällig, dass Feature-Speicher wiederholte Berechnungen verhindern.
Der Feature-Katalog kann als Vorläufer für einen Offline- (und/oder Online-) Feature-Store dienen. Er bietet eine einfachere Möglichkeit der Zusammenarbeit. Zwei Teams, die dieselbe Funktionslogik verwenden, haben eine weiche Abhängigkeit. Es ist ein kleinerer Schritt, Daten gemeinsam zu nutzen, wenn die Teams bereits auf Code-Ebene zusammenarbeiten. Die gemeinsame Nutzung von Daten schafft eine härtere Datenabhängigkeit und reduziert die Berechnungskosten.
Löst:
- Vermeiden Sie doppelte Arbeit bei der Entwicklung von Funktionen
- Verhindern Sie doppelte Berechnungen
Offline- und Online-Funktionsspeicher
Der Offline- und Online-Featurespeicher kombiniert die Vorteile des Offline-Featurespeichers mit der Möglichkeit, Online-Features mit geringer Latenz bereitzustellen. Der Online-Funktionsspeicher ist nur relevant, wenn Sie Ihr Modell online bereitstellen.
Modell kann Merkmale abfragen
Der Online-Funktionsspeicher befasst sich mit dem Problem, dass Kundenfunktionen abgerufen werden müssen, die nicht vom Verbraucher oder Anrufer bereitgestellt werden. Das folgende Bild veranschaulicht dies.
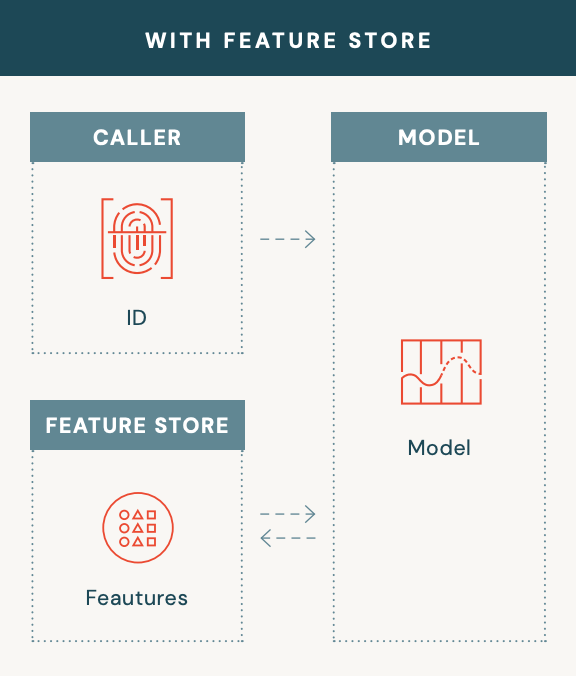 Bild aus Databricks' Comprehensive Guide to Feature stores
Bild aus Databricks' Comprehensive Guide to Feature stores
Dieses Muster entkoppelt die Modellverbraucher von der Modellanwendung. Es ermöglicht, dass sich das Modell und die Verbraucher unabhängig voneinander ändern können. Bei einem Merkmalsspeicher ist die einzige Eingabeanforderung die Entitäts-ID, die zum Abrufen dieser Merkmale verwendet wird. Die Merkmale werden vorberechnet und gespeichert. Das Hinzufügen neuer Funktionen zur Anwendung für maschinelles Lernen geschieht, ohne dass die Verbraucher davon wissen müssen.
Die 'Online'-Komponente eines Feature Stores
Online-Feature-Stores bieten oft einen Mechanismus, über den Features in einer Online-Ansicht materialisiert werden können. Diese Materialisierung kann in regelmäßigen Abständen durchgeführt werden. Die Merkmale im Online-Speicher sind dann so veraltet wie bei der letzten Materialisierung des Online-Speichers. Das ist in vielen Fällen in Ordnung, wie bereits im Abschnitt über vorberechnete Merkmale beschrieben.
Die meisten Online-Funktionsspeicher bieten auch eine Möglichkeit, die materialisierte Ansicht kontinuierlich zu aktualisieren. Dies geschieht durch Streaming-Updates. Anwendungsfälle für Daten mit geringer Latenzzeit sind Betrugserkennung, dynamische Preisgestaltung und Empfehlungssysteme. Häufige Datenaktualisierungen verringern die Unbeständigkeit der Merkmale im Online-Merkmalsspeicher. Dies erhöht die Komplexität, die Wartungskosten und die Laufzeitkosten der Funktionen. Ein Offline- und Online-Feature-Store wird häufig von einem auf Streaming-Daten spezialisierten Datenplattform-Team gepflegt.
