Blog
Standardmäßig sicher, überraschend langsam
Was AWS vergessen hat, über die RDS IAM-Authentifizierung zu erwähnen

Im Laufe meiner Karriere als Backend- und Cloud-Ingenieur habe ich mit verschiedenen Datenbankmanagementsystemen gearbeitet. Und obwohl jedes von ihnen sein eigenes Protokoll, seine eigene Datenverwaltung und seine eigenen Verwaltungsverfahren hat, bleibt eine Sache immer gleich: die Verwaltung der Zugangsdaten.
Seien wir ehrlich: Die Erstellung eines Datenbankbenutzers und die Gewährung der erforderlichen Berechtigungen ist nur die halbe Arbeit. Sobald der Benutzer erstellt ist, benötigen die Techniker das Passwort, um mit der Datenbank arbeiten zu können. Nach dem Prinzip der Zwölf-Faktor-App werden die Klartext-Anmeldedaten aus Ihrem Anwendungscode herausgehalten. Es ändert sich nicht viel, ob es sich um eine Umgebungsvariable oder eine vollständige Konfigurationsdatei handelt. Es ist immer noch ein Geheimnis, das verwaltet werden muss: Jemand muss es bereitstellen, regelmäßig rotieren oder eine Lambda-Funktion erstellen, um dies zu tun. Und wenn das Geheimnis einmal durchgesickert ist, ist es bis zum nächsten Rotationszyklus gültig.
RDS IAM-Authentifizierung als Retter in der Not... Meistens
Die Amazon RDS IAM-Authentifizierung verspricht, das Geheimnis vollständig zu eliminieren - das "Passwort" ist ein kurzlebiges Token mit einer 15-minütigen TTL, das bei Bedarf generiert wird und an eine IAM-Identität gebunden ist, die Ihre Cloud-Plattform bereits verwaltet.
Aus betrieblicher Sicht ist dies ein attraktiver Tausch. Sie tauschen die Verwaltung des Lebenszyklus von Anmeldeinformationen gegen die Verwaltung von IAM-Richtlinien - etwas, das Ihr Team wahrscheinlich schon überall sonst in AWS macht.
Wenn Sie Ihre Datenbank-Anmeldedaten bereits in den Secrets Manager verschoben haben, haben Sie das Problem der hartkodierten Anmeldedaten gelöst. Die IAM-Authentifizierung ist der nächste logische Schritt - tauschen Sie ein verwaltetes Geheimnis gegen eine verwaltete Identität. Keine Rotations-Lambdas, kein Zeitfenster für den Verlust von Zugangsdaten, das länger als 15 Minuten dauert. Es passt genau in die Art und Weise, wie die moderne AWS-Infrastruktur über den Zugriff denkt.
Die Arbeit mit Legacy-Datenbanken, die oft von Workloads verwendet werden, die sich Ihrer Kontrolle entziehen, hindert das Team daran, die Verwaltung von Geheimnissen vollständig zu eliminieren. Bei Anwendungen, die Sie modifizieren oder sogar von Grund auf neu erstellen können, liegt der Handel jedoch auf der Hand.
Wir haben es geschafft. Dann haben wir uns die Latenzzeit unserer p99-Anfragen angesehen.
