Von Kreditratings bis hin zur Wohnungsvergabe werden Modelle des maschinellen Lernens zunehmend eingesetzt, um "alltägliche" Entscheidungsprozesse zu automatisieren. Mit dem wachsenden Einfluss auf die Gesellschaft werden immer mehr Bedenken über den Verlust von Transparenz, Verantwortlichkeit und Fairness der Algorithmen, die die Entscheidungen treffen, geäußert. Wir als Datenwissenschaftler müssen unser Spiel verstärken und nach Wegen suchen, um aufkommende Diskriminierung in unseren Modellen abzuschwächen. Wir müssen sicherstellen, dass unsere Vorhersagen Menschen mit bestimmten sensiblen Merkmalen (z.B. Geschlecht, ethnische Zugehörigkeit) nicht unverhältnismäßig stark benachteiligen.
Glücklicherweise hat die NIPS-Konferenz im letzten Jahr gezeigt, dass in diesem Bereich aktiv untersucht wird, wie man Fairness in Vorhersagemodelle bringen kann. Die Zahl der zu diesem Thema veröffentlichten Arbeiten steigt rapide an, ein Zeichen dafür, dass Fairness endlich ernst genommen wird. Dieser Punkt wird auch in der folgenden Karikatur deutlich, die dem ausgezeichneten Kurs CS 294 entnommen wurde : Fairness in Machine Learning Kurs an der UC Berkley entnommen wurde.

Einige Ansätze konzentrieren sich auf Interpretierbarkeit und Transparenz, indem sie eine tiefere Abfrage komplexer Blackbox-Modelle ermöglichen. Andere Ansätze machen trainierte Modelle robuster und fairer in ihren Vorhersagen, indem sie das Optimierungsziel einschränken und verändern. Wir werden uns mit dem letztgenannten Ansatz befassen und zeigen, wie kontradiktorische Netzwerke Fairness in unsere Vorhersagemodelle bringen können.
In diesem Blogbeitrag werden wir ein Modell für die Vorhersage des Einkommensniveaus trainieren, die Fairness seiner Vorhersagen analysieren und dann zeigen, wie das adversarische Training genutzt werden kann, um es fair zu machen. Der verwendete Ansatz basiert auf dem 2017 erschienenen NIPS Paper "Learning to Pivot with Adversarial Networks" von Louppe et al.
Beachten Sie, dass der Großteil des Codes weggelassen wurde. Das Jupyter-Notebook mit dem gesamten Code finden Sie hier.
Einkommensprognosen erstellen
Beginnen wir damit, einen einfachen Klassifikator zu trainieren, der vorhersagen kann, ob das Einkommen einer Person mehr als 50.000 Dollar pro Jahr beträgt oder nicht. Um diese Vorhersagen zu treffen, greifen wir auf den UCI-Datensatz für Erwachsene zurück, der auch als "Census Income"-Datensatz bezeichnet wird. Es ist nicht schwer, sich vorzustellen, dass Finanzinstitute Modelle auf ähnlichen Datensätzen trainieren und sie verwenden, um zu entscheiden, ob jemand für einen Kredit in Frage kommt oder nicht, oder um die Höhe einer Versicherungsprämie festzulegen.
Bevor wir ein Modell trainieren, zerlegen wir die Daten zunächst in drei Datensätze: Merkmale, Ziele und sensible Attribute. Der Satz der Merkmale X enthält die Eingabeattribute, die das Modell für die Vorhersagen verwendet, mit Attributen wie Alter, Bildungsgrad und Beruf. Die Ziele yinleft{income>50K, incomeleq 50Kright}. Die Gruppe der sensiblen Attribute z_{race}inleft{black, whiteright} und z_{sex}inleft{male, femaleright}.
Es ist wichtig zu beachten, dass die Datensätze sich nicht überschneiden, so dass die sensiblen Attribute Ethnie und Geschlecht nicht Teil der Merkmale sind, die für das Training des Modells verwendet werden.
# load ICU data set
X, y, Z = load_ICU_data('data/adult.data')
> features X: 30940 samples, 94 attributes
> targets y: 30940 samples
> sensitives Z: 30940 samples, 2 attributesUnser Datensatz enthält die Informationen von etwas mehr als 30.000 Personen. Als nächstes teilen wir die Daten in einen Trainings- und einen Testdatensatz auf, wobei die Aufteilung 50/50 beträgt, und skalieren die Merkmale X mit Hilfe der Standardskalierung.
