In einem früheren Blog haben wir eine neuartige Methode für die Software-Qualitätssicherung für refaktorisierten Code beschrieben, der bereits in der Produktion läuft, inspiriert von dem Ansatz Scientist, den GitHub 2016 veröffentlicht hat. In diesem Blog erklären wir, wie wir diese QA-Methode für das Testen von AWS Lambda-Funktionen implementiert haben und welche Erfahrungen wir damit gemacht haben.
Das Endziel des Scientist-Ansatzes ist es, die überarbeitete Funktionalität mit Zuversicht zu veröffentlichen. Wie in dem anderen Beitrag erläutert, wird das Vertrauen dadurch gewonnen, dass sowohl die aktuelle Version der Funktionalität (die "Kontrolle") als auch eine neue Implementierung (der "Kandidat") in der Produktion ausgeführt werden und der Produktionsverkehr an beide gesendet wird. Bei dieser Vorgehensweise wird die "Kontroll"-Antwort an den Client zurückgeschickt, so dass der ursprüngliche Anfrager nicht merkt, dass im Hintergrund ein Experiment läuft. Durch den Vergleich der Antworten der Kontroll- und der Kandidatenversion (hinsichtlich ihrer Funktionalität, aber auch unter Berücksichtigung der Leistung, des Speicherverbrauchs usw.) können Sie eine fundierte Entscheidung darüber treffen, ob die Kandidatenversion in die neue Produktionsversion übernommen werden soll.
Die Implementierung des Scientist-Ansatzes auf GitHub wurde in Ruby entwickelt und es gibt alternative Implementierungen für viele andere Sprachen. Es fehlte eine Alternative für die Anwendung des Scientist-Ansatzes auf AWS Lambdas oder andere serverlose Plattformen. Hier kommt Serverless Scientist ins Spiel, eine Implementierung von Scientist für AWS Lambdas. Wie der Name schon andeutet, haben wir vor, dies auch für andere serverlose Implementierungen wie Google Functions und Microsoft Azure Functions zu implementieren.
Anforderungen für Serverless Scientist
Die Beschreibung im vorigen Blog lässt sich in eine Reihe von Fähigkeiten für eine Serverless Scientist-Implementierung übersetzen. Sie muss das Folgende unterstützen:
- Führen Sie Experimente durch: Führen Sie Kontrollen und (möglicherweise mehrere) Kandidaten unter Verwendung des Produktionsverkehrs in einer Produktionsumgebung durch.
- Vergleichen Sie die Ergebnisse der Kontrolle und des Kandidaten, um Rückschlüsse auf die Qualität eines Kandidaten zu ziehen.
- Leiten Sie den Datenverkehr mühelos und ohne Ausfallzeiten an einen oder mehrere Kandidaten weiter.
- Keine spürbaren Auswirkungen für Endverbraucher, wenn Sie ein Experiment aufrufen, Kandidaten in einem Experiment hinzufügen oder entfernen oder die Implementierung eines Kandidaten verbessern.
- Es sind keine Änderungen an der Steuerung erforderlich, um das Testen durch Experimente zu ermöglichen.
- Keine anhaltende Wirkung von Kandidaten in Produktionsdaten (d.h. Kandidaten dürfen Produktionsdaten nicht aktualisieren).
Übrigens, bei "Keine Änderung der Kontrolle erforderlich" versagen, wie erklärt, einige andere Methoden.
Serverlose Implementierung von Scientist
Alle Details zur Implementierung des Serverless Scientist finden Sie im Code Repository. Das folgende Diagramm veranschaulicht den Aufbau des Serverless Scientist. Der Serverless Scientist befindet sich zwischen dem Client und der "Control"-Funktion und besteht aus zwei Lambda-Funktionen. Die Lambda-Funktion "Scientist" ist dafür zuständig, Anfragen vom Client zu empfangen, sie an die Steuerung weiterzuleiten und die Antwort so schnell wie möglich an den Client zurückzugeben. (In diesem Blog erfahren Sie, wie wir die durch den Scientist verursachte Latenz minimiert haben). Darüber hinaus speichert die Lambda-Funktion die Ergebnisse des Kontrollaufrufs in DynamoDB und ruft asynchron die Experimentor Lambda-Funktion auf. Um zu wissen, welche Experimente ausgeführt werden sollen und wo die Kontrolle und die Kandidaten zu finden sind, stützt sich die Scientist Lambda-Funktion auf eine YAML-Datei in einem AWS S3-Bucket.