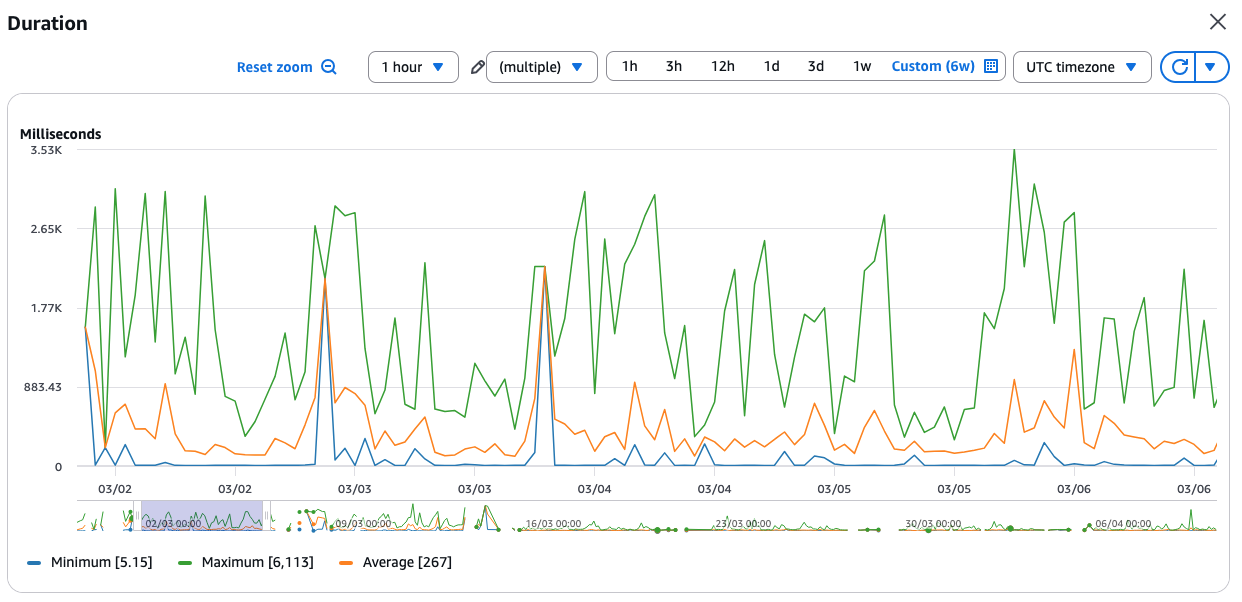 Die erste Reaktion war natürlich zu prüfen, ob wir eine suboptimale Abfrage übersehen haben oder ob alle Indizes vorhanden sind. Aber unsere Datenbank war einfach nur im Leerlauf:
Die erste Reaktion war natürlich zu prüfen, ob wir eine suboptimale Abfrage übersehen haben oder ob alle Indizes vorhanden sind. Aber unsere Datenbank war einfach nur im Leerlauf: 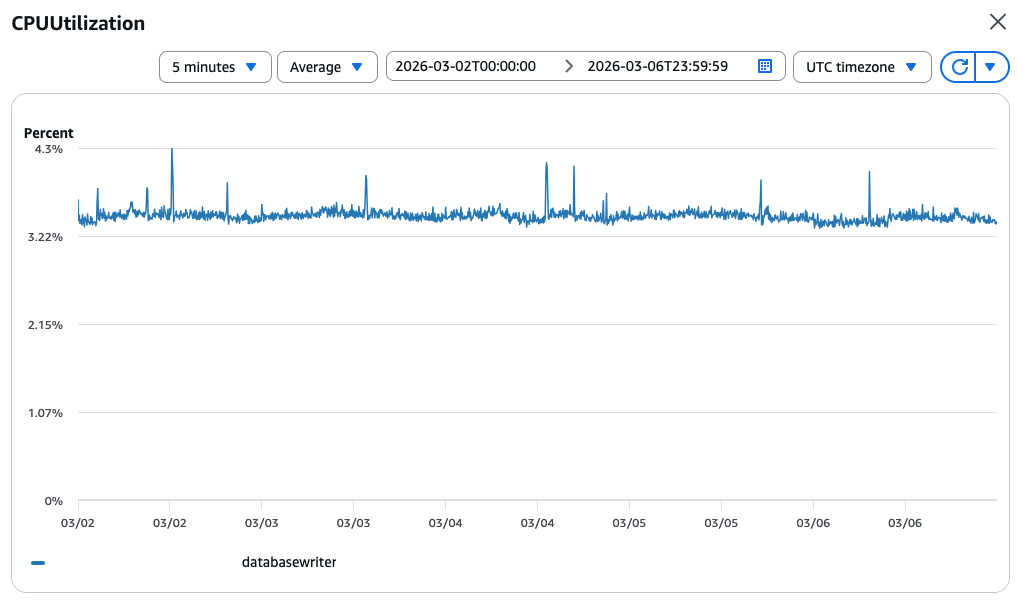 Für das Protokoll, die Datenbankkonfiguration:
Für das Protokoll, die Datenbankkonfiguration:
- Amazon Aurora Serverless (v2) PostgreSQL v16.8
- Minimum ACU - 2
- Maximum ACU - 8
Die gleiche Latenz war in den Entwicklungs- und Staging-Umgebungen leicht zu reproduzieren. Um also alle abtrünnigen Abhängigkeiten und Lambda-Kaltstarts zu eliminieren, habe ich eine EC2-Instanz bereitgestellt und bin zur reinen Befehlszeile und psql zurückgekehrt. Die guten alten Zeiten :)
Das Rettungsteam war... Verspätet
Auf jeder EC2-Instanz ist die AWS CLI vorinstalliert. Es ist auch eine gute Praxis, ein IAM-Instanzprofil zu erstellen. Um Verbindungsprivilegien mit RDS IAM Authentication zu gewähren, müssen Sie die folgende Richtlinienanweisung hinzufügen:
{
"Action": "rds-db:connect",
"Resource": "arn:aws:rds-db:<REGION>:<ACCOUNT>:dbuser:<DB_CLUSTER_ID>/<DB_USERNAME>",
"Effect": "Allow"
}Ja, Ihr DBA/DevOps muss zunächst einen passwortlosen Datenbankbenutzer erstellen und diesem eine rds_iam zuweisen. Sobald der Benutzer und die Richtlinie vorhanden sind, können wir ein Token erhalten:
export PGPASSWORD=$(aws rds generate-db-auth-token \
--hostname $PGHOST \
--port $PGPORT \
--username $PGUSER \
--region $AWS_REGION \
)Die PG* Umgebungsvariablen sind praktisch, da sie automatisch vom Dienstprogramm psql gelesen werden, so dass Sie sie nicht erneut übergeben müssen. Es ist an der Zeit zu sehen, was los ist, drei, zwei, eins:
$ time psql -c 'SELECT 1'
?column?
----------
1
(1 row)
real 0m6.148s
user 0m0.006s
sys 0m0.006sWarten Sie... Schon wieder...
$ time psql -c 'SELECT 1'
?column?
----------
1
(1 row)
real 0m0.119s
user 0m0.000s
sys 0m0.012sIch ging zum Dashboard für die Datenbanküberwachung, um nach einer Erklärung zu suchen. Die Diagramme waren ruhig, genau wie die CPU-Auslastung oben. Bis ich dieses Diagramm auf der dritten Seite fand. Die Zahlen waren langweilig, das Muster ähnelte jedoch der Funktionsdauer: 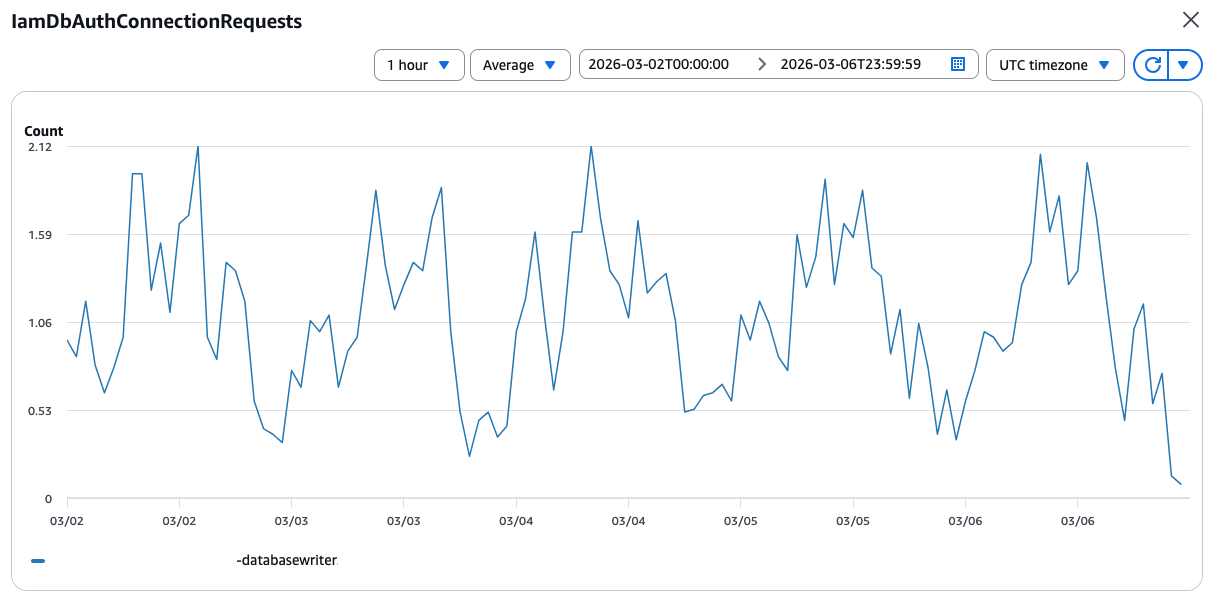 Während ich mir die Graphen ansah, waren ein paar Minuten vergangen. Ich wechselte zurück zur EC2-Konsole und führte den Befehl ein weiteres Mal aus:
Während ich mir die Graphen ansah, waren ein paar Minuten vergangen. Ich wechselte zurück zur EC2-Konsole und führte den Befehl ein weiteres Mal aus:
$ date
Mon Mar 9 14:11:29 UTC 2026
$ time psql -c 'SELECT 1'
?column?