# split into train/test set
X_train, X_test, y_train, y_test, Z_train, Z_test = train_test_split(X, y, Z, test_size=0.5,
stratify=y, random_state=7)
# standardize the data
scaler = StandardScaler().fit(X_train)
scale_df = lambda df, scaler: pd.DataFrame(scaler.transform(df), columns=df.columns, index=df.index)
X_train = X_train.pipe(scale_df, scaler)
X_test = X_test.pipe(scale_df, scaler)Lassen Sie uns nun unseren Prädiktor für die Höhe des Grundeinkommens trainieren. Wir verwenden Keras, um ein einfaches dreischichtiges Netzwerk mit ReLU-Aktivierungen und Dropout auf die Trainingsdaten anzuwenden. Die Ausgabe des Netzwerks ist ein einzelner Knoten mit sigmoidaler Aktivierung, so dass es "die Wahrscheinlichkeit, dass das Einkommen dieser Person größer als 50K ist" vorhersagt.
def nn_classifier(n_features):
inputs = Input(shape=(n_features,))
dense1 = Dense(32, activation='relu')(inputs)
dropout1 = Dropout(0.2)(dense1)
dense2 = Dense(32, activation='relu')(dropout1)
dropout2 = Dropout(0.2)(dense2)
dense3 = Dense(32, activation="relu")(dropout2)
dropout3 = Dropout(0.2)(dense3)
outputs = Dense(1, activation='sigmoid')(dropout3)
model = Model(inputs=[inputs], outputs=[outputs])
model.compile(loss='binary_crossentropy', optimizer='adam')
return model
# initialise NeuralNet Classifier
clf = nn_classifier(n_features=X_train.shape[1])
# train on train set
history = clf.fit(X_train, y_train, epochs=20, verbose=0)Schließlich verwenden wir diesen Klassifikator, um Vorhersagen zum Einkommensniveau in den Testdaten zu treffen. Wir bestimmen die Leistung des Modells, indem wir die Fläche unter der Kurve und die Trefferquote anhand der Vorhersagen für die Testdaten berechnen.
# predict on test set
y_pred = pd.Series(clf.predict(X_test).ravel(), index=y_test.index)
print(f"ROC AUC: {roc_auc_score(y_test, y_pred):.2f}")
print(f"Accuracy: {100*accuracy_score(y_test, (y_pred>0.5)):.1f}%")
> ROC AUC: 0.91
> Accuracy: 85.1%Mit einem ROC AUC von mehr als 0,9 und einer Vorhersagegenauigkeit von 85% können wir sagen, dass unser Basisklassifikator ziemlich gut abschneidet! Ob er allerdings auch faire Vorhersagen macht, bleibt abzuwarten.
Qualitatives Modell Fairness
Wir beginnen die Untersuchung der Fairness unseres Klassifizierers mit einer Analyse der Vorhersagen, die er für die Testmenge gemacht hat. Die Diagramme in der Abbildung unten zeigen die Verteilungen der vorhergesagten P(income>50K) angesichts der sensiblen Attribute.
fig = plot_distributions(y_pred, Z_test, fname='/wp-content/images/biased_training.png')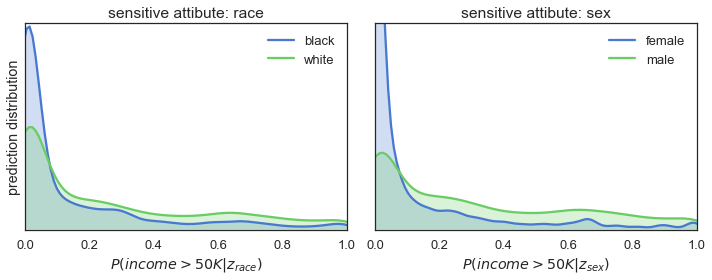
Die Abbildung zeigt, dass sowohl für Ethnie (= linkes Diagramm) als auch für Geschlecht (= rechtes Diagramm) die blauen Vorhersageverteilungen eine große Spitze am unteren Ende des Wahrscheinlichkeitsbereichs aufweisen. Das bedeutet, dass die Wahrscheinlichkeit, dass der Klassifikator ein Einkommen unter 50.000 vorhersagt, wenn eine Person black und/oder female ist, viel höher ist als wenn jemand white und/oder male ist.
