
Einführung
LLMs lassen sich mit einer Technik namens RAG aufladen, die es uns ermöglicht, Probleme wie Halluzinationen oder fehlenden Zugang zu internen Daten zu überwinden. RAG gewinnt in der Branche immer mehr an Bedeutung und wird sowohl in der Open-Source-Welt als auch bei großen Cloud-Anbietern immer ausgereifter. Aber was können wir von RAG erwarten? Wie ist der aktuelle Stand der Technik in der Branche? Welche Anwendungsfälle funktionieren gut und welche sind eher schwierig? Lassen Sie es uns gemeinsam herausfinden!
Warum RAG
Retrieval Augmented Generation (RAG) ist eine beliebte Technik zur Kombination von Retrieval-Methoden wie der Vektorsuche mit Large Language Models (LLMs). Dies bietet uns mehrere Vorteile, wie z.B. das Abrufen zusätzlicher Informationen auf der Grundlage einer Suchanfrage eines Benutzers: Wir können LLM-generierte Antworten zitieren und zitieren. Kurz gesagt, RAG ist wertvoll, weil:
- Zugang zu aktuellem Wissen
- Zugang zu internen Unternehmensdaten
- Mehr sachliche Antworten
Das klingt alles großartig. Aber wie funktioniert RAG? Lassen Sie uns die RAG-Stufen einführen, damit wir die RAG mit zunehmendem Komplexitätsgrad besser verstehen.
Die RAG-Stufen
Die RAG hat viele verschiedene Facetten. Um die RAG besser zu verstehen, sollten wir sie in vier Stufen unterteilen:
 Stufe 1 Stufe 1Basic RAG |
 Level 2 Level 2Hybride Suche |
 Level 3 Level 3Fortgeschrittene Datenformate |
 Level 4 Level 4Multimodal |
|---|
Jede Stufe bringt neue Komplexität mit sich. Neben der Erläuterung der Techniken werden wir uns auch mit der Rechtfertigung der eingeführten Komplexität befassen. Das ist wichtig, denn Sie wollen gute Gründe dafür haben: Wir wollen alles so einfach wie möglich machen, aber nicht einfacher [1] .
Wir werden mit dem Aufbau einer RAG von Anfang an beginnen und verstehen, welche Komponenten dafür erforderlich sind. Lassen Sie uns also gleich mit Level 1 beginnen: Basic RAG.
Stufe 1: Grundlegende RAG
Lassen Sie uns eine RAG erstellen. Um eine RAG zu erstellen, benötigen wir zwei Hauptkomponenten: die Dokumentensuche und die Generierung von Antworten.
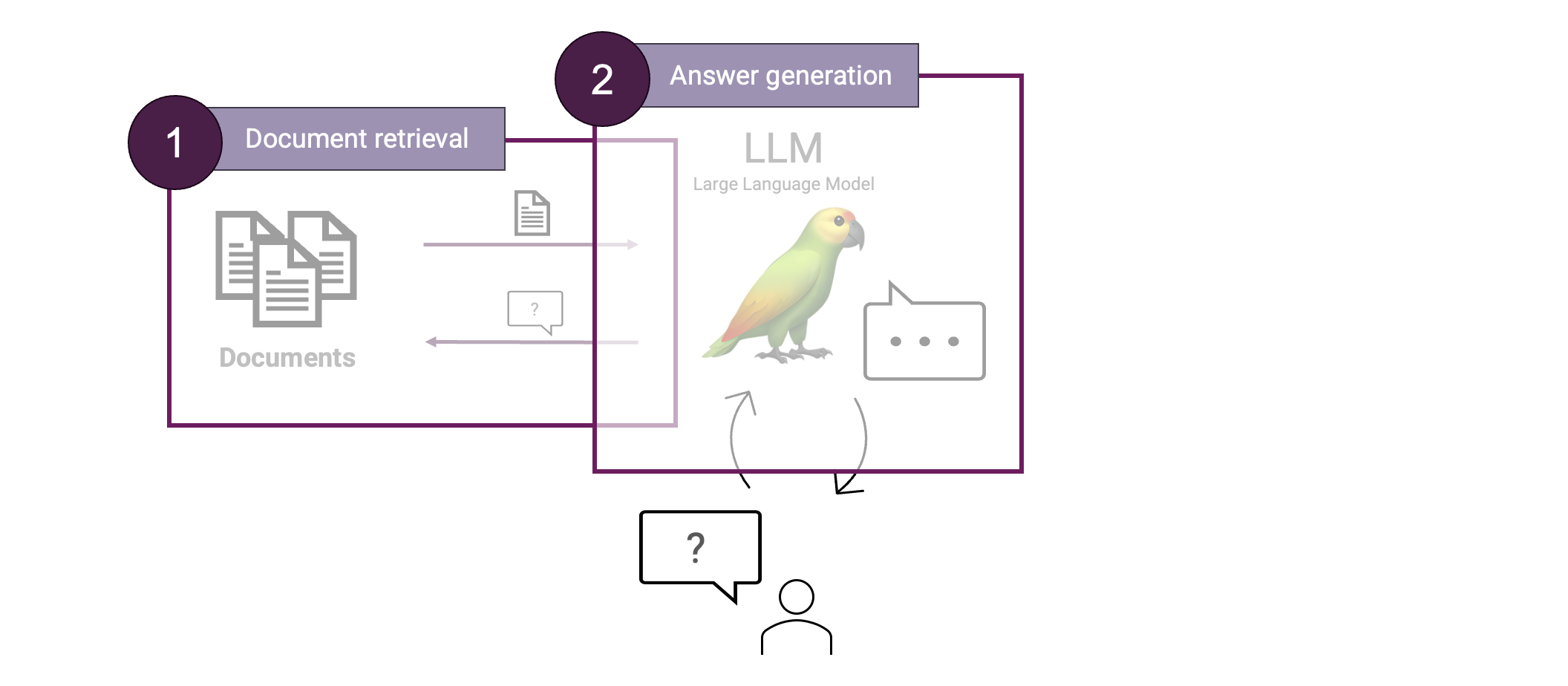
Im Gegensatz zu einer normalen LLM-Interaktion rufen wir jetzt zunächst den relevanten Kontext ab, um dann die Frage nur unter Verwendung dieses Kontexts zu beantworten. Dadurch können wir unsere Antwort auf den abgerufenen Kontext stützen, was die Antwort faktisch zuverlässiger macht.
