Blog
Vereinfachen Sie Ihre Workflow-Bereitstellung mit Databricks Asset Bundles: Teil I

Databricks ist jetzt die erste Wahl für Datenteams. Seine benutzerfreundliche, kollaborative Plattform vereinfacht die Erstellung von Datenpipelines und maschinellen Lernmodellen. Die programmgesteuerte Bereitstellung dieser Workflows in der Produktion kann jedoch eine Herausforderung sein. Viele Datenexperten, mich eingeschlossen, haben sich mit verschiedenen Strategien für die Bereitstellung und das Ressourcenmanagement auseinandergesetzt. Ich habe verschiedene Ansätze erforscht. Sie reichen von benutzerdefinierten Python-Paketen, die die Databricks CLI und API verwenden, bis hin zu einer Mischung aus Bash-Skripten und dbx (einem früheren Tool für Databricks). Diese Vielfalt wirft mehrere Fragen auf: Welche Teile der Infrastruktur sollten in die Anwendung aufgenommen werden? Wie konfigurieren wir anwendungsspezifische Ressourcen? Wie können wir Implementierungen in Entwicklungs-/Produktionsumgebungen isolieren? Wie gehen wir mit mehreren Bereitstellungszielen um? Anstatt uns auf unsere Kernanwendungen zu konzentrieren, steuern wir oft einen Mix aus Tools und benutzerdefiniertem Code, der ständige Aufmerksamkeit erfordert.
In den nächsten Blog-Beiträgen möchte ich Ihnen Databricks Asset Bundles (DABs oder Bundles) als eine neue Möglichkeit der Bereitstellung auf Databricks vorstellen:
-
Zunächst werden wir DABs vorstellen, ihre Vorteile erläutern und ihren Lebenszyklus anhand eines Beispiels zeigen. Außerdem werden wir Gemeinsamkeiten und Unterschiede zwischen DABs und Terraform als Tools für die Verwaltung von Infrastrukturen diskutieren.
-
Dann werden wir uns mit Bundles beschäftigen und Ihnen zeigen, wie Sie diese nutzen können, um sie an die Bedürfnisse Ihres Projekts anzupassen.
-
Schließlich möchte ich noch einen Schritt weitergehen und zeigen, wie Sie es in Ihre CI/CD-Pipelines integrieren können.
Databricks Asset-Bündel: Was
Databricks Asset Bundles sind eine Möglichkeit, Projekteinstellungen, Ressourcen, Umgebungen und Artefakte in einem einfachen, einheitlichen Format zu definieren. DABs helfen uns bei der Übernahme von Best Practices in der Softwareentwicklung und bei der reibungslosen Integration mit CI/CD-Tools.
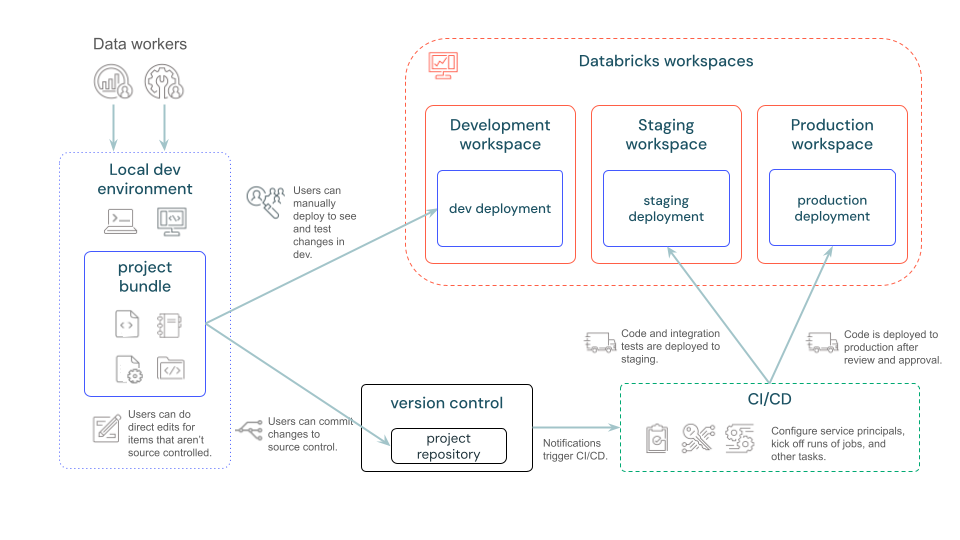 Quelle: https://docs.databricks.com/en/dev-tools/bundles/index.html
Quelle: https://docs.databricks.com/en/dev-tools/bundles/index.html
Das obige Diagramm veranschaulicht, wie Bundles mit Databricks-Ressourcen und CI/CD-Tools interagieren, um den Lebenszyklus der Entwicklung zu erleichtern. Ganz allgemein gesprochen:
-
Projekt-Bündel: Code und Ressourcenkonfiguration befinden sich in einem einzigen Repository. Die Ressourcen werden in einem lesbaren Format (YAML-Dateien) definiert.