Die Ergebnisse der qualitativen Analyse sind also ziemlich eindeutig: Die Vorhersagen sind definitiv nicht fair, wenn man sie im Kontext von Ethnie und Geschlecht betrachtet. Wenn es um die Zuweisung der hohen Einkommensstufen geht, begünstigt unser Modell die üblichen Verdächtigen: weiße Männer.
Quantitative Modellgerechtigkeit
Um ein 'quantitatives' Maß dafür zu erhalten, wie fair unser Klassifikator ist, lassen wir uns von der U.S. Equal Employment Opportunity Commission (EEOC) inspirieren. Sie verwendet die sogenannte 80%-Regel, um die ungleichen Auswirkungen eines geschützten Merkmals auf eine Gruppe von Menschen zu quantifizieren. Zafar et al. zeigen in ihrem Papier "Fairness Constraints: Mechanisms for Fair Classification", wie eine allgemeinere Version dieser Regel, die so genannte p%-Regel, zur Quantifizierung der Fairness eines Klassifizierers verwendet werden kann. Diese Regel ist wie folgt definiert:
Ein Klassifikator, der eine binäre Klassenvorhersage hat{y} in left{0,1 right} für ein binäres sensitives Attribut zin left{0,1 right} macht, erfüllt die p%-Regel
, wenn die folgende Ungleichung gilt:
minleft(frac{P(hat{y}=1|z=1)}{P(hat{y}=1|z=0)}, frac{P(hat{y}=1|z=0)}{P(hat{y}=1|z=1)}right)geqfrac{p}{100}Die Regel besagt, dass das Verhältnis zwischen der Wahrscheinlichkeit eines positiven Ergebnisses, wenn das sensible Attribut wahr ist, und der gleichen Wahrscheinlichkeit, wenn das sensible Attribut falsch ist, nicht kleiner als p:100 ist. Wenn ein Klassifikator also vollkommen fair ist, erfüllt er die 100%-Regel. Wenn er dagegen völlig unfair ist, erfüllt er die %0-Regel.
Bei der Bestimmung der Fairness unseres Klassifizierers werden wir der EEOC folgen und sagen, dass ein Modell fair ist, wenn es mindestens eine 80%-Regel erfüllt. Lassen Sie uns also die p%-Regeln für den Klassifikator berechnen und eine Zahl für seine Fairness festlegen. Beachten Sie, dass wir den Schwellenwert für unseren Klassifikator bei 0,5 ansetzen, damit seine Vorhersage binär ist.
print("The classifier satisfies the following %p-rules:")
print(f"tgiven attribute race; {p_rule(y_pred, Z_test['race']):.0f}%-rule")
print(f"tgiven attribute sex; {p_rule(y_pred, Z_test['sex']):.0f}%-rule")
> The classifier satisfies the following %p-rules:
> given attribute race; 45%-rule
> given attribute sex; 32%-ruleWir stellen fest, dass der Klassifikator für beide empfindlichen Attribute eine p%-Regel erfüllt, die deutlich unter 80% liegt. Dies unterstützt unsere frühere Schlussfolgerung, dass der trainierte Klassifikator bei seinen Vorhersagen unfair ist.
Kampf gegen die Voreingenommenheit
Es ist wichtig zu betonen, dass das Training eines fairen Modells nicht einfach ist. Man könnte versucht sein, zu glauben, dass es ausreicht, sensible Informationen aus den Trainingsdaten zu entfernen. Unser Klassifikator hatte keinen Zugriff auf die Attribute Ethnie und Geschlecht und trotzdem haben wir ein Modell erstellt, das Frauen und Schwarze benachteiligt. Das wirft die Frage auf: Was hat unser Klassifizierer zu diesem Verhalten veranlasst?
