Blog
Verwendung untergeordneter Pipelines in GitLab

Child-Pipelines in GitLab ermöglichen es Ihnen, ein strafferes und wiederverwendbares Verhalten zu erstellen. Sie sind separate Pipelines, die von einer übergeordneten Pipeline ausgelöst werden.
Warum sollten Sie Child-Pipelines verwenden?
Wenn eine normale Pipeline ausgeführt wird, wird der gesamte Code der Dateien, die Sie eingebunden haben, in .gitlab-ci.yml entsorgt. Deshalb müssen Sie jedem Job einen eindeutigen Namen geben und immer wieder dieselben Regeln einfügen, so dass einige nur bei einer Merge-Anfrage oder im Hauptzweig ausgeführt werden. Das ist das Äquivalent von Spaghetti-Code und macht Ihre Pipeline komplexer und schwieriger zu aktualisieren.
Eine untergeordnete Pipeline ist ein neuer Kontext mit einer eigenen Teilmenge von Aufträgen. Alle Regeln, die Sie haben, müssen nur verarbeitet werden, wenn Sie entscheiden, die untergeordnete Pipeline zu starten. Dies führt zu schlankerem und wiederverwendbarem Code. Auch Änderungen sind einfacher, da Sie sich nur auf das Verhalten einer kleinen Teilmenge von Aufträgen konzentrieren müssen.
Hier sind einige Fälle, in denen Child-Pipelines am sinnvollsten sind:
- Aufbrechen eines Monolithen: Da
.gitlab-ci.ymlund alle Vorlagen und anderen enthaltenen Dateien bei der Ausführung der Pipeline zu einer einzigen großen Datei zusammengefasst werden, sind GitLab-Pipelines monolithisch. Mit Child-Pipelines können Sie diesen Monolithen aufbrechen, wodurch Sie Variablen besser isolieren unddefaultso verwenden können, dass Ihr Code leichter zu verwalten ist. In einem früheren Blog habe ich eine Methode für den Umgang mit Monorepos vorgestellt, aber auch die Grenzen aufgezeigt, die sich ergeben, wenn Sie Ihren gesamten Code in einer einzigen großen Datei zusammenfassen. - In sich geschlossener, wiederverwendbarer Code: Jede untergeordnete Pipeline kann eine eigene, in sich geschlossene Gruppe von Verhaltensweisen darstellen, so dass Sie Änderungen am Code vornehmen können, ohne befürchten zu müssen, dass diese die gesamte Pipeline beschädigen.
- Geringere Komplexität: Wenn Sie mehrere untergeordnete Pipelines erstellen und diese parallel laufen, ist es einfacher, über den Problembereich nachzudenken, wenn das Verhalten jeder Verzweigung in einem eigenen, in sich abgeschlossenen Satz von Dateien enthalten ist, als wenn alles in einer einzigen großen Datei zusammengefasst wäre.
- Isolierung: Wenn eine untergeordnete Pipeline fehlschlägt, schlägt der übergeordnete Auftrag, der sie ausgelöst hat, standardmäßig nicht fehl. Dies kann nützlich sein, wenn Sie z. B. eine Lint-Prüfung durchführen, die zwar fehlschlagen kann, aber nicht den Abschluss des Builds verhindern sollte.
Eine einfache Eltern/Kind-Pipeline
Im Folgenden finden Sie ein vereinfachtes Beispiel.
Den Quellcode finden Sie im Referenz-Repository.
Lassen Sie uns zunächst die untergeordnete Pipeline-Datei child-pipeline.yml definieren:
child-job:
script: echo "I am the child job in the child pipeline"
Dies tut nichts weiter als eine Meldung zu drucken. Als nächstes definieren wir die Datei .gitlab-ci.yml:
parent-trigger-job:
trigger:
include:
- local: child-pipeline.yml
Wenn wir den Code pushen, startet die Pipeline ganz normal und legt dann die untergeordnete Pipeline an.
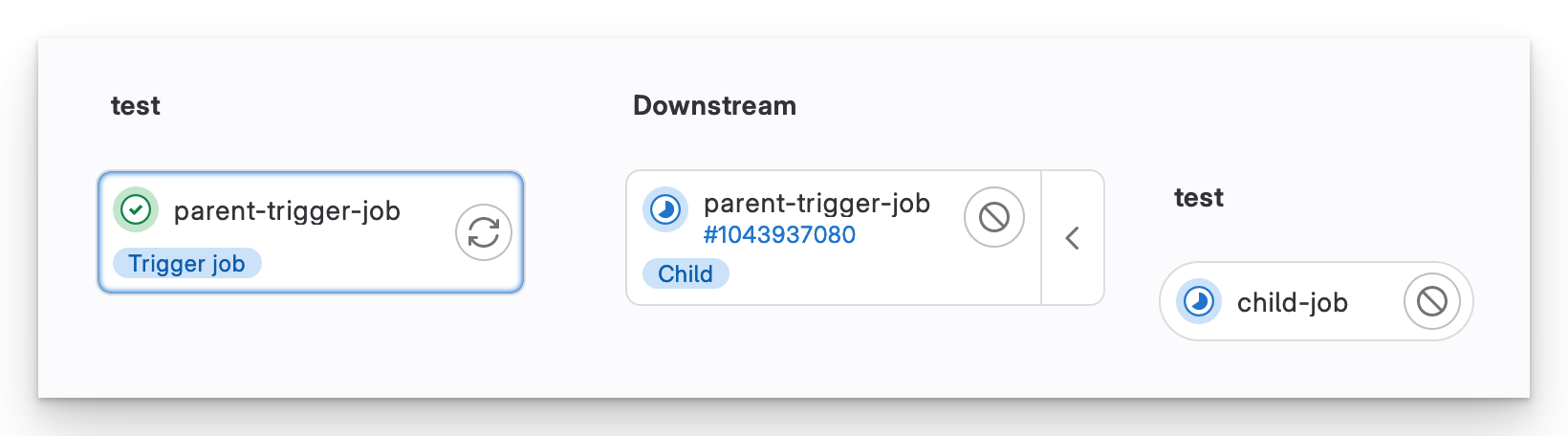
Nachgelagerte Pipeline
Die Schnittstelle für eine übergeordnete/untergeordnete Pipeline sieht anders aus als eine normale Pipeline. Wir sehen, dass es eine nachgelagerte Pipeline und den/die Auftrag/Aufträge gibt, die sie ausführt.