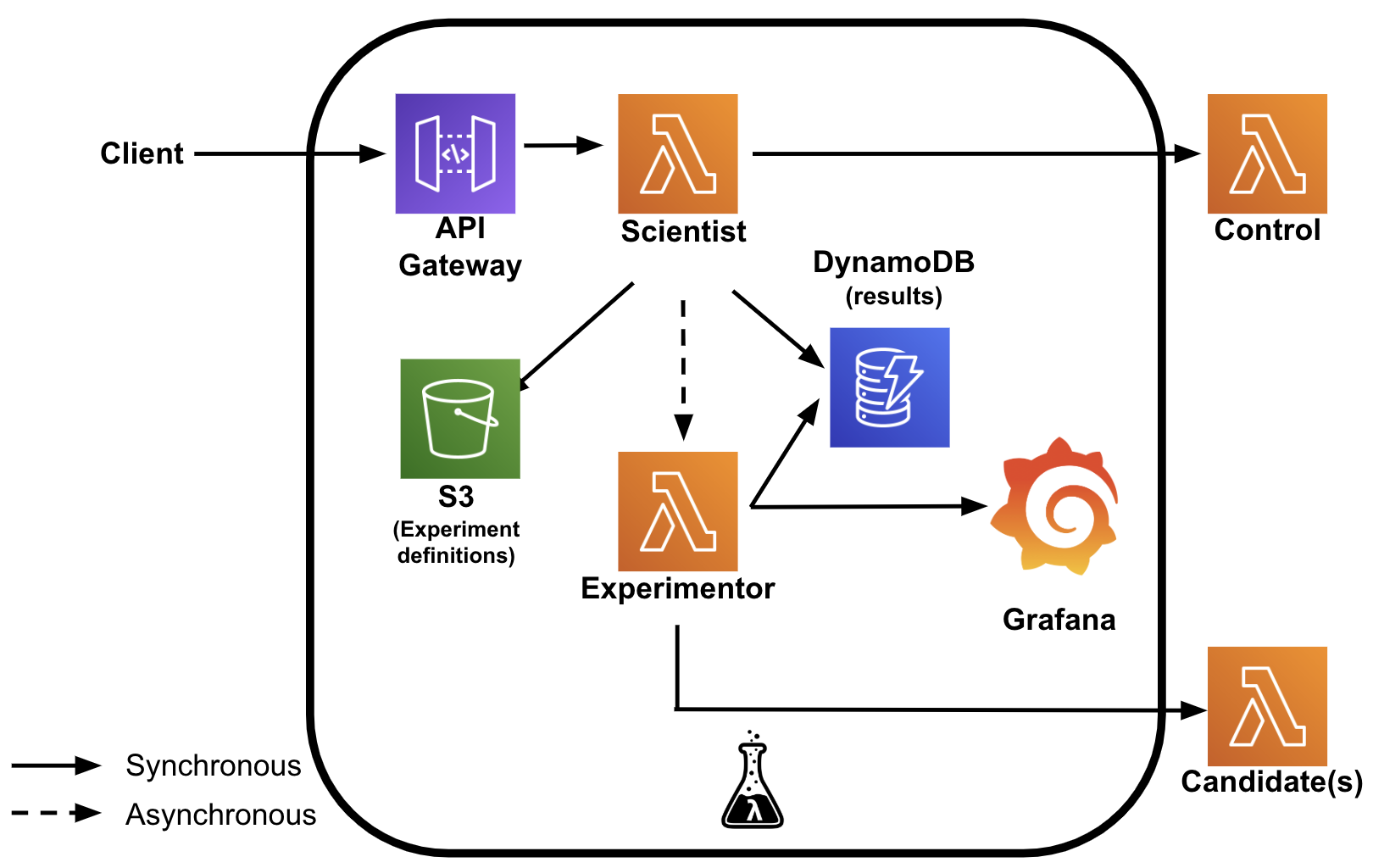
Die Experimentor Lambda-Funktion ruft alle Kandidaten auf, vergleicht ihre Antworten mit den Kontrollantworten und speichert die Ergebnisse in einem DynamoDB-Datenspeicher. Der Experimentor stellt die Ergebnisse der Vergleiche auch in Grafana zur Verfügung. Im Grafana-Dashboard können Sie die Ergebnisse des Vergleichs zwischen der Kontrolle und dem/den Kandidaten in Bezug auf Aspekte wie:
- Antwortstatuscodes, Antwortkörper und Kopfzeilen;
- Reaktionszeiten und Speichernutzung.