-
Data Worker können ihre Ressourcen in einem Entwicklungsarbeitsbereich bereitstellen, um ihre Anwendung zu testen.
-
Nach dem Testen können Sie Ihr Bundle in eine CI/CD-Pipeline integrieren, um es in einer Produktionsumgebung einzusetzen. Sie können auch von Ihrem lokalen Rechner aus in die Produktion einsteigen, wenn Sie möchten.
Vor DABs mussten Sie verschiedene Databricks CLI-Befehle und API-Aufrufe verwenden. Außerdem mussten Sie json Dateien für Auftragsressourcen konfigurieren. Alternativ konnten Sie die Bereitstellung auch manuell vornehmen, aber das war fehleranfällig und langfristig schwer zu pflegen. Lassen Sie uns nun anhand eines Beispiels sehen, wie Bundles die Bereitstellung in einer einzigen Befehlszeilenschnittstelle zentralisieren.
Databricks Asset-Bündel: Wie
Wir werden an einem Demo-Anwendungsfall arbeiten, um die Leistungsfähigkeit von Bundles zu zeigen. Ich hoffe, dass ich Ihnen die wichtigsten Funktionen der Bundles zeigen kann und wie sie die Entwicklung und Bereitstellung auf Databricks vereinfachen.
Sie müssen eine App für die Datenaufnahme erstellen. Sie soll Daten aus einer bestimmten Quelle lesen und sie in Ihren Data Lake schreiben. Sie entwickeln eine Python-Anwendung, die dynamische Parameter akzeptiert, um dies programmatisch zu bewerkstelligen.
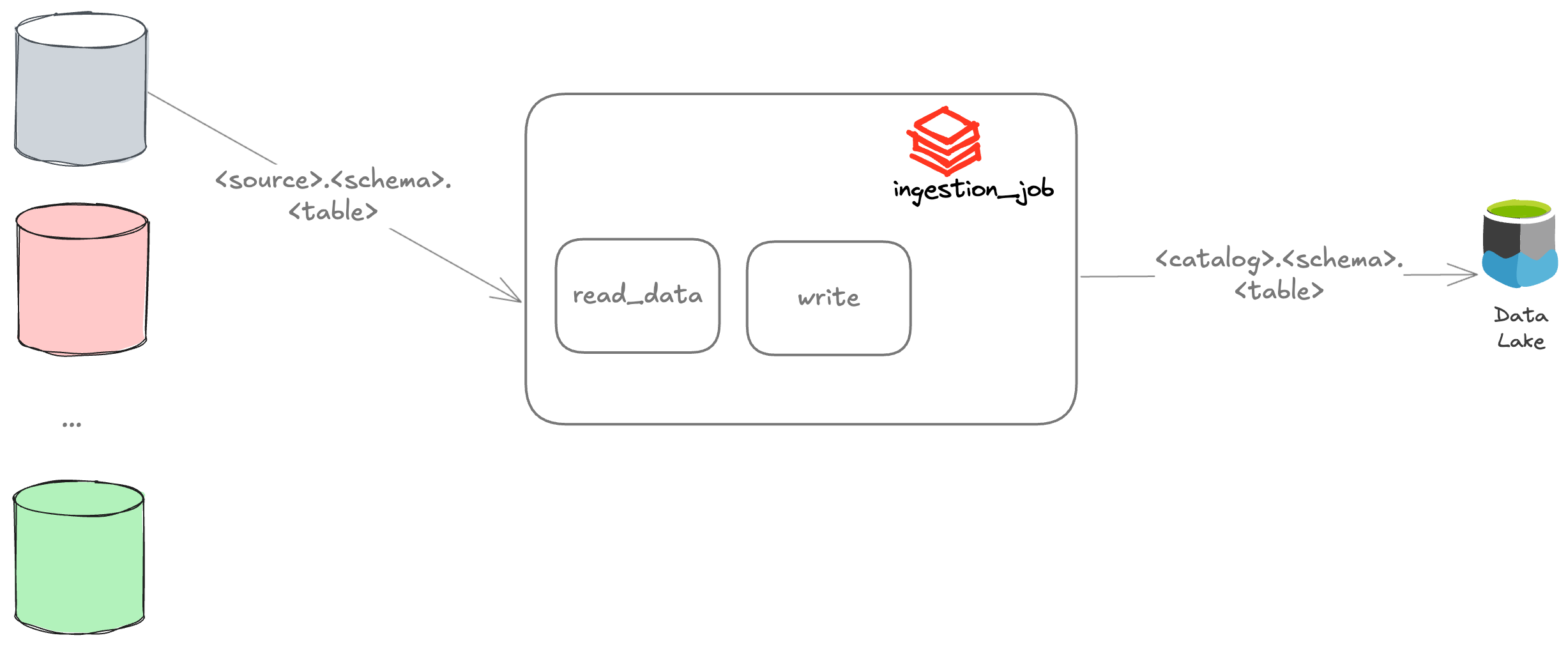
Ihre Anwendung ruft Daten aus der externen Quelle ab, z.B. Schema und Tabellennamen. Anschließend wird sie in Ihren Data Lake schreiben.
Ihre Aufgabe benötigt die folgenden Parameter als Eingabe:
- input_source
- input_schema
- input_table
- output_catalog
- output_schema
- output_table
Sie haben Ihren Code entwickelt und möchten nun Ihre Anwendung testen und schließlich mit Hilfe von Databricks-Jobs bereitstellen.
Lebenszyklus eines Pakets
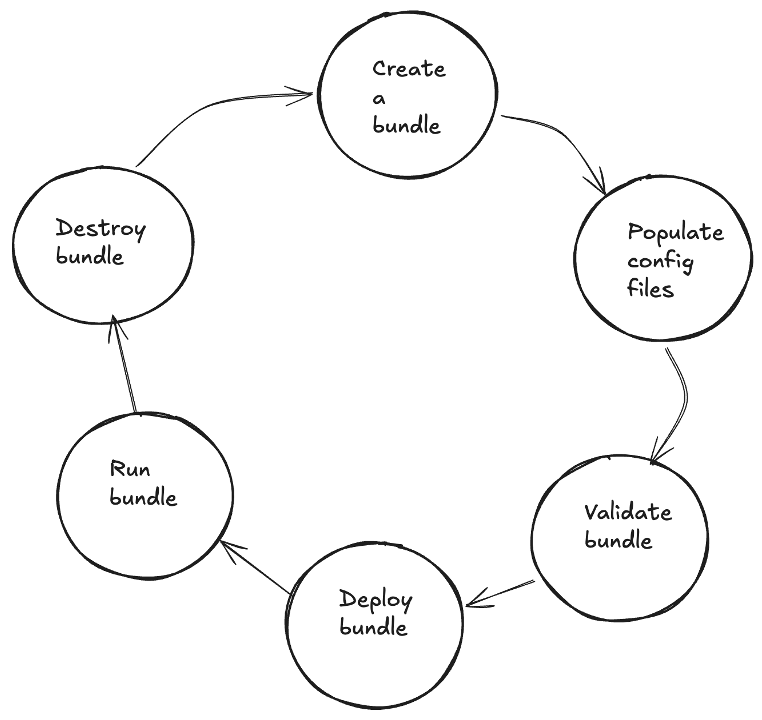
Schritt 1: Erstellen Sie ein Bündel
Als Erstes müssen Sie eine Bundle-Datei-Konfiguration erstellen. Das können Sie auf zwei Arten tun, entweder über die Befehlszeile oder durch die manuelle Erstellung einer YAML-Datei.
