Blog
Führen Sie große Sprachmodelle lokal mit Ollama und Open WebUI aus

Große Sprachmodelle (LLMs) wie ChatGPT sind erstaunlich. Aber die meisten großen Unternehmen werden ihre LLMs immer in der Cloud betreiben. Und die Cloud ist einfach der Computer eines anderen! Was aber, wenn Sie Ihre eigenen LLMs auf Ihrem eigenen Computer laufen lassen wollen?
Sie können es! Fangen wir an.
Was ist Ollama?
Ollama ist ein Tool, mit dem Sie Large Language Models lokal ausführen können. Es kann dazu verwendet werden, Modelle herunterzuladen und mit ihnen über eine einfache
Ollama installieren
Sie können Ollama installieren, indem Sie die Download-Seite besuchen.
Auf dem Mac können Sie es auch über Homebrew installieren.
Um Ollama zu installieren, führen Sie den folgenden Befehl in Ihrem Terminal aus:
brew install --cask ollama
Starten Sie dann die Ollama-App.
Jetzt können Sie Ollama-Befehle ausführen, indem Sie ollama in Ihr Terminal eingeben.
Sprechen Sie mit einem LLM bei Ollama
Probieren wir das Gemma2 von Google aus. Wir haben uns für die 2B-Version entschieden, weil sie so klein ist. Dadurch ist der Download schnell und die Ausführung erfolgt im Vergleich zu größeren Modellen schnell.
Führen Sie den folgenden Befehl aus, um Gemma2:2b herunterzuladen:
ollama pull gemma2:2b
Sobald der Download abgeschlossen ist, können wir den Chat mit Gemma2 beginnen:
ollama run gemma2:2b
>>> Hi
Hello! How can I help you today?
Schön, Sie sprechen mit einem LLM, der auf Ihrem eigenen Computer läuft! Wenn Sie andere Modelle ausprobieren möchten, finden Sie die verfügbaren Modelle in der Ollama-Bibliothek.
Die Chat-Oberfläche von Ollama eignet sich gut zum Testen, aber insgesamt ist sie ziemlich eingeschränkt. Lassen Sie uns etwas dagegen tun!
WebUI öffnen
Open WebUI ist eine Webschnittstelle, die eine Verbindung zu LLM-Diensten wie Ollama (und auch OpenAI) herstellen kann. Die Benutzeroberfläche ist von der Oberfläche von ChatGPT inspiriert.
Open WebUI installieren
Beachten Sie, dass diese Installation Docker erfordert.
Wir können Open WebUI mit einem einzigen Docker-Befehl herunterladen, installieren und ausführen:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Hier erfahren Sie, was die Befehle bedeuten:
docker run: Führen Sie Open WebUI in einem Docker-Container aus.-d: laufen im Hintergrund.-p 3000:8080: Verbinden Sie den lokalen Port 3000 mit dem Container-Port 8080.--add-host: Stellen Sie sicher, dass Docker mit Ollama kommunizieren kann.-vein gemeinsames Volume mounten, so dass unsere Daten gespeichert bleiben, auch wenn der Container anhält.--restart: Läuft immer im Hintergrund.--name: Name des Containers.- ghcr.io/open-webui/open-webui:main: Der Container, den wir ausführen.
Open WebUI wird jetzt unter http://localhost:3000/ verfügbar sein.
Open WebUI einrichten
Öffnen Sie http://localhost:3000/ in Ihrem Browser.
Open WebUI erfordert eine Anmeldung, damit Sie zum Administrator werden können. Keine Sorge, Ihre Daten bleiben auf Ihrem Computer!
So steht es in den FAQ von Open WebUI:
F: Warum werde ich aufgefordert, mich zu registrieren? Wohin werden meine Daten gesendet?
A: Um die Sicherheit zu erhöhen, müssen Sie sich als Admin-Benutzer anmelden. Dies gewährleistet, dass Ihre Daten sicher sind, falls die Open WebUI jemals von außen zugänglich gemacht wird. Es ist wichtig zu wissen, dass alles lokal gehalten wird. Wir sammeln Ihre Daten nicht. Wenn Sie sich anmelden, verbleiben alle Informationen auf Ihrem Server und verlassen niemals Ihr Gerät. Ihre Privatsphäre und Sicherheit haben für uns oberste Priorität, so dass Ihre Daten jederzeit unter Ihrer Kontrolle bleiben.
Höchstwahrscheinlich werden Sie sich danach nicht mehr anmelden müssen. Vergessen Sie nicht, Ihr Passwort an einem sicheren Ort zu speichern!
Sprechen Sie mit einem LLM mit Open WebUI
Sobald Sie sich angemeldet haben, können Sie mit gemma2:2b chatten. Wenn er nicht automatisch ausgewählt ist, klicken Sie auf "Modell auswählen" und wählen Sie gemma2:2b.
