Blog
Was sind Container, wie werden sie hergestellt und warum sind sie so gut?

In diesem Artikel möchte ich Ihnen eine einfache Zusammenfassung geben, damit Sie das Container-Paradigma selbst entdecken können. Wir werden versuchen, Fragen zu beantworten wie: Was sind Container, wie werden sie hergestellt und warum sind sie großartig? Als ich das erste Mal von "Containern" hörte, dachte ich, dass Container sehr kleine, abgespeckte Knoten sind. Nun, ich kann Ihnen sagen, dass das definitiv nicht der Fall ist. Das Wichtigste zuerst: Container sind keine VMs. Container bieten eine Möglichkeit, ein Betriebssystem zu virtualisieren, so dass mehrere Arbeitslasten auf einem einzigen Betriebssystem laufen (in dem Sinne, dass derselbe Kernel von den Containern gemeinsam genutzt wird). VMs virtualisieren die Hardware, so dass jede VM über eine eigene isolierte Instanz eines Betriebssystems verfügt (unter Verwendung eines Hypervisors). Das ist vielleicht schwer zu verstehen, wenn Sie anfangen, etwas über die Containerisierung zu lernen, und scheint vage zu sein, aber ich werde mein Bestes tun, um die Dinge auf dem Weg zu klären.
Die Container-Metapher
Die Containerisierung bietet eine saubere Trennung von Belangen. Sie bieten eine Abstraktion von der Umgebung, auf der sie ausgeführt werden. Wir packen alle Abhängigkeiten und Konfigurationen zusammen, so dass wir sie leicht verschieben können. Eine Analogie, auf die ich mich gerne beziehe, wenn ich Containerisierung beschreibe, ist, dass wir kleine Wohnungen haben, die sich die Sanitäranlagen und die Zentralheizung mit anderen kleinen Wohnungen teilen, aber jede Wohnung hat ihre eigenen Möbel, ihre eigene verschlossene Eingangstür und in einigen Wohnungen läuft vielleicht eine Katze namens Gizmo herum, in anderen nicht. Wir packen das Apartment in eine Kiste mit einer Vorlage, wie die Sanitär- und Zentralheizungsinstallation zu erfolgen hat, falls ein neues Energieversorgungsunternehmen beschließt, es zu übernehmen, und nennen es einen 'Container'. Durch diese Systemabstraktionsebene wird ein Container sehr portabel. Egal, ob Sie den Container in einer Staging-Umgebung oder in der Produktion einsetzen möchten, der Inhalt des Containers bleibt derselbe (vom Anwendungscode bis zu den installierten Abhängigkeiten). Wenn wir unsere Wohnung in ein anderes Gebäude verlegen wollen, haben wir alles vorbereitet. Wir besitzen jetzt Metadaten, von der Frage, ob die Katze in der Wohnung herumläuft oder nicht, über Metadaten zu den verfügbaren Möbeln bis hin zur Vorlage, wie die Sanitäranlagen und die Zentralheizung aussehen sollen. Dies ermöglicht eine viel leichtere portable Erfahrung. Wir müssen weniger booten und verbrauchen nur einen Bruchteil des Speichers im Vergleich zur Bereitstellung einer neuen isolierten Instanz eines Betriebssystems.
Was macht also einen Container aus?
Wie werden Prozesse isoliert, während sie denselben Kernel verwenden? Um diese Frage zu beantworten, müssen wir in den Linux-Kernel eintauchen. Sind Sie schon ganz aufgeregt? Der Linux-Kernel verfügt über einige Funktionen wie:
- Namespaces
- C-Gruppen
- Seccomp-bpf
Diese Funktionen ermöglichen es uns, Prozesse sicher voneinander zu isolieren, was wiederum diese "Wohnung in einer Box" ausmacht, von der wir vorhin sprachen und die als "Container" bezeichnet wird.
Aber wie verwenden Sie diese Kernel-Funktionen und was macht sie so sicher, dass wir sie isolieren können? Werfen wir einen Blick auf einige dieser Linux-Kernel-Funktionen.