Von Databricks CLI aus können Sie dies tun:
databricks bundle init
Bei dieser Option stehen Ihnen einige integrierte Vorlagen zur Verfügung. Sie können jedoch auch manuell eine YAML-Datei erstellen oder eine der vielen Vorlagen aus dem Databricks-Repository auswählen.
Für unseren Anwendungsfall werden wir die Vorlage python_wheel_poetry aus dem Repository wählen, die Poetry zum Erstellen Ihrer Python-Anwendung und zur Verwaltung von Abhängigkeiten verwendet. Wenn Sie mehr über Poetry erfahren möchten, schauen Sie sich die offizielle Dokumentation an.
Schritt 2: Konfigurieren Sie ein Bundle
Alles beginnt mit der Datei databricks.yml. Dies ist der zentrale Ort, an dem Ihre gesamte Projektkonfiguration definiert wird. Sie darf nur einmal in Ihrer Projektstruktur vorhanden sein. Für unseren Anwendungsfall ist dies die Anfangskonfiguration:
bundle:
name: ingestion_demo
include:
- ./resources/ingestion_job.yml
artifacts:
default:
type: whl
build: poetry build
path: .
targets:
dev:
default: true
mode: development
workspace:
host: https://adb-xxxxxxxxx.x.azuredatabricks.net/
Es gibt eine Top-Level-Mapping-Syntax, die einige Hauptkomponenten definiert:
bundle: Hier legen Sie allgemeine Einstellungen für das Bundle fest, z.B. den Bundle-Namen.include: Eine Liste von Pfadkugeln, in die Ihre Ressourcen eingefügt werden sollen (wir werden die Ressourcen in Kürze besprechen)artifacts: Welche Artefakte werden mit dem Bundle verteilttargets: Für welche Umgebungen Sie bereitstellen und welche spezifischen Konfigurationen Sie während der Bereitstellung vornehmen.
Diese zentrale Datei legt fest, wie und wo wir die Ressourcen bereitstellen, aber uns fehlt das, was wir bereitstellen, nämlich die Auftragsdefinition selbst. Für unseren Anwendungsfall wäre das so:
resources:
jobs:
ingestion_job: # unique identifier of job resource beind deployed
name: ingestion_job
tasks:
- task_key: main
python_wheel_task:
package_name: ingestion
entry_point: ingestion
named_parameters:
input_source: mysql
input_schema: foo_schema
input_table: foo_table
output_catalog: bar_catalog
output_schema: bar_schema
output_table: bar_table
libraries:
- whl: ../dist/*.whl
new_cluster:
node_type_id: Standard_DS3_v2
num_workers: 1
spark_version: 15.3.x-cpu-ml-scala2.12
Wir beginnen mit der Definition eines Schlüssels namens resources, gefolgt von der Ressource selbst, die wir bereitstellen möchten, in diesem Fall: ein Job-Workflow und die dazugehörigen Aufgaben. Die Aufgabe heißt main und erhält die zuvor genannten Parameter. Außerdem definieren wir am Ende der Datei die minimale Clusterkonfiguration, die unser Job verwenden wird, um die angegebenen Aufgaben auszuführen.
Schritt 3: Ein Bundle validieren
Als Nächstes werden wir unsere Bundle-Konfiguration mit dem folgenden Befehl validieren:
databricks bundle validate
Ausgänge:
# Name: ingestion_demo
# Target: dev
# Workspace:
# Host: https://adb-1065999601799872.12.azuredatabricks.net/
# User: victor.deoliveira@xebia.com
# Path: /Workspace/Users/victor.deoliveira@xebia.com/.bundle/ingestion_demo/dev
# Validation OK!
Wenn Sie sich nicht bei Ihrem Databricks-Arbeitsbereich authentifiziert haben, wird ein Fehler angezeigt. Dann müssen Sie sich mit dem in der Ausgabe angegebenen Befehl authentifizieren.