Klicken Sie unten auf dem Bildschirm auf "Nachricht senden" und beginnen Sie zu chatten!
Die Benutzeroberfläche ist recht einfach und bedarf kaum einer Erklärung. Aber es gibt einige coole Dinge, die Sie tun können.
Coole Funktionen
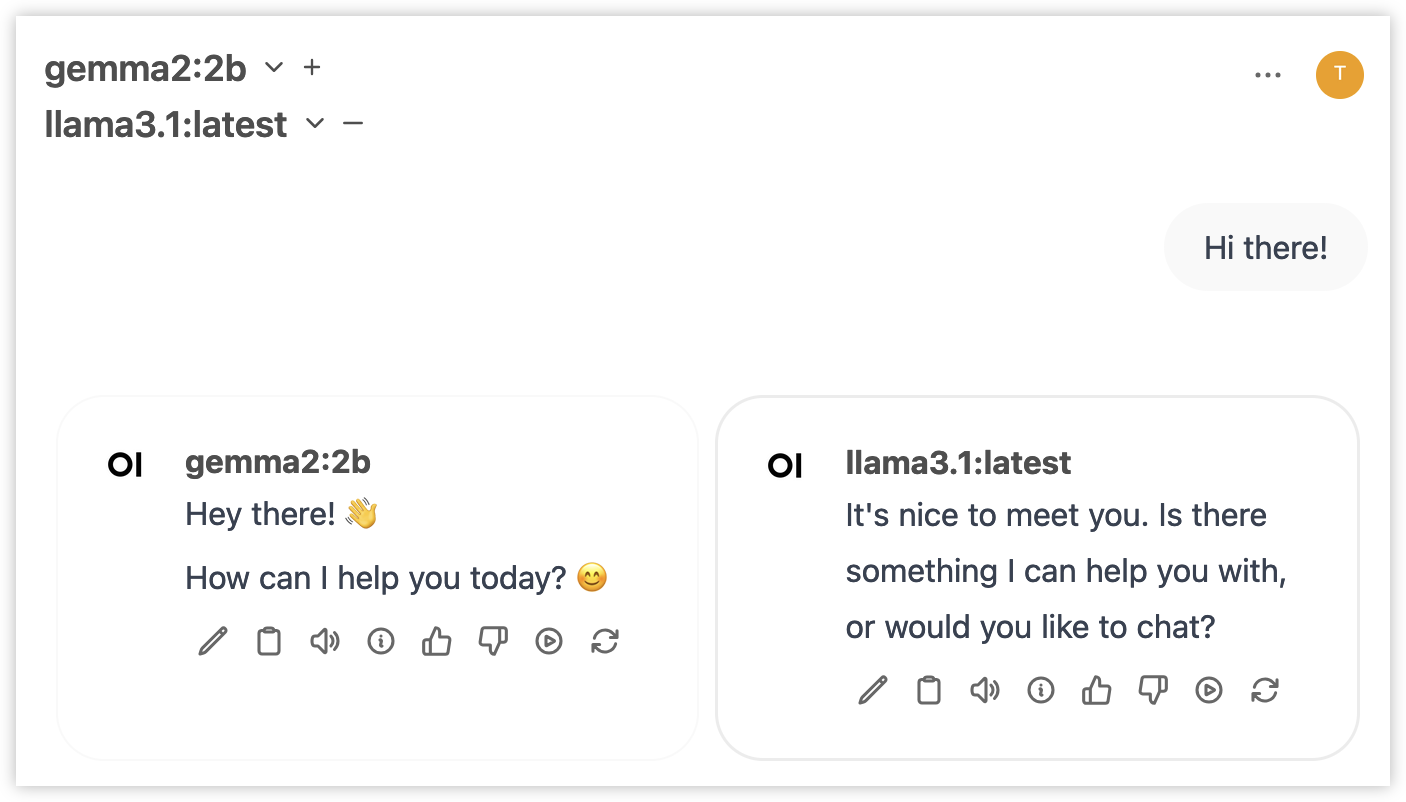
Mehrere LLMs an der gleichen Eingabeaufforderung ausführen
Klicken Sie auf das Plus-Symbol (neben dem von Ihnen ausgewählten Modell) und fügen Sie ein weiteres Modell hinzu. Sie können nun LLMs Seite an Seite vergleichen!
Inhalt aus einer Datei hinzufügen
Klicken Sie links von der Stelle, an der Sie Ihre Nachricht senden, auf das Plus-Symbol (+). Wählen Sie "Dateien hochladen" und wählen Sie eine Datei aus. Jetzt können Sie Fragen zum Inhalt der Datei stellen. Beachten Sie, dass dies nicht immer perfekt funktioniert. Versuchen Sie also, die Datei genau zu benennen und auf sie zu verweisen.
