Blog
Mit ausführbaren Spezifikationen der Konkurrenz immer einen Schritt voraus

Jedes Unternehmen möchte sich schnell anpassen, sei es aufgrund neuer oder geänderter Geschäftsideen oder aufgrund von Veränderungen auf dem Markt. Nur wenn man sich schnell anpasst, kann man der Konkurrenz voraus sein. Für ein Unternehmen, das sich wie Picnic stark auf selbst entwickelte Software verlässt, bedeutet dies, dass sich die Software schnell ändern muss. Und genau hier wird es schwierig.
In diesem Beitrag erläutere ich, wie schnelles Feedback im Softwareentwicklungsprozess erforderlich ist, um Softwareänderungen zu beschleunigen, und wie ausführbare Spezifikationen diese Feedbackschleife reduzieren können. Ich beschreibe, wie wir diese Methodik bei Picnic anwenden und welche Vorteile wir daraus ziehen.
Langsames Feedback bedeutet langsame Softwareänderungen
Viele Faktoren können Softwareänderungen verlangsamen, wie z.B. ein Team, dem es an Autonomie mangelt, oder veralteter Code, aber hier möchte ich mich auf langsames Feedback konzentrieren. Nehmen wir an, das Folgende ist eine grobe Zusammenfassung eines durchschnittlichen Softwareentwicklungsprozesses:
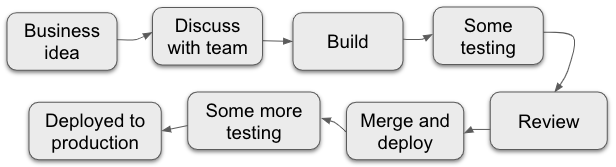
- Das Unternehmen, der Produktverantwortliche oder das Team selbst hat eine Geschäftsidee, für die eine Softwareänderung erforderlich ist.
- Das Team und der Produktverantwortliche besprechen, wie es gebaut werden soll und wie komplex es ist.
- Jemand aus dem Team (oder besser zwei: Pair Programming!) erstellt es, und natürlich auch einige gute Unit-Tests dazu.
- Es werden einige manuelle Tests durchgeführt, um zu überprüfen, ob die Änderung wie erwartet funktioniert.
- Jemand überprüft die Änderung, um zu sehen, ob die Änderung wie erwartet aussieht/funktioniert.
- Die Änderung wird zusammengeführt (oder auch nicht, wenn Sie trunk-basiert entwickeln!), es werden eventuell weitere Tests durchgeführt, und irgendwann wird die Änderung in die Produktion übernommen.
Im Softwareentwicklungsprozess ist langsames Feedback ein mehrköpfiges Monster, denn bei jedem der oben genannten Schritte können Sie Feedback erhalten.
Ein paar Beispiele:
- Während Sie die Idee und die Softwareänderung mit dem Team besprechen, stellt sich heraus, dass die Änderung nicht den geschäftlichen Anforderungen entspricht. Oder die Änderung ist gar nicht machbar.
- Manuelle Tests sind zeitaufwändig, so dass Sie nicht alles testen können. Dadurch entstehen Fehler in der Änderung, an der Sie gerade arbeiten, oder in Änderungen, die Sie zuvor vorgenommen haben (Regressionen). Die Behebung dieser Fehler kann kostspielig und zeitaufwändig sein, vor allem, wenn Sie sie erst nach der Bereitstellung der Änderung finden (bedenken Sie, welchen Schaden ein Fehler anrichten kann!).
- Ein Code-Review kann Probleme aufdecken, aber dieses Feedback kommt oft zu spät, um vergeudeten Aufwand und Nacharbeit zu vermeiden.
- Ein Missverständnis zwischen dem Product Owner und dem Team könnte dazu führen, dass das Falsche gebaut wird, was vielleicht erst nach der Bereitstellung entdeckt wird.
Je später Sie Feedback erhalten, desto mehr Zeit haben Sie mit einer Änderung verschwendet, die nicht erwünscht ist. Um dieses Problem zu lösen, brauchen wir schnelles Feedback, damit wir schnell scheitern und keine Zeit verschwenden. Das wiederum beschleunigt den Entwicklungsprozess!