Bei dieser Validierung wird geprüft, ob die YAML-Syntax korrekt ist und ob das Schema unseres Bundles gültig ist, d.h. ob die Feldzuordnungen an der richtigen Stelle stehen und den richtigen Typ haben. Um das Bundle-Schema zu generieren, können Sie Folgendes ausführen:
databricks bundle schema > bundle_config_schema.json
Tipp: Wenn Sie die folgende Zeile:
# yaml-language-server: $schema=../bundle_config_schema.jsonam Anfang Ihrer DABs-Dateien einfügen, können Sie die erwarteten Typen und Felder über Ihre IDE überprüfen.
Die Validierung ist ein netter zusätzlicher Überprüfungsschritt zur Vermeidung von Fehlern in Produktionsumgebungen, aber auch während der Entwicklung, wo Sie Probleme erkennen können, bevor Sie tatsächlich versuchen, den Code auf der Databricks-Seite auszuführen.
Schritt 4: Verteilen Sie ein Bundle
Dann stellen wir unser Bundle bereit, indem wir es ausführen:
databricks bundle deploy
Ausgänge:
# Building default...
# Uploading ingestion-0.2.0-py3-none-any.whl...
# Uploading bundle files to /Workspace/Users/victor.deoliveira@xebia.com/.bundle/ingestion_demo/dev/files...
# Deploying resources...
# Updating deployment state...
# Deployment complete!
Auf dem Arbeitsbereich können Sie den verteilten Auftrag überprüfen:
Im Moment haben wir nur ein Ziel, das standardmäßig in unserem Arbeitsbereich dev (Entwicklung) bereitgestellt wird. Standardmäßig werden alle Dateien unter dem Benutzer bereitgestellt, der den Bereitstellungsbefehl ausgeführt hat. In meinem Fall finde ich ihn unter: /Workspace/Users/victor.deoliveira@xebia.com/.bundle/ingestion_demo/dev/.
Beachten Sie, dass Bundles von Haus aus eine Isolierung der Bereitstellung ermöglichen. Sie tun dies, indem sie Ihre Ressourcen unter dem Benutzerordner workspace bereitstellen und ein Präfix zu Ihrem bereitgestellten Auftrag hinzufügen. Im zweiten Teil unserer Serie werden wir Ihnen mehr Informationen dazu geben.
In Ihrer Ordnerstruktur können Sie dann drei Unterordner finden:
- Artefakte: Artefakte für Ihr Projekt. In unserer Demo enthält es die
.whlDateien, die sich auf unser Python-Rad-Paket beziehen, das bereitgestellt wird. - Dateien: Alle relevanten Dateien, die mit dem Projekt bereitgestellt werden. Da wir keine Dateien ausgeschlossen haben, werden alle Projektdateien mit dem Arbeitsbereich synchronisiert.
- Zustand: Unter der Haube führt Bundles den Terraform-Code aus. Daher finden Sie hier die Terraform-Statusdatei.
Was tun Sie, sobald Ihr Auftrag bereitgestellt ist? Sie sind bereit, Ihre Anwendungslogik auszuführen und zu testen.
Schritt 5: Führen Sie ein Bundle aus
Sie können verteilte Aufträge auch einfach über die Bundles-Klammer ausführen:
databricks bundle run ingestion_job
Tipp: Der Befehl
runverfügt über die Option--validate-only, die nützlich sein kann, um Ihre logische Anwendung zu testen, ohne die Tabelle tatsächlich zu laden. Es wird nach Schemanamen, Tabellen und Spalten gesucht, ohne die Daten zu laden.
Schritt 6: Ein Bündel zerstören
Schließlich können Sie alle Aufträge, Pipelines und Artefakte zerstören, die durch einfaches Ausführen bereitgestellt wurden:
databricks bundle destroy
Wenn Sie ein Bundle zerstören, werden die zuvor bereitgestellten Aufträge, Pipelines und Artefakte des Bundles dauerhaft gelöscht. Diese Aktion kann nicht rückgängig gemacht werden.
