Blog
Was ist nötig, damit ChatGPT meine Todoist-Aufgaben verwaltet?

Titel: "Was braucht es, damit ChatGPT meine Todoist-Aufgaben verwaltet?" Beschreibung: "Haben Sie sich jemals gefragt, was man braucht, um einen KI-Assistenten zu implementieren, der Ihren Todoist-Posteingang verwalten kann? In diesem Blog zeige ich Ihnen, wie ich meinen LLM-basierten Todoist-Agenten mithilfe des REACT-Frameworks implementiert habe." date: 2023-09-17T14:14:45+02:00 publishdate: 2023-09-17T14:14:45+02:00 tags: [] draft: false math: false image: "/cover.png" use_featured_image: true featured_image_size: 600x
Ich war schon immer von der Idee KI-basierter Assistenten wie Jarvis und Friday fasziniert. Vor kurzem wurde diese Faszination erneut geweckt, als ich über das Baby AGI-Projekt las. Das weckte in mir den Wunsch, selbst einen LLM-Agenten zu implementieren. Ich habe auch den idealen Anwendungsfall dafür. Ich bin ein großer Nutzer von Todoist, aber wie viele Todoist-Nutzer bin ich besser darin, meinen Todoist-Posteingang zu füllen, als ihn aufzuräumen. Daher würde ich mir einen KI-Assistenten wünschen, der mir dabei hilft. Er könnte zum Beispiel folgende Dinge für mich tun: ähnliche Aufgaben gruppieren, Aufgaben in das richtige Projekt verschieben oder sogar neue Projekte erstellen, wenn kein passendes Projekt existiert. Wie Sie in dem Demo-Video unten sehen können, ist mir das gelungen.
https://www.youtube.com/watch?v=QttrZMfdi2c
Jetzt fragen Sie sich vielleicht, wie ich das gemacht habe. Es läuft alles auf die folgenden Fragen hinaus:
- Wie können Sie LLM Aktionen durchführen lassen?
