Blog
Steigern Sie Ihre ADF-Produktivität mit Terraform

Einführung
In diesem Blogbeitrag erfahren Sie, wie Azure Data Factory (ADF) und Terraform zur Optimierung der Datenaufnahme genutzt werden können. ADF ist ein Microsoft Azure-Tool, das häufig für die Aufnahme von Daten und die Orchestrierung von Aufgaben verwendet wird. Ein typisches Szenario für ADF besteht darin, Daten aus einer Datenbank abzurufen und sie als Dateien in einem Online-Blob-Speicher zu speichern, die von Anwendungen nachgelagert genutzt werden können.

Beispiel eines Ingestionsprozesses mit ADF
ADF bietet eine grafische Benutzeroberfläche, mit der Benutzer problemlos Pipelines erstellen können, die verschiedene Datenquellen mit ihren Zielen verbinden. Dieser klickbasierte Entwicklungsansatz mag im Vergleich zu High-Code-Alternativen zugänglich erscheinen. Er birgt jedoch auch die Gefahr, dass er ineffizient ist und viel Entwicklungszeit in Anspruch nimmt. Um dieses Problem zu lösen, schlagen wir eine effiziente Entwicklungsmethode vor, die die Entwicklungszeit durch die Verwendung von Parametern und die Bereitstellung von Triggern mit Terraform minimiert und sich an zwei Best Practices für die Softwareentwicklung orientiert.
Ein kurzer Hinweis: Dieser Blog richtet sich an Datenenthusiasten mit einiger Erfahrung in Data Factory. Er setzt ein grundlegendes Verständnis der in ADF verwendeten Konzepte voraus. Wenn Sie ADF noch nicht kennen, betrachten Sie ihn als Ausgangspunkt, um das Potenzial von ADF zu entdecken.
Bewährte Praktiken der Softwareentwicklung
DRY (Don't Repeat Yourself - Wiederholen Sie sich nicht)
DRY ist ein grundlegendes Prinzip in der Softwareentwicklung, das die Vermeidung von Wiederholungen von Code oder Logik betont. Es fördert die Wiederverwendbarkeit, Wartbarkeit und Lesbarkeit von Code, indem es sicherstellt, dass jedes Wissen oder jede Funktionalität innerhalb eines Softwaresystems nur an einer Stelle dargestellt wird.
Wir halten uns an das DRY-Prinzip (Don't repeat yourself) und sagen:
ähnlicher Datenspeicher -> ähnliche Ingestion-Pipeline
KISS (Keep It Simple, Stupid)
KISS ist ein Design- und Entwicklungsprinzip, das für Einfachheit bei Softwaredesign, -architektur und -implementierung plädiert. Die Idee hinter dem KISS-Prinzip ist es, Lösungen so einfach wie möglich zu halten, ohne dabei auf Funktionalität oder Effektivität zu verzichten.
Wir halten uns an das KISS-Prinzip und sagen:
Jede Pipeline hat so wenige Aktivitäten wie nötig (vorzugsweise 1) Jede Pipeline hat ein klares Ziel (vorzugsweise nur das Kopieren von Daten)
Ziel
Dieser Blog-Beitrag soll Ihnen einen Weg aufzeigen, wie Sie ADF mit Hilfe von Parametern und Triggern nutzen können, die von Terraform erstellt wurden und die sich an die erwähnten Best Practices für die Softwareentwicklung halten. Dies führt zu weniger Klicks, schnelleren Entwicklungszeiten und ermöglicht es, dass auch weniger technisch versierte Personen mitarbeiten können.
Wir tun dies, indem wir:
- Eine Trennung zwischen dem, was wir tun wollen, und dem, wie wir es tun wollen:
- Was wir tun möchten: Daten nach einem bestimmten Zeitplan aus einem Datenspeicher in einen Speichercontainer verschieben.
- Wie wir es machen wollen: Eine Pipeline mit (vorzugsweise) einer oder mehreren Aktivitäten unter Verwendung von Datensätzen und verknüpften Diensten in ADF.
Durch diese Aufteilung können auch technisch weniger versierte Benutzer verstehen und möglicherweise dazu beitragen, "was wir tun wollen", ohne sich Gedanken darüber zu machen, "wie wir es tun wollen".
