Blog
Rationalisierung von Data Science Workflows mit einem Feature-Katalog

Die Herausforderungen von benutzerdefinierten Modell-Pipelines in der Datenwissenschaft
Sind Sie es leid, in Ihrem Data-Science-Team mit Unklarheiten und doppelter Arbeit zu kämpfen?
Mit dem Aufkommen von Data Lakes verlassen sich immer mehr Teams auf benutzerdefinierte Pipelines für die Datenvorverarbeitung und das Feature Engineering. Dies kann jedoch zu einem großen Problem führen : Es wird schwieriger, Funktionen wiederzuverwenden oder sogar ähnliche Funktionen zwischen verschiedenen Teams zu vergleichen.
Stellen Sie sich vor, zwei Teams melden dem Marketingteam eine durchschnittliche Klickrate, aber ein Team schließt die Klicks von Robotern aus und das andere nicht. Ohne diesen Unterschied in der Interpretation zu erkennen, könnte das Marketingteam einige völlig falsche Entscheidungen treffen.
In diesem Blog-Beitrag gehen wir der Frage nach, wie Sie diese Herausforderungen meistern und die Zusammenarbeit, Konsistenz und Geschwindigkeit in Ihrem Data Science-Team verbessern können.
Nachfolgend ein schematischer Überblick über zwei Teams, die unterschiedliche Definitionen verwenden und wie ein Feature-Katalog dieses Problem lösen kann.
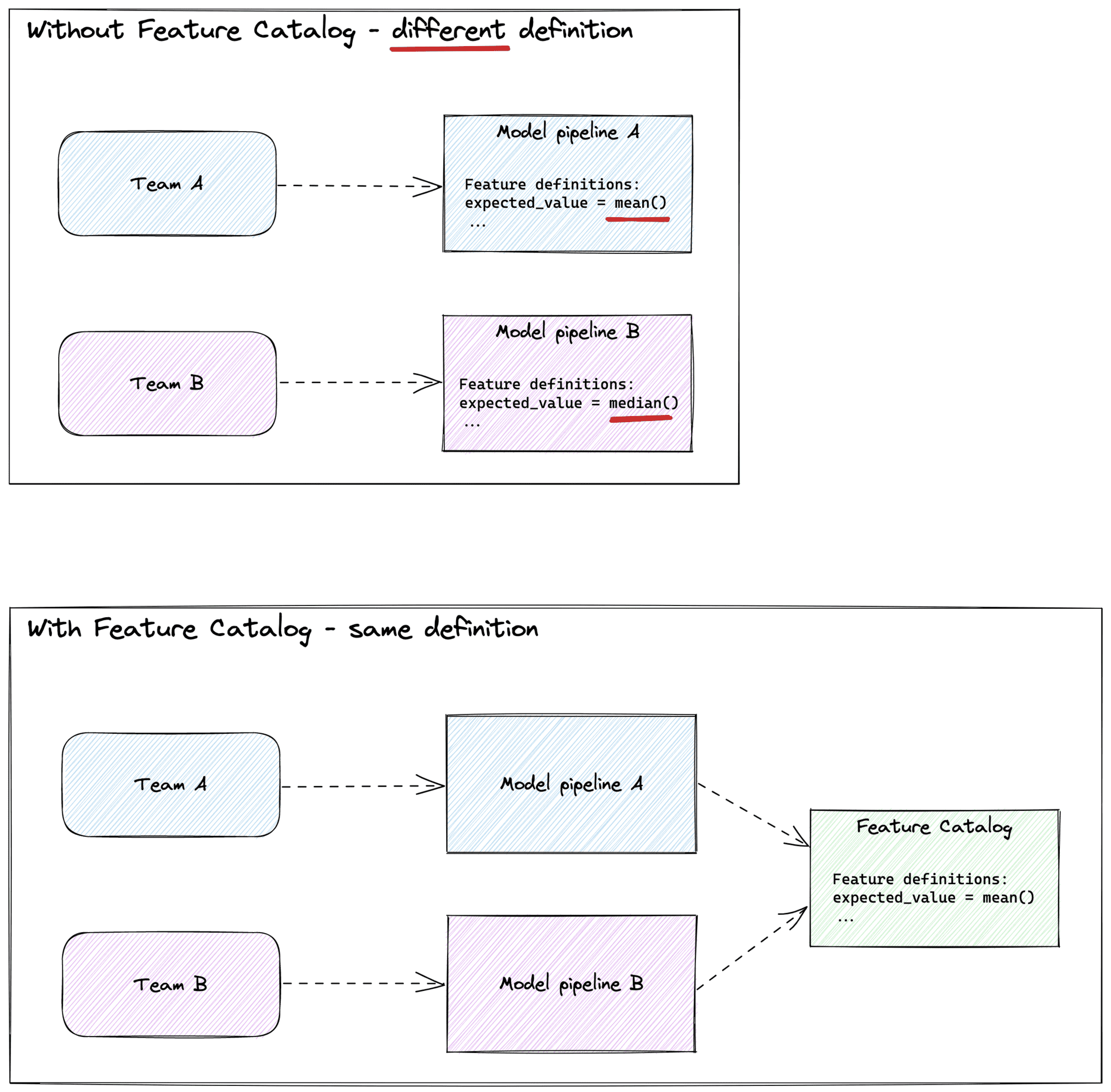
Ein Merkmalskatalog: Die Lösung für eine organisierte und effiziente Merkmalsberechnung
Eine unübersichtliche und unorganisierte Feature-Pipeline gehört mit einem Feature-Katalog der Vergangenheit an. Dieser Katalog bietet einen zentralen Ort für Feature-Definitionen und einen benutzerfreundlichen Weg, um ihn zu verwenden und Ihren Prozess zu rationalisieren.