----------
1
(1 row)
real 0m3.940s
user 0m0.015s
sys 0m0.000sServerloses Aurora: Die IAM-Steuer in voller Höhe zahlen
Bevor wir zu Serverless Aurora wechselten, um die Importzeit des Legacy-Datensatzes zu verbessern, verwendeten wir eine bereitgestellte Datenbankinstanz. Und ich konnte mich nicht erinnern, jemals solch hohe Verbindungszeiten erlebt zu haben.
Unsere Benutzer waren nicht so wachsam, denn für sie funktionierte die Sache einfach - man bekommt seine Antwort, es dauert nur seine Zeit. Was dazu beitrug, das Problem noch mehr zu verschleiern, waren die Zeitüberschreitungen der Lambda-Funktionen - die berüchtigten Standardwerte von 30 Sekunden. Die API-Handler haben also einfach nie ein Zeitlimit überschritten.
Also änderte ich den Typ der Datenbankinstanz von Serverless zu einem ressourcenmäßig ähnlichen db.t4g.medium, einem Allzweck-Instanztyp mit 2 vCPUs und 4 GB Speicher, was in etwa 2 ACUs entspricht. Das Ergebnis war überraschend:
$ time psql -c 'SELECT 1'
?column?
----------
1
(1 row)
real 0m1.597s
user 0m0.013s
sys 0m0.000sAlles andere war wie immer:
- Die gleiche EC2-Instanz.
- Das RDS-Authentifizierungstoken wurde auf die gleiche Weise erzeugt.
- In beiden Fällen keine expliziten
ssl-modeHinweise, diepsqlmit der Zertifikatsüberprüfung verlangsamt haben könnten.
Ich verbrachte etwa eine Stunde damit, die Instanztypen zu wechseln und dieselben Tests durchzuführen: Die Ergebnisse waren ähnlich, mit kleinen Abweichungen bei "kalten" und "heißen" Verbindungsversuchen. An diesem Punkt beschloss ich, dass ich etwas übersehen haben könnte, denn solche Ergebnisse können nicht nur von mir stammen. Also reichten wir ein Support-Ticket bei AWS ein, weil wir dachten, dass es sich um eine Verschlechterung des Service oder sogar um einen Fehler im Authentifizierungs-Plugin handeln müsste.
Aus irgendeinem Grund hatte ich das Gefühl, dass ich plausiblere Beweise brauchte, als den psql Dienstprogramm zu timen. Also beschloss ich, sie zu sammeln.
Bringen Sie die Stoppuhr mit
Obwohl ich wusste, dass die Ergebnisse ähnlich aussehen würden, habe ich ein kleines Testlabor eingerichtet:
- Eine Amazon Aurora Serverless-Instanz mit einer Mindestkapazität von 2 ACUs.
- Eine Python-basierte Lambda-Funktion, vollständig instrumentiert mit
- Lambda Performance Insights.
- OpenTelemetry-Metriken, die an CloudWatch Application Signals gesendet werden.
- Ein HTTP-API-Gateway, das einen einzigen
GET-Endpunkt bereitstellt, der von der Lambda-Funktion unterstützt wird.
AWS Distro for OpenTelemetry Lambda hilft bei der schweren Arbeit. Alles, was ich tun musste, war, meinen eigenen Code zu instrumentieren. So erhielt der API-Handler-Code 2 Histogramm-Meter, um die Zeit für den Erwerb des RDS IAM-Tokens und den Aufbau einer Datenbankverbindung aufzuzeichnen:
from aws_lambda_powertools import Logger
from opentelemetry import metrics
logger = Logger()
meter = metrics.get_meter(__name__)
rds_connection_latency = meter.create_histogram(
name="rds-iam.rds.connection.latency",
description="Measures latency time to establish a new RDS connection",
unit="ms",
)
rds_token_latency = meter.create_histogram(
name="rds-iam.rds.auth-token.latency",
description="Measures latency time to generate a new RDS auth token",
unit="ms",
)
Ich habe beschlossen, auch die Verbindungslatenzen für die klassische Benutzername-Passwort-Authentifizierung zu testen. Ja, die, von der uns die RDS IAM-Authentifizierung hätte befreien sollen. Also habe ich in der Funktion get_db_connection_string ein Feature-Flag hinzugefügt, mit dem Sie schnell von einer Authentifizierungsart zur anderen wechseln können:
import boto3
rds_client = boto3.client("rds")
secrets_manager = boto3.client("secretsmanager")
_db_token: dict = {"acquired_at": 0, "value": None}
_token_ttl = 14 * 60
def _get_db_auth_token() -> str:
"""
Lazy fetch of IAM authentication token
The function fetches a new token at first call,
or if the existing token's TTL has expired.
"""
global _db_token, _token_ttl
logger.debug("Using RDS IAM auth")
t = time.time()
token_age = t - _db_token["acquired_at"]
if token_age >= _token_ttl:
start_ns = time.time_ns()
_db_token = {
"acquired_at": t,
"value": rds_client.generate_db_auth_token(
os.environ["PGHOST"],
int(os.environ["PGPORT"]),
os.environ["PGUSER"]
),
}
end_ns = time.time_ns()
token_time_ms = (end_ns - start_ns) / 1_000_000
rds_token_latency.record(token_time_ms)
logger.debug("Got RDS IAM token", extra={"token_ms": token_time_ms})
return _db_token["value"]
_password = None
def _get_pwd_from_secret() -> str:
"""
Lazy fetch of RDS password from Secrets Manager.