In unserem Fall wird es sowohl den bereitgestellten Auftrag als auch die erstellten Ressourcenordner löschen.
Wir haben das Ende des Lebenszyklus von Bundles erreicht. In wenigen Schritten können Sie den Code auf Ihrem Rechner ausführen, um Ihre Anwendung auf Databricks zu testen. Dies gibt Ihnen mehr Sicherheit, Ihre Änderungen in die Produktion zu übertragen, da Sie sie von Anfang bis Ende getestet haben.
Sind DABs ein Ersatz für Terraform Code?
Wenn Sie mit Terraform vertraut sind, ist Ihnen wahrscheinlich die Ähnlichkeit der Befehle validate, deploy und destroy mit den Befehlen in Terraform aufgefallen. Der Grund dafür ist, dass DABs, wie wir gesehen haben, Terraform-Code hinter den Kulissen ausführen. Dann stellt sich natürlich die Frage: Welche Teile unserer Infrastruktur sollten in Terraform bleiben und welche in Databricks Asset Bundles?
Ein wichtiger Aspekt bei der Einführung eines neuen Tools ist es, dessen Zweck und Grenzen zu verstehen. Aus Databricks offizieller Bundles-Dokumentation:
"Databricks Assets Bundles sind ein Infrastructure-as-Code (IaC) Ansatz zur Verwaltung Ihrer Databricks-Projekte."
Wie in Alex' Beitrag Terraform vs. Databricks Asset Bundles erläutert, verwalten Bundles Ressourcen auf Projektebene. Außerdem vereinfachen sie die Bereitstellung über mehrere Umgebungen hinweg. Die gesamte High-Level-Infrastruktur, wie z.B. Workspaces, Metastore, Kataloge und Cloud-Ressourcen, sollte über Terraform und nicht über Bundles verwaltet werden. Dies gilt auch für die Zugriffskontrolle auf diese Objekte.
In unserem Fall sehen wir, dass ein Arbeitsbereich, ein Katalog und ein persönlicher Rechencluster außerhalb von Bundles bereitgestellt werden sollten. In unserem Repository haben wir dann einen Job-Cluster für die Ausführung des Codes, die Umgebung für die Bereitstellung von Artefakten und Dateien und unsere Anwendung selbst, ein Python-Radpaket, definiert. Wir können auch Berechtigungen auf Projektebene verwalten.