Namespaces
Namespaces sind einer der Bausteine der Isolierung. Sie führen die Isolierung auf Kernel-Ebene durch. Ähnlich wie chroot funktioniert, das den Prozess in einem anderen Root-Verzeichnis einsperrt, trennen Namespaces andere Aspekte des Systems. Sie sind ein integraler Bestandteil der Architektur von Tools wie Docker. Namespaces wurden in der
Der Mount-Namensraum teilt das Dateisystem virtuell auf, so dass Prozesse, die in einem Mount-Namensraum laufen, nicht auf Dateien außerhalb ihres Einhängepunkts zugreifen können.
Der Process- oder pid.-Namensraum.
In Linux folgen Prozesse einem Zweig, einem so genannten Prozessbaum, wobei jede PID im Baum auf einen aktiven Prozess verweist. Der Prozess-Namensraum schneidet einen Zweig des Prozessbaums ab und verhindert den Zugriff auf weitere Zweige des Prozesses. Das ist wichtig, denn wenn ein Prozess das Privileg hat, andere Prozesse zu inspizieren oder sogar zu töten, dann haben wir ein Problem. Der Prozess, der dies tut, bleibt im übergeordneten Namensraum, im ursprünglichen Prozessbaum, macht aber das Kind zur Wurzel seines eigenen Prozessbaums.
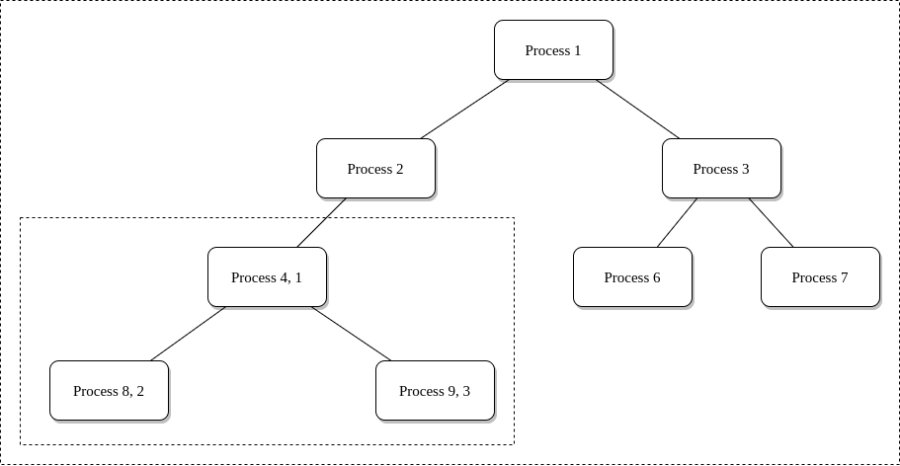 4 ist die PID im übergeordneten Prozessbaum und 1 ist die PID im neuen untergeordneten Prozessbaum.
4 ist die PID im übergeordneten Prozessbaum und 1 ist die PID im neuen untergeordneten Prozessbaum.
Mit der PID-Namensraumisolierung haben Prozesse im untergeordneten Namensraum keine Möglichkeit, von der Existenz der übergeordneten Prozesse zu erfahren. Prozesse im Eltern-Namensraum haben jedoch einen vollständigen Überblick über die Prozesse im Kind-Namensraum, so als wären sie jeder andere Prozess im Eltern-Namensraum. Der PID-Namensraum hindert den Prozess daran, andere Prozesse zu sehen oder mit ihnen zu interagieren.
Der Netzwerk- oder Net-Namensraum.
Ein Netzwerk-Namensraum ermöglicht es Prozessen, einen anderen Satz von Netzwerkschnittstellen und Routing-Tabellen zu sehen. Um eine brauchbare Netzwerkschnittstelle im untergeordneten Netzwerk-Namensraum bereitstellen zu können, müssen wir eine zusätzliche virtuelle Netzwerkschnittstelle erstellen.
Um ein- und ausgehenden Datenverkehr zu ermöglichen, müssen wir in der Lage sein, vom übergeordneten Netzwerk-Namensraum zur virtuellen Schnittstelle im untergeordneten Netzwerk-Namensraum zu kommunizieren. Dies kann durch die Erstellung einer Bridge und eines Routing-Prozesses erreicht werden. Da dies ein recht komplexes Thema ist, empfehle ich Ihnen, sich selbst darüber zu informieren.