"""
global _password
logger.debug("Using RDS credentials secret")
if _password is None:
start_ns = time.time_ns()
secret = secrets_manager.get_secret_value(SecretId="rds-cluster-user")
end_ns = time.time_ns()
rds_token_latency.record((end_ns - start_ns) / 1_000_000)
_password = json.loads(secret["SecretString"])["password"]
return _password
def get_db_connection_string() -> str:
"""
Returns DB connection string for psycopg
"""
use_rds_token = int(os.environ["USE_RDS_TOKEN"])
password = _get_db_auth_token() if use_rds_token else _get_pwd_from_secret()
return " ".join(
[
f"host={os.environ['PGHOST']}",
f"port={os.environ['PGPORT']}",
f"dbname={os.environ['PGDATABASE']}",
f"user={os.environ['PGUSER']}",
f"password={password}",
]
)
Um das alles zu verdrahten, habe ich schließlich psycopg-Verbindungspools verwendet, um mehrere Verbindungen innerhalb der gleichen Lambda-Funktionslaufzeit zu erstellen. Warum nicht nur eine Verbindung, sondern einen Pool? Nun ja:
- Eine Anfrage erstreckt sich über ein Lambda.
- Ein Lambda erhält ein RDS-Auth-Token und öffnet eine Verbindung.
- Die Verbindung wird während des gesamten Lebenszyklus der Laufzeit wiederverwendet.
- Außerdem liefern die Verbindungspools Verbindungsstatistiken.
Das heißt, sobald ich meinen Lasttest starte, wird Lambda X gleichzeitige Instanzen mit X offenen Verbindungen erzeugen. Und diese Datenbankverbindungen würden während des gesamten Tests verwendet werden. Dadurch erhalte ich nur X Latenzdatenpunkte zu Beginn des Tests. Meine Idee war es, die Verbindungslatenz mit dem RDS-Auth-Token zu messen , den Aurora bereits "gesehen" hatte. Nur um zu prüfen, ob es einen Unterschied macht.
Ich habe also die Verbindung max_lifetime auf 3 Minuten eingestellt und den Pool synchron "geöffnet", um die "kalten" Verbindungszeiten zu erhalten:
pool = None
prev_conn_time = 0
def get_pool():
"""
Returns a psycopg connection pool.
If no pool exists, create a new one and return it.
"""
global pool, prev_conn_time
if pool is None:
pool = ConnectionPool(
get_db_connection_string,
min_size=1,
max_size=5,
# maximal lifetime of a single connection
max_lifetime=180,
open=False,
)
pool.open(wait=True)
# record connection statistic
cold_start_ms = pool.get_stats()["connections_ms"]
rds_connection_latency.record(cold_start_ms)
prev_conn_time = cold_start_ms
return pool
def handler(event, ctx):
""" """
global prev_conn_time
p = get_pool()
with p.connection() as cnt:
cnt.execute("SELECT 1")
conn_ms = p.get_stats()["connections_ms"]
# connection statistic is cumulative, we need delta
if prev_conn_time < conn_ms:
rds_connection_latency.record(conn_ms - prev_conn_time)
prev_conn_time = conn_ms
return {"body": "Hello there"}Ein aufmerksamer Leser hätte aufgeschrien:
Ha, ein Anfängerfehler!
Das RDS-Token und der Verbindungspool sollten außerhalb des Funktionshandlers initialisiert werden.
Und sie hätten Recht, aber nur teilweise.
Kaltstart-Schlagloch
Die Sache ist die, dass der Kaltstart der Lambda-Funktion, auch bekannt als Init-Stadium, jetzt in Rechnung gestellt wird. Vor einiger Zeit konnte man einige Kosten einsparen, indem man schwere Ressourcen, wie z.B. die Abfrage von Geheimnissen und Datenbankverbindungen, vor der Deklaration des Funktionshandlers initialisierte. Dies ist jedoch nicht mehr der Fall, da die Init-Zeitfunktion dem Kunden in Rechnung gestellt wird.
Während des Experiments habe ich einen weiteren Nachteil dieses Ansatzes entdeckt. Die Init-Phase wird nicht als Dauer der Funktion gemeldet. Ja, sie wird an die Protokollgruppe der Funktion gemeldet, aber sie wird nicht als Metrik Dauer auf dem Überwachungs-Dashboard angezeigt.
Was nun? Nun, wenn Sie die Dauer Ihrer Funktionen überwachen oder sogar einen Alarm einstellen, um sie im Auge zu behalten, sollten Sie daran denken, dass Kaltstarts von dieser Kennzahl ausgeschlossen sind. Aber Sie zahlen trotzdem für sie.