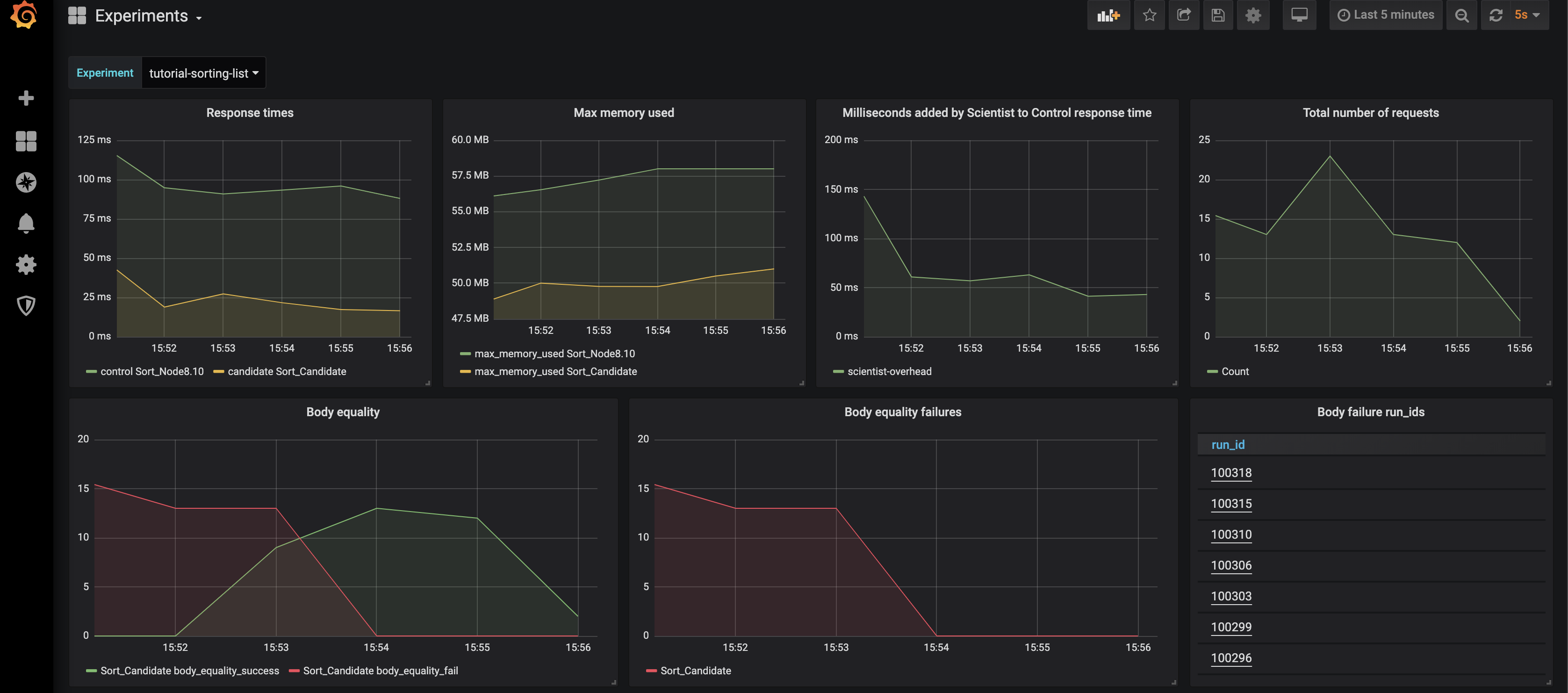
Der Screenshot unten ist ein Beispiel für das Dashboard. In der oberen Zeile erhalten Sie einen Einblick in die Antwortzeiten und die Speichernutzung der Kontrolle und der Kandidaten, die vom Wissenschaftler hinzugefügte Latenz und die Gesamtzahl der Anfragen. Die 2. Zeile zeigt die Ergebnisse des Vergleichs des Antwortkörpers des/der Kandidaten mit dem der Kontrolle. Ganz rechts stehen die IDs der Experimentierläufe mit Fehlschlägen. Wenn Sie auf diese klicken, gelangen Sie auf eine Seite, die den Unterschied zwischen Kontrolle und Antwort zeigt. Wie Sie um 15:54 Uhr sehen können, wurde eine neue Version bereitgestellt, die einen Fehler behebt. In diesem Screenshot nicht zu sehen, aber im Dashboard vorhanden, sind Vergleiche für HTTP-Header und Antwortcodes.