C-Gruppen
Wir kennen jetzt die Theorie hinter der Systemisolierung auf der Kernel-Ebene, aber was wäre, wenn wir auch die Nutzung bestimmter Ressourcen dieser isolierten Komponente einschränken wollten? An dieser Stelle kommen Kontrollgruppen ins Spiel. Nehmen wir an, ich möchte, dass diese bestimmte Wohnung nicht mehr Strom als 0,8702 kWh verbraucht, wenn jemand zu Hause ist. Dies kann so interpretiert werden, dass eine Gruppe von isolierten Prozessen nicht mehr als die Menge N an Speicher verwendet.
Seccomp-bpf
Was wäre, wenn wir verhindern wollten, dass bestimmte Systemaufrufe vom Container an den Kernel erfolgen? Ein Apartment 121 sollte nicht das Recht haben, das Licht einzuschalten. Das wäre das Äquivalent dazu, einem Container mitzuteilen, dass er keine Rechte für den Zugriff auf das Internet hat. Was ein Container tun darf und was nicht, wird in Profilen definiert. Sie können verschiedenen Containern unterschiedliche Profile zuweisen. Das Standardprofil für einen Docker-Container finden Sie hier im Docker-Repository auf Github. Es blockiert 44 Syscalls von den 300 verfügbaren. Seccomp verwendet das Berkeley Packet Filter Programm, mit dem Sie auch benutzerdefinierte Filter einrichten können. Sie können Syscalls einschränken, indem Sie Bedingungen angeben, wie oder wann der Syscall eingeschränkt werden soll. Die Seccomp-Filter ersetzen die Syscalls durch Verweise auf das Bpf-Programm, das die Ausführung anstelle des Syscalls übernimmt.
Lassen Sie uns einen Container bauen!
Nachdem wir nun ein grundlegendes Verständnis für die Funktionen haben, können wir uns an die praktische Arbeit machen, indem wir einen "Container" von Grund auf erstellen. Es stellt sich heraus, dass es ziemlich einfach ist, neue Namespaces zu erstellen, Sie können einfach unshare ausführen. Erstellen Sie nun einen neuen PID-Namensraum und führen Sie die Bash darin aus.
[ec2-user@]$ sudo unshare --fork --pid --net --mount-proc bash
Wo befinden wir uns? Es scheint, als befänden wir uns in dem verzweigten Prozessbaum, von dem wir vorhin sprachen. Ich kann keine anderen Prozesse in diesem Prozessbaum außer der Bash sehen, das ist gut, wir mögen Isolation!
[root@ec2-user]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.1 0.4 124860 4028 pts/0 S 16:35 0:00 bash
root 16 0.0 0.3 164364 3924 pts/0 R+ 16:35 0:00 ps aux
Ich habe auch ein '-net'-Argument zum 'unshare'-Befehl hinzugefügt, der einen unabhängigen IPv4- und IPv6-Stack erzeugt. Neue Netzwerk-Namensräume verfügen standardmäßig über ein Loopback-Gerät, aber keine anderen Netzwerkgeräte. Um von Ihrem Netzwerk-Namensraum aus auf das Internet zugreifen zu können, empfehle ich Ihnen, die Konfigurationen für Netzwerk-Namensräume zu lesen.
[root@ec2-user]# ip link show
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
Es ist an der Zeit, sich mit der Kontrollgruppe zu beschäftigen, über die wir vorhin gesprochen haben. Ich habe ein Beispiel dafür gegeben, wie man die Speichernutzung einer Gruppe von Prozessen einschränken kann. Bevor wir dies tun können, müssen wir eine neue Ebene in der cgroup-Hierarchie erstellen. Ich habe sie 'mymemgroup' genannt.
[ec2-user@]$ sudo cgcreate -a ec2-user -g memory:mymemgroup
Schauen wir uns an, was sich in der Speicher-Cgroup 'mymemgroup' befindet.
Es sieht aus wie eine Reihe von Dateien, die Konfigurationen für die Speicher-Cgroup enthalten.
