Blog
Schnellere Joins in DataFusion auf der Grundlage von Tabellenstatistiken

DataFusion ist eine neue Datenverarbeitungs-Engine, die in der Programmiersprache Rust geschrieben wurde. Sie bietet eine SQL- und eine DataFrame-API zur Transformation von Datensätzen aus verschiedenen Quellen und in verschiedenen Dateiformaten, ähnlich wie Spark. DataFusion verwendet Apache Arrow als zugrunde liegendes Speichermodell, ein effizientes In-Memory-Spaltenformat. Diese Wahl hat erhebliche Leistungsvorteile im Vergleich zu einer Darstellung auf Zeilenebene, wie sie Apache Spark verwendet.
Wie andere Datenbanken und Engines gezeigt haben, kann die Ausführung von analytischen(OLAP-)Abfragen in einem spaltenweisen statt zeilenweisen Format die Abfrageausführung erheblich beschleunigen, oft um das 20-fache oder mehr! Wenn die Verarbeitung zeilenweise erfolgt, werden bei der Ausführung einer Abfrage viele komplexe Operationen in der inneren Schleife ausgeführt, z.B. die Interpretation eines Ausdrucks, die Berechnung des Ergebnisses und der Übergang zum nächsten Wert in der Zeile, wobei völlig unterschiedliche Operationen und Datentypen verarbeitet werden. Im Gegensatz dazu kann die innere Schleife beim Betrieb auf Spaltenebene sehr einfach sein, so dass die CPU leicht erkennen kann, welche Anweisungen wahrscheinlich als nächstes ausgeführt werden und verschiedene Formen der Parallelisierung auf Anweisungsebene nutzen kann. Moderne CPUs können Hunderte von Anweisungen gleichzeitig ausführen, sogar auf einem Kern. Der Code kann so geschrieben werden, dass er die verfügbaren SIMD-Befehle nutzt und gleichzeitig auf mehrere Eingänge wirkt, um die Dinge noch weiter zu beschleunigen. 
Bildquelle: Arrow Website
DataFusion ist in Rust implementiert, einer Sprache, die sowohl schnell ist als auch die Kontrolle über den Speicher hat und dennoch Speichersicherheit bietet, was sie zu einer sehr geeigneten Sprache macht, um performanten und korrekten Code zu schreiben. Im Vergleich zu Java, das auf der JVM läuft, verbrauchen in Rust geschriebene Systeme in der Regel viel weniger Speicher. Das spart Kosten und ermöglicht die Ausführung größerer Workloads auf einem einzigen Rechner! Ein früherer Benchmark von Ballista, einer verteilten Engine in Rust, die DataFusion verwendet, zeigt, dass sie bei kleinen bis mittelgroßen Datensätzen mit etwa 10x weniger Speicher auskommt. Die JVM benötigt mindestens 1 GB für den Heap. Spark speichert auch Zwischenergebnisse zwischen den Phasen im Speicher. DataFusion kann mehr Daten in Stapeln von Datensätzen streamen und so den Speicherverbrauch niedrig halten. DataFusion profitiert auch vom Arrow-Format, das Datentypen wie Strings auf effiziente Weise speichert.
In der Rust-Version von Arrow und DataFusion wurden zwischen Version 2 und 3, die im Januar veröffentlicht werden soll, zahlreiche Leistungsverbesserungen vorgenommen.
Ich habe zum Beispiel einen schnelleren CSV-Parser beigesteuert und die Leistung von Hashing verbessert. Es wurden Kernel verbessert, die Implementierungen häufig verwendeter Berechnungen bieten, wie z.B.
Vor kurzem habe ich DataFusion einen neuen Optimierungspassus hinzugefügt, um Hash-Joins schneller zu machen. Ein Hash Join ist ein beliebter Algorithmus, um Joins schnell zu implementieren. Der Hash-Join-Algorithmus ist in eine
Implementierung / Ergebnisse
Die Optimierung wird als Optimierungsdurchlauf auf dem logischen Plan, einer abstrakten Darstellung einer Abfrage, implementiert. Wenn die linke Seite einer Verknüpfung mehr Zeilen enthält als die rechte Seite, werden die Reihenfolge und der Verknüpfungstyp vertauscht. Wenn die linke Seite bereits kleiner ist, wird die Reihenfolge beibehalten.
Beim Testen der Optimierung ist etwas Unerwartetes passiert: Wenn die Optimierungsregel verwendet wurde, um die Reihenfolge zu ändern, schnitt die Abfrage schlechter ab als das Original.