Ausführbare Spezifikationen zur Reduzierung der Rückkopplungsschleife
Nachdem ich eine Zeit lang die Auswirkungen von langsamem Feedback bei Picnic beobachtet hatte, fand ich verschiedene Möglichkeiten, die Feedback-Schleife zu reduzieren und Softwareänderungen zu beschleunigen. Eine dieser Möglichkeiten besteht darin, ein gemeinsames Verständnis zwischen einem Product Owner und einem Team von Software-Ingenieuren darüber zu schaffen, was gebaut werden muss, und zwar mit einer Technik namens Example Mapping. Dabei handelt es sich um eine Methode zur gemeinsamen Erarbeitung von Beispielen dafür, wie sich das System verhalten soll. Diese Beispiele können dann in ausführbare Spezifikationen umgewandelt werden, auf die ich mich in diesem Beitrag konzentrieren werde.
Ausführbare Spezifikationen geben Ihnen das schnelle Feedback, das Sie brauchen, um keine Zeit mit der Entwicklung von Software zu verschwenden, die Sie nicht brauchen oder die nicht funktioniert.
Warum also ausführbar?
Diese Spezifikationen werden als ausführbar bezeichnet, weil sie als automatisierte Tests ausgeführt werden können. Das bedeutet, dass Sie einerseits eine von Menschen lesbare Spezifikation dessen haben, was das System - oder eine bestimmte Änderung innerhalb des Systems - tun soll. Auch Personen, die mit der Domäne vertraut sind, aber kein spezifisches technisches Fachwissen besitzen, können diese Spezifikationen verstehen. Andererseits haben Sie eine Reihe von automatisierten Tests, die ein Softwareentwickler durchführen kann, um zu überprüfen, ob alles wie erwartet funktioniert. Es ist eine lebendige Dokumentation. Wenn sich die Dokumentation ändert, ändern sich auch Ihre Tests.
Da es sich um automatisierte Tests handelt, werden manuelle Tests und die damit verbundene Zeitverschwendung drastisch reduziert. Und damit auch Regressionen, die sich einschleichen, weil Sie vergessen haben, eine Funktion zu testen, die vor einem Jahr entwickelt wurde. Beachten Sie, dass ich nicht gegen manuelle Tests bin - explorative Tests sind immer noch nützlich für Dinge, die schwer zu automatisieren sind oder nicht oft getestet werden müssen. Es sind die langweiligen, sich wiederholenden und zeitaufwändigen manuellen Tests, die automatisiert werden sollten.
Im Grunde wollen wir das Richtige bauen, es richtig bauen und automatisch überprüfen, ob dies der Fall ist.
Ein Werkzeug für ausführbare Spezifikationen
Die oben beschriebene Theorie mag ja ganz nett sein, aber wie funktioniert das in der Praxis?
Es gibt verschiedene Tools zur Erstellung ausführbarer Spezifikationen, eines davon ist Cucumber. Eine Spezifikation in Cucumber sieht wie folgt aus:

Gherkin ist die Sprache, in der Sie Ihre Spezifikationen niederschreiben, so dass Cucumber jede Zeile (einen sogenannten Schritt) als automatisierten Test ausführen kann. Sie haben eine Reihe so genannter Funktionsdateien, die jeweils eine klare Beschreibung der Funktion und mehrere Szenarien wie das obige enthalten, in denen Beispiele beschrieben werden, die das Verhalten der Funktion beschreiben.
Sie sind vielleicht mit der given-when-then-Struktur vertraut. Der
Obwohl man mehrere Blogbeiträge darüber schreiben könnte, wie man Szenarien schreibt und was in ihnen enthalten sein sollte und was nicht, ist es wichtig, dass jeder im Team (einschließlich des Product Owners!) versteht, was sie bedeuten. Nur dann können Sie Missverständnisse darüber vermeiden, wie das beabsichtigte Verhalten aussehen sollte.
Technische Einrichtung
Ich beschreibe Ihnen die technischen Einzelheiten, wie Sie diese Spezifikation als automatisierten Test ausführen können, und beschreibe den technischen Aufbau.