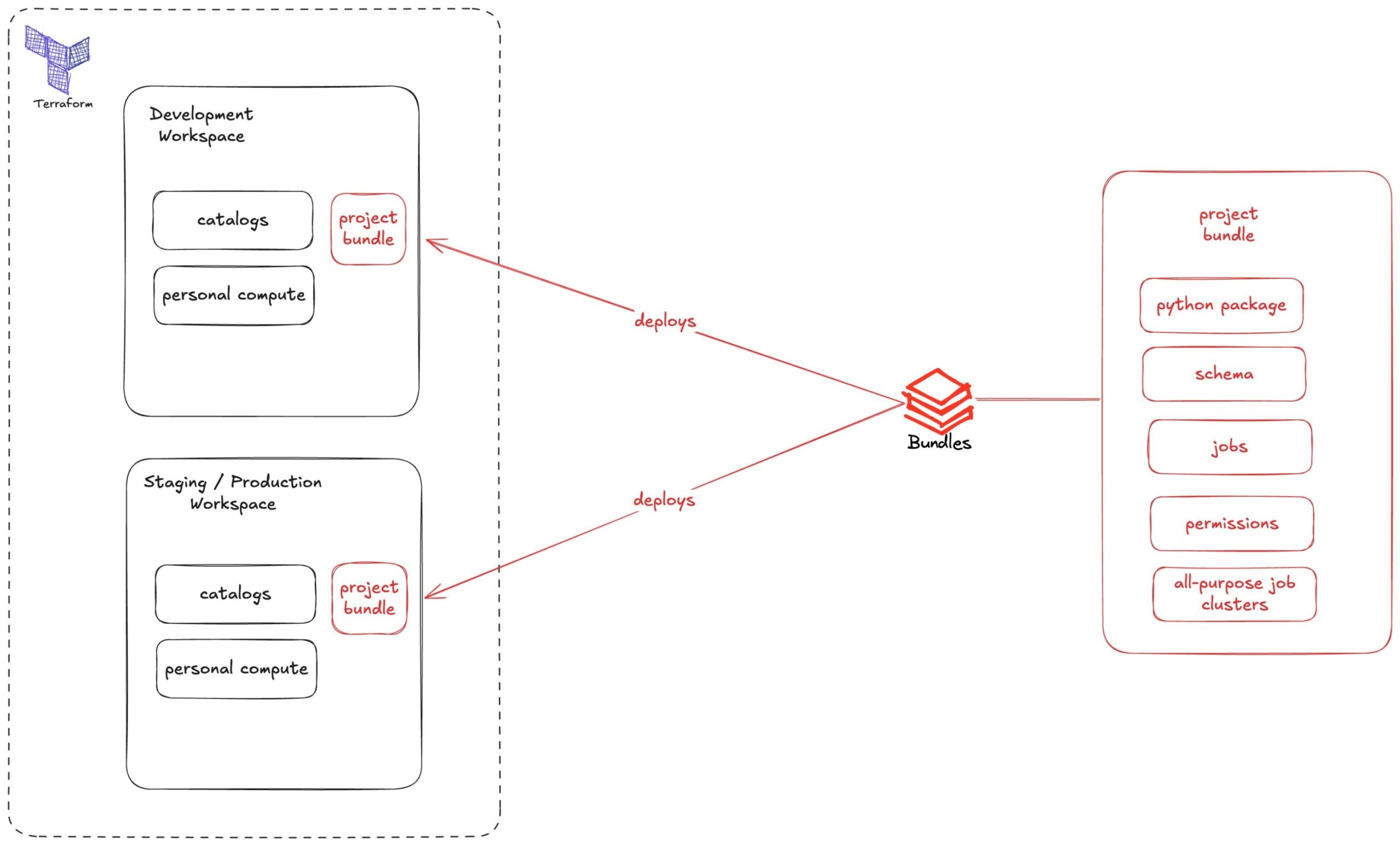
In dem obigen Diagramm sehen wir, dass Bundles ein kleineres Stück Logik sind, das alle Abhängigkeiten Ihres Projekts darstellt und wie es mit den von Terraform bereitgestellten Ressourcen wie verschiedenen Arbeitsbereichen und Katalogen interagiert.
Fazit
In diesem ersten Teil der Serie haben wir Databricks Asset Bundles vorgestellt. Sie sind ein wichtiges Werkzeug für Datenexperten. Sie helfen dabei, die Entwicklung zu rationalisieren und gleichzeitig bewährte Softwarepraktiken zu befolgen. Wir zeigen Ihnen, wie Sie mit ein paar YAML-Dateien und ein paar CLI-Befehlen ganz einfach ein Projekt einrichten können, um alle Ihre auftragsspezifischen Ressourcen und Konfigurationen zu initiieren, zu validieren, bereitzustellen, auszuführen und schließlich zu zerstören. Wir haben auch besprochen, welche Teile Ihrer Infrastruktur von Terraform und welche von DABs verwaltet werden sollten. Im nächsten Teil dieser Serie erfahren Sie, wie Bundles die Isolierung der Bereitstellung vereinfachen, wie Sie Ihren eigenen Cluster nutzen können, um Ihre Jobläufe während der Entwicklung zu beschleunigen, wie Sie Ressourcen über Jobs hinaus hinzufügen können, z.B. Schemas oder MlFlow-Experimente, wie Sie Voreinstellungen verwenden, um die Jobbereitstellung pro Ziel anzupassen und wie Sie benutzerdefinierte Variablen verwenden können, um die Fähigkeiten von Bundles zu erweitern und an die Bedürfnisse Ihres Projekts anzupassen. In der Zwischenzeit lade ich Sie ein, DABs zu erkunden und sie in Ihren Projekten zu testen.
Verfasst von
Victor De Oliveira
I appreciate feedback: https://www.linkedin.com/in/victor-de-oliveira-b0634449/
Unsere Ideen
Weitere Blogs




Contact