Verschachtelte untergeordnete Pipelines
Es ist nicht nur möglich, dass eine übergeordnete Pipeline untergeordnete Pipelines hervorbringt, sondern diese untergeordneten Pipelines können wiederum ihre eigenen untergeordneten Pipelines hervorbringen. Diese Eltern/Kind/Enkel-Tiefe ist jedoch die Grenze dessen, was GitLab zulässt.
Den Quellcode finden Sie im Referenz-Repository.
Wir verwenden die gleiche .gitlab-ci.yml Datei wie zuvor:
parent-trigger-job:
trigger:
include:
- local: child-pipeline.yml
Jetzt fügen wir einen neuen Auftrag zu child-pipeline.yml hinzu:
child-job:
script: echo "I am the child job in the child pipeline"
# New job to trigger a child pipeline
child-trigger-job:
trigger:
include:
- local: grandchild-pipeline.yml
Dieser neue Job funktioniert genauso wie der parent-trigger-job. Schließlich fügen wir grandchild-pipeline.yml hinzu:
grandchild-job:
script: echo "I am the grandchild job in the grandchild pipeline"
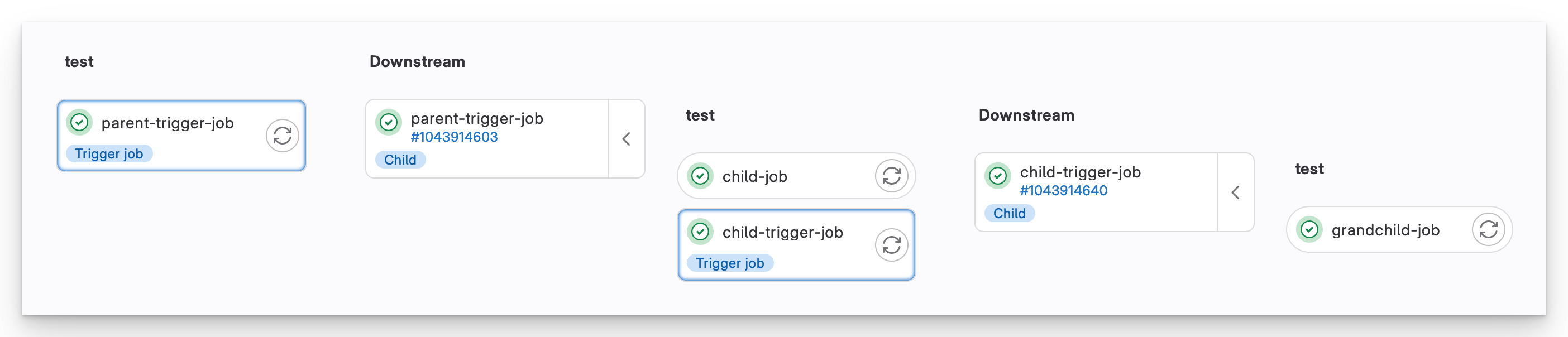
Verschachtelte nachgelagerte Pipelines
Mit dieser Verschachtelung ermöglicht Ihnen GitLab, Ihr Verhalten auf interessante Weise aufzufächern.
Übergabe von Variablen an untergeordnete Pipelines
Auch wenn untergeordnete Pipelines unabhängig von ihren Eltern laufen, ist es möglich, Variablen mit ihnen zu teilen.
Den Quellcode finden Sie im Referenz-Repository.
GUI-Variablen
Lassen Sie uns mit dem einfachsten Beispiel beginnen: GUI-definierte Variablen. Ich definiere eine Variable namens SUPER_SECRET unter Einstellungen > CI/CD > Variablen.