Bei Picnic verwenden die meisten Teams Java. Daher haben wir uns entschieden, Behave als unsere Cucumber-Implementierung zu verwenden und die Tests, die von den Feature-Dateien ausgeführt werden, in Python zu implementieren. Ich weiß, das klingt seltsam, aber es war eine bewusste Entscheidung. Indem wir unterschiedliche Sprachen für Tests und Produktionscode verwenden, erzwingen wir eine Trennung zwischen Tests und Produktionscode und verhindern, dass der Test auf Implementierungsdetails angewiesen ist. Schließlich wollen wir das von außen beobachtete Verhalten unseres Systems testen, nicht das Innenleben! Selbst wenn Sie die gleiche Sprache verwenden würden (einige Teams bei Picnic verwenden Python), würde ich Ihnen dennoch dringend raten, diese Trennung beizubehalten. Was Sie testen wollen, sind die äußeren APIs Ihres Systems, egal ob es sich um eine Messaging-Schnittstelle, REST oder SOAP handelt.
Apropos "das System", welchen Umfang hat es?
Bei Picnic setzt jedes Team einen oder mehrere Docker-Container in einer Kubernetes-Umgebung ein, so dass es am einfachsten war, jeden Container zum Testobjekt zu machen. Es ist jedoch wahrscheinlich, dass Sie einen Container nicht alleine ausführen und testen können, da er Abhängigkeiten zu Datenbanken, Message Brokern und anderen externen Diensten hat, die über REST oder SOAP kommunizieren. Im Folgenden finden Sie einen Überblick darüber, wie wir einen Container isoliert testen konnten:
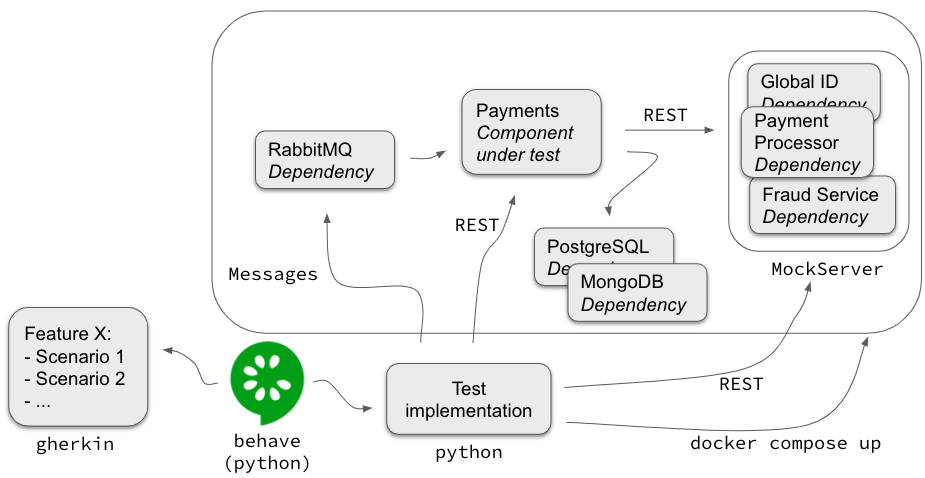
Dies ist die Einrichtung für das Testen des Containers Payments. Die Abhängigkeiten von Payments werden ebenfalls in Containern ausgeführt. Im Fall von RabbitMQ führen wir das echte System aus, weil es einfacher ist, als die Messaging-Schnittstelle zu simulieren. Das Gleiche gilt für die Datenbanken, aber noch wichtiger ist, dass diese den Zustand des Systems speichern. Da Sie das System von außen beobachten, ist es Ihnen eigentlich egal, wie es seinen Zustand aufrechterhält, solange das erwartete Verhalten beobachtet wird. Abgesehen vom Zurücksetzen des Zustands zwischen den Szenarien sollte daher nur der Payments Container direkt mit den Datenbanken interagieren.
Für die anderen Abhängigkeiten, wie den internen Betrugsdienst oder einen Zahlungsprozessor, simulieren wir die REST-Schnittstellen mit einem Tool namens MockServer. Unsere Testimplementierung wird für jedes Szenario (im Abschnitt "given") Erwartungen festlegen, um sicherzustellen, dass der Payments-Container denkt, er spreche mit dem echten Ding. Wir werden MockServer auch verwenden, um zu überprüfen, ob bestimmte Interaktionen tatsächlich stattgefunden haben. Unser Schritt "Dann wird ein Einzug von 1337 Cent durch den Zahlungsprozessor initiiert" tut dies zum Beispiel.