Erster Kandidat
Von hier aus habe ich einen Leistungstest mit siege durchgeführt:
siege -t 15M https://$API_GATEWAY_URL
Und das ergab die folgenden Ergebnisse:
- Serverloses Aurora mit RDS IAM-Authentifizierung
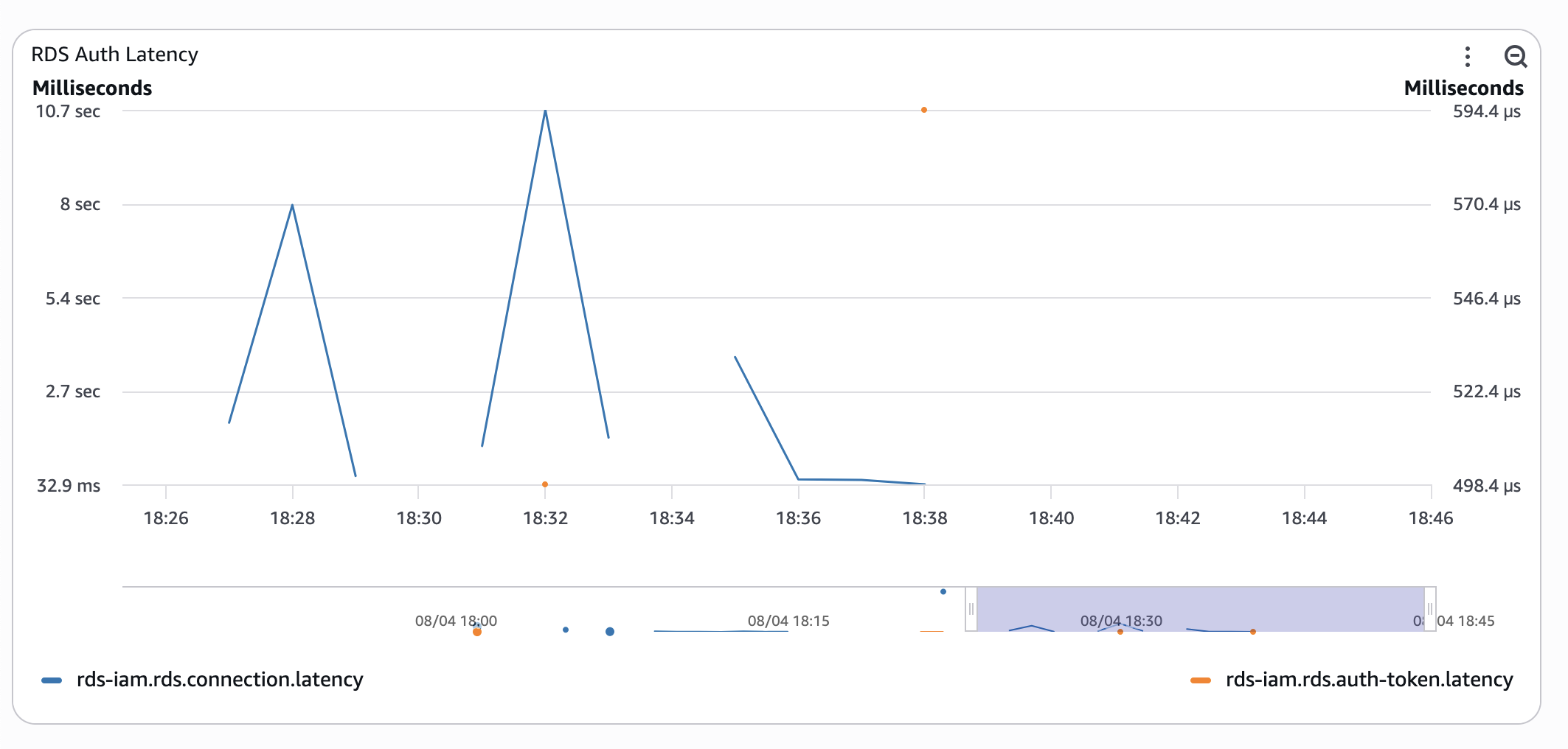
- Serverloses Aurora mit klassischem Benutzernamen und Passwort.
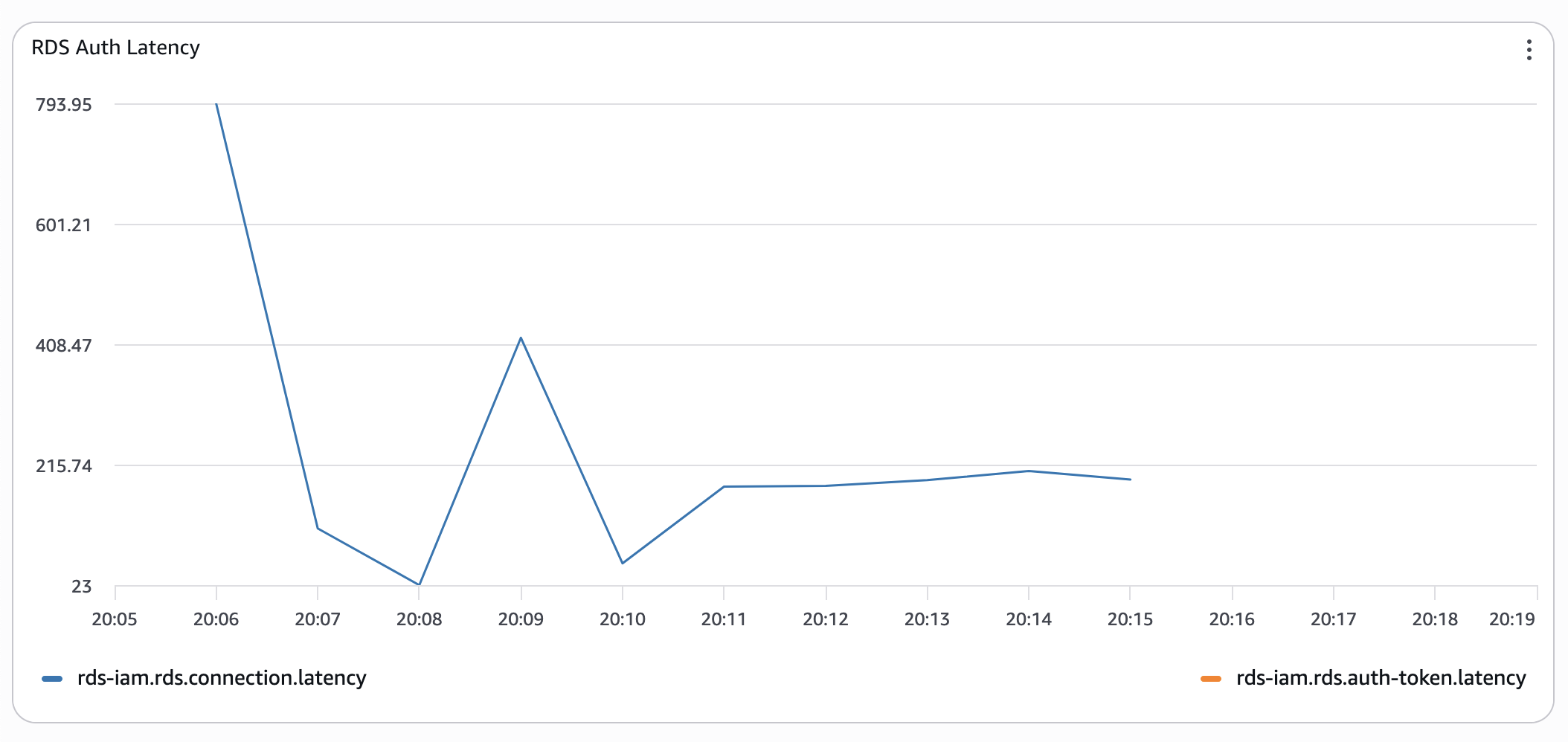 Das Timing ist zwar immer noch nicht perfekt, aber bereits 10 Mal besser.