[ec2-user@]$ ls -l /sys/fs/cgroup/memory/mymemgroup
total 0
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 cgroup.clone_children
--w--w---- 1 ec2-user root 0 3 jul 17:13 cgroup.event_control
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 cgroup.procs
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.failcnt
--w--w---- 1 ec2-user root 0 3 jul 17:13 memory.force_empty
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.kmem.failcnt
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.kmem.limit_in_bytes
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.kmem.max_usage_in_bytes
-r--r--r-- 1 ec2-user root 0 3 jul 17:13 memory.kmem.slabinfo
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.kmem.tcp.failcnt
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.kmem.tcp.limit_in_bytes
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.kmem.tcp.max_usage_in_bytes
-r--r--r-- 1 ec2-user root 0 3 jul 17:13 memory.kmem.tcp.usage_in_bytes
-r--r--r-- 1 ec2-user root 0 3 jul 17:13 memory.kmem.usage_in_bytes
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.limit_in_bytes
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.max_usage_in_bytes
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.memsw.failcnt
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.memsw.limit_in_bytes
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.memsw.max_usage_in_bytes
-r--r--r-- 1 ec2-user root 0 3 jul 17:13 memory.memsw.usage_in_bytes
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.move_charge_at_immigrate
-r--r--r-- 1 ec2-user root 0 3 jul 17:13 memory.numa_stat
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.oom_control
---------- 1 ec2-user root 0 3 jul 17:13 memory.pressure_level
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.soft_limit_in_bytes
-r--r--r-- 1 ec2-user root 0 3 jul 17:13 memory.stat
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.swappiness
-r--r--r-- 1 ec2-user root 0 3 jul 17:13 memory.usage_in_bytes
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.use_hierarchy
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 notify_on_release
-rw-rw-r-- 1 root root 0 3 jul 17:13 tasks
Es gibt so viele Möglichkeiten, die Speichernutzung einzuschränken. Versuchen Sie, das harte Limit für den zugewiesenen Kernelspeicher zu ermitteln, indem Sie den Wert von memory.kmem.limit_in_bytes überprüfen.
[ec2-user@]$ cat /sys/fs/cgroup/memory/mymemgroup/memory.kmem.limit_in_bytes
9223372036854771712
Das sieht aus wie die höchste positive vorzeichenbehaftete 64-Bit-Ganzzahl (263-1), abgerundet auf Vielfache von 4096 (212), aber warum? Nach einigen Nachforschungen im Linux-Kernel habe ich herausgefunden, dass der Wert auf den Standardwert PAGE_COUNTER_MAX gesetzt ist und beim Lesen des Wertes mit PAGE_SIZE multipliziert wird. Es ist nicht die exakte Anzahl des möglichen Speichers in Bytes, da er auf die Stelle abgerundet wird, an der die letzten Bytes abfallen.
Diese Zahl ist das Maximum für die Speicherung einer Zahl in binärer Form in einem Speicher und offenbar der Standardwert für die Eigenschaft limit_in_bytes der Speichergruppe.
Versuchen wir, den Wert zu ändern und ihn auf 5 Megabyte zu senken, damit wir mit unserem Container auf der sicheren Seite sind.
[ec2-user@]$ sudo echo 5000000 > /sys/fs/cgroup/memory/mymemgroup/memory.limit_in_bytes
[ec2-user@]$ cat /sys/fs/cgroup/memory/mymemgroup/memory.limit_in_bytes
4997120
Es ist an der Zeit, die cgroup zu verwenden. Wir können cgexec verwenden, um eine Aufgabe in einer bestimmten cgroup auszuführen. Lassen Sie uns Bash in unserer auf 5 Megabyte beschränkten cgroup ausführen!
[ec2-user@]$ sudo cgexec -g memory:mymemgroup bash
Wir wollen nun das Verhalten unserer cgroup testen und sehen, wie sie auf das Überschreiten des zugewiesenen Speichers, 5 Megabyte, reagiert. Ich denke, dass 'yum get update' ein bisschen mehr braucht, um diesen Prozess zu initiieren. 'Beendet'! Es sieht so aus, als hätte der OOM ("Out of Memory") Killer den Prozess beendet und seine Aufgabe korrekt erledigt, danke OOM Killer. Der OOM Killer ist ein Daemon, der vom Linux-Kernel aufgerufen wird, wenn das System kritisch wenig Speicher hat oder wenn ein Prozess versucht, ein Speicherlimit zu umgehen. Dieser Daemon hat noch viel mehr Funktionen als die, die ich gerade erklärt habe, ich empfehle Ihnen, ihn zu lesen.
[root@ec2-user]# sudo yum get update
Killed
Es scheint, als hätten wir gute Arbeit geleistet! Wir haben eine isolierte Umgebung geschaffen und unsere Speichernutzung erfolgreich eingeschränkt.
Wir haben jetzt einen halben 'Container', glaube ich?