Ich habe an einer Implementierung eines solchen Feature-Katalogs in Form eines Python-Pakets gearbeitet. Er ermöglichte eine einfache Gruppierung ähnlicher Funktionen und eine effiziente Wiederverwendung der Logik. Außerdem wurde ein Gleichgewicht zwischen Komplexität, Lesbarkeit und Geschwindigkeit gefunden. Als Bonus war es in der Lage, automatisch Diagramme zur Visualisierung der Datenabhängigkeiten zu erstellen. Dies ist möglich, wenn Sie Ihren Code strukturieren und ein einfaches Skript erstellen (z.B. in Ihrer CI-Pipeline aufgerufen), das Ihre Dokumentation und Diagramme automatisch auf dem neuesten Stand hält.
Die Vorteile eines Funktionskatalogs
Ein Feature-Katalog kann in vielerlei Hinsicht hilfreich sein. Er bietet Ihnen einen zentralen Ort, an dem alle Feature-Definitionen aufbewahrt werden. So können Sie sicherstellen, dass die Sichtweise des Unternehmens auf eine Funktion mit der Beschreibung im Code übereinstimmt. Außerdem wird es für die Teams einfacher, Feature-Definitionen gemeinsam zu nutzen und wiederzuverwenden. Das spart Zeit und verbessert die Qualität der Funktionen. Außerdem lassen sich so neue Ideen für Analysen oder Anwendungsfälle des maschinellen Lernens schneller testen.
Mit einem Feature-Katalog können Sie die Berechnung von Features beschleunigen. Das liegt daran, dass Sie dieselbe Logik und dieselben Zwischenergebnisse wiederverwenden können, anstatt jedes Mal bei Null anfangen zu müssen. Wenn Sie Ihren Code gut strukturieren, ist es einfacher zu verstehen, wie die Daten verwendet werden. Und es wird auch einfacher sein, den Code zu pflegen.
Ein Feature-Katalog unterscheidet sich von einem Feature-Shop, aber beide können Teil einer größeren Sache sein, die Feature-Plattform genannt wird. Wenn Sie mehr darüber wissen möchten, lesen Sie diesen Blogbeitrag
Ein Feature-Katalog hat viele Vorteile, auch wenn Sie noch keine vollständige Feature-Plattform haben. Er macht es einfacher, später einen Feature Store zu erstellen, wenn Sie ihn brauchen. Aber nicht jedes Unternehmen braucht einen Feature Store. Er ist nur dann sinnvoll, wenn Sie dieselben Funktionen häufig verwenden oder wenn Sie sie sofort benötigen (d.h. keine Verzögerung bei der Berechnung). Nur dann lohnt sich die zusätzliche Komplexität eines Feature Stores.
Starten Sie Ihren Feature-Katalog mit dieser Vorlage
Wenn Sie viele Daten mit einem Programm wie Spark verarbeiten müssen, können Sie diese Vorlage auf GitHub verwenden, um Ihren eigenen Feature-Katalog zu erstellen. Er hat die folgenden Eigenschaften:
- Einfach zu bedienen, um die gewünschten Funktionen zu erhalten
- Begrenzte Wiederholungen und verbesserte Geschwindigkeit durch Gruppierung von Funktionen, die dieselbe
groupbybenötigen, aber eine andere Aggregation durchführen - Ermöglicht verschiedene Aggregationsstufen ohne doppelte Logik/Code
- Verwendet keine zusätzlichen Schritte wie Caching oder temporäre Tabellen, um die Wartung zu vereinfachen und die Optimierer von Spark effizienter arbeiten zu lassen.
- Ermöglicht Ihnen die (Wieder-)Verwendung von Merkmalen als Ausgangspunkt für andere Merkmale, ohne dass Sie diese erneut berechnen müssen.