Das Timing ist zwar immer noch nicht perfekt, aber bereits 10 Mal besser.
Ich habe den gleichen Test mehrmals durchgeführt und dabei entweder Funktionen zur Neuverteilung ausgelöst oder sie einfach abkühlen lassen - die Ergebnisse waren ähnlich: "kalte" Verbindungen mit RDS IAM auth sind horrend langsam. Das Vorwärmen des Verbindungspools verbesserte die Situation erheblich.
Der Nächste, bitte
Für die nächste Runde habe ich eine Serverless RDS-Instanz (minimale Kapazität von 2 ACU) durch eine bereitgestellte db.t4g.medium ersetzt.
Die T-Klasse von Instanzen ist eine so genannte "burstable" Klasse: Instanzen verdienen CPU-Credits, wenn ihre Last niedrig ist, und verbrauchen sie, wenn sie in die Höhe schießt. Dies hätte die Ergebnisse des Experiments verschlechtern können, denn die Instanz beginnt mit einem Guthaben von 0. Aber, keine Chance:
- Bereitgestellte Aurora-Instanz mit RDS IAM Auth:
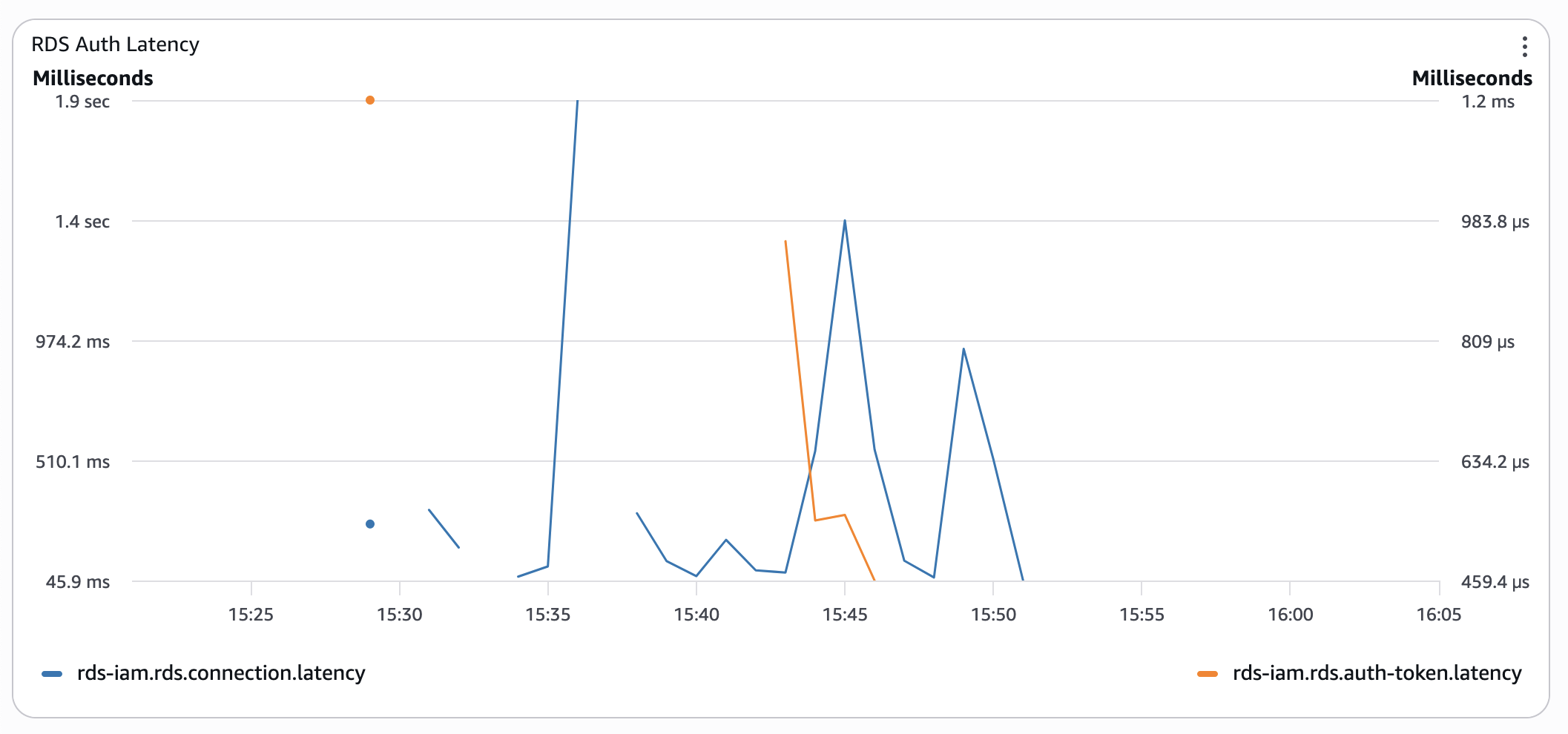 Auch ohne CPU-Guthaben ist die Verbindungslatenz im schlimmsten Fall 3 Mal niedriger als bei Aurora ohne Server.