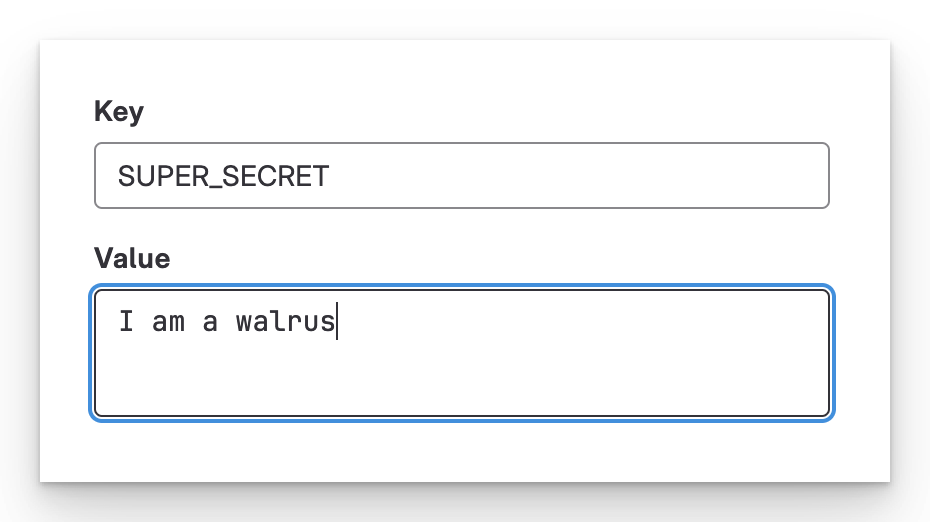
Definieren Sie eine Variable in der GUI
Auch hier beginnen wir mit einer .gitlab-ci.yml Datei:
parent-job:
script:
- echo "The GUI-defined SUPER_SECRET is $SUPER_SECRET"
parent-trigger-job:
trigger:
include:
- local: child-pipeline.yml
Als nächstes kommt child-pipeline.yml:
child-job:
script:
- echo "The GUI-defined SUPER_SECRET is $SUPER_SECRET"
child-trigger-job:
trigger:
include:
- local: grandchild-pipeline.yml
Zum Schluss definieren wir grandchild-pipele.yml:
grandchild-job:
script:
- echo "The GUI-defined SUPER_SECRET is $SUPER_SECRET"
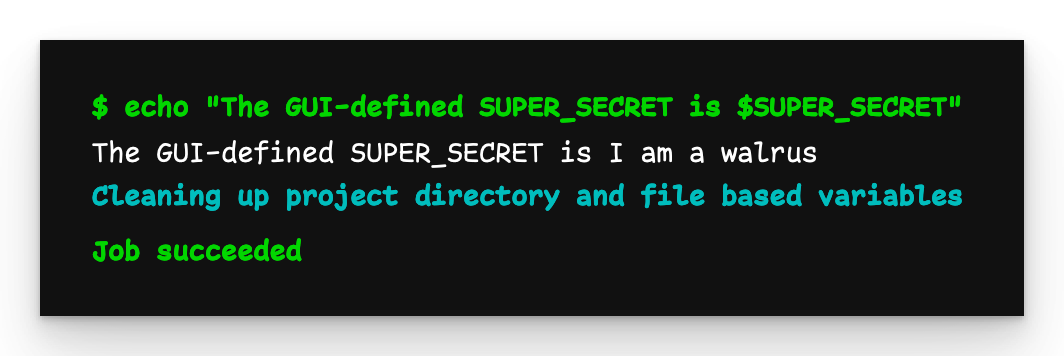
Eltern, Kind, Enkelkind Ausgabe
Die Ausgabe aller drei Pipelines ist die gleiche: I am a walrus. Das liegt daran, dass sie zwar unabhängig voneinander laufen, aber alle im Kontext des Repositorys ausgeführt werden.
YAML-Variablen deklarieren
Bei YAML-definierten Variablen ist die Situation nicht ganz die gleiche.
Lassen Sie uns zwei Variablen zu .gitlab-ci.yml hinzufügen:
VERSION: YAML-globalAPI_KEY: Job-local
variables:
VERSION: 0.1.0 # Global variable
parent-job:
script:
- echo "The GUI-defined SUPER_SECRET is $SUPER_SECRET"
parent-trigger-job:
variables:
API_KEY: api-key-value # Job-local variable
trigger:
include:
- local: child-pipeline.yml
Wir aktualisieren child-pipeline.yml, um diese neuen Variablen wiederzugeben und eine eigene globale Variable zu definieren:
ENVIRONMENT: YAML-global (Kind)
variables:
ENVIRONMENT: test # Child-level global variable
child-job:
script:
- echo "The GUI-defined SUPER_SECRET is $SUPER_SECRET"
- echo "Using API KEY $API_KEY for version $VERSION"
child-trigger-job:
trigger:
include:
- local: grandchild-pipeline.yml
Jetzt aktualisieren wir grandchild-pipeline.yml, um alle Variablen auszugeben:
grandchild-job:
script:
- echo "The GUI-defined SUPER_SECRET is $SUPER_SECRET"
- echo "I am using API KEY $API_KEY for version $VERSION in the $ENVIRONMENT environment"
Die Ausgabe von parent-job bleibt gleich, also sehen wir uns an, was child-job ausgibt:
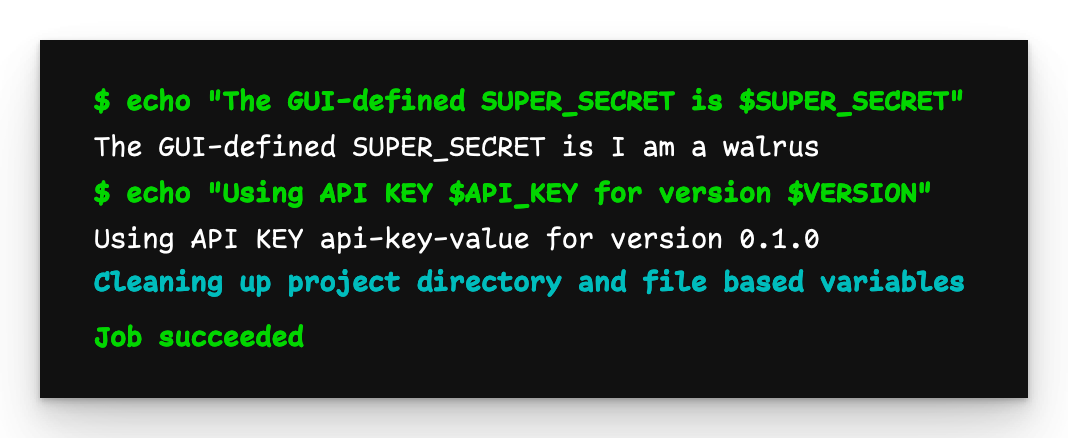
Child-Pipeline-Ausgabe
Die Ausgabe ist so, wie wir sie erwarten: Die Variablen API_KEY und VERSION werden erfolgreich an die Child-Pipeline übergeben.