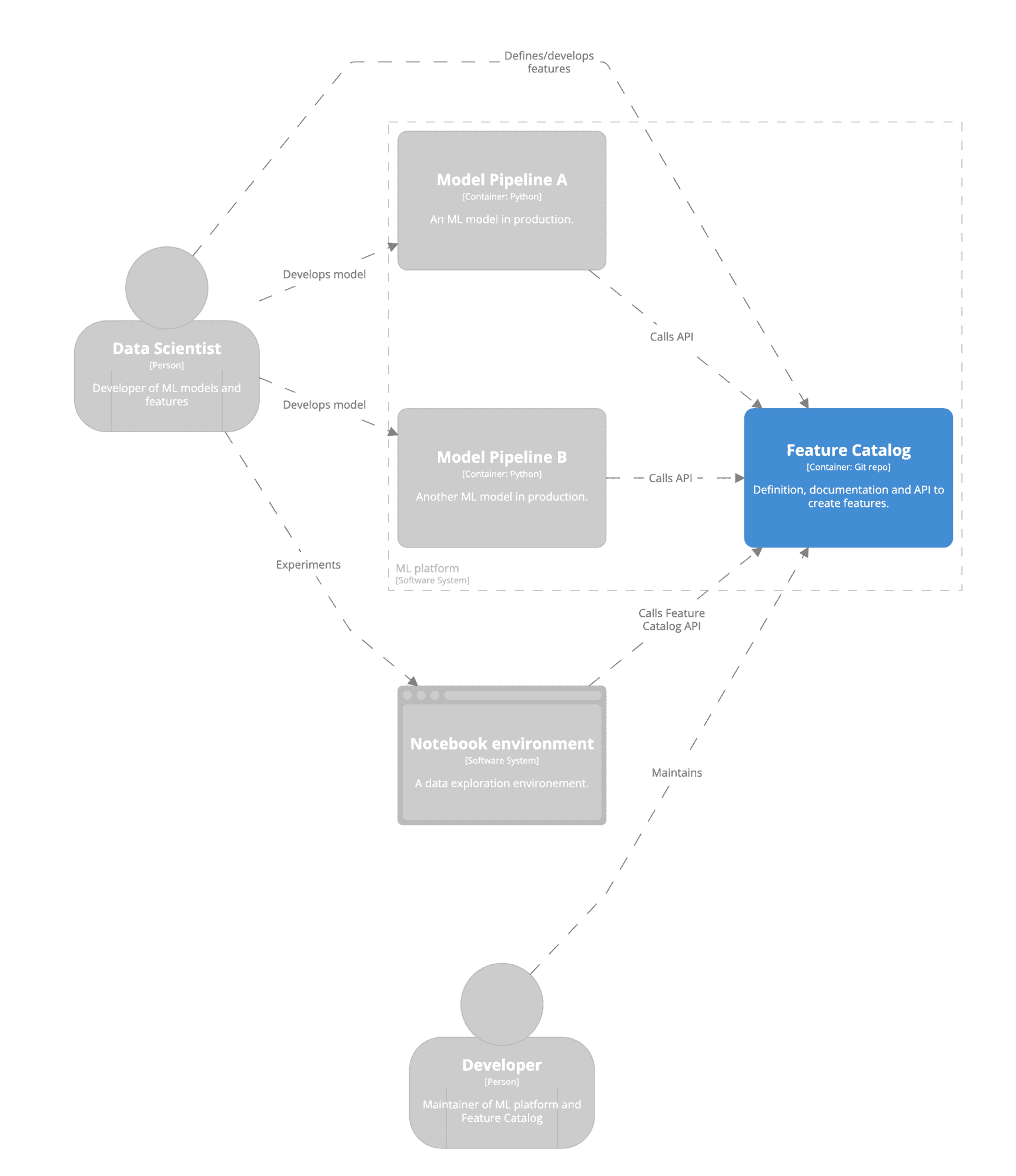
- Enthält einen Entwurf für eine C4-Architektur
- Enthält ein Diagramm, das Abhängigkeiten zwischen Features zeigt, die automatisch aus dem Code generiert werden können
Hier ist ein Beispiel für die Erstellung von Merkmalen mit diesem Repository (siehe auch das Beispiel-Notizbuch im Repository). Es berechnet zwei Merkmale, "darkshore_count" und "total_count", für alle Avatare im Datensatz.
all_avatars = spark.read.parquet("data/wow.parquet").select("avatarId").distinct()
features = compute_features(
spark=spark,
scope=all_avatars,
feature_groups=[
Zone(
features_of_interest=["darkshore_count", "total_count"],
aggregation_level="avatarId"
),
])
> avatarId darkshore_count total_count
> 0 0 76
> 1 0 19
> 2 0 192
Unten sehen Sie einen Teil der C4-Modellarchitektur, die in der gemeinsamen Vorlage enthalten ist. Dies gibt einen schematischen Überblick darüber, wie der Feature-Katalog in Ihrem Data Science-Workflow positioniert werden kann.
Nutzen Sie diesen Code und melden Sie sich, wenn Sie Fragen oder Ideen für Verbesserungen haben. Und natürlich sind Pull Requests willkommen.
Einpacken
Ein Feature-Katalog kann Data Science-Teams helfen, besser zusammenzuarbeiten. Sie brauchen weniger Zeit für sich wiederholende Arbeiten und erstellen bessere Funktionen, die einfach zu verwenden und zu pflegen sind. Und das, ohne die zusätzliche Komplexität eines Feature Stores hinzuzufügen. Wenn Sie ähnliche Probleme haben, können Sie die Vorlage verwenden, um Ihren eigenen Feature Catalog zu starten.
Verfasst von

Roel




Contact