Auch ohne CPU-Guthaben ist die Verbindungslatenz im schlimmsten Fall 3 Mal niedriger als bei Aurora ohne Server. - Aurora mit klassischer Authentifizierung bereitgestellt:
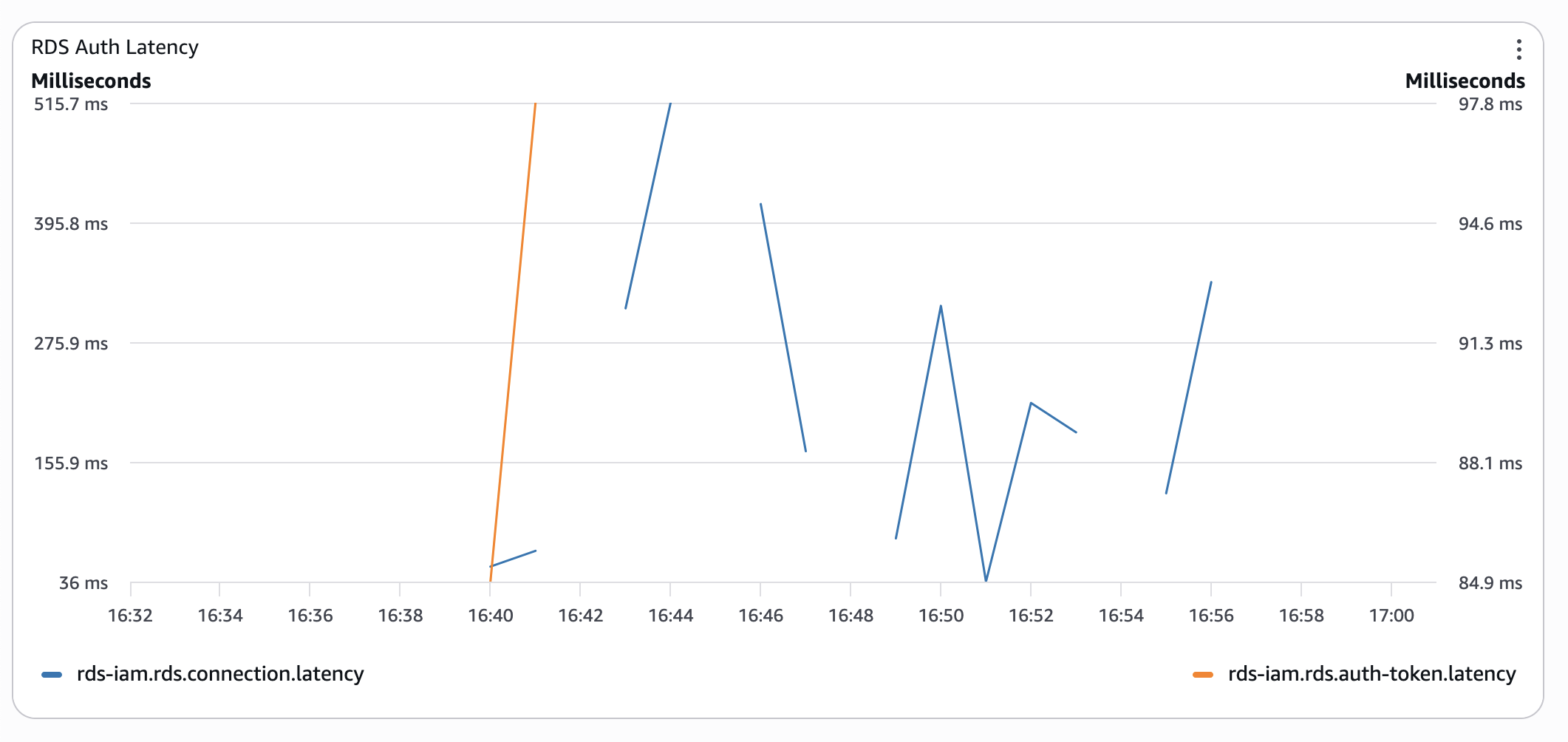 In diesem Stadium begann sich ein niedriges CPU-Guthaben bemerkbar zu machen. Ich ließ mir also etwas Zeit und wiederholte den Test am nächsten Morgen:
In diesem Stadium begann sich ein niedriges CPU-Guthaben bemerkbar zu machen. Ich ließ mir also etwas Zeit und wiederholte den Test am nächsten Morgen: 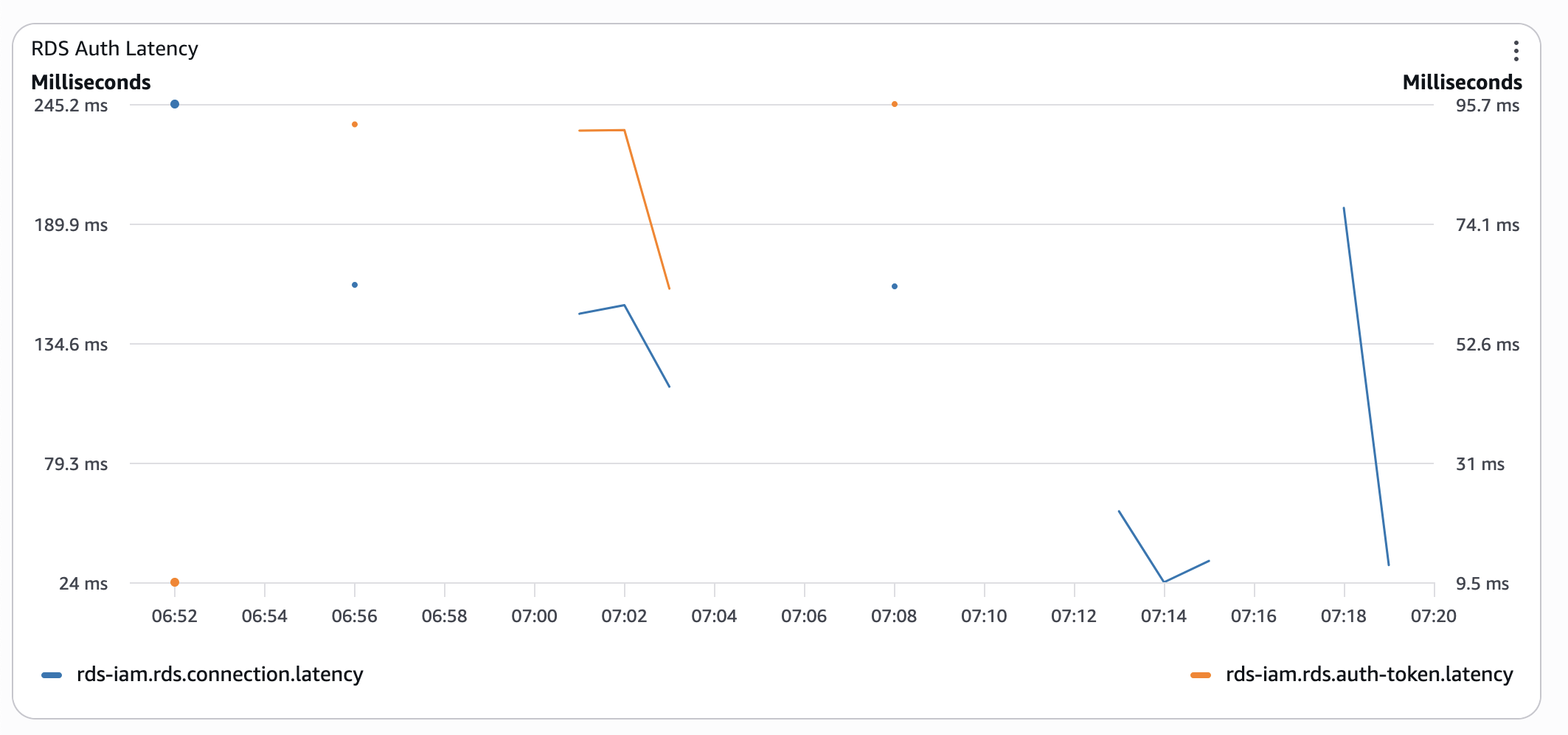
War ich überrascht? Nein, das wusste ich bereits von psql timings. War es die Mühe wert? Ja, ich habe all diese Metriken erhalten, so dass ich diese hübschen Diagramme erstellen konnte 🤓.