Das beobachtete Verhalten ist höchstwahrscheinlich auf Verzerrungen in den Trainingsdaten zurückzuführen. Um zu verstehen, wie das funktioniert, betrachten Sie die folgenden zwei Beispiele für Bildklassifizierungsfehler:

Der Klassifikator, der diese Fehler machte, wurde auf Daten trainiert, in denen einige ethnische und rassische Minderheiten durch eine kleine Anzahl von Klassen überrepräsentiert sind. Zum Beispiel werden Schwarze oft beim Basketball und Asiaten beim Tischtennis gezeigt. Das Modell greift diese Verzerrungen auf und nutzt sie für seine Vorhersagen. Sobald es jedoch in die freie Wildbahn entlassen wird, wird es auf Bilder stoßen, in denen diese Minderheiten etwas anderes tun als Basketball oder Tischtennis zu spielen. Da es sich immer noch auf seine gelernten Vorurteile verlässt, kann das Modell diese Bilder auf ziemlich schmerzhafte Weise falsch klassifizieren.
Der UCI-Datensatz, der für das Training unseres Klassifizierers verwendet wurde, weist ähnliche Verzerrungen in den Daten auf. Der Datensatz basiert auf Volkszählungsdaten aus dem Jahr 1994, einer Zeit, in der die Einkommensungleichheit ein ebenso großes Problem war wie heute. Es überrascht nicht, dass die meisten Gutverdiener in den Daten weiße Männer sind, während Frauen und Schwarze häufiger zur Gruppe der Geringverdiener gehören. Unser Vorhersagemodell kann diese Verzerrungen indirekt erlernen, zum Beispiel durch Merkmale wie Bildungsniveau und Postleitzahl des Wohnorts. Infolgedessen erhalten wir die im vorigen Abschnitt beobachteten unfairen Vorhersagen, auch wenn wir die Merkmale Ethnie und Geschlecht entfernt haben.
Wie können wir dieses Problem beheben? Im Allgemeinen gibt es zwei Ansätze, die wir verfolgen können. Wir können versuchen, die Verzerrung des Datensatzes zu beseitigen, indem wir zum Beispiel zusätzliche Daten hinzufügen, die aus einer repräsentativeren Stichprobe stammen. Alternativ können wir das Modell so einschränken, dass es gezwungen ist, gerechtere Vorhersagen zu treffen. Im nächsten Abschnitt werden wir zeigen, wie kontradiktorische Netzwerke beim zweiten Ansatz helfen können.
Adversarische Netzwerke FTW
Im Jahr 2014 veröffentlichten Goodfellow et al. ihre bahnbrechende Arbeit über Generative Adversarial Networks (GANs). Sie stellen GANs als ein System aus zwei neuronalen Netzen vor, einem generativen Modell und einem kontradiktorischen Klassifikator, die in einem Nullsummenspiel gegeneinander antreten. In diesem Spiel konzentriert sich das generative Modell darauf, Muster zu erzeugen, die von echten Daten nicht zu unterscheiden sind, während der adversarische Klassifikator versucht, zu erkennen, ob die Muster vom generativen Modell oder von den echten Daten stammen. Beide Netzwerke werden gleichzeitig trainiert, so dass das erste besser in der Lage ist, realistische Muster zu erzeugen, während das zweite besser darin wird, die Fälschungen von den echten zu unterscheiden. Die Abbildung unten zeigt einige Beispiele von Bildern, die von einem GAN erzeugt wurden:

Unser Verfahren zum Trainieren eines fairen Einkommensklassifizierers ist von GANs inspiriert: Es nutzt adversarische Netzwerke, um die so genannte Pivotal-Eigenschaft des Vorhersagemodells zu erzwingen. Diese statistische Eigenschaft stellt sicher, dass die Ergebnisverteilung des Modells nicht mehr von sogenannten Störparametern abhängt. Diese Parameter sind nicht von unmittelbarem Interesse, müssen aber in einer statistischen Analyse berücksichtigt werden. Indem wir die sensiblen Attribute als Nuisance-Parameter verwenden, können wir Vorhersagen erzwingen, die unabhängig von Ethnie und Geschlecht (in unserem Fall) sind. Das ist genau das, was wir brauchen, um faire Vorhersagen zu machen!