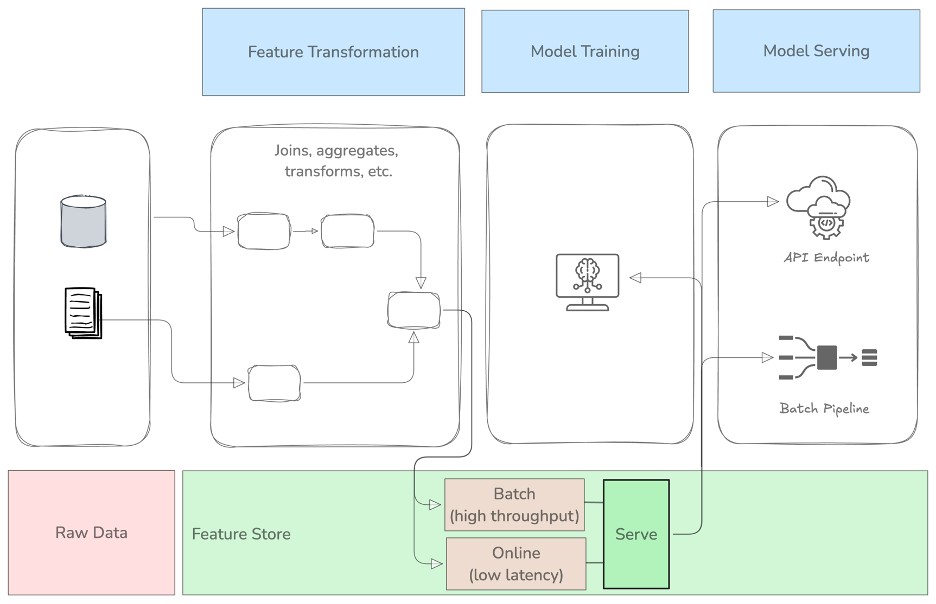 Die Rolle des Offline- und Online-Funktionsspeichers im Workflow des maschinellen Lernens
Die Rolle des Offline- und Online-Funktionsspeichers im Workflow des maschinellen Lernens
Im obigen Diagramm sind die Offline- und Online-Feature-Store-Komponenten in einer einzigen Ansicht kombiniert. Wir sehen, dass die Serve-Komponente unseres Feature-Stores zwei verschiedene Strategien hat: Batch und Online. Der Batch-Teil enthält eine Datenbank, die für einen hohen Durchsatz optimiert ist. Der Online-Teil bedient Merkmale aus einer Datenbank, die für eine geringe Latenzzeit optimiert ist. Letztere wird für Vorhersagen benötigt, bei denen die Merkmale (fast) in Echtzeit aktualisiert und bereitgestellt werden müssen.
Lösen von Zug-zu-Zug-Verschiebungen
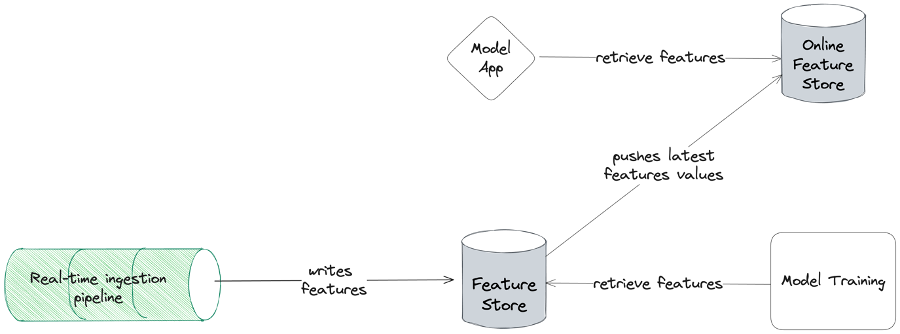
Das obige Diagramm zeigt, wie ein Offline- und ein Online-Feature-Store mit der Trainings- und Serviceumgebung zusammenhängen. Ein Online-Feature-Store ist eine für Lesevorgänge optimierte Datenbank, in der Features von Modellanwendungen abgerufen werden können. Aber wie genau löst der Online-Feature-Store die Schieflage zwischen Training und Service? Indem Sie eine einzige Pipeline haben, die Ihre Merkmale in Ihren Merkmalsspeicher schreibt. Denken Sie daran, dass Sie sicherstellen können, dass die Features in der Trainings- und in der Serving-Umgebung auf die gleiche Weise berechnet werden, um eine Verzerrung zwischen Training und Service zu verhindern.