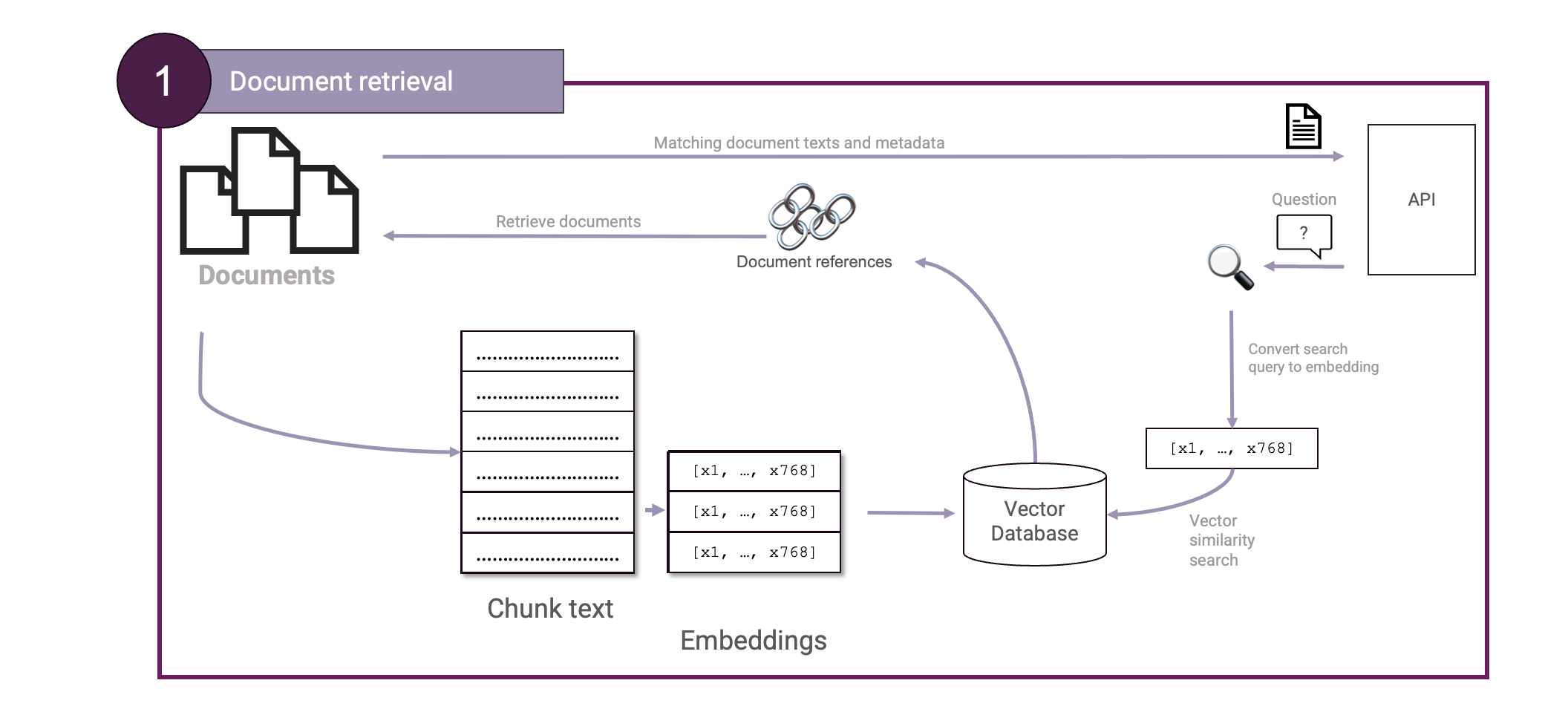
Schauen wir uns beide Komponenten genauer an und beginnen wir mit dem Schritt des Abrufs von Dokumenten. Eine der wichtigsten Techniken, die unseren Abