Blog
Verwendung von Multiprojekt-Pipelines in GitLab

Ich habe bereits über die Verwendung von Child-Pipelines in GitLab geschrieben, aber es gibt noch eine andere Art von Pipeline, die Multiprojekt-Pipeline, mit der Sie mehrere separate Repositorys von einer einzigen Quelle aus steuern können.
Der Unterschied zwischen untergeordneten Pipelines und Multiprojekt-Pipelines
Eine Child-Pipeline ist eine Sub-Pipeline, die im Kontext desselben Repositorys ausgelöst wird. Die Vorteile werden in diesem Beitrag erläutert, aber das Wesentliche ist, dass Ihre Pipelines besser isoliert, schlanker und wiederverwendbar sind.
Stellen Sie sich nun vor, dass Sie ein oder mehrere unabhängige Repositorys haben (die vielleicht sogar ihre eigenen untergeordneten Pipelines verwenden), die jeweils ihre eigenen Regeln und Bedingungen für die Ausführung haben. In einem Multiprojekt-Pipeline-Setup würden Sie eine neue Master-Pipeline erstellen, die eine oder mehrere dieser Pipelines in ihren eigenen Repositories auslösen kann.
Nehmen wir zum Beispiel an, Sie haben mehrere Teams, die verschiedene Teile Ihrer Website verwalten, jedes mit seinem eigenen Repository. Sie können Aktualisierungen einspielen und einen Build starten, der auf der Website live geht. Es kann jedoch vorkommen, dass Sie Aktualisierungen aus verschiedenen Repositories synchronisieren müssen. Hier kommt ein "Manager"-Repository ins Spiel. Es kann die Pipelines der anderen Repositorys starten, vielleicht sogar in einer bestimmten Reihenfolge, ohne diese zu verändern.
Einfacher ausgedrückt: Eine Multiprojekt-Pipeline lässt die Pipeline eines Repositorys die Pipeline eines anderen Repositorys starten.
In diesem Blog werde ich die Begriffe Upstream und Downstream häufig verwenden. Hier ist, was ich meine:
- nachgelagert: Eine normale Pipeline in einem Repository, die ausgeführt wird, wenn die richtigen Bedingungen ausgelöst werden. Sie wird zum "Downstream", wenn sie von einem anderen Repository (Upstream) ausgelöst wird.
- Upstream: Eine Pipeline, die eine Pipeline in einem anderen Repository (Downstream) auslöst.
Eine einfache Multiprojekt-Pipeline
Lassen Sie uns mit einem einfachen Beispiel beginnen. Legen Sie zwei Repositories an, um dem Beispiel zu folgen.
Sie finden den Quellcode im Upstream-Repository und im Downstream-Repository.
Die erste zu definierende Datei ist .gitlab-ci.yml im Downstream-Repository:
downstream-job:
script: echo "I test the code"
Wenn wir diese Datei pushen, startet die Pipeline und läuft wie gewohnt.
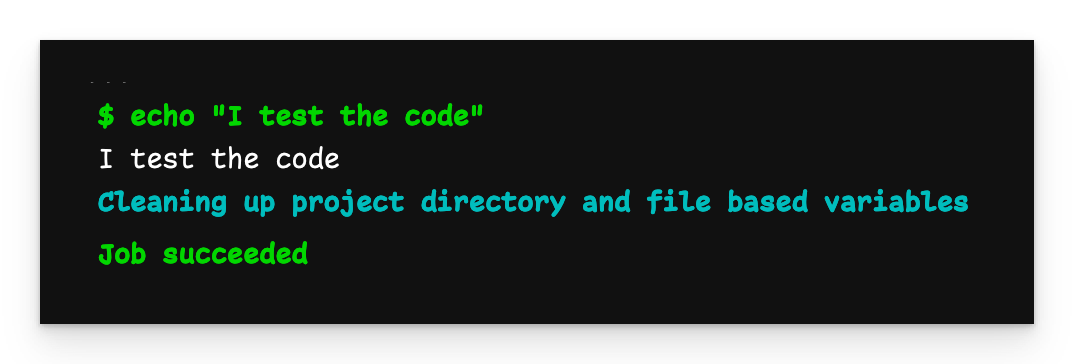
Einfache Pipeline-Ausgabe
Die nächste Datei ist .gitlab-ci.yml im Upstream-Repository:
trigger-downstream-job:
trigger:
project: zaayman-samples/using-multi-project-pipelines-in-gitlab-downstream
branch: basic-multi-project-pipeline
Beachten Sie, dass wir keinen Dateinamen für die im nachgeschalteten Repository definierte Pipeline angeben. Das liegt daran, dass wir die reguläre Pipeline dieses Repositorys auslösen und die ist immer in .gitlab-ci.yml definiert.
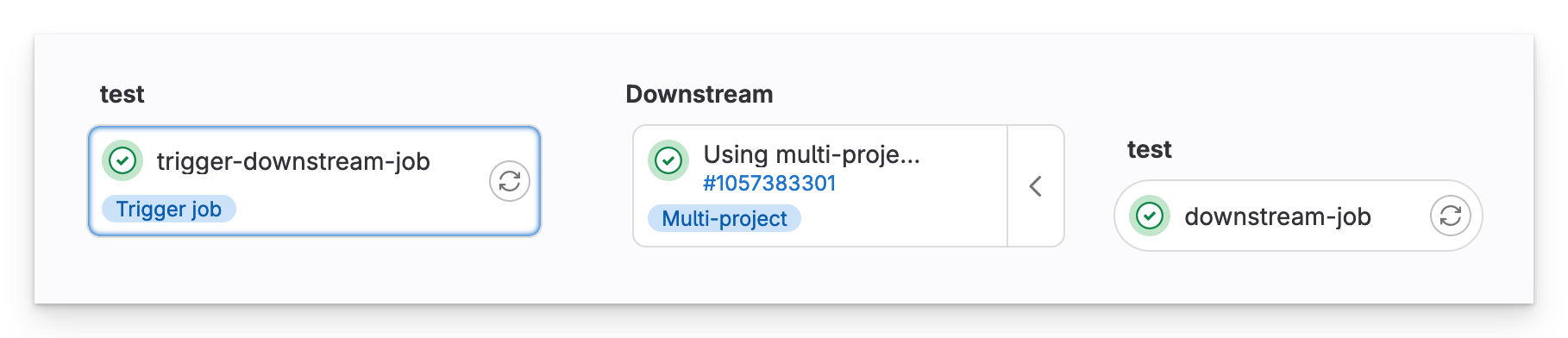
Vorgelagerte Pipeline
In der Upstream-Pipeline sehen wir, dass in unserem anderen Repository eine Multiprojekt-Downstream-Pipeline ausgelöst wurde.
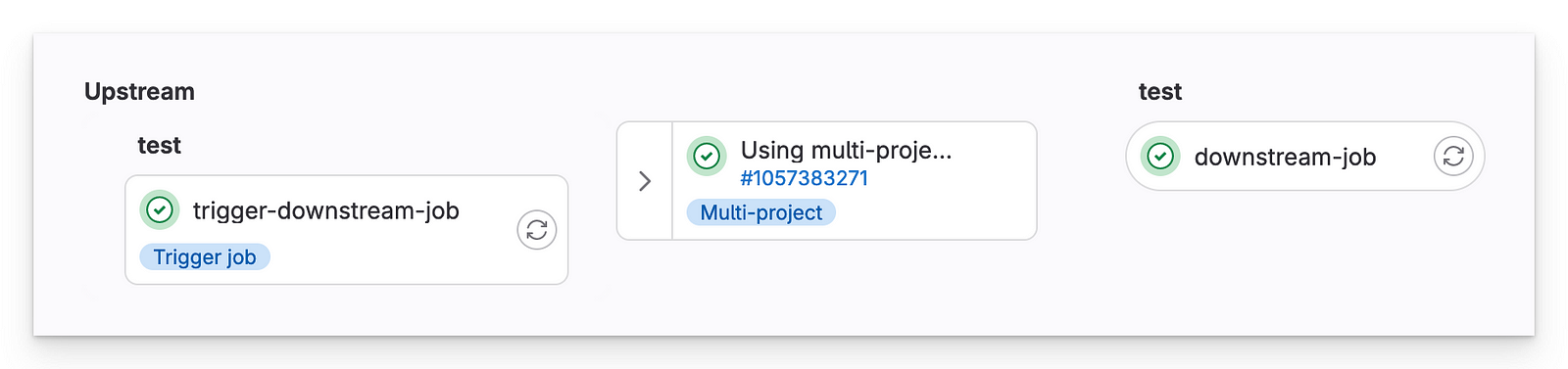
Nachgelagerte Pipeline
Die wichtigsten Erkenntnisse aus diesem Beispiel sind:
- Das Repository mit dem Basisauftrag ist ein normales, unabhängiges Repository und eine Pipeline. Es wird nur dann zu einem "nachgelagerten" Repository, wenn es durch das vorgelagerte Repository ausgelöst wird.
- Das "Manager"-Repository kann dieses Repository veranlassen, seine Pipeline so auszuführen, als ob es normal ausgelöst worden wäre.
Übergabe von Variablen
Wie bei den Beispielen aus dem Beitrag über untergeordnete Pipelines werden die Variablen, die Sie in der Upstream-YAML-Datei definieren, an die Downstream-Pipeline weitergegeben. Allerdings wird keine der GUI-Variablen, die Sie unter Einstellungen > CI/CD > Variablen definieren, automatisch an die Pipeline des nachgeschalteten Repositorys weitergegeben. Das liegt daran, dass sie in einem völlig anderen Repository läuft. Wenn Sie möchten, dass sie auf diese Variablen zugreifen kann, müssen Sie sie manuell übergeben.
Sie finden den Quellcode im Upstream-Repository und im Downstream-Repository.
Wir beginnen im Downstream-Repository mit .gitlab-ci.yml:
variables:
GLOBAL_VAR: Downstream
job-local-entry-point:
variables:
LOCAL_VAR: Downstream
trigger:
include: child-pipeline.yml
Für diese Pipeline habe ich 3 Variablen definiert:
- Eine GUI-Variable unter Einstellungen > CI/CD > Variablen namens
$GUI_VAR - Eine globale Variable namens
$GLOBAL_VAR - Eine job-lokale Variable namens
$LOCAL_VAR
Als nächstes definieren wir die child-pipeline.yml: Datei, die ausgelöst wird.
child-job:
script:
- echo "Doing some testing"
- echo "GUI_VAR=$GUI_VAR"
- echo "GLOBAL_VAR=$GLOBAL_VAR"
- echo "LOCAL_VAR=$LOCAL_VAR"
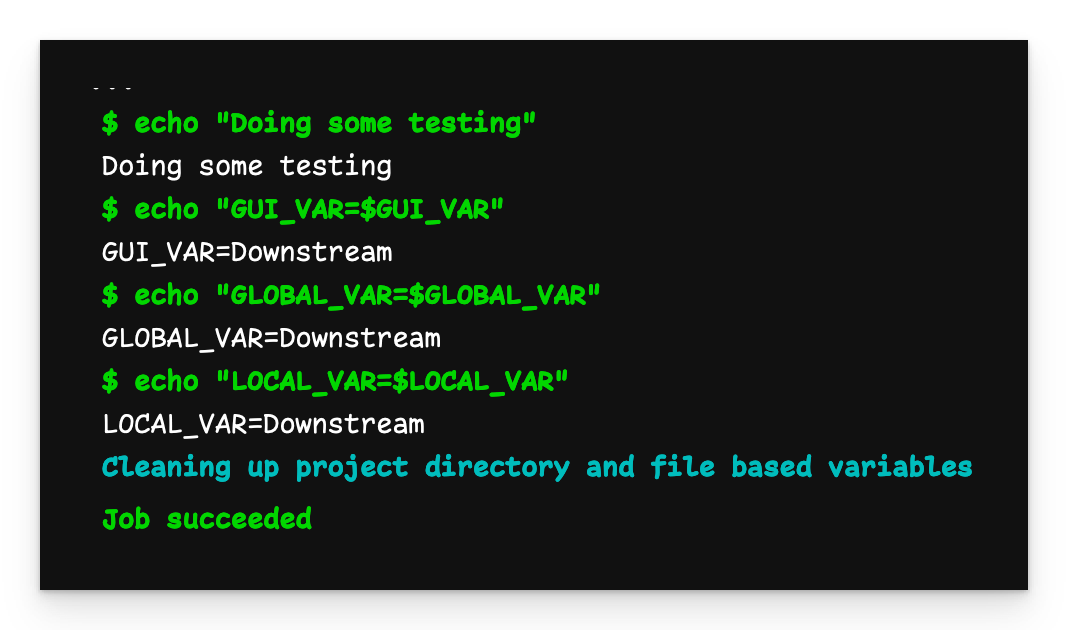
An die Child-Pipeline übergebene Variablen
Wir sehen, dass alle Variablen den Wert Downstream haben, wie wir sie definiert haben.
Kommen wir nun zum Upstream-Repository. Zunächst definieren wir ebenfalls eine GUI-Variable namens $GUI_VAR mit dem Wert Upstream. Dann definieren wir .gitlab-ci.yml:
variables:
GUI_VAR: $GUI_VAR
GLOBAL_VAR: Upstream
manager-trigger-job:
variables:
LOCAL_VAR: Upstream
trigger:
project: zaayman-samples/using-multi-project-pipelines-in-gitlab-downstream
branch: passing-variables
Für die Upstream-Pipeline habe ich 3 Variablen definiert:
- Eine GUI-Variable namens
$GUI_VAR - Eine globale Variable namens
$GLOBAL_VAR - Eine job-lokale Variable namens
$LOCAL_VAR
Wir müssen auch die .gitlab-ci.yml Datei des nachgelagerten Repositorys aktualisieren:
variables:
GLOBAL_VAR: Downstream
job-local-entry-point:
rules:
- if : $CI_PIPELINE_SOURCE != "pipeline" # Add this rule
variables:
LOCAL_VAR: Downstream
trigger:
include: child-pipeline.yml
job-upstream-entry-point: # Add this job
rules:
- if: $CI_PIPELINE_SOURCE == "pipeline"
variables:
GUI_VAR: $GUI_VAR
GLOBAL_VAR: $GLOBAL_VAR
LOCAL_VAR: $LOCAL_VAR
trigger:
include: child-pipeline.yml
Beachten Sie die Regeln, die ich hinzugefügt habe. Wenn eine Pipeline durch eine vorgelagerte Pipeline ausgelöst wird, wird $CI_PIPELINE_SOURCE zu "pipeline", d.h. job-upstream-entry-point wird ausgeführt. Wenn sie normal ausgelöst wird (z.B. durch einen Push), wird job-local-entry-point ausgeführt.
Wir haben jetzt zwei getrennte Einstiegspunkte in die nachgelagerte Pipeline, wobei die an die untergeordnete Pipeline übergebenen Variablen unterschiedlich sind, je nachdem, wie die Pipeline ausgelöst wurde.
Jetzt pushen wir die Upstream-Pipeline-Datei.
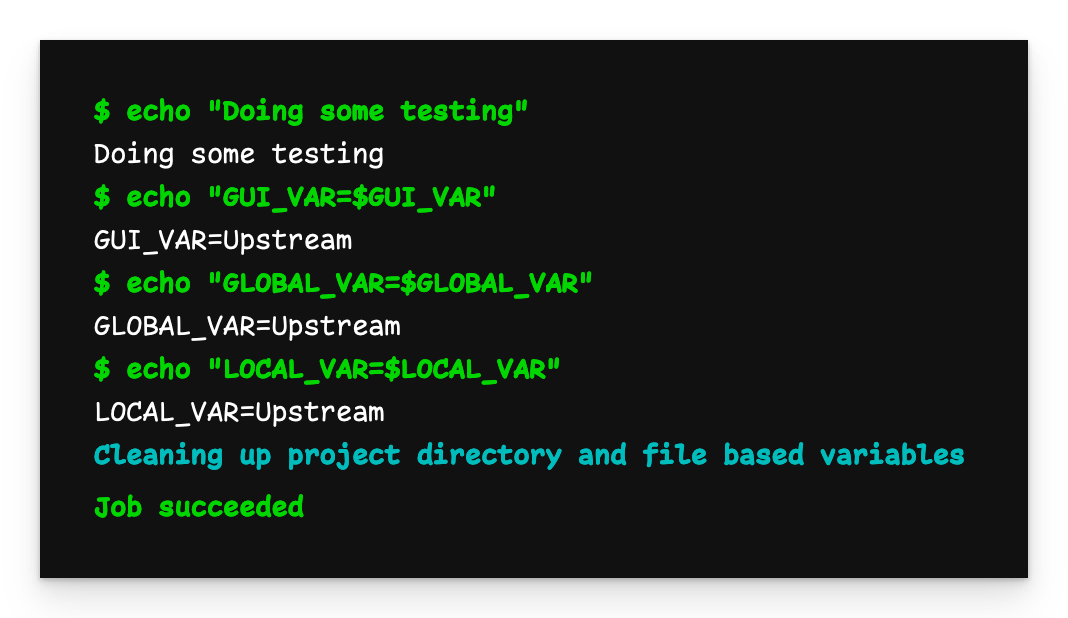
Downstream-Pipeline-Ausgabe mit Upstream-Variablen
Wenn wir nun die Ausgabe der nachgelagerten Pipeline untersuchen, sehen wir, dass alle Variablen jetzt den Wert Upstream haben, den sie von der vorgelagerten Pipeline erhalten haben.
Sicherheitsbedenken
Seien Sie vorsichtig, wenn Sie eine Pipeline in einem Projekt auslösen, über das Sie keine Kontrolle haben. Es ist durchaus möglich, dass böswillige Akteure einen ehemals harmlosen Code in einen bösartigeren umwandeln. Während der Code in einem völlig separaten (und isolierten) Projekt ausgeführt wird, wissen Sie nicht, welcher Kontext von GitLab freigegeben wird (oder versehentlich durchsickert), wenn die nachgeschaltete Pipeline ausgelöst wird. Dies ist besonders gefährlich, wenn Sie Variablen mit der Child-Pipeline gemeinsam nutzen. Am besten vermeiden Sie dies ganz und forken das Repository, damit Sie die volle Kontrolle darüber haben.
Übergabe von Dateien
Die Übergabe von Dateien in einem Multiprojekt-Setup (wenn Sie nicht das Premium-Abonnement nutzen) ist etwas komplizierter als bei einer Child-Pipeline, aber dennoch möglich. Allerdings müssen wir außerhalb von GitLab gehen und die Dateien mit curl aus der Upstream-Pipeline abrufen.
Sie können den Quellcode im Referenz-Repository und im Child-Repository finden.
Beginnen wir mit der Datei .gitlab-ci.yml des Downstream-Repositorys:
downstream-job:
script: |
if [ "$CI_PIPELINE_SOURCE" == "pipeline" ]; then
curl -L --header "PRIVATE-TOKEN: $ACCESS_TOKEN"
"https://gitlab.com/api/v4/projects/$PROJECT_ID/jobs/artifacts/$BRANCH/download?job=create-file-job"
--output artifact.zip
unzip artifact.zip
else
echo "Downstream" > file.txt
fi
cat file.txt
Ignorieren Sie die $ Variablen für den Moment.
Diese Pipeline hat zwei Verhaltensweisen, je nachdem, wie sie gestartet wird. Wenn sie von einer Upstream-Pipeline ausgelöst wird, verwendet sie curl, um das Artefakte-Archiv von der GitLab-API abzurufen. Wenn sie lokal ausgeführt wird, erstellt sie file.txt.
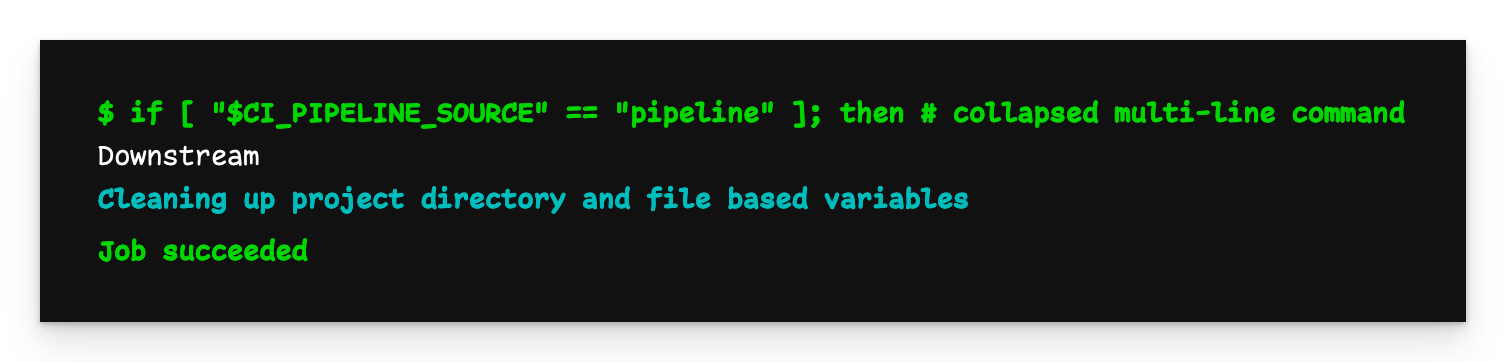
Ausgang der nachgelagerten Pipeline
Wie erwartet, wurde der "Downstream"-Fluss ausgeführt und wir haben eine Datei mit dem Inhalt "Downstream".
Lassen Sie uns nun .gitlab-ci.yml im Upstream-Repository definieren:
create-file-job:
stage: build
script:
- echo "Upstream" > file.txt
artifacts:
paths:
- file.txt
upstream-trigger-job:
stage: test
variables:
PROJECT_ID: $PROJECT_ID
ACCESS_TOKEN: $ACCESS_TOKEN
BRANCH: $CI_COMMIT_REF_NAME
trigger:
project: using-multi-project-pipelines-in-gitlab-downstream
branch: passing-files
Damit dieses Beispiel funktioniert, benötigen Sie ein paar zusätzliche Variablen:
- ACCESS_TOKEN: Klicken Sie in der Web-Benutzeroberfläche auf Ihr Profilbild und dann auf Präferenzen > Zugriffstoken. Wenn Sie noch keins haben, erstellen Sie ein Zugriffstoken, geben Sie ihm den Geltungsbereich
read_apiund speichern Sie es. - PROJECT_ID: Klicken Sie in der Web-Benutzeroberfläche auf Einstellungen > Allgemein. Hier finden Sie die Projekt-ID.
Fügen Sie nun diese beiden Werte als Variablen in der GUI unter Einstellungen > CI/CD > Variablen hinzu.
GUI-Variablen
In der Pipeline-Datei übergeben Sie ACCESS_TOKEN und PROJECT_ID an die nachgelagerte Pipeline sowie den aktuellen Zweig (CI_COMMIT_REF_NAME), in dem der vorgelagerte Auftrag läuft. Dadurch erfährt der Befehl curl, aus welchem Zweig die Datei heruntergeladen werden soll.
Die Übergabe von Dateien in einer Multiprojekt-Konfiguration ist etwas komplizierter als bei Child-Pipelines, aber dennoch möglich. Allerdings müssen wir außerhalb von GitLab gehen und die Dateien mit curl aus der Upstream-Pipeline abrufen.
Sie können den Quellcode im Referenz-Repository und im Child-Repository finden.
Damit dieses Beispiel funktioniert, benötigen Sie ein paar zusätzliche Variablen:
- ACCESS_TOKEN: Klicken Sie in der Web-Benutzeroberfläche auf Ihr Profilbild und dann auf Präferenzen > Zugriffstoken. Wenn Sie noch keins haben, erstellen Sie ein Zugriffstoken, geben Sie ihm den Geltungsbereich
read_apiund speichern Sie es. - PROJECT_ID: Klicken Sie in der Web-Benutzeroberfläche auf Einstellungen > Allgemein. Hier finden Sie die Projekt-ID.
Mit diesen Informationen sind Sie bereit, weiterzumachen.
Beginnen wir mit unserem Manager-Repository und definieren .gitlab-ci.yml:
create-file-job:
stage: build
script:
- echo "Important stuff" > file.txt
artifacts:
paths:
- file.txt
parent-trigger-job:
stage: test
trigger:
project: zaayman-samples/using-child-pipelines-in-gitlab-child
branch: main
Als nächstes definieren wir .gitlab-ci.yml im nachgelagerten Repository:
child-job:
script: |
curl -L --header "PRIVATE-TOKEN: <ACCESS_TOKEN>"
"https://gitlab.com/api/v4/projects/<PROJECT_ID>/jobs/artifacts/main/download?job=create-file-job"
--output artifact.zip
unzip artifact.zip
cat file.txt
Die Datei .gitlab-ci.yml des nachgelagerten Projekts verwendet einen einfachen curl Befehl, um die Datei von der GitLab API abzurufen.
Ersetzen Sie die obigen Platzhalter durch IhreACCESS_TOKENundPROJECT_ID. Beachten Sie auch, dass Sie den Namen des Jobs angeben müssen, der das Artefakt erstellt hat (in diesem Fallcreate-file-job).
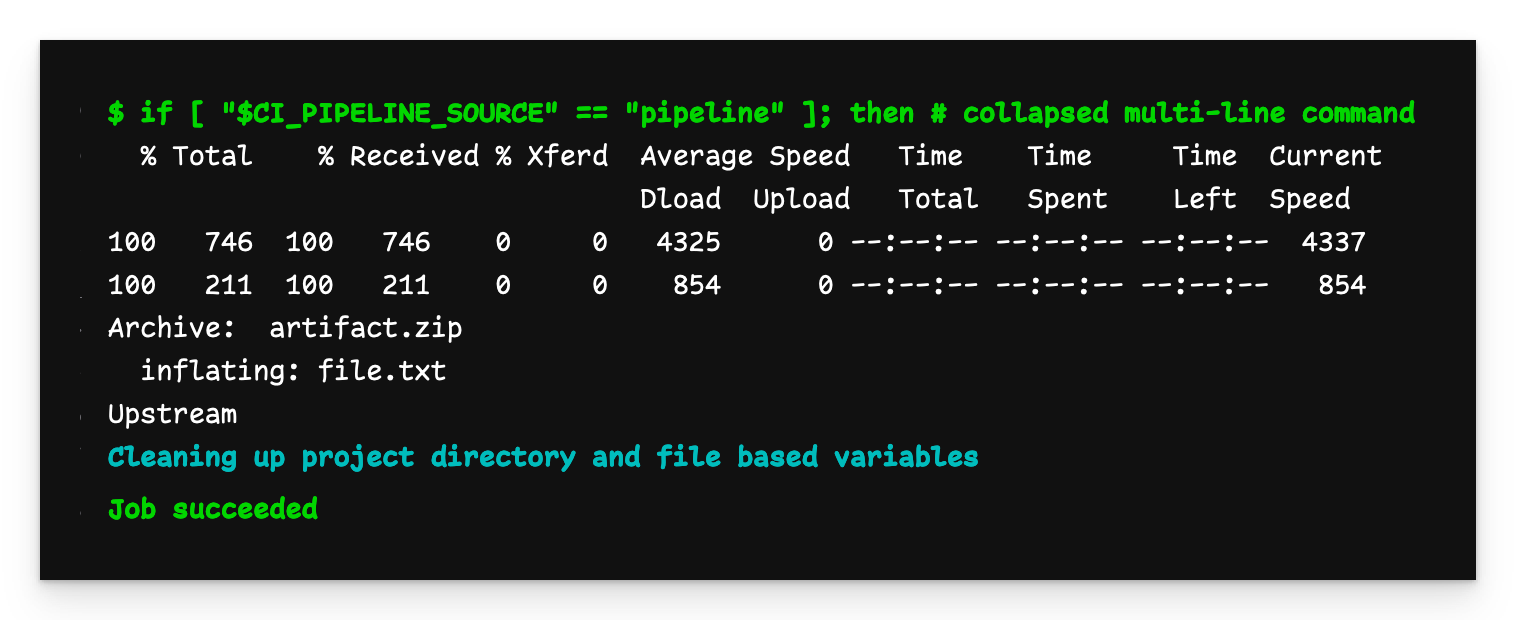
Multi-Projekt Child-Pipeline-Ausgabe
Die Ausgabe von child-jobim entfernten Repository (d.h. "Upstream") zeigt, dass die Datei erfolgreich heruntergeladen und extrahiert wurde.
Letzte Notizen
- Eine untergeordnete Pipeline wird in demselben Repository ausgeführt wie die Pipeline, die sie ausgelöst hat, während eine Multiprojekt-Pipeline in dem Repository ausgeführt wird, das demjenigen nachgelagert ist, das sie ausgelöst hat.
- Wenn Sie eine untergeordnete Pipeline verwenden, stehen die in der GUI definierten Variablen automatisch für die untergeordnete Pipeline zur Verfügung, während eine in einem Upstream-Repository definierte GUI-Variable nicht automatisch an eine nachgeordnete Multiprojekt-Pipeline weitergegeben wird.
- Eine untergeordnete Pipeline ist auf zwei Verschachtelungsebenen beschränkt (d.h. Elternteil/Kind/Enkelkind), während eine Multiprojekt-Pipeline unendlich viele Auslöser haben kann (d.h. Pipeline A kann Auslöser für B sein, die wiederum Auslöser für C sein kann, die wiederum Auslöser für D sein kann, usw.).
Fazit
Multiprojekt-Pipelines können nützlich sein, um eine zentrale Kontrolle über Ihre bestehenden Pipelines zu erhalten. Wenn Sie alle Ihre Pipelines unter diesem Gesichtspunkt erstellen, kann sich jedes Repository auf seine Funktionalität konzentrieren, während sich das Manager-Repository auf die Koordination konzentrieren kann.
Verfasst von
Jeffrey Zaayman
Unsere Ideen
Weitere Blogs




Contact