Verfahren der kontradiktorischen Ausbildung
Der Ausgangspunkt für das gegnerische Training unseres Klassifikators ist die Erweiterung der ursprünglichen Netzwerkarchitektur um eine gegnerische Komponente. Die Abbildung unten zeigt, wie diese erweiterte Architektur aussieht:
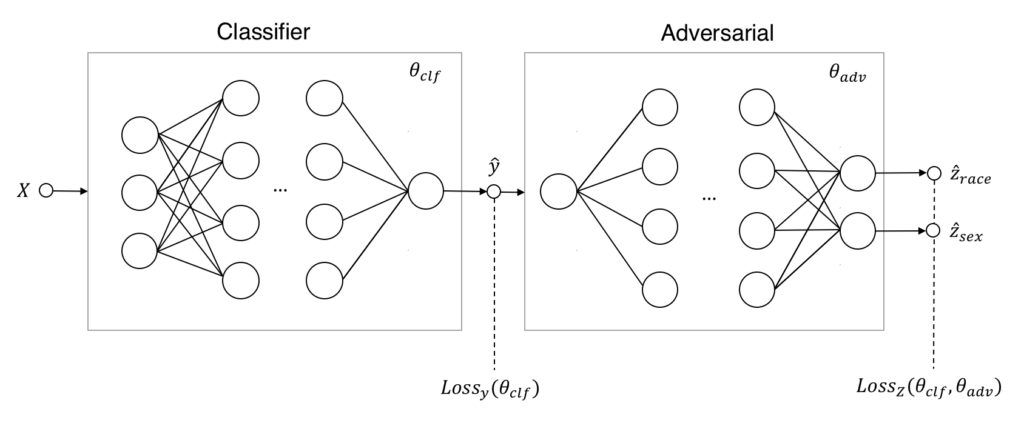
Auf den ersten Blick sieht dieses System aus zwei neuronalen Netzen dem System, das zum Training von GANs verwendet wird, sehr ähnlich. Es gibt jedoch einige wichtige Unterschiede. Erstens wurde das generative Modell durch ein prädiktives Modell ersetzt. Anstatt also synthetische Daten zu generieren, erzeugt es nun tatsächliche Vorhersagen hat{y} auf der Grundlage der Eingabe X. Zweitens besteht die Aufgabe des gegnerischen Modells nicht mehr darin, echte von generierten Daten zu unterscheiden. Stattdessen sagt er die sensiblen Attributwerte Loss{y}(theta{clf}) und Loss{Z}(theta{clf},theta_{adv}) bezeichnet werden.
Betrachten wir die Natur des Nullsummenspiels, an dem der Klassifizierer und der Gegner beteiligt sind. Der Klassifikator verfolgt ein zweifaches Ziel: die bestmögliche Vorhersage des Einkommensniveaus zu treffen und gleichzeitig sicherzustellen, dass Ethnie oder Geschlecht nicht daraus abgeleitet werden können. Dies wird durch die folgende Zielfunktion erfasst:
min_{theta_{clf}}left[Loss_{y}(theta_{clf})-lambda Loss_{Z}(theta_{clf},theta_{adv})right].Er lernt also, seine eigenen Prognoseverluste zu minimieren und gleichzeitig die des Gegners zu maximieren (da lambda positiv ist und die Minimierung eines negierten Verlusts dasselbe ist wie dessen Maximierung). Beachten Sie, dass die Erhöhung der Größe von lambda den Klassifikator zu faireren Vorhersagen führt, während die Vorhersagegenauigkeit darunter leidet. Das Ziel während des Spiels ist einfacher Für den Gegner: Vorhersage von Ethnie und Geschlecht auf der Grundlage der Vorhersagen des Klassifikators zum Einkommensniveau. Dies wird in der folgenden Zielfunktion festgehalten:
min_{theta_{adv}}left[Loss_{Z}(theta_{clf},theta_{adv})right].Der Gegner kümmert sich nicht um die Vorhersagegenauigkeit des Klassifizierers. Ihm geht es nur darum, seine eigenen Verluste bei der Vorhersage zu minimieren.
Da unser Klassifikator nun um eine gegnerische Komponente erweitert wurde, wenden wir uns dem gegnerischen Trainingsverfahren zu. Kurz gesagt, können wir dieses Verfahren in den folgenden 3 Schritten zusammenfassen:
- Trainieren Sie den Klassifikator mit dem vollständigen Datensatz.