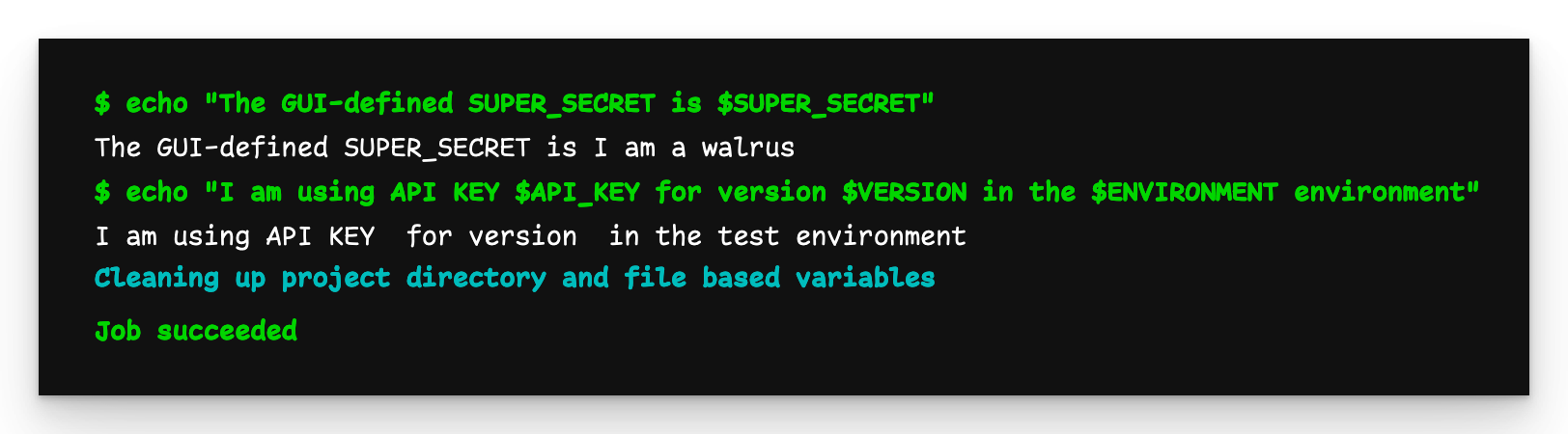
Ausgabe der Pipeline des Enkels
Die Ausgabe der Enkel-Pipeline ist jedoch nicht dieselbe. Wir sehen, dass die in der Child-Pipeline definierte globale Variable ENVIRONMENT an das Enkelkind weitergegeben wird, aber API_KEY und VERSION, wie sie in der Parent-Pipeline definiert sind, nicht. Daraus ist ersichtlich, dass YAML-definierte Variablen nur für ihre unmittelbaren Kinder sichtbar sind.
Wie können wir API_KEY und VERSION für die Enkel-Pipeline verfügbar machen? Wir müssen sie manuell propagieren. Wir aktualisieren child-pipeline.yml und definieren diese Variablen neu:
variables:
ENVIRONMENT: test
API_KEY: $API_KEY # Redefine the API_KEY variable
VERSION: $VERSION # Redefine the VERSION variable
child-job:
script:
- echo "The GUI-defined SUPER_SECRET is $SUPER_SECRET"
- echo "Using API KEY $API_KEY for version $VERSION"
child-trigger-job:
trigger:
include:
- local: grandchild-pipeline.yml
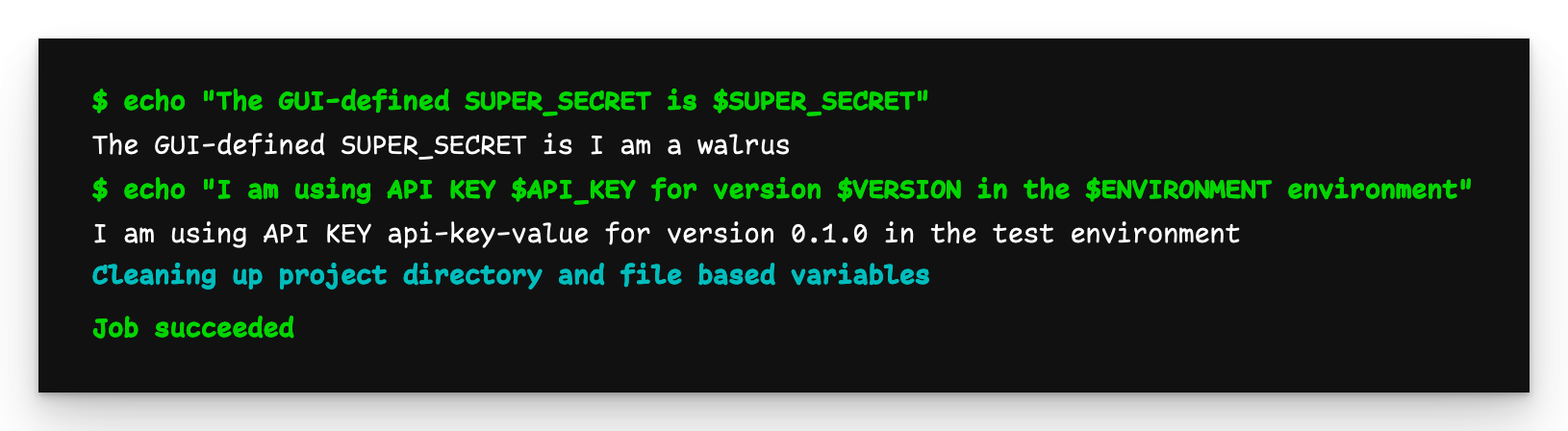
Ausgabe der Enkel-Pipeline (endgültig)
Nun ist die Ausgabe von grandchild-job so, wie wir es erwarten.