- Erstellen Sie wiederverwendbare Pipelines: Wir brauchen uns nicht zu wiederholen (ähnlicher Datenspeicher â ähnliche Ingestion-Pipeline).
Wir haben unseren Arbeitsablauf mit ADF in zwei Teile aufgeteilt:
Aufbau dynamischer Pipelines mit Parametern
Der Nutzen
Wie wir es machen wollen: eine Pipeline mit einer (vorzugsweise) oder mehreren Aktivitäten unter Verwendung von Datensätzen und verknüpften Diensten in ADF.
Wie bereits erwähnt, erstellen wir Pipelines und planen dann die Pipelineläufe separat. Das bedeutet, dass wir Pipelines so erstellen müssen, dass wir sie so oft wie möglich wiederverwenden können. Diese Wiederverwendung der gleichen Pipeline wird durch die Parametrisierung der Pipeline-Objekte ermöglicht. Ein Parameter ist eine benannte Einheit, die Werte definiert, die in verschiedenen Komponenten Ihrer Datenfabrik wiederverwendet werden können. Mit Hilfe von Parametern können Sie Ihre Datenfabrik dynamischer, flexibler, einfacher zu pflegen und skalierbar machen.
Um die Macht der Parameter zu demonstrieren, nehmen wir das folgende Beispiel:
Die Daten müssen von 2 SQL-Datenbanken mit 5 Tabellen in einen Azure Blob Storage-Container übertragen werden. Jede Tabelle muss in ein Parkett umgewandelt werden, und der zugehörige Ordner muss in einen Container gelegt werden. Ein Azure Key Vault wird erstellt, um alle Geheimnisse zu speichern. Die Datenbanken sehen wie folgt aus:
hr
- contracts
- employees
sales
- customers
- inventory
- sales
Der Vergleich der Ressourcenmenge mit und ohne Parameter sieht wie folgt aus:
| Ressourcen | Ohne Parameter | Mit Parametern |
|---|---|---|
| Verknüpfte Dienste | 3 (1 für jede Datenbank, 1 für den Blob) | 2 (1 für die Datenbanken, 1 für den Blob) |
| Datensätze | 10 (1 für jede Tabellenquelle/-senke) | 2 (1 für SQL, 1 für Blob-Parkett) |