- Trainieren Sie den gegnerischen Klassifikator anhand der Vorhersagen des trainierten Klassifikators.
- Während der
TIterationen trainieren Sie gleichzeitig das gegnerische Netzwerk und das Klassifizierungsnetzwerk:- trainieren Sie zunächst den Adversarial für eine einzige Epoche, während Sie den Klassifikator festhalten
- Dann trainieren Sie den Klassifikator auf einem einzigen Mini-Batch, während Sie die gegnerische Variable festhalten.
Das eigentliche kontradiktorische Training beginnt erst nach den ersten beiden Vor-Trainingsschritten. Zu diesem Zeitpunkt ahmt das Trainingsverfahren das Nullsummenspiel nach, bei dem unser Klassifikator (hoffentlich) lernt, wie er Vorhersagen trifft, die sowohl genau als auch fair sind.
Faire Einkommensprognosen
Schließlich sind wir bereit, einen fairen Klassifikator adverserial zu trainieren. Wir beginnen mit der Initialisierung unseres neuen Klassifizierers und trainieren sowohl den Klassifizierer als auch die gegnerischen Netzwerke:
# initialise FairClassifier
clf = FairClassifier(n_features=X_train.shape[1], n_sensitive=Z_train.shape[1],
lambdas=[130., 30.])
# pre-train both adverserial and classifier networks
clf.pretrain(X_train, y_train, Z_train, verbose=0, epochs=5)Die mitgelieferten lambda Werte, die Fairness und Genauigkeit aufeinander abstimmen, sind auf lambda_{race}=130 und lambda_{sex}=30 eingestellt. Wir haben heuristisch festgestellt, dass diese Einstellungen zu einem ausgewogenen Anstieg der p%-Regelwerte während des Trainings führen. Offenbar ist es etwas schwieriger, Fairness für die Rassenattribute durchzusetzen als für das Geschlecht.
Nun, da beide Netzwerke vortrainiert wurden, kann das gegnerische Training beginnen. Wir werden beide Netzwerke gleichzeitig für 165 Iterationen trainieren, während wir die Leistung des Klassifizierers auf den Testdaten verfolgen:
# adverserial train on train set and validate on test set
clf.fit(X_train, y_train, Z_train,
validation_data=(X_test, y_test, Z_test),
T_iter=165, save_figs=True)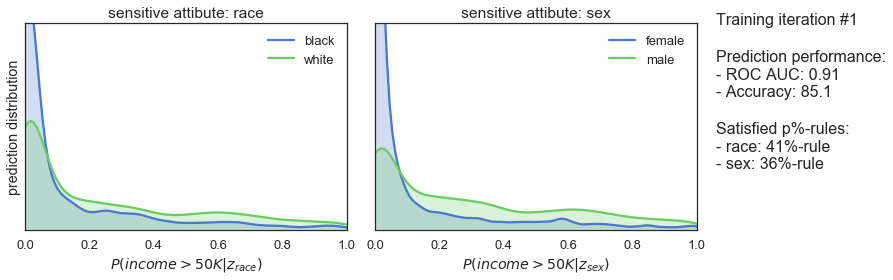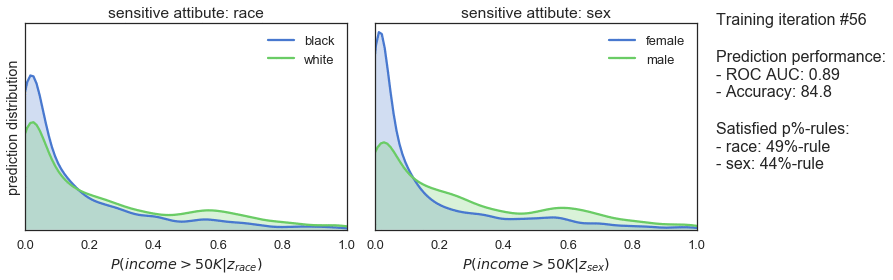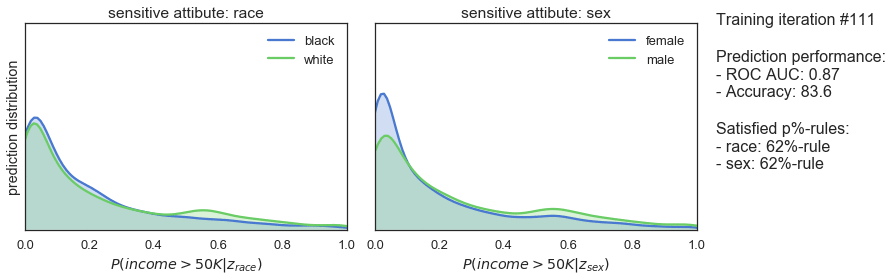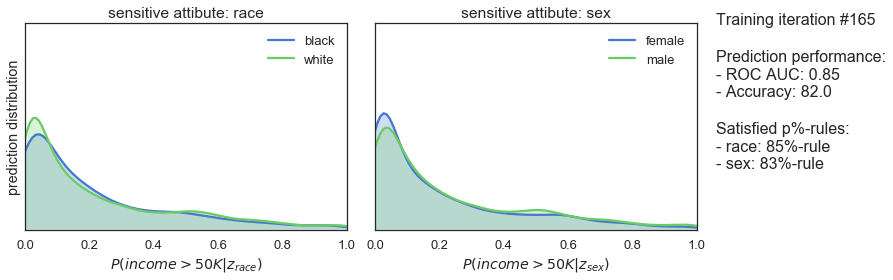