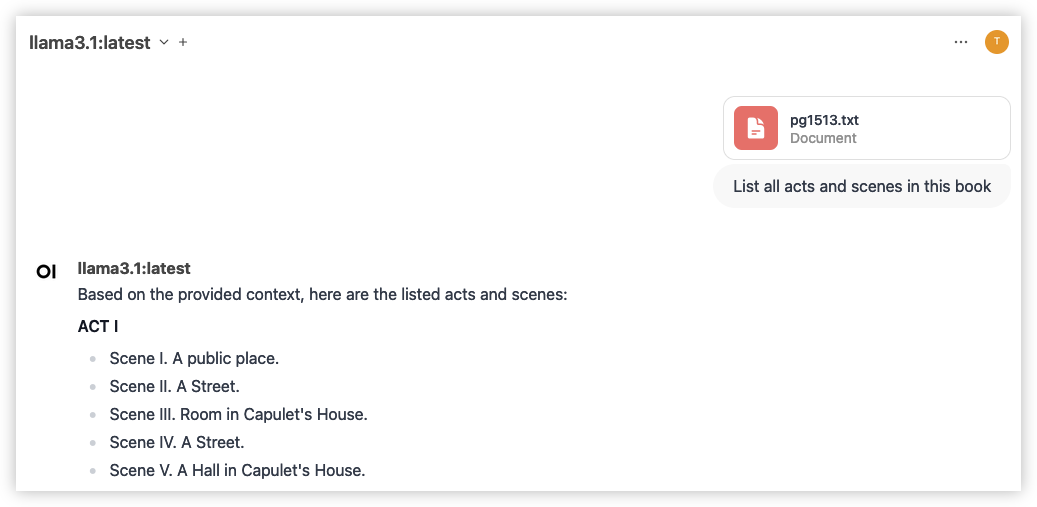
Dieses Beispiel verwendet das kostenlose ebook Romeo und Julia von William Shakespeare
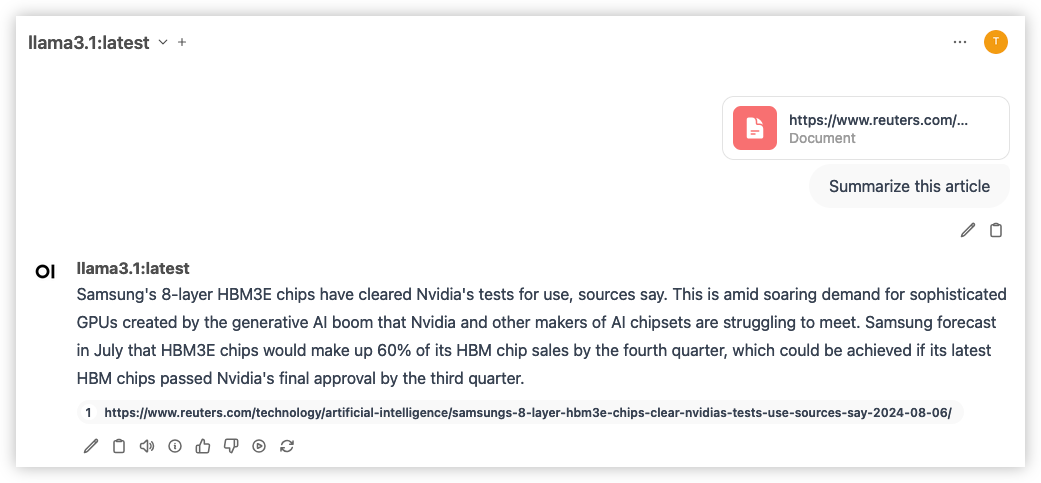
Webinhalte hinzufügen
Wir können Webdaten hinzufügen, indem wir ein # platzieren und eine URL einfügen. Achten Sie darauf, Enter zu drücken. Dadurch wird der Webinhalt als Dokument hinzugefügt.
Code direkt ausführen
Wenn Sie Ihren LLM bitten, Code zu erstellen und er einen Codeblock bereitstellt, können Sie oben rechts im Codeblock auf "Ausführen" klicken. Dadurch wird der Code ausgeführt und die Ausgabe unterhalb des Codeblocks angezeigt.
Natürlich sollten Sie den Code vor der Ausführung überprüfen, um sicherzustellen, dass er nichts tut, was Sie nicht wollen!

Es gibt noch viele weitere Funktionen in Open WebUI, die Sie hier entdecken können.
Fazit
Das war's! Sie führen Large Language Models lokal mit Ollama und Open WebUI aus. Sie können privat chatten, verschiedene Modelle verwenden und mehr!
Foto von Sahand Babali auf Unsplash
Verfasst von
Timo Uelen
Timo Uelen is a Machine Learning Engineer at Xebia.




Contact