Verhindern der Übergabe von globalen Variablen an ein Child
Was, wenn wir keine Variablen an eine Child-Pipeline übergeben wollen?
Den Quellcode finden Sie im Referenz-Repository.
Wir können inherit:variables:false in gitlab-ci.yml verwenden, um zu verhindern, dass globale Variablen an die Child-Pipeline weitergegeben werden:
variables:
VERSION: 0.1.0
parent-trigger-job:
inherit: # Prevent global variables
variables: false # being passed down
trigger:
include:
- local: child-pipeline.yml
Dies verhindert zwar, dass YAML-globale Variablen weitergegeben werden, aber Sie können trotzdem einen variables Abschnitt in Ihren auslösenden Job einfügen und diese werden dann an das Child weitergegeben.
Als nächstes definieren wir child-pipeline.yml:
child-job:
script:
- echo "Using version $VERSION"
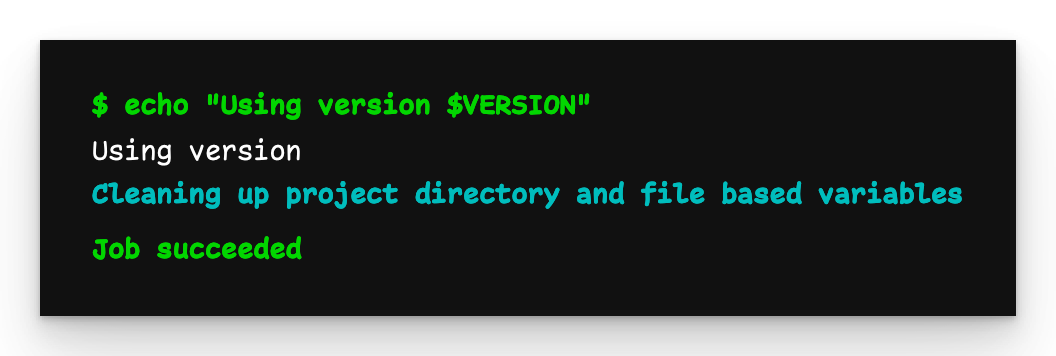
Child-Pipeline-Ausgabe
Wie wir sehen können, wurde die globale Variable VERSION nicht an die Child-Pipeline weitergegeben.
Übergabe von Dateien an untergeordnete Pipelines
Es ist nicht nur möglich, Variablen an untergeordnete Pipelines zu übergeben, sondern auch Dateien.
Den Quellcode finden Sie im Referenz-Repository.
Hier ist eine .gitlab-ci.yml Datei, die eine Datei erstellt und speichert:
create-file-job:
stage: build
script:
- echo "Important stuff" > file.txt # Create the file
artifacts: # Upload
paths: # the file
- file.txt # as an artifact
parent-trigger-job:
stage: test
trigger:
include:
- local: child-pipeline.yml
variables:
PARENT_PIPELINE_ID: $CI_PIPELINE_ID # This variable is important
Als nächstes erstellen wir eine child-pipeline.yml Datei, die die Datei herunterlädt:
child-job:
needs:
- pipeline: $PARENT_PIPELINE_ID # Reference to the parent pipeline
job: create-file-job # The job that creates the file
script: cat file.txt
Sie müssen die Pipeline-ID des Elternteils ($CI_PIPELINE_ID) an das Kind übergeben, damit es den Auftrag identifizieren kann, der die Datei erstellt.
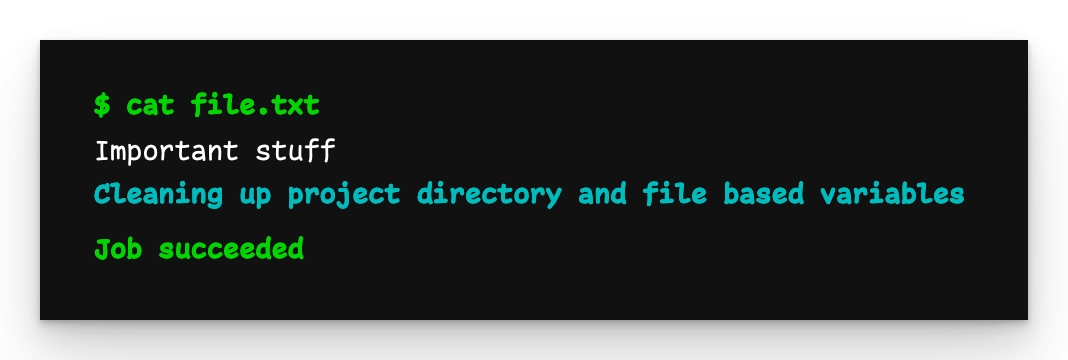
Child-Pipeline-Ausgabe
Hier sehen wir, dass file.txt erfolgreich an die Child-Pipeline übergeben wurde.
Einbindung mehrerer untergeordneter Pipeline-Dateien
Bis jetzt haben wir immer nur eine Child-Pipeline-Datei verwendet, aber es ist möglich, mehrere zu include.
Den Quellcode finden Sie im Referenz-Repository.
Wir beginnen mit .gitlab-ci.yml:
parent-trigger-job:
trigger:
include:
- local: template.yml
- local: child-pipeline-a.yml
- local: child-pipeline-b.yml
Wenn Sie dies tun, werden die beiden (oder mehr) untergeordneten Pipeline-Dateien in einer einzigen Datei zusammengeführt und als eine Pipeline ausgelöst. So können Sie default Elemente definieren, Vorlagen gemeinsam nutzen und sogar Abhängigkeiten mit needs erstellen.
Die Datei template.yml besteht aus:
.my-template:
after_script: echo "I run at the end"
Die Datei child-pipeline-a.ymllautet:
python-job:
extends: [.my-template]
script: echo "I am the Python job"
Die Datei child-pipeline-b.ymllautet:
default:
before_script: echo "I am after_script"
docker-job:
needs: [python-job]
extends: [.my-template]
script: echo "I am the Docker job"
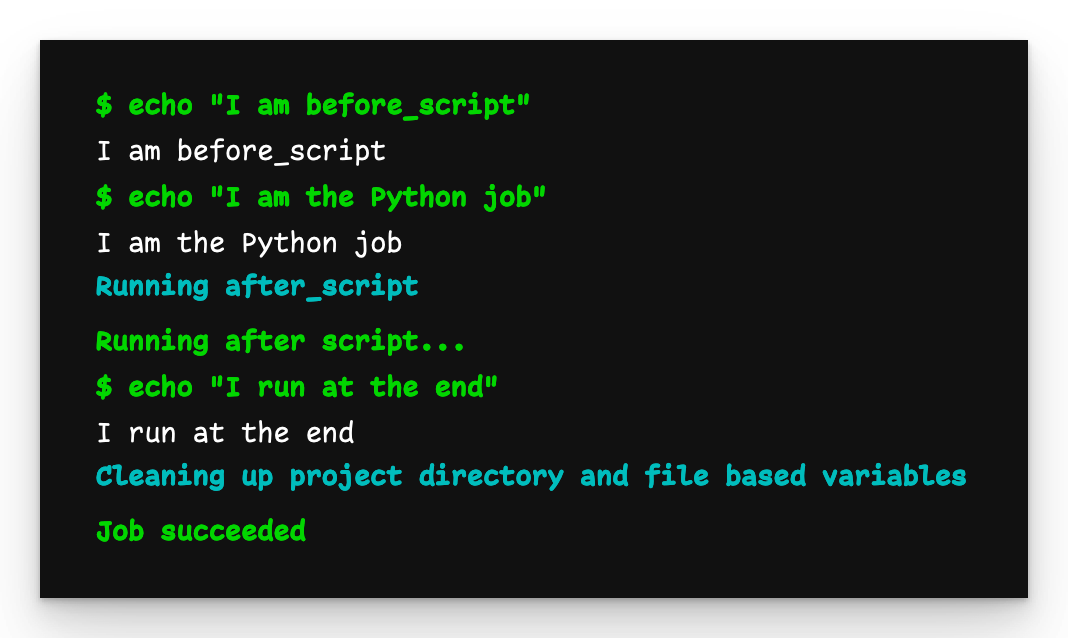
python-job
Die python-job gibt das aus, was wir erwarten. Die in child-pipeline-b.yml definierte Vorgabe before_script wurde angewendet und die Vorlage war zugänglich.
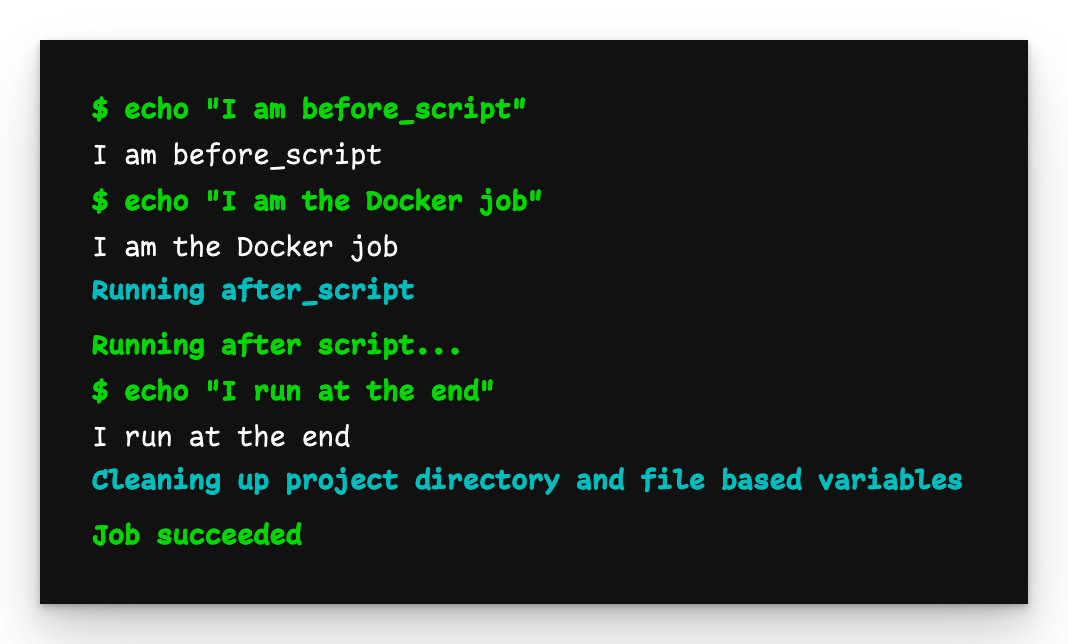
docker-job
Auch docker-job gibt das aus, was wir erwarten, und wartet außerdem darauf, dass python-job beendet wird, bevor es ausgeführt wird.