| Pipelines | 5 (1 für jeden Tisch) | 1 |
Visuell sieht diese Verbesserung in ADF wie folgt aus:
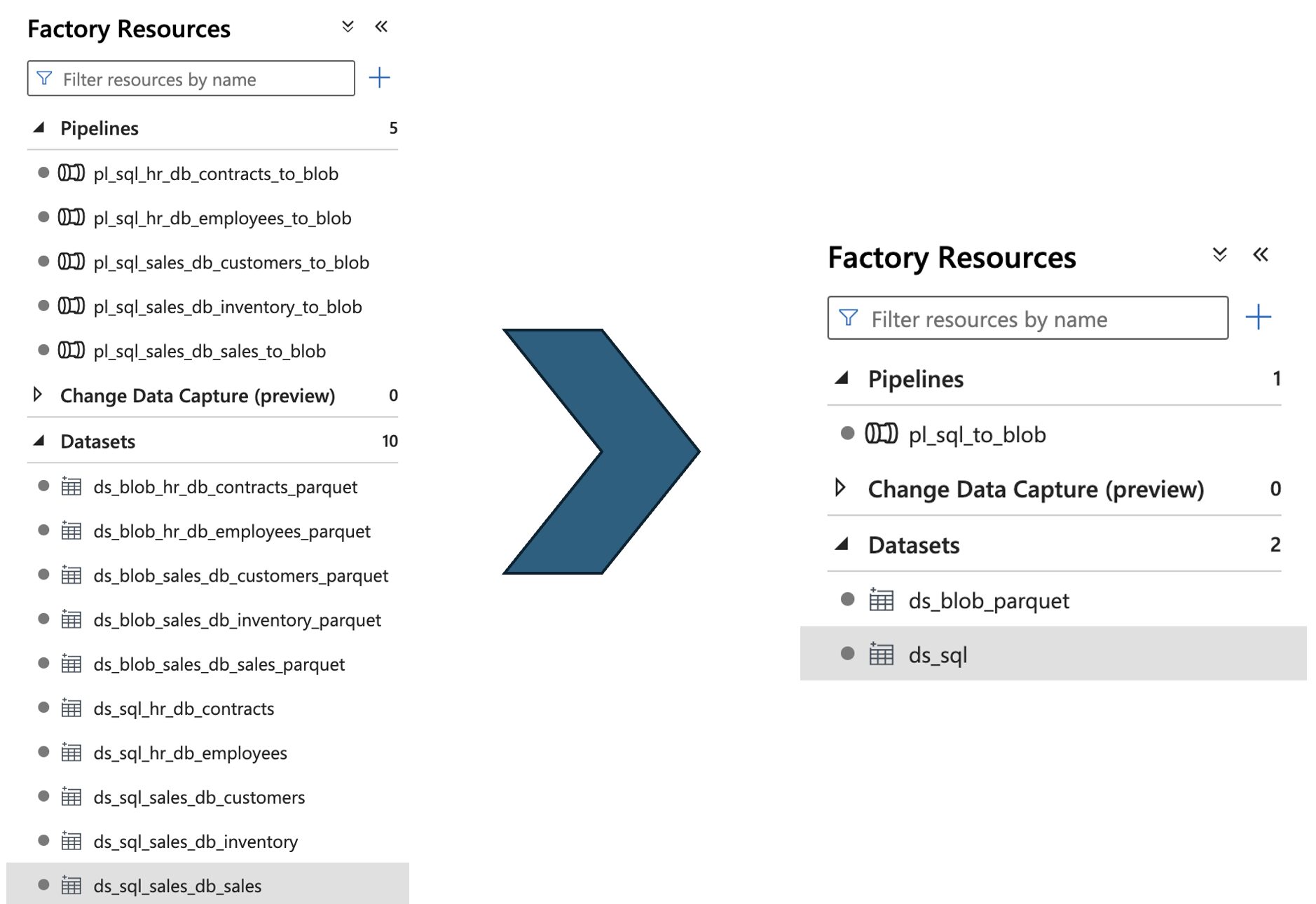
Das ist eine enorme Verbesserung, selbst mit nur 2 SQL-Datenbanken und fünf Tabellen. Stellen Sie sich die Vorteile vor, wenn es Hunderte von Tabellen gibt! Das Hinzufügen einer neuen Tabelle zum parametrisierten Setup würde keine Änderungen an den Pipeline-Definitionen erfordern. Dies ermöglicht es auch nicht-technischen Personen, neue Tabellen zu laden, indem sie sich an die festgelegten Richtlinien von
Durch diese Aufteilung können auch technisch weniger versierte Benutzer verstehen und möglicherweise dazu beitragen, "was wir tun wollen", ohne sich Gedanken darüber machen zu müssen, "wie wir es tun wollen".
Wie funktioniert das?
Mit ADF werden wir eine Pipeline erstellen und Parameter definieren. Eine Erklärung der Pipeline-Parameter finden Sie hier.
Wo wollen wir also Parameter hinzufügen? Im Grunde überall! Um sicherzustellen, dass unsere Pipelines vollständig parametrisiert sind, müssen wir auf verschiedenen Ebenen der Pipeline Parameter einfügen.
Pipeline-Parameter Pipeline-Parameter sind übergeordnete Parameter, die für die gesamte Pipeline gelten. Diese Parameter können verschiedene Aspekte der Pipeline-Ausführung steuern, z. B. umfeldspezifische Einstellungen, Dateipfade oder Verarbeitungsoptionen.
Datensatzparameter Datensatzparameter werden verwendet, um Datensätze innerhalb der Pipeline dynamischer zu gestalten. Indem Sie Datensätze parametrisieren, können Sie die Details der Datenquelle oder des Ziels zur Laufzeit ändern und so Ihre Datenverarbeitung flexibler gestalten. Dies ist besonders nützlich, wenn Sie mit mehreren Datensätzen arbeiten, die einer ähnlichen Struktur folgen, sich aber im Detail unterscheiden, z.B. bei Dateinamen oder Verbindungsstrings.