- Wie zwingen Sie den Agenten dazu, sich an den REACT-Rahmen zu halten?
- Wie können Sie die Antwort des Agenten analysieren und validieren?
- Wie gehen Sie mit LLMs um, die Fehler machen?
In diesem Blog werde ich einige Codeschnipsel zeigen, um zu erklären, was passiert. Aus Platzgründen kann ich jedoch nicht den gesamten Code in diesem Blog zeigen. Wenn Sie die gesamte Codebasis lesen möchten, finden Sie sie hier.
Wie können Sie LLM Aktionen durchführen lassen?
Bevor wir in die Details der Implementierung eintauchen, müssen wir zunächst einige Hintergrundinformationen darüber erörtern, wie wir LLMs die Fähigkeit geben, Aktionen auszuführen. Das Ziel dieses Projekts war es, einen LLM zu haben, mit dem wir ein Gespräch führen können. Wenn wir dem LLM während dieses Gesprächs sagen, dass er eine bestimmte Aufgabe ausführen soll, sollte er dazu auch in der Lage sein. Wenn wir dem LLM zum Beispiel sagen, dass er meinen Posteingang leeren soll, sollte er mir sagen, dass er gerade dabei ist, und mit der Ausführung dieser Aufgabe beginnen. Sobald er fertig ist, sollte er mir das mitteilen, und wir setzen unser Gespräch fort. Das hört sich einfach an, aber es unterscheidet sich von dem typischen Chat-Prozess, den wir gewohnt sind. Der Prozess besteht jetzt aus zwei Teilen: dem Konversationsteil und einem neuen Hintergrundprozessteil. In diesem Hintergrundteil wählt der LLM selbstständig Aktionen aus und führt sie aus, die ihm dabei helfen, die von uns gestellte Aufgabe zu erfüllen. Sie können sich diesen Prozess in etwa so vorstellen:
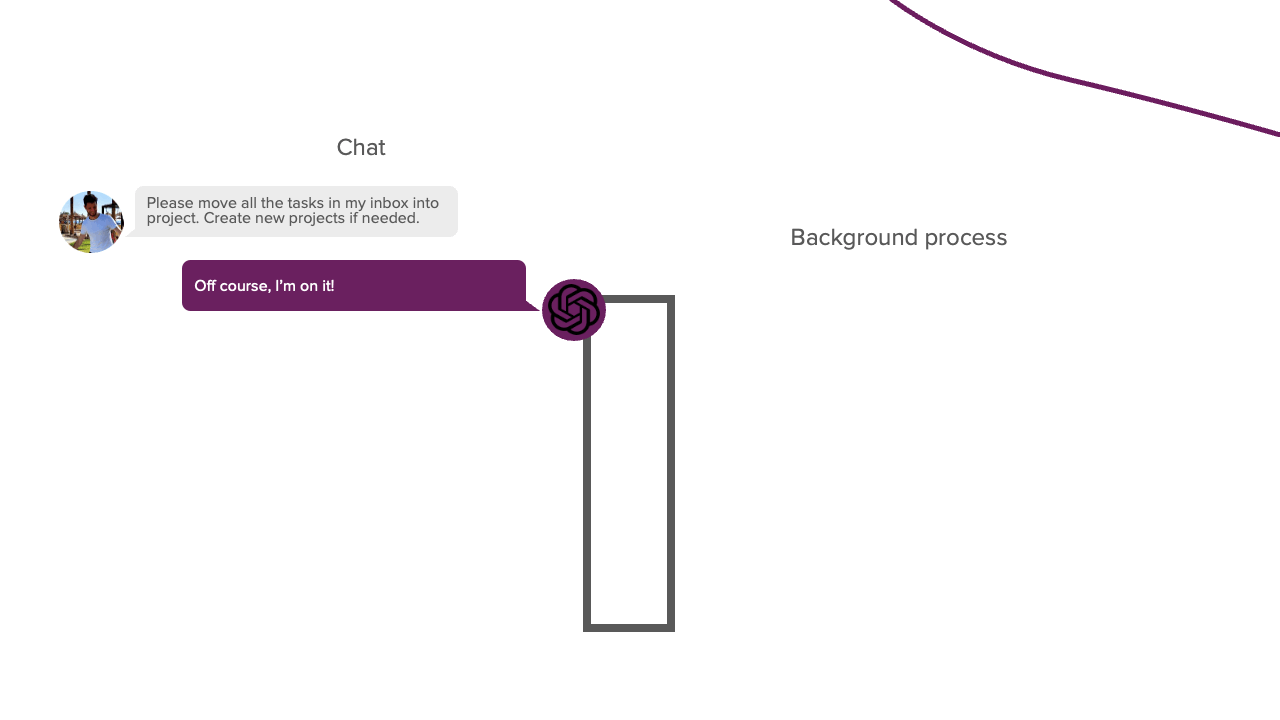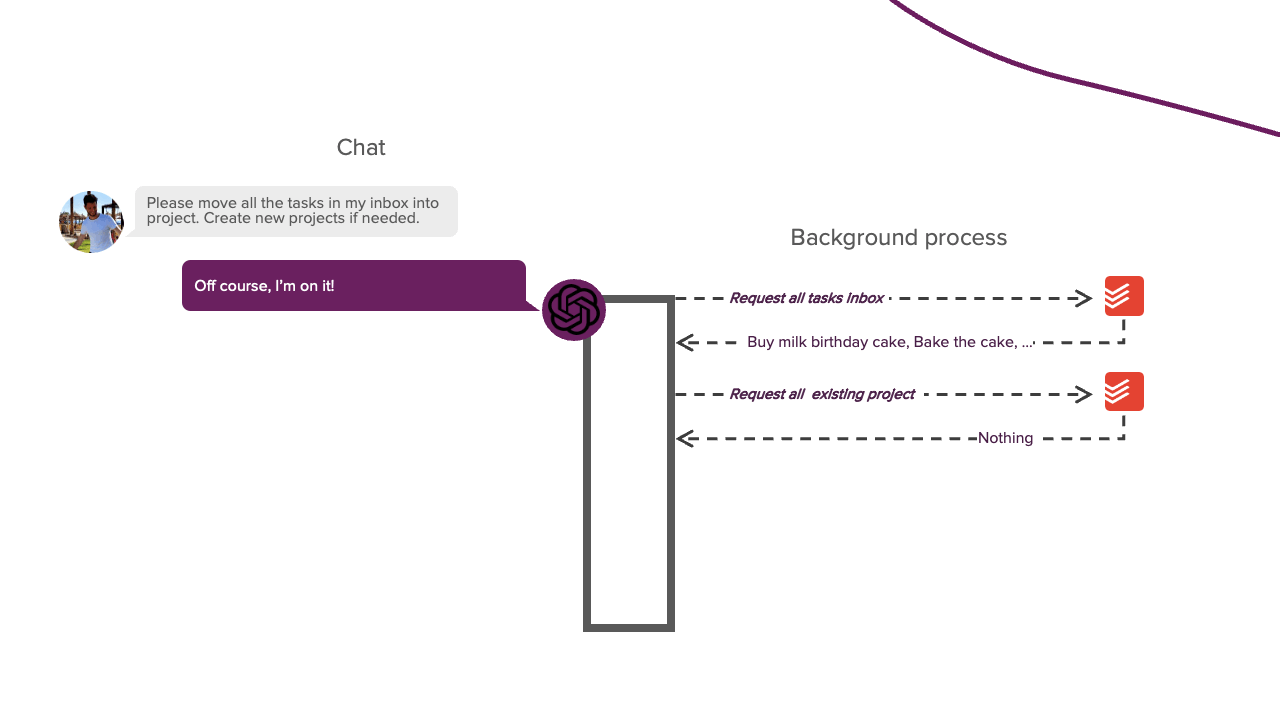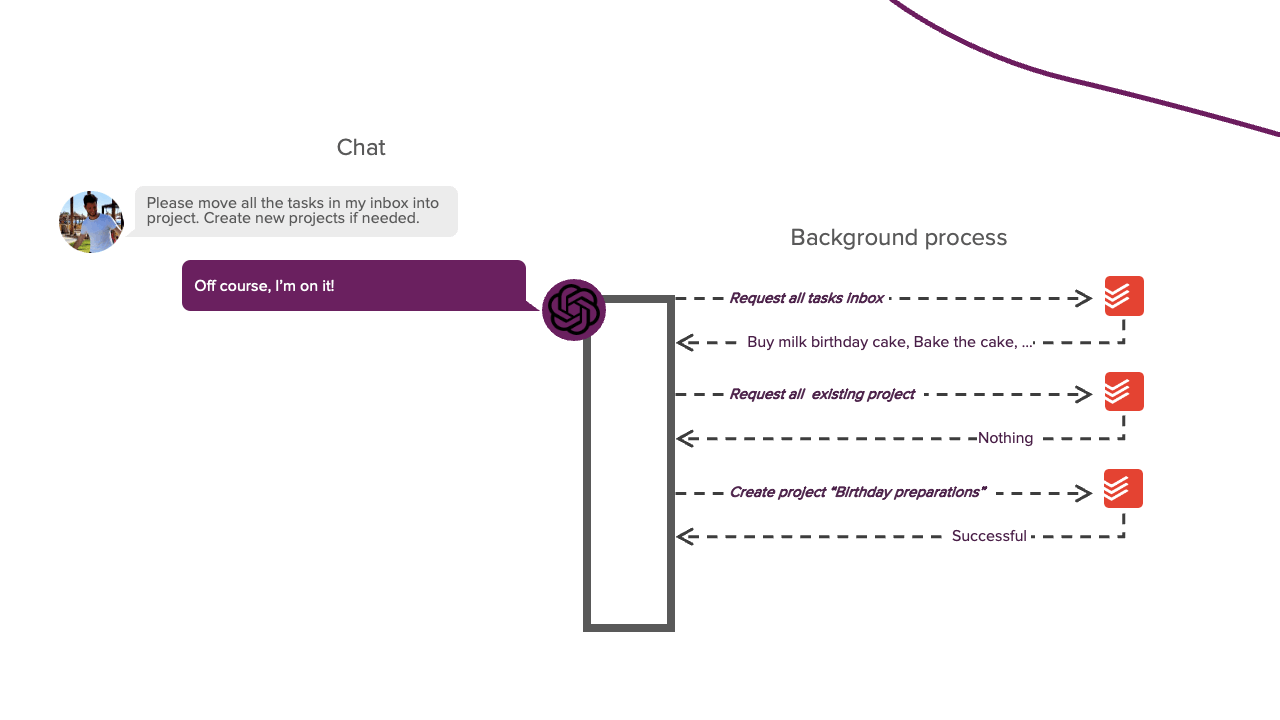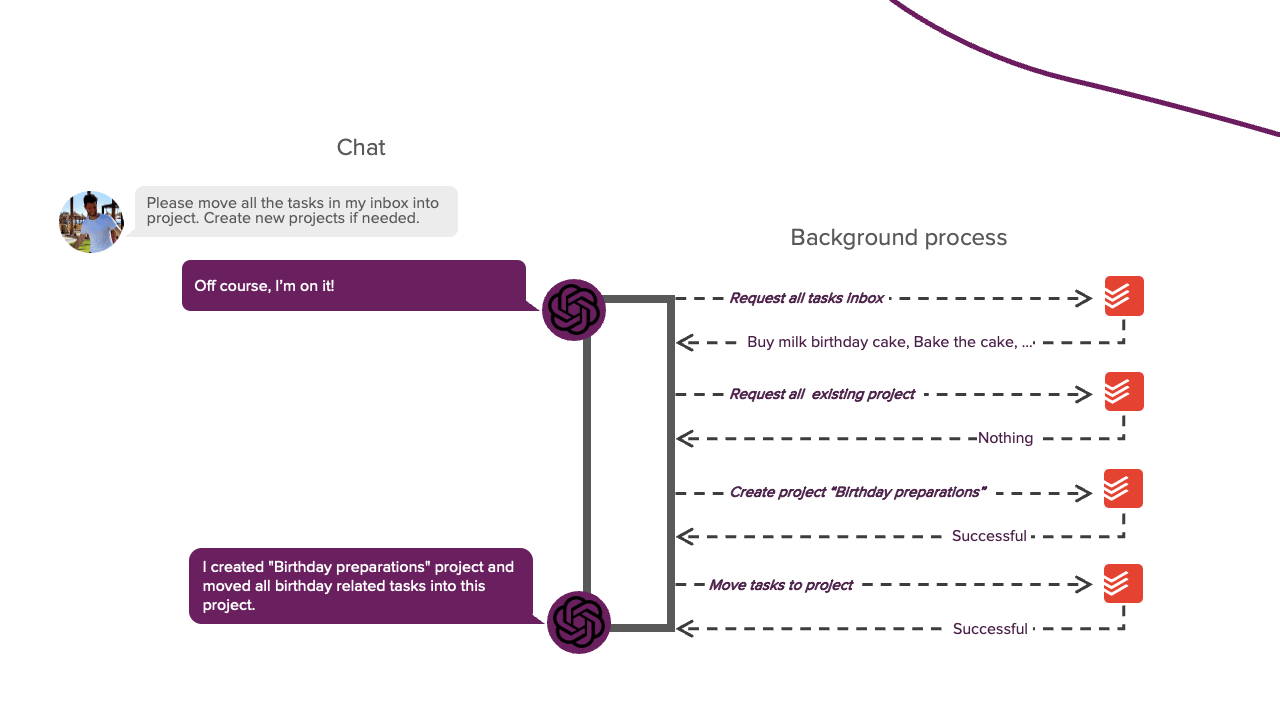
LLMs können dies standardmäßig nicht tun, da sie keine eigenständigen Aktionen durchführen können. Sie können nur mit generiertem Text auf uns reagieren. Wenn Sie sich jedoch jemals von einem LLM bei der Fehlersuche in einem Programm helfen lassen haben, wissen Sie, dass er Ihnen sagen kann, welche Aktion Sie durchführen sollten. Normalerweise führen Sie diese Aktion für den LLM aus; wenn sie noch nicht funktioniert, geben Sie ihm die entsprechende Fehlermeldung. Sie wiederholen diesen Vorgang, bis Sie das Problem gelöst haben. In diesem Szenario agieren Sie ähnlich wie bei dem Hintergrundprozess aus dem obigen Bild. Dieser Ansatz funktioniert, aber wir wollen etwas mehr Eigenständigkeit. Dazu müssen wir den LLM in einem parsbaren Format antworten lassen, das uns sagt, ob er eine bestimmte Aktion durchführen möchte. Ein Python-Skript kann dann diese Antwort parsen, die Aktion für den LLM ausführen und das Ergebnis an den LLM zurückgeben. Dieser Prozess ermöglicht es dem LLM, eigenständig Aktionen auszuführen. Diese Prompting-Technik wird REACT genannt und ist die Grundlage dieses Projekts. Der Systemprompt dieses Frameworks sieht wie folgt aus:
Use the following format:
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Die Antwort des LLM besteht nun also aus einem Thought und einem Action Teil. Im Thought Teil kann der LLM seinen Gedankengang erläutern, so dass er über seinen Fortschritt und frühere Beobachtungen nachdenken kann. Dieser Teil basiert auf der Chain-of-Thought-Technik und hilft, die Aufmerksamkeit des LLMs zu fokussieren. Der Teil Action ermöglicht es dem LLM, uns mitzuteilen, welche Aktion er durchführen möchte. Der LLM kann diese Aktion zwar immer noch nicht selbständig durchführen, aber zumindest kann er jetzt angeben, dass er eine bestimmte Aktion durchführen möchte. Ein Python-Skript kann diese Aktion dann parsen und für den LLM ausführen. Die Ausgabe dieser Aktion wird dann wieder in den LLM als Observation Teil eingespeist. Dieser Vorgang kann so lange wiederholt werden, bis der LLM seine Aufgabe abgeschlossen hat. Dann schreibt er den Teil Final Answer. Dieser Teil enthält den Text, der dem Benutzer angezeigt wird. Zum Beispiel: "Ich bin fertig mit X." und von hier aus kann die Konversation wie gewohnt fortgesetzt werden. Das ist die grundlegende Idee hinter dem REACT-Framework. Sehen wir uns nun an, wie wir das implementieren können.

Wie zwingen Sie den Agenten dazu, sich an den REACT-Rahmen zu halten?
Als ich mit diesem Projekt begann, habe ich schnell gelernt, dass es nicht so einfach ist, einen LLM Aktionen ausführen zu lassen. Die Implementierung des REACT-Frameworks ist gar nicht so schwer, aber die Handhabung all der Grenzfälle schon. Am interessantesten ist, dass all diese Randfälle auftreten, wenn Sie in Ihrer Systemaufforderung nicht explizit genug sind. Es ist so, als würden Sie einem Kind sagen, es solle sein Zimmer aufräumen. Wenn Sie sich nicht klar genug ausdrücken, wird es Ihre Anweisungen höchstwahrscheinlich falsch interpretieren oder, noch schlimmer, einen Weg finden, zu schummeln. Eine meiner ersten Aufforderungen sah zum Beispiel so aus wie die untenstehende Aufforderung. Sie müssen nicht alles lesen, aber es gibt Ihnen eine Vorstellung davon, wie lang ein Prompt werden kann, wenn Sie alle Regeln und Sonderfälle erklären müssen.
def create_system_prompt():
return """
You are a getting things done (GTD) ai assistant.
You run in a loop of Thought, Action, Action Input, Observation.
At the end of the loop you output an Answer to the question the user asked in his message.
Use the following format:
Thought: here you describe your thoughts about process of answering the question.
Action: the action you want to take next, this must be one of the following: get_all_tasks, get_inbox_tasks or get_all_projects, move_task, create_project.
Observation: the result of the action
.. (this Thought/Action/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Your available actions are:
- get_all_tasks: Use this when you want to get all the tasks. Return format json list of tasks.
- get_inbox_tasks: Use this get all open tasks in the inbox. Return format json list of tasks.
- get_all_projects: Use this when you want to get all the projects. Return format json list of projects.
- move_task[task_id=X, project_id=Y]: Use this if you want to move task X to project Y. Returns a success or failure message.
- create_project[name=X]: Use this if you want to create a project with name X. Returns a success or failure message.
Tasks have the following attributes:
- id: a unique id for the task. Example: 123456789. This is unique per task.
- description: a string describing the task. Example: 'Do the dishes'. This is unique per task.
- created: a natural language description of when the task was created. Example: '2 days ago'
- project: the name of the project the task is in. Example: 'Do groceries'. All tasks belong to a project.
Projects have the following attributes:
- id: a unique id for the project. Example: 123456789. This is unique per project.
- name: a string describing the project. Example: 'Do groceries'. This is unique per project.
- context: a string describing the context of the project. Example: 'Home'. Contexts are unique and each project belongs to a context.
"""
Sie könnten denken, dass die Aufforderung ziemlich eindeutig ist und funktionieren sollte. Leider fand der LLM zahlreiche Möglichkeiten, diese Aufforderung falsch zu interpretieren und Fehler zu machen. Nur eine kleine Auswahl der Dinge, die schief gelaufen sind:
- Das LLM formatierte die
move_taskimmer wieder auf unterschiedliche Weise. Zum Beispiel:move_task[task_id=X, project_id=Y],move_task[task_id = X, project_id = Y],move_task[X, Y],move_task[task=X, project=Y]. Das machte das Parsen ziemlich kompliziert. - Es hat versucht, Aktionen auszuwählen, die es nicht gab. Zum Beispiel:
loop through each task in the inbox. - Der LLM entschuldigte sich immer wieder für seine Fehler. Aufgrund dieser Entschuldigungen hielt sich das Format der Antwort nicht mehr an das REACT-Framework, was zu Parsing-Fehlern führte (und zu komplexerem Code, um diese Fehler zu behandeln).
- und viele mehr...
Ich habe versucht, diese Probleme zu beheben, indem ich die Systemaufforderung deutlicher formuliert habe, aber das hat nichts gebracht. Nach einigem Nachdenken wurde mir klar, dass Code ausdrucksstärker ist als Text. Daher beschloss ich, das Antwortformat als JSON-Schema zu definieren und den LLM zu bitten, nur JSON zu generieren, das sich an dieses Schema hält. Das Schema für die Aktion move_task sieht zum Beispiel so aus:
{
"title": "MoveTaskAction",
"description": "Use this to move a task to a project.",
"type": "object",
"properties": {
"type": {
"title": "Type",
"enum": [
"move_task"
],
"type": "string"
},
"task_id": {
"title": "Task Id",
"description": "The task id obtained from the get_all_tasks or get_all_inbox_tasks action.",
"pattern": "^[0-9]+$",
"type": "string"
},
"project_id": {
"title": "Project Id",
"description": "The project id obtained from the get_all_projects action.",
"pattern": "^[0-9]+$",
"type": "string"
}
},
"required": [
"type",
"task_id",
"project_id"
]
}
Dieses Schema ist viel expliziter als jede auf natürlicher Sprache basierende Erklärung, die ich schreiben könnte. Und was noch besser ist: Ich kann auch zusätzliche Validierungsbedingungen wie Regex-Muster hinzufügen. Man könnte meinen, dass die Erstellung dieser Art von Schemata viel mehr Arbeit macht als das Schreiben einer Systemabfrage. Dank der schema_json Methode, die dieses Schema automatisch für Sie generiert. In der Praxis werden Sie also nur den folgenden Code schreiben müssen:
class MoveTaskAction(pydantic.BaseModel):
"""Use this to move a task to a project."""
type: Literal["move_task"]
task_id: str = pydantic.Field(
description="The task id obtained from the"
+ " get_all_tasks or get_all_inbox_tasks action.",
regex=r"^[0-9]+$",
)
project_id: str = pydantic.Field(
description="The project id obtained from the get_all_projects action.",
regex=r"^[0-9]+$",
)
Und das pydantische Modell für die erwartete Reaktion des LLM sieht wie folgt aus:
...
class ReactResponse(pydantic.BaseModel):
"""The expected response from the agent."""
thought: str = pydantic.Field(
description="Here you write your plan to answer the question. You can also write here your interpretation of the observations and progress you have made so far."
)
action: Union[
GetAllTasksAction,
GetAllProjectsAction,
CreateNewProjectAction,
GetAllInboxTasksAction,
MoveTaskAction,
GiveFinalAnswerAction,
] = pydantic.Field(
description="The next action you want to take. Make sure it is consistent with your thoughts."
)
...
# The rest of action models excluded for brevity
Mit diesen Pydantic-Modellen weise ich nun den LLM an, nur mit JSON zu antworten, das diesem Schema entspricht. Dazu verwende ich die folgende Systemabfrage:
def create_system_prompt():
return f"""
You are a getting things done (GTD) agent.
You have access to multiple tools.
See the action in the json schema for the available tools.
If you have insufficient information to answer the question, you can use the tools to get more information.
All your answers must be in json format and follow the following schema json schema:
{ReactResponse.schema()}
If your json response asks me to preform an action, I will preform that action.
I will then respond with the result of that action.
Do not write anything else than json!
"""
Dank dieser Änderung in der System-Eingabeaufforderung machte der LLM nicht mehr die zuvor erwähnten Formatierungsprobleme. Infolgedessen musste ich viel weniger Randfälle abdecken, wodurch ich meine Codebasis erheblich vereinfachen konnte. Das macht mich als Entwickler immer sehr glücklich.
Wie können Sie die Antwort des Agenten analysieren und validieren?
An diesem Punkt haben wir einen LLM, der immer mit JSON antwortet und der LLM weiß, dass dieses JSON dem Schema aus dem obigen pydantischen Modell entsprechen muss. Wir müssen dieses JSON noch parsen und die Aktion, die der LLM durchführen möchte, daraus extrahieren. Hier kommt Pydantic ins Spiel. Die Funktion parse_raw von Pydantic kann das gesamte Parsing und die Validierung für uns übernehmen. Wenn das JSON dem Schema entspricht, gibt sie eine Instanz des Modells zurück. Diese Pydantic-Modelle arbeiten bemerkenswert gut mit der Anweisung match von Python zusammen, so dass wir problemlos die richtige Aktion auswählen können. In diesen Fällen führen wir die Aktion und den API-Aufruf für das LLM durch und geben das Ergebnis als Beobachtung zurück. Das Ergebnis ist ein Code zum Parsen und Auswählen von Aktionen, der in etwa wie folgt aussieht:
response = ReactResponse.parse_raw(response_text)
match response.action:
case GetAllTasksAction(type="get_all_tasks"):
... # preform get_all_tasks action
observation = ...
case GetAllProjectsAction(type="get_all_projects"):
... # preform get_all_projects action
observation = ...
case CreateNewProjectAction(type="create_project", name=name):
... # preform create_project action
observation = ...
case GetAllInboxTasksAction(type="get_inbox_tasks"):
... # preform get_inbox_tasks action
observation = ...
case MoveTaskAction(type="move_task", task_id=task_id, project_id=project_id):
... # preform move_task action
observation = ...
case GiveFinalAnswerAction(type="give_final_answer", answer=answer):
... # preform give_final_answer action
return answer
Innerhalb dieser case Anweisungen führen wir die Aktion aus, die der LLM durchführen möchte. Wenn der LLM beispielsweise eine Aufgabe verschieben möchte, verwenden wir die Attribute task_id und project_id aus dem Objekt MoveTaskAction, um den API-Aufruf für den LLM durchzuführen. Wir erstellen eine Beobachtung für den LLM auf der Grundlage dessen, was während dieses API-Aufrufs geschieht. Im Falle der Aktion move_task ist diese Beobachtung eine Erfolgs- oder Fehlermeldung. Im Falle von Datenerfassungsaktionen wie get_all_tasks und get_all_projects ist die Beobachtung eine JSON-Liste, die die angeforderten Daten enthält. Anschließend senden wir diese Beobachtung an den LLM, damit dieser mit der Generierung seiner nachfolgenden Antwort beginnen kann, womit wir wieder am Anfang dieses Codes angelangt sind. Wir fahren mit diesem Code in einer Schleife fort, bis der LLM die Aktion give_final_answer ausführt. (Oder bis eine andere Bedingung zum vorzeitigen Abbruch erfüllt ist, wie z.B. eine maximale Anzahl von Aktionen oder ein Zeitlimit.) Dann unterbrechen wir die Schleife und geben die Nachricht zurück, die der LLM an den Benutzer senden möchte, so dass die Konversation fortgesetzt werden kann.
Wie gehen Sie mit LLMs um, die Fehler machen?
Wir haben jetzt einen LLM, der eigenständig Aktionen durchführen kann, und wir haben einen Weg gefunden, um zu verhindern, dass er Formatierungsfehler macht. Dies sind jedoch nicht die einzigen Fehler, die ein LLM machen kann. Der LLM kann auch logische Fehler machen. Zum Beispiel könnte er:
- Versuchen Sie, ein Projekt mit einem Namen zu erstellen, der bereits existiert.
- Versuchen Sie, eine Aufgabe in ein Projekt zu verschieben, das nicht existiert.
- Versuchen Sie, eine Aufgabe mit einer
task_idzu verschieben, die nicht existiert. - Etc.
Der Umgang mit diesen Fehlern ist knifflig. Wir könnten nach diesen Fehlern suchen, aber dann würden wir wahrscheinlich die gesamte (Eingabeüberprüfungs-)Logik in der Todoist-API wiederholen. Ein spannenderer und weniger komplexer Ansatz ist es, einfach zu versuchen, die Aktion auszuführen. Wenn eine Ausnahme auftritt, fangen wir sie ab und leiten die Ausnahmemeldung als Beobachtung an den LLM zurück. Bei diesem Ansatz wird der LLM automatisch darüber informiert, dass er einen Fehler gemacht hat, und erhält alle notwendigen Informationen, um ihn zu korrigieren. Der Code für diesen Ansatz sieht ungefähr so aus:
...
try:
...
match response.action:
...
except Exception as e:
observation = f"""
Your response caused the following error:
{e}
Please try again and avoid this error.
"""
...
In der Abbildung unten sehen Sie zum Beispiel, dass der LLM etwas übereifrig ist und versucht, ein neues Projekt zu erstellen, obwohl es bereits ein Projekt mit diesem Namen gibt. Dies führt zu einer Ausnahme, die dann als Beobachtung an den LLM zurückgemeldet wird. Der LLM denkt über diese Ausnahme nach und beschließt dann, dass er zunächst versuchen sollte, alle Projekte mit der Aktion get_all_projects zu erhalten.

Ich finde das faszinierend. Das LLM hat seinen Fehler erkannt und eine Lösung entwickelt, um ihn zu beheben. Dieser Ansatz funktioniert also bemerkenswert gut. Es funktioniert sogar noch besser, wenn Sie Ausnahmemeldungen haben, die erklären, was schief gelaufen ist, und vorschlagen, wie man es beheben kann. Diese Dinge gehören bereits zu den besten Praktiken für vom Menschen beabsichtigte Ausnahmemeldungen. Daher finde ich es witzig, dass diese bewährten Verfahren auch auf den LLM-Agentenbereich übertragbar sind.
Einpacken
Sie haben nun ein grundlegendes Verständnis des REACT-Frameworks und wie ich es in meinem Todoist-Agenten implementiert habe. Dieses Proof-of-Concept-Projekt war für mich sehr aufschlussreich. Was mich bei diesem Projekt am meisten überrascht hat, war die Tatsache, dass sich die Fehler und Probleme, auf die ich gestoßen bin, deutlich von gewöhnlichen Softwareentwicklungsfehlern unterscheiden. Diese Fehler fühlten sich eher an wie Missverständnisse zwischen Menschen als wie tatsächliche Softwarefehler. Diese Beobachtung bringt mich zu der Frage, ob es noch andere Inspirationen gibt, die wir aus dem Bereich der Kommunikation beziehen und auf den Bereich der LLM-Agenten anwenden können. Das könnte etwas sein, das wir in einem zukünftigen Projekt erforschen sollten. Wie auch immer, ich hoffe, dieser Blog hat Sie dazu inspiriert, das REACT-Framework selbst auszuprobieren. Es macht unheimlich viel Spaß, diese Art von Agenten zu implementieren und mit ihnen herumzuspielen. Wenn Sie sich von meiner Codebasis inspirieren lassen möchten, finden Sie sie hier. Viel Glück und viel Spaß!
Verfasst von
Jordi Smit




Contact