Das Ziel eines Offline- und Online-Featurespeichers ist es, die Art und Weise, wie Batch- und Online-Features berechnet werden, zu vereinheitlichen und so die Train-Serve-Verzerrung zu beheben. Ein Train-Serve-Skew kann immer noch auftreten, wenn Sie ein Feature verwenden, das von zwei verschiedenen Pipelines berechnet wurde. Die Implementierung eines Offline- und Online-Feature-Stores ist alles andere als einfach und erfordert Expertenwissen auf dem Gebiet der Datentechnik.
Löst:
- Abrufen von Funktionen, die nicht durch Kundeneingabe bereitgestellt werden
- Vermeiden Sie doppelte Arbeit bei der Entwicklung von Funktionen
- Verhindern Sie doppelte Berechnungen
- Schräglage des Zugs bedienen
Lösungsraum
Wir haben sechs Muster untersucht, die sich mit den vier Gründen für die Einführung eines Feature Store befassen. Wir haben erörtert, wann jedes der einzelnen Muster angewendet werden kann und welche Nachteile es hat. Dies wurde in dem unten stehenden Baumdiagramm zusammengefasst, um Ihnen eine Entscheidungshilfe zu geben. Die Entscheidung, welches Muster Sie verwenden sollten, ist sehr viel differenzierter als ein einfaches Ja oder Nein. Das Diagramm hilft Ihnen bei der Unterscheidung zwischen den Mustern und erleichtert Ihnen so die Entscheidungsfindung.
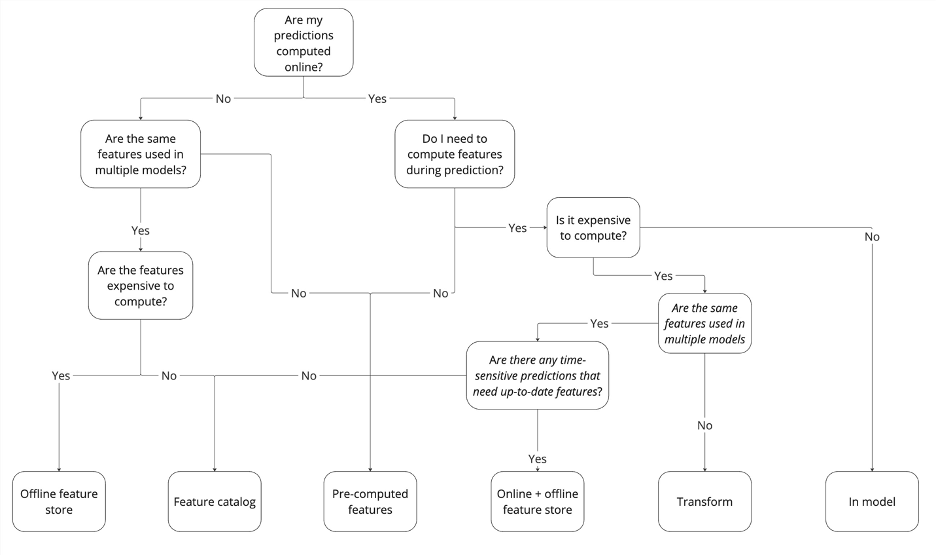
Letzte Worte
In diesem Blogbeitrag haben wir die Essenz dessen, was ein Feature Store ist, herausgearbeitet, indem wir uns auf die häufigsten Probleme konzentriert haben, die Sie damit lösen können. Wir haben gezeigt, dass der Begriff "Feature Store" vielschichtig ist. Es gibt verschiedene Herausforderungen, die bei der Einführung zu berücksichtigen sind. Es ist wichtig, sich auf das Problem zu konzentrieren, das Sie zu lösen versuchen. Auf diese Weise vermeiden Sie, dass Sie sich in unnötige Komplexität einkaufen und damit technische Schulden machen, die zwangsläufig abbezahlt werden müssen. Je nach Problem, das Sie zu lösen versuchen, gibt es oft viel einfachere Lösungen für einen Feature Store. In diesem Blog-Beitrag werden die Kompromisse bei jeder Lösung hervorgehoben. Es ist wichtig, dass Sie das Problem, das Sie zu lösen versuchen, und die Kompromisse der möglichen Lösung verstehen, damit Sie die richtige Entscheidung treffen können.
Bannerbild oben auf der Seite von Tobias Fischer auf Unsplash
Verfasst von
Roy van Santen
Unsere Ideen
Weitere Blogs




Contact