Learnings
Was haben wir also beim Einsatz des Serverless Scientist gelernt?
- Beim Wechsel der Implementierungssprache für eine Lambda-Funktion haben wir einen unerwarteten Unterschied zwischen den Sprachen festgestellt: Die Funktion round() in Python3 verhält sich bei Zahlen, die auf .5 enden, anders als round() in Python2.7 und Javascript.
- Es ist wichtig, das beabsichtigte Ergebnis (die Semantik der Antwort) zu vergleichen und nicht das wörtliche Ergebnis (seine Syntax). Ein Beispiel:
{"first": 1, "second": 2}und{"second": 2, "first": 1}sind semantisch gleich, unterscheiden sich aber, wenn Sie sie wörtlich vergleichen. - Wir waren in der Lage, schnell mit neuen Kandidatenversionen zu iterieren, ohne die Kunden in irgendeiner Weise zu beeinträchtigen. Das Grafana-Dashboard hat sich hier als sehr wertvoll erwiesen.
- Da wir echten Produktionsverkehr an die Kandidaten weiterleiteten, mussten wir keine Testfälle selbst erstellen. Es traten Randfälle auf, die wir selbst sicher nicht erkannt hätten und die wir beheben konnten.
Natürlich ist der (Serverless) Scientist-Ansatz kein Allheilmittel. Es gibt zahlreiche Situationen, in denen er weniger anwendbar ist, zum Beispiel, wenn:
- die Schnittstelle des Kandidaten ist nicht rückwärtskompatibel mit der Steuerung;
- es gibt nur einen begrenzten Produktionsverkehr (in diesem Fall ist die Abdeckung der Funktionen gering);
- es gibt keine Kontrolle, mit der Sie vergleichen können (z.B. ist es die erste Implementierung der Funktion);
- Die Leistungsanforderungen erlauben keine zusätzliche Latenzzeit durch den Aufruf eines Experiments. Bei unseren Messungen fügte die Platzierung des Serverless Scientist zwischen Client und Kontrolle eine zusätzliche Latenz von ~50 Millisekunden zu den Kontrollantworten hinzu. Dies ist möglicherweise nicht in allen Situationen akzeptabel;
- Kontrolle (und Kandidaten) schreibt dauerhafte Änderungen in einen Datenspeicher. Dies führt zu einer zusätzlichen Komplexität bei der Synchronisierung von Datenspeichern, da Sie auf keinen Fall möchten, dass Kandidaten den Produktionsdatenspeicher aktualisieren.
Was kommt als Nächstes?
Aber selbst mit den oben genannten Einschränkungen erwies sich der Einsatz von Serverless Scientist für uns als nützlich, als wir das Refactoring der /whereis #jeder?und wir planen, die Funktionalität des Serverless Scientist zu erweitern. Einige unserer Ideen dazu sind:
- feinere Vergleichsfunktionen - die Möglichkeit, verschiedene Antwortformate wie einfachen Text, HTML-Ausgabe, JSON-Objekte, PDF-Dateien und Bilder zu vergleichen;
- Verteilung des Datenverkehrs auf Kandidaten - die Möglichkeit, den Prozentsatz des Produktionsdatenverkehrs, der an eine Kandidatenfunktion gesendet wird, zu erhöhen oder zu verringern;
- einfachere Verwaltung von Experimenten - eine schöne Benutzeroberfläche zum Erstellen, Aktualisieren und Beenden von Experimenten, wobei die Experimentdaten in einer Datenbank statt in einer YAML-Datei in einem AWS S3-Bucket gespeichert werden;
- Unterstützung für generische API-Tests;
- benutzerdefinierte Endpunkte für die Berichterstattung über Metriken;
- bessere UI für den Vergleich von Ergebnissen;
- Unterstützung für andere FaaS-Plattformen wie Google Functions und Microsoft Azure Functions.
Nutzen Sie Serverless Scientist für Ihre Projekte und lassen Sie uns Ihre Erfahrungen wissen.
Verfasst von
Gero Vermaas
Unsere Ideen
Weitere Blogs

Wo die GitHub Copilot Erweiterungspunkte die Governance brechen
Viele der jüngsten Ergänzungen des GitHub Copilot-Ökosystems bieten einen echten Mehrwert für einzelne Entwickler, erweitern aber auch die...
Rob Bos



Contact