Sie haben Post erhalten
Erinnern Sie sich an die Unterstützungsanfrage, die wir eingereicht haben? Nun, ich hatte auf ein anderes Ergebnis gehofft, als es eintrat. Stellen Sie sich vor, wie überrascht ich war, als wir nach mehr als einer Woche, in der wir Nachrichten hin und her schickten, andere Tests auf Anraten der Support-Techniker durchführten und den Fall an die RDS- und IAM-Serviceteams weiterleiteten, die folgende Antwort erhielten:
1. Aurora Serverless löscht den Speicher beim Skalieren (Auslagern), was sich wie beobachtet auf die Verbindungslatenz auswirken kann.
2. Das Gleiche kann bei der Verwendung von RDS Proxy und Serverless Aurora-Instanzen beobachtet werden, obwohl die Auswirkungen geringer sind.
3. Bereitgestellte Instanzen zeigen sowohl am Cluster-Endpunkt als auch am RDS Proxy-Endpunkt eine verbesserte Leistung, da die Instanz nicht ausgelagert wird.
Das Engineering-Team hat darauf hingewiesen, dass eine Erhöhung der minACU die Verbindungslatenzen verbessern kann; es gibt jedoch keine Garantie, dass Instanzen/Cluster mit hoher minACU nicht ausgelagert werden.
Ja, alle Datenbankverbindungen sind mit Kosten verbunden. Aber ich weigere mich zu glauben, dass der Preis mehrere Sekunden Latenzzeit sind. Haben wir irgendwelche Empfehlungen erhalten? Natürlich, kurz gesagt, mehr Geld für das Problem auszugeben:
1. Bei latenzempfindlichen Arbeitslasten schneiden provisionierte Instanzen besser ab, allerdings zu einem höheren Preis.
Das bedeutet nichts anderes als "Wählen Sie Ihr eigenes Gift" - eine höhere Rechnung für Ihre Datenbank oder für Ihren Computer.
2. RDS Proxy verbessert die Verbindungslatenz, unabhängig davon, ob er mit Provisioned Instances oder Serverless verwendet wird.
Der Proxy hat die Verbindungslatenz tatsächlich verbessert, indem er sie einfach vor Ihrer Arbeitsbelastung versteckt hat. Ich habe den Test auch durchgeführt. Die allerersten Verbindungen hatten die gleichen horrenden Latenzen. Nachdem Ihr Proxy warm genug ist, erhalten wir Latenzen von unter 100 ms. Juhu! Außerdem haben wir jetzt einen weiteren Service, für den wir bezahlen müssen!
Der letzte Absatz war nichts weiter als das berüchtigte "Danke für Ihre Zeit und Hilfe, wir haben alles notiert".
Unsere Untersuchung hat ergeben, dass dieses Verhalten mit der Serverless-Architektur und den Skalierungsvorgängen von Aurora vereinbar ist.
Das Entwicklungsteam hat diese Ergebnisse dokumentiert, um zukünftige Produktverbesserungen zur Optimierung der Verbindungsleistung zu unterstützen.
Einpacken
Da alle unsere Migrationsaktivitäten abgeschlossen waren und das Nutzungsmuster vorhersehbar war, tauschten wir in einem ersten Schritt unser Serverless Aurora gegen eine gute alte provisionierte Instanz aus. Allein dadurch halbierte sich unsere durchschnittliche Anfragedauer. Kaltstarts konnten immer noch 1-2 Sekunden dauern, aber Spitzen von 4+ Sekunden waren komplett verschwunden.
Beim Durchstöbern der Dokumente habe ich zwei weitere Gründe gefunden, die zum Nachdenken anregen:
- Benutzerdefinierte Route 53 DNS-Einträge anstelle von Cluster-Endpunkten - vergessen Sie es;
generate-db-auth-tokenakzeptiert nur Letztere.
Wenn Sie also ein menschenfreundlichesrds.<YOUR_DOMAIN>.internalfür die automatische Umschaltung auf einen anderen Cluster haben möchten, wenn etwas schief geht, ist RDS IAM auth nichts für Sie. - RDS Auth-Token-Generationen werden weder in CloudWatch noch in CloudTrail protokolliert. Es ist also unmöglich , Metriken zu erhalten und Alarme zu setzen.
Ja, die Verwaltung von Datenbankbenutzern und ihren Anmeldedaten ist eine Übung für sich. Und die RDS IAM-Authentifizierung sieht sehr verlockend aus. Wenn Sie es in Erwägung ziehen, haben Sie jetzt die Zahlen. Machen Sie den Handel mit offenen Augen.
Foto von Michael Anthony.
Verfasst von
Yev Dytyniuk
AWS Cloud Consultant/Engineer
A software/cloud engineer who has seen enough to go and fix things before the damage is done. I've built various web applications, integrated enterprise systems, run migrations, etc. I like simple, effective, and robust architectures and am always on the lookout for another interesting challenge: optimise a wonky database, turn an hour-long batch process into a blazingly fast event-based pipeline, or just talk about the quirks of another AWS service.
Unsere Ideen
Weitere Blogs

Wo die GitHub Copilot Erweiterungspunkte die Governance brechen
Viele der jüngsten Ergänzungen des GitHub Copilot-Ökosystems bieten einen echten Mehrwert für einzelne Entwickler, erweitern aber auch die...
Rob Bos



Contact