Einbindung von Dateien aus anderen Repositories
Der gesamte bisher gezeigte Code der Child- und Grandchild-Pipeline stammt aus Dateien desselben Projekts, aber es ist durchaus möglich, Dateien aus anderen Repositories einzubinden.
Sie können den Quellcode im Referenz-Repository und im anderen Repository finden.
Der Code für die Datei child-pipeline.yml aus dem anderen Repository bleibt derselbe:
child-job:
script: echo "I am the child job in the child pipeline"
Die Änderung wird in der Datei .gitlab-ci.yml des übergeordneten Repositorys vorgenommen:
parent-trigger-job:
trigger:
include:
- project: zaayman-samples/using-child-pipelines-in-gitlab-other
file: /child-pipeline.yml
ref: other-repositories
Wir verwenden nicht mehr include:local, sondern geben eine andere project und ref (d.h. den Namen des Zweigs oder den Commit-Hash) und die YAML-Datei der Child-Pipeline an.

Die Ausgabe ist so, wie wir sie erwarten.
Beachten Sie, dass im entfernten Repository keine Pipelines ausgeführt werden. Die untergeordnete Pipelinedatei wurde aus dem entfernten Repository abgerufen und im übergeordneten Repository ausgeführt.
Sicherheitsbedenken
Seien Sie vorsichtig, wenn Sie auf Pipeline-Code aus Repositories verweisen, über die Sie keine Kontrolle haben. Es ist zwar möglich, den entfernten Code zu überprüfen, bevor Sie ihn verwenden, aber nichts hindert einen bösen Akteur daran, später bösartigen Code hinzuzufügen. Da dieser Code im Kontext Ihres Repositorys ausgeführt wird, hat er Zugriff auf GUI-definierte Variablen und sogar Geheimnisse (die mit etwas base64-Kodierung aufgedeckt werden können). Es ist besser, das Repository zu forken, damit Sie den Code vollständig kontrollieren können.
Handhabung von Fehlern
Wenn eine übergeordnete Pipeline eine untergeordnete Pipeline auslöst, wartet sie standardmäßig nicht auf den Abschlussstatus der untergeordneten Pipeline (Erfolg/Fehlschlag), bevor sie ihren eigenen Status bestimmt. Dies hat zwar den Vorteil, dass eine fehlgeschlagene untergeordnete Pipeline keine Auswirkungen auf den Status der übergeordneten Pipeline hat, aber das ist nicht immer das Verhalten, das Sie wünschen.
Beginnen wir damit, das Standardverhalten zu zeigen. Lassen Sie uns .gitlab-ci.yml erstellen:
parent-trigger-job:
trigger:
include:
- local: child-pipeline.yml
Die Datei child-pipeline.yml gibt eine Meldung aus und beendet sich mit einem Wert ungleich Null, um sicherzustellen, dass sie fehlschlägt.
child-job:
script:
- echo "Hello, I am the child job"
- exit 1

Die übergeordnete Pipeline ist erfolgreich, obwohl die untergeordnete Pipeline fehlgeschlagen ist
Beachten Sie, dass die übergeordnete Pipeline bestanden hat, obwohl die untergeordnete Pipeline fehlgeschlagen ist. Das liegt daran, dass die Child-Pipeline standardmäßig unabhängig von der Parent-Pipeline und parallel zu dieser ausgeführt wird. Wenn Sie möchten, dass sich der Status der Child-Pipeline auf die Parent-Pipeline auswirkt, aktualisieren Sie parent-job und verwenden Sie strategy:depend, um sicherzustellen, dass die Parent-Pipeline fehlschlägt, wenn die Child-Pipeline fehlschlägt.
parent-job:
trigger:
include:
- local: child-pipeline.yml
strategy: depend # Use this strategy

Übergeordnete Pipeline schlägt fehl, weil die untergeordnete Pipeline fehlgeschlagen ist
Jetzt schlägt die übergeordnete Pipeline fehl.
Verwendung untergeordneter Pipelines zur Verwaltung von Monorepos
In einem früheren Blog habe ich eine Möglichkeit vorgeschlagen, ein Monorepo zu verwalten. Aufgrund der Art und Weise, wie GitLab alle Dateien zu einer einzigen zusammenfasst und wie seine Regeln funktionieren, werden im Grunde alle Unterverzeichnisse des Monorepo "ausgeführt", aber nur das gewünschte wird fertiggestellt. Das ist für ein kleines Monorepo in Ordnung, kann aber unhandlich werden, wenn es viele Unter-Repositories hat.
Den Quellcode finden Sie im Referenz-Repository.
Indem Sie untergeordnete Pipelines verwenden, vereinfachen Sie den Mechanismus, der die Aktivierung der erforderlichen Pipeline im Unterverzeichnis auslöst.
Wir beginnen mit der Erstellung eines Unterverzeichnisses docker, das ein eigenes Unter-Repository innerhalb der Monorepo sein wird. Innerhalb dieses Verzeichnisses legen wir eine Dockerfile und eine docker-pipeline.yml Datei ab:
default:
image: docker:latest
docker-job:
script: echo "Docker job"
Der Inhalt von Dockerfile spielt keine Rolle, da wir in diesem Beispiel nichts damit machen werden. Sie ist nur da, damit es eine Datei gibt, die im Unter-Repository geändert werden kann, um die Pipeline auszulösen.