Bei der Untersuchung der Implementierung des Hash-Joins in DataFusion wurde klar, dass neben der linken Seite eines Joins auch der rechte Teil eine Nachschlagetabelle erstellt!
Ich änderte die Implementierung so, dass nur die Sondenseite verwendet wird, um Elemente auf der linken Seite nachzuschlagen, und vereinfachte die Implementierung, wodurch einige andere Ineffizienzen beseitigt wurden. Jetzt laufen Abfragen mit Joins viel schneller als vorher. Dies lässt sich anhand von zwei cargo run --release --bin tpch -- benchmark --iterations 10 --path und die Ergebnisse gemittelt.
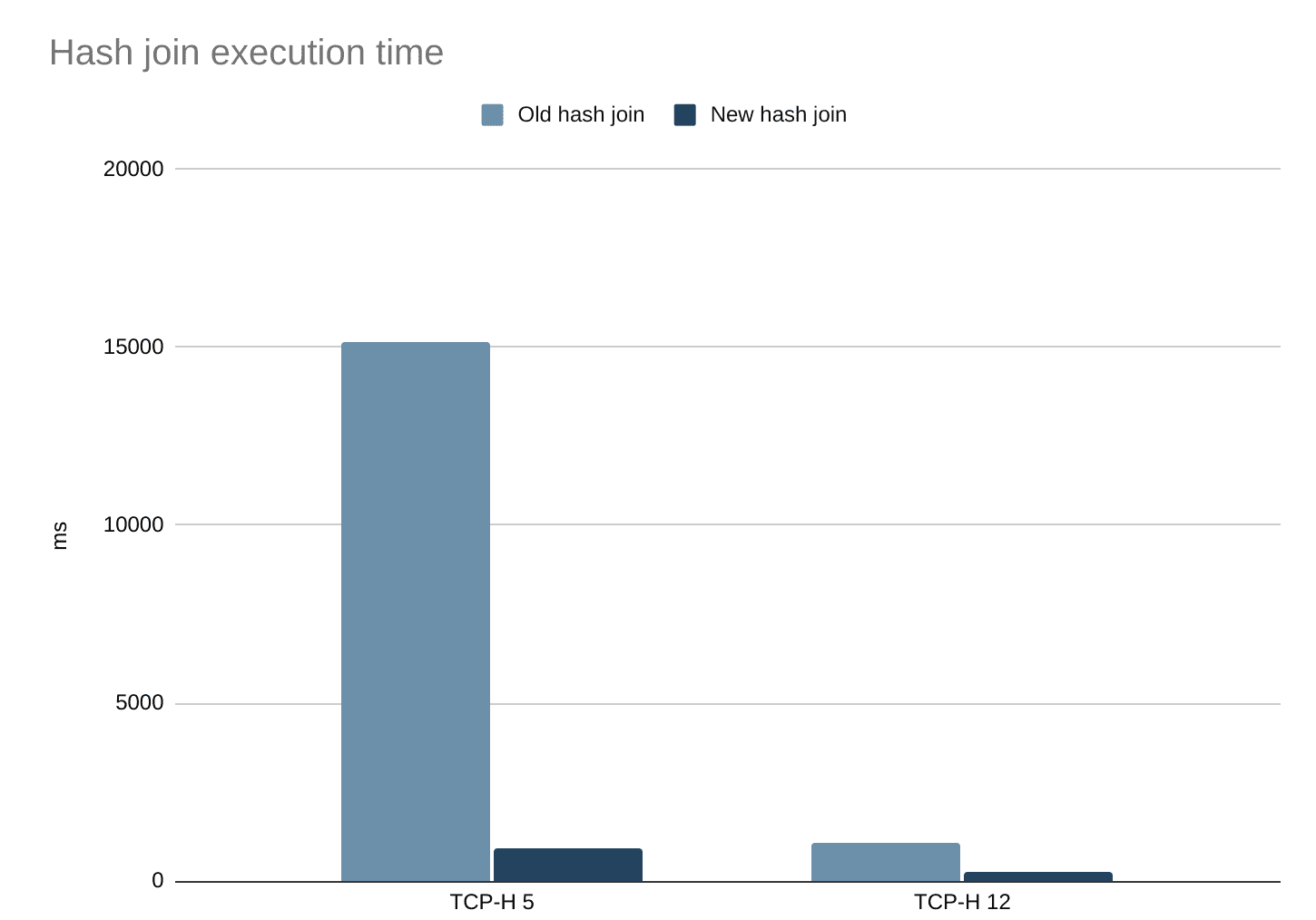
Wenn die Optimierungsregel angewandt und mit der verbesserten Hash-Join-Implementierung kombiniert wird, werden die Abfragen, auf die die Regel angewandt werden kann, schneller ausgeführt. In diesem Fall wird die Gesamtausführungszeit um etwa 16 % reduziert. Bei unausgewogeneren Verknüpfungen kann der Geschwindigkeitszuwachs noch größer sein. Die Daten enthalten etwa 6 Millionen Einzelposten (ursprünglich auf der linken Seite der Verknüpfung) und 1,5 Millionen Bestellungen (auf der rechten Seite).