Parameter für verknüpfte Dienste Mit Parametern für verknüpfte Dienste können Sie Verbindungen zu Ihren Datenquellen und Zielen dynamisch konfigurieren. Diese Parameter machen Ihre verknüpften Dienste an verschiedene Umgebungen oder Szenarien anpassbar und erhöhen so die Gesamtflexibilität Ihrer Pipeline.
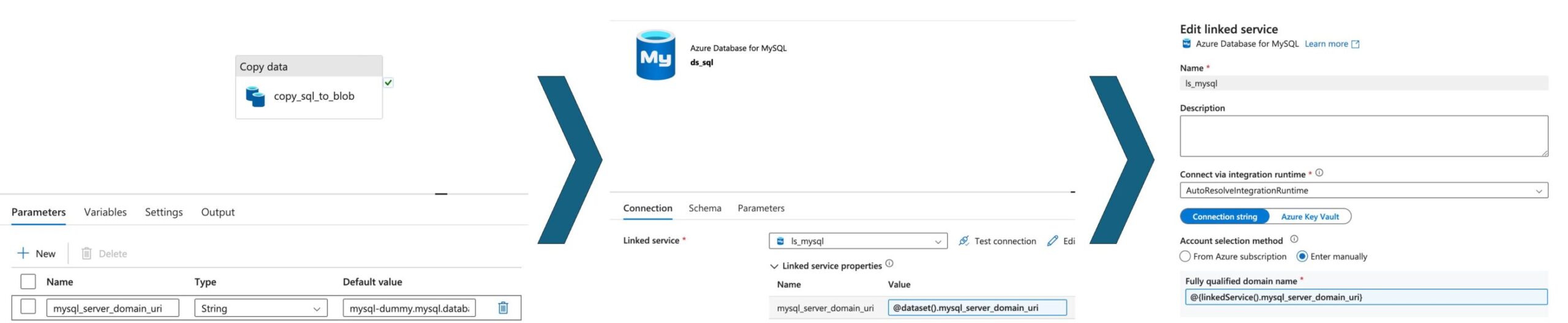
Übergabe von Parametern: Pipeline -> Datensatz -> Verknüpfter Dienst
In einer vollständig parametrisierten Datenpipeline können Parameter nahtlos von der Pipeline-Ebene zu Datensätzen und verknüpften Diensten fließen. Diese hierarchische Parameterübergabe stellt sicher, dass sich jede Pipeline-Komponente dynamisch an die Parameter anpassen kann, die zu Beginn der Pipeline-Ausführung bereitgestellt werden. Die Abbildung unten zeigt, wie der Parameter mysql_server_domain_uri an die Pipeline übergeben wird, die ihn an das Dataset weitergibt, das ihn am Ende des Linked Service verwendet, um eine Verbindung zum SQL-Server herzustellen.
Planen von Pipelines mit Terraform
Bisher haben wir uns mit bewährten Methoden der Codierung und deren Zusammenhang mit Parametern befasst. Jetzt, da wir wissen, wie man dynamische und wiederverwendbare Pipelines erstellt, ist es an der Zeit, sich mit deren Planung zu befassen. Die Planung von Pipelines erfolgt in ADF mit Hilfe von Triggern. Trigger sind Mechanismen, die die Ausführung von Datenpipelines auf der Grundlage bestimmter Bedingungen automatisieren, z.B. zu einem bestimmten Zeitpunkt.
Die Erstellung von Triggern für jeden Datensatz, insbesondere für mehrere Umgebungen, kann zeitaufwändig und fehleranfällig sein, wenn Sie nur die ADF-GUI verwenden. Die Aufrechterhaltung der Konsistenz zwischen den Umgebungen wird zur Herausforderung, und aufgrund des klickbasierten Entwicklungsansatzes können schnell Fehler auftreten.
In diesem Blog zeigen wir Ihnen, wie Sie diese Trigger mit Terraform anstelle der ADF-GUI erstellen können. Einige Vorteile der Verwendung von Terraform gegenüber der GUI sind:
Konsistenz: Terraform-Skripte stellen sicher, dass Ihre Infrastruktur in verschiedenen Umgebungen (Entwicklung, Test, Produktion) konsistent eingesetzt wird.