Ja, das stimmt. Ich saß gespannt auf meinem Stuhl, als ich damit herumspielte, obwohl ich mich schnell daran erinnern musste, dass ich kein Containerexperte bin und dass ich nicht versuchen sollte, das Rad neu zu erfinden, niemals. Es gibt eine Vielzahl von Tools wie Docker und Container-Clients auf niedrigerer Ebene, mit denen Sie Container erstellen können. Das Herumspielen mit diesen Linux-Kernel-Funktionen ist großartig, um ein gutes Verständnis für die Containerisierung zu bekommen, aber das war's (für mich). Wenn Sie tiefer in dieses Thema eintauchen möchten, empfehle ich Ihnen, die Fußnoten am Ende dieses Artikels zu lesen.
Container und Microservices
Container werden am besten in einer Microservice-Architektur eingesetzt, da jeder Dienst unabhängig und lose gekoppelt ist, um seine eigene Verantwortung als Service-Proxy zu erfüllen. Wir können einem Microservice problemlos einen Container zuweisen und nach dieser Regel messen. Da sich Container leicht aufsetzen lassen, ist auch die Skalierung einfach. Microservices skalieren unabhängig voneinander und Daten können dezentralisiert werden, da nicht hinter jedem Microservice die gleiche Art von Datenbank unterhalten werden muss. Ein Microservice könnte einen Dokumentenspeicher wie Elasticsearch verwenden, während ein anderer eine Datenbank wie Redis nutzt. Ich empfehle Ihnen, nachzulesen, wie Container und Microservices Hand in Hand gehen, da ich Ihnen hier nur eine einfache Zusammenfassung biete. Jetzt, da Sie Microservices haben, müssen Sie Lebenszyklus- und Aufgabenmanagement implementieren, wie z.B. Lastausgleich, Skalierungsrichtlinien, Routing, Zustandsüberwachung und Sicherheitsrichtlinien. Es gibt einige großartige Tools wie Google Cloud Run, AWS Fargate und Kubernetes, mit denen Sie Ihre Container-Workloads orchestrieren können. Nehmen wir unseren örtlichen Supermarkt als Beispiel. Dieser Supermarkt ist in 3 logisch unabhängige Komponenten (Microservices) aufgeteilt.
- Eine Zahlungs-Gateway-API, die der Kassenzähler ist.
- Eine Inventar-API, die den Überblick über die Artikel in Ihrem Geschäft behält.
- Eine Datenbank, die als unser Lieferant fungiert. Wenn wir plötzlich einen Ansturm von Zahlungsgateway-Anfragen erhalten, wäre es unlogisch, einen ganz neuen Laden zu eröffnen, denn warum sollten wir sowohl unsere Bestands-API als auch unsere Datenbank skalieren wollen, wenn es keine zusätzliche Belastung gibt? Wir fügen lieber 2 weitere Kassenschalter hinzu, und zwar schnell! Wenn sich einer der Mitarbeiter an der Kasse wegen der ganzen Hektik unwohl fühlen würde, würden wir einen 'Container' verlieren. In diesem Fall würden Systeme wie AWS Fargate dem Geschäft einen neuen Kassenschalter hinzufügen und einen gesunden Mitarbeiter zuweisen, der dahinter steht. Unterm Strich ermöglichen Container Flexibilität und Portabilität. Ingenieure sollten in der Lage sein, einen Container an eine beliebige Umgebung zu liefern, ohne sich um den Inhalt (Code, Laufzeit, Abhängigkeiten und Konfiguration) des Containers kümmern zu müssen.
Fußnoten
- Redhat bietet einige großartige Informationen über Namespaces, die manuelle Erstellung von Containern und seccomp, das war sehr nützlich.
- Die meisten meiner Nachforschungen habe ich durch das Lesen der Man Pages gemacht.
- IBMs Spektrum-Symphonie enthält eine sehr ausführliche Erklärung zu cgroup, die ich Ihnen empfehle.
Verfasst von

Bruno Schaatsbergen
Bruno is an open-source and serverless enthusiast. He tends to enjoy looking for new challenges and building large scale solutions in the cloud. If he's not busy with cloud-native architecture/development, he's high-likely working on a new article or podcast covering similar topics. In his spare time he fusses around on Github or is busy drinking coffee and exploring the field of cosmology.
Unsere Ideen
Weitere Blogs




Contact