Anschließend erstellen wir ein Verzeichnis python mit einer Datei main.py und einer Datei python-pipeline.yml:
default:
image: python:latest
python-job:
script: echo "Python job"
Wie gesagt, der Inhalt von main.py spielt hier keine Rolle.
Zum Schluss erstellen wir die Datei .gitlab-ci.yml:
docker-trigger-job:
rules:
- changes: [docker/**]
trigger:
include:
- local: /docker/docker-pipeline.yml
python-trigger-job:
rules:
- changes: [python/**]
trigger:
include:
- local: /python/python-pipeline.yml
Im vorherigen Blog wurden die Pipeline-Dateien aller Unterverzeichnisse einbezogen, unabhängig davon, in welchem Verzeichnis eine Änderung vorgenommen wurde. Die spezifischen Regeln, die bestimmen, welche Jobs ausgeführt werden, mussten für jeden Job erweitert werden. Jetzt werden die Regeln nur einmal an einer Stelle ausgedrückt, um zu bestimmen, welche Pipeline-Datei ausgelöst werden soll. Außerdem können wir jetzt für jede Pipeline eine andere default verwenden.
Die endgültige Verzeichnisstruktur sieht wie folgt aus:
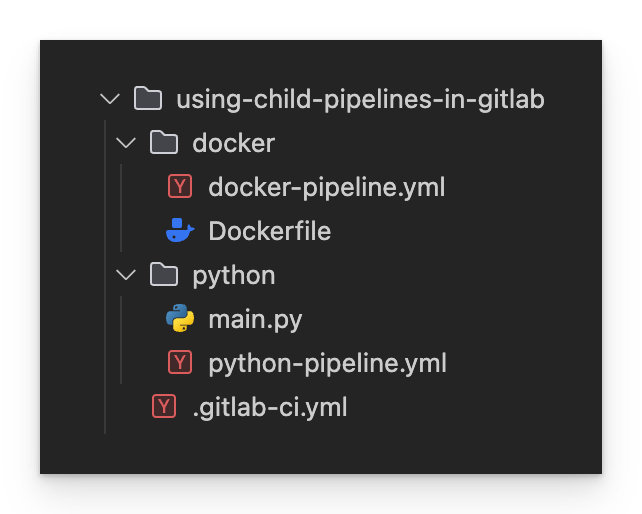
Endgültige Verzeichnisstruktur
Wenn wir eine Änderung auf docker/Dockerfile pushen, wird nur die Docker Child-Pipeline ausgelöst.
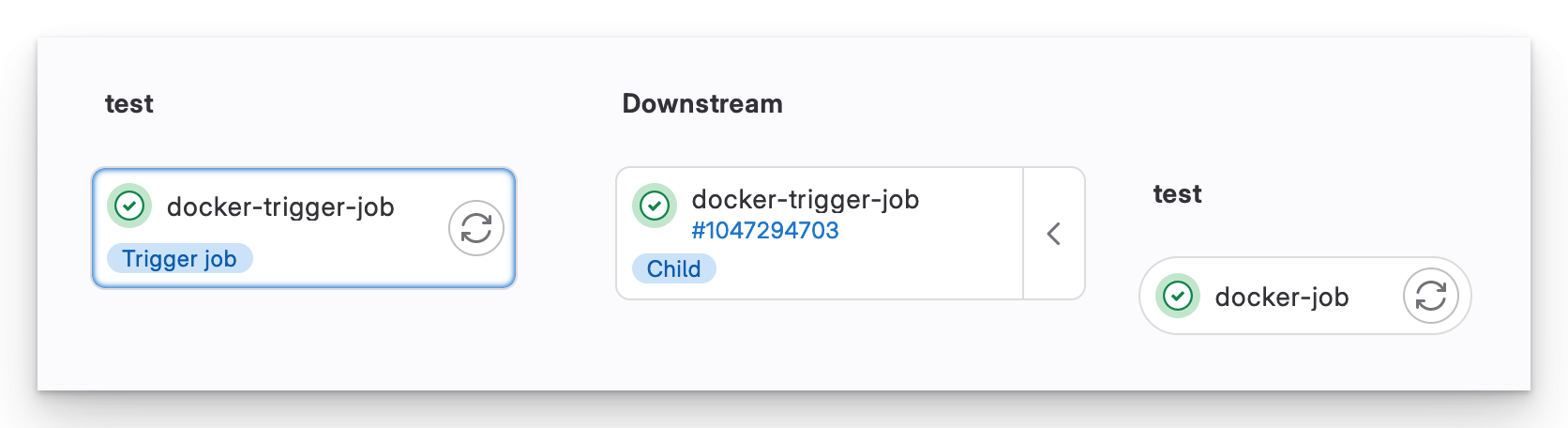
Eine Monorepo Docker Child-Pipeline
Child-Pipelines sind ein viel saubererer Weg, um eine Monorepo zu verwalten. Sie ermöglichen es jedem Team, seine eigene Pipeline anzupassen, ohne Angst haben zu müssen, dass sie andere beeinträchtigt.
Fazit
Wie bei vielen modernen Technologien gibt es auch bei GitLab-Pipelines viele Möglichkeiten, die gleichen Lösungen zu erreichen. Ganz gleich, ob Sie einem Team beitreten, das bereits Child-Pipelines verwendet, oder ob Sie Ihren bestehenden Pipeline-Code in kleinere, wiederverwendbare Einheiten aufteilen möchten.
Verfasst von
Jeffrey Zaayman




Contact