Versionskontrolle: Mit Terraform können Ihre Infrastrukturkonfigurationen in Versionskontrollsystemen wie Git gespeichert werden, was es einfacher macht, Änderungen zu verfolgen, mit Teammitgliedern zusammenzuarbeiten und bei Bedarf zu früheren Versionen zurückzukehren.
Reproduzierbarkeit: Mit Terraform können Sie den Bereitstellungsprozess automatisieren und so den Zeit- und Arbeitsaufwand für die Einrichtung und Konfiguration von ADF-Pipelines in verschiedenen Umgebungen reduzieren.
Benutzerfreundlichkeit mit YAML-Dateien: ADF-Trigger können mithilfe von YAML-Dateien definiert werden, wodurch die Konfiguration auch für weniger technisch versierte Teammitglieder zugänglich wird. Das menschenlesbare Format von YAML vereinfacht die Einrichtung und Änderung von Triggern und ermöglicht es Teammitgliedern ohne tiefgreifende technische Kenntnisse, Datenquellen hinzuzufügen.
Anforderungen
- Kenntnisse von Terraform
- Terraform authentifiziert für Ihre Azure-Umgebung
- Eine parametrisierte ADF-Pipeline
Wie funktioniert das?
Terraform wird für die Bereitstellung und Verwaltung der Trigger in einer Azure Data Factory verwendet. Die Datei main.tf ( hier beschrieben) wird verwendet, um:
- Lesen Sie die Trigger-Konfigurationen aus den
trigger_info.yamlDateien wie hier beschrieben - Erstellen Sie Azure Data Factory-Trigger-Objekte basierend auf der Konfiguration
Die Bereitstellung kann lokal oder mit einem Automatisierungstool wie Github Actions oder Azure DevOps erfolgen.
Erstellen einer trigger_info.yaml
Für jede Datenquelle und für jede Umgebung dieser Datenquelle, für die Sie Daten abrufen möchten, muss eine trigger_info.yaml Datei erstellt werden.
In dieser yaml finden Sie alle Informationen, die Sie zum Erstellen Ihres Pipeline-Triggers benötigen, wie in diesem Beispiel unten gezeigt:
pipeline_name: pl_sql_to_blob
schedule:
frequency: Day
interval: 1
hours: [3]
datastore_parameters:
mysql_server_domain_uri: 'mysql-dummy.mysql.database.azure.com'
database_username: 'dummy_username'
storage_account_name: 'sa_dummy'
container: 'adf-triggers-blog'
key_vault_uri: 'https://kv-playground-ra.vault.azure.net/'
key_vault_sql_database_password_secret_name: 'mysql-dummy-password'
datasets:
- name: hr_contracts
dataset_parameters:
database: 'hr'
table: 'contracts'
- name: hr_employees
dataset_parameters:
database: 'hr'
table: 'employees'
Die Datei besteht aus mehreren verschiedenen Teilen:
pipeline_name: Der Name der Pipeline in Azure Data Factory (ADF), für die Sie Auslöser erstellen möchten.
schedule: Gibt die Häufigkeit (z.B. Tag oder Stunde) an, mit der der Trigger ausgeführt werden soll, einschließlich des Intervalls und der Uhrzeit der Ausführung. Diese Einstellungen gelten allgemein für alle Pipelines und sind nicht von pipeline-spezifischen Parametern abhängig.
datastore_parameters: Enthält spezifische Parameter für den Datenspeicher. Da diese Parameter von allen Datenspeichern gemeinsam genutzt werden, müssen sie nur einmal definiert werden. Beachten Sie, dass wir hier keine Geheimnisse direkt speichern, sondern nur einen Geheimnamen für ein Geheimnis, das aus einem Schlüsseltresor abgerufen werden soll.
datasets: Dieses Feld enthält datensatzspezifische Informationen. Der in unserem Beispiel verwendete SQL Server enthält die Datenbank und die Tabelle.