Die obigen Diagramme zeigen, wie sich die Vorhersageverteilungen, die erfüllten p%-Regeln und die Vorhersageleistung unseres Klassifikators während des gegnerischen Trainings entwickeln. In Iteration 1, wenn das Training gerade erst beginnt, sind die Vorhersagen sehr ähnlich wie bei dem zuvor trainierten Klassifikator: sowohl in Bezug auf die Verzerrung als auch auf die Vorhersageleistung hoch. Mit fortschreitendem Training sehen wir, dass die Vorhersagen allmählich immer gerechter werden, während die Vorhersageleistung leicht abnimmt. Schließlich, nach 165 Trainingsiterationen, sehen wir, dass der Klassifikator die 80%-Regel für beide sensitiven Attribute erfüllt und einen ROC AUC von 0,85 und eine Genauigkeit von 82% erreicht.
Es scheint also, dass das Trainingsverfahren recht gut funktioniert. Nachdem wir nur 7 % der Vorhersageleistung geopfert haben, erhalten wir einen Klassifikator, der faire Vorhersagen in Bezug auf Ethnie und Geschlecht macht. Ein ziemlich anständiges Ergebnis!
Fazit
In diesem Blogbeitrag haben wir gezeigt, dass es nicht so einfach ist, Vorhersagemodelle fair zu gestalten, indem man "einfach" einige sensible Attribute aus den Trainingsdaten entfernt. Es erfordert clevere Techniken, wie z.B. adverses Training, um die oft stark verzerrten Trainingsdaten zu korrigieren und unsere Modelle zu fairen Vorhersagen zu zwingen. Und ja, faire Vorhersagen haben ihren Preis: Sie verringern die Leistung Ihres Modells (hoffentlich nur ein wenig, wie es in unserem Beispiel der Fall war). In vielen Fällen ist dies jedoch ein relativ geringer Preis dafür, dass wir die verzerrte Welt von gestern hinter uns lassen und den Weg in eine gerechtere Zukunft vorhersagen!
Vielen Dank an Henk, der so freundlich war, diese Arbeit zu begutachten und seine Kommentare abzugeben!
Verbessern Sie Ihre Python-Kenntnisse, lernen Sie von den Experten!
Bei GoDataDriven bieten wir eine Vielzahl von Python-Kursen an, die von den besten Experten auf diesem Gebiet unterrichtet werden. Kommen Sie zu uns und verbessern Sie Ihr Python-Spiel:
- Data Science with Python Foundation - Möchten Sie den Schritt von der Datenanalyse und -visualisierung zu echter Datenwissenschaft machen? Dies ist der richtige Kurs.
- Advanced Data Science with Python - Lernen Sie, Ihre Modelle wie ein Profi zu produzieren und Python für maschinelles Lernen zu verwenden.
Verfasst von
Stijn Tonk




Contact