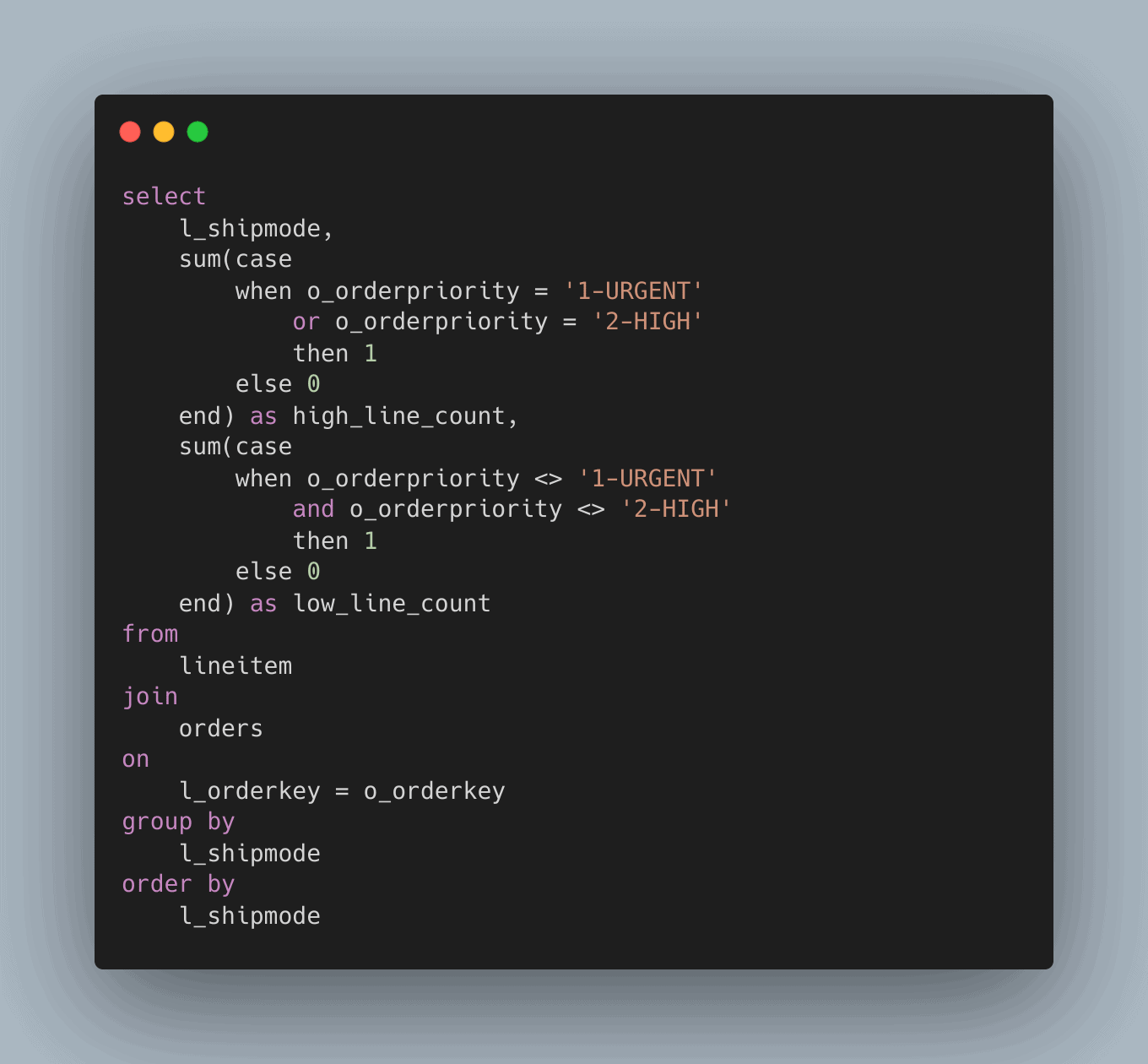
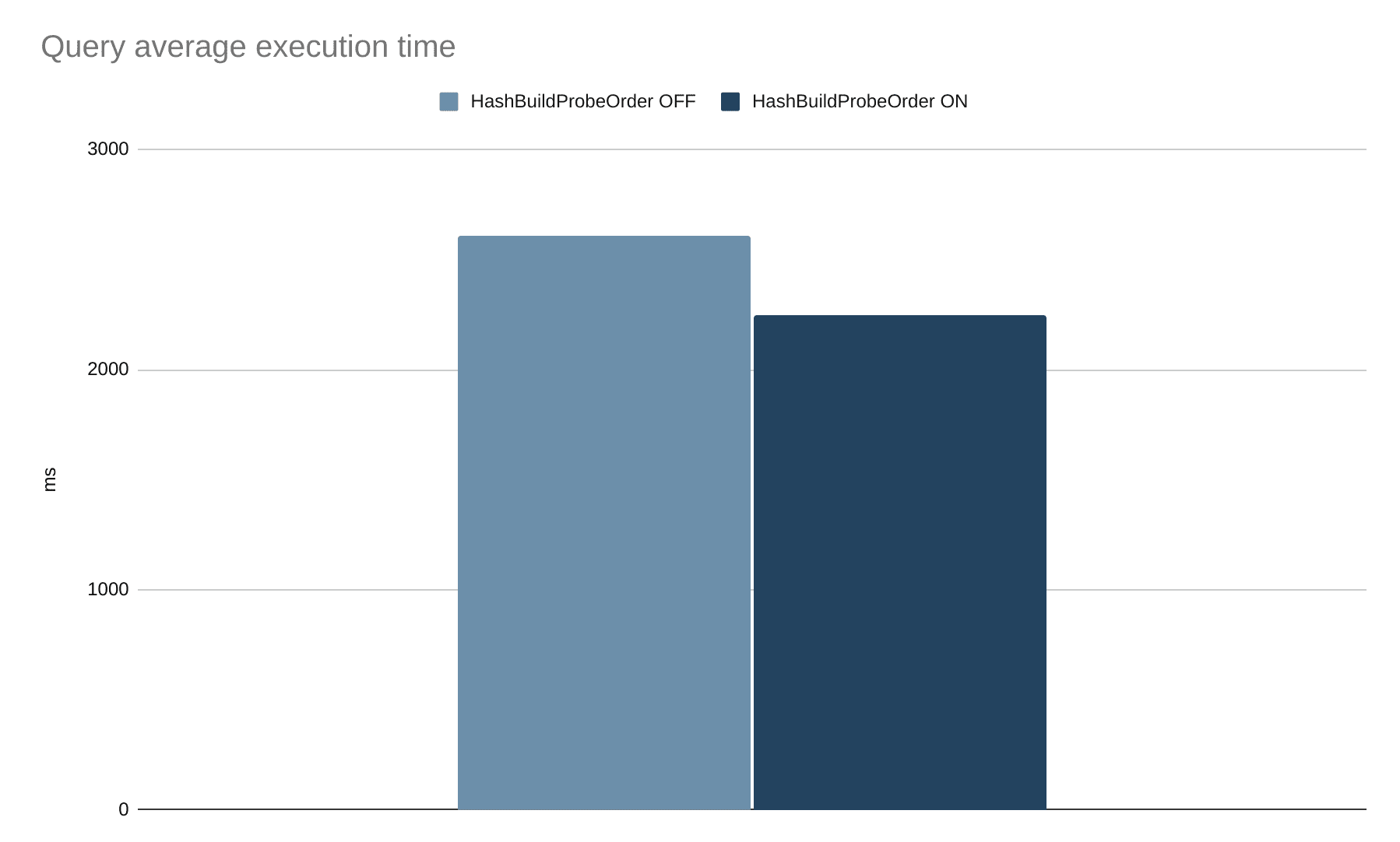
Fazit
Statistiken sind ein vielversprechender Weg, um Abfragen zu beschleunigen. In Zukunft könnten viele weitere Optimierungen hinzugefügt werden, die von Tabellenstatistiken profitieren. Viele Statistiken sind jedoch erst nach der Ausführung von Abfragen bekannt, so dass es in Zukunft interessant wäre, auch eine Form der adaptiven Abfrageausführung hinzuzufügen. Hash-Joins könnten weiter verbessert werden, z.B. durch die Verwendung von vektorisiertem Hashing, das auch für Hash-Aggregationen verwendet werden kann, die in GROUP BY-Abfragen eingesetzt werden.
Ich persönlich bin sehr gespannt auf die Zukunft von Arrow und DataFusion und darauf, wie Rust und Apache Arrow die Datenanalyse und Datenwissenschaft beschleunigen werden.
Verfasst von
Daniël Heres
Unsere Ideen
Weitere Blogs



Contact