Hinweis: Die Zeitplaneinstellungen sind für alle Pipelines gleich, aber die datastore_parameters und dataset_parameters sind pipelinespezifisch. Zusammen müssen diese beiden Parameter alle für eine Pipeline erforderlichen Parameter enthalten.
Verarbeitung der Trigger_info in main.tf
Nun, da wir unsere Trigger in der Datei trigger_info.yaml definiert haben, ist es an der Zeit, diese Informationen zu verarbeiten und in tatsächliche ADF-Trigger umzuwandeln. Die Verarbeitung findet in der Datei
locals {
time_zone = "W. Europe Standard Time"
// Retrieve datastore configurations from YAML files
datastore_configs = {
for filename in fileset("env/${var.env_path}/datastores/*/", "*.yml") :
filename => yamldecode(file("env/${var.env_path}/datastores/*/${filename}"))
}
// Generate triggers based on datastore configurations
triggers = merge(flatten([
for filename, datastore in local.datastore_configs : [
for dataset in datastore.datasets : {
"${datastore.pipeline_name}_${dataset.dataset_parameters.database}_${dataset.dataset_parameters.table}" = {
"pipeline_name" = datastore.pipeline_name
"schedule" = datastore.schedule
"datastore_parameters" = datastore.datastore_parameters
"dataset_parameters" = dataset.dataset_parameters
}
}
]
])...)
}
// Retrieve the Azure Data Factory resource
data "azurerm_data_factory" "this" {
name = var.adf_name
}
// Create triggers based on the generated triggers
resource "azurerm_data_factory_trigger_schedule" "this" {
for_each = local.triggers
name = each.key
data_factory_id = data.azurerm_data_factory.this.id
time_zone = local.time_zone
interval = each.value.schedule.interval
frequency = each.value.schedule.frequency
schedule {
hours = lookup(each.value.schedule, "hours", [0])
minutes = lookup(each.value.schedule, "minutes", [0])
}
pipeline {
name = each.value.pipeline_name
parameters = merge([
each.value.datastore_parameters,
each.value.dataset_parameters
]...)
}
}
Erläuterung der verschiedenen Abschnitte:
Locals block: Im Block locals werden Konfigurationen aus YAML-Dateien in einsatzfähige Trigger verarbeitet. Der Name des Auslösers wird implizit auf der Grundlage mehrerer Parameter festgelegt, um eine einheitliche Benennung aller Auslöser zu gewährleisten. Wenn Sie jedoch den Triggernamen zu einem expliziten Feld in der Konfigurationsdatei machen, könnte dies die Identifizierung und Verwaltung von Trigger-Konfigurationen vereinfachen.
Data block: Im Datenblock rufen wir die Informationen der ADF-Ressource ab, die verwendet werden soll.
Resource block: Der Ressourcenblock spezifiziert die Erstellung von Ressourcen, in diesem Fall von geplanten Triggern in Azure Data Factory. Er verwendet lokale Variablen und abgerufene Daten, um jeden Trigger dynamisch zu konfigurieren und zu erstellen, wobei Parameter wie Name, Zeitplan und Pipeline-Details festgelegt werden.
Nachdem Sie alles eingerichtet haben, können Sie die Trigger mit dem regulären Terraform-Plan erstellen und anwenden.
Zusammenfassung
In diesem informativen Blog-Beitrag haben wir die leistungsstarke Kombination von Azure Data Factory (ADF) und Terraform zur Optimierung der Dateneingabe untersucht. Wir haben ein Setup vorgestellt, das die potenziellen Ineffizienzen des klickbasierten Entwicklungsansatzes in ADF behebt und eine effizientere Methode unter Verwendung von Parametern und Triggern bietet, die von Terraform erstellt werden. Unser Ziel ist es, eine Lösung bereitzustellen, die sich an Best Practices orientiert, die Entwicklungszeiten beschleunigt und auch nicht-technische Benutzer in die Lage versetzt, effektiv mitzuarbeiten.
Verfasst von
Rik Adegeest
Rik is a dedicated Data Engineer with a passion for applying data to solve complex problems and create scalable, reliable, and high-performing solutions. With a strong foundation in programming and a commitment to continuous improvement, Rik thrives on challenging projects that offer opportunities for optimization and innovation.




Contact