Als letztes Teil des Puzzles wird unsere Testimplementierung docker compose ausführen, um alle Container zu starten. Sobald es bereit ist, die Tests auszuführen, interpretiert behave unsere Spezifikationen und führt sie aus.
Das Schöne an diesem Setup ist, dass wir es sowohl lokal als auch auf einem CI-Server ausführen können. Denken Sie daran: Wir wollen
Rollout
Jetzt werden Sie vielleicht denken: Sicher, das ist gut für ein neues Projekt, bei dem wir ganz von vorne anfangen und alles perfekt machen können, aber für mein bestehendes Projekt, das eine Menge Legacy-Code enthält, ist das nicht von großem Nutzen. Das ist nicht wahr.
Als ich anfing, war Picnic bereits 5 Jahre alt, eine Menge Code war geschrieben worden, das meiste davon gut, einiges davon nicht so gut, nichts davon mit ausführbaren Spezifikationen, wie ich sie oben beschrieben habe. Nichtsdestotrotz begann ich mit der Erstellung eines Proof-of-Concept-Setups mit einem einzigen Szenario für ein Team und gerade genug zusätzlichen Bits, um es mit Docker Compose zum Laufen zu bringen. Ich habe auch einige externe Abhängigkeiten simuliert, um zu zeigen, wie das funktioniert. Ich wählte ein Szenario, das einige brüchige, aber wichtige Codes berührte, so dass wir sofort von den Vorteilen profitieren konnten.
Als das Team von diesem Ansatz überzeugt war, haben wir das Setup mit unserer CI-Pipeline verbunden. Anstatt einmalig Spezifikationen für alles zu erstellen (wovon ich dringend abrate), erstellten wir jedes Mal, wenn wir Code anfassten oder eine neue Funktion hinzufügten, eine Funktionsdatei mit einigen Szenarien. Langsam aber sicher erreichten wir einen Zustand, in dem alle wichtigen Geschäftsfunktionen durch eine ausführbare Spezifikation abgedeckt waren. Das sprach sich herum und andere Teams wurden interessiert. Jetzt schreibt fast jedes Team bei Picnic diese Spezifikationen und reduziert den Feedback-Zyklus.
Der reduzierte Feedback-Zyklus
In diesem Beitrag habe ich erklärt, dass wir schnelles Feedback brauchen, um Software schnell zu ändern. Ausführbare Spezifikationen sind eine Möglichkeit, den Feedbackzyklus in Ihrem Softwareentwicklungsprozess zu verkürzen. Indem wir diese bei Picnic einführen, können wir jetzt:
- Bauen Sie das, was gebraucht wird, und nicht das, was wir fälschlicherweise für das halten, was wir brauchen.
- Sie erhalten sofortige Rückmeldung darüber, ob eine neu erstellte Funktion funktioniert und ob vorhandene Funktionen noch funktionieren, wodurch Fehler in der Produktion reduziert werden.
- Wir finden die Implementierung nicht mehr beängstigend oder riskant, sondern sind sicher, dass unsere Änderungen funktionieren.
- Verfügen Sie über eine lebendige Dokumentation. Wenn sich die Spezifikationen ändern, ändern sich auch unsere Tests, denn die Spezifikationen sind die Tests.
- Durch das Sicherheitsnetz der ausführbaren Spezifikationen haben wir die Freiheit, Refactoring durchzuführen. Wir können den Code verbessern, ohne Gefahr zu laufen, etwas kaputt zu machen, und können so eine gesündere Codebasis pflegen.
All dies verkürzt die Zeit für Softwareänderungen in einem Unternehmen und verschafft Ihnen einen Vorsprung gegenüber der Konkurrenz. Ich hoffe, dass dies Ihnen hilft, ausführbare Spezifikationen in Ihrem Unternehmen einzuführen und die Zeit zu verkürzen, die Sie für die Änderung Ihrer Software benötigen!
Dieser Artikel wurde ursprünglich auf dem Picnic-Blog veröffentlicht.
Verfasst von
Simeon van der Steen
Unsere Ideen
Weitere Blogs

Wo die GitHub Copilot Erweiterungspunkte die Governance brechen
Viele der jüngsten Ergänzungen des GitHub Copilot-Ökosystems bieten einen echten Mehrwert für einzelne Entwickler, erweitern aber auch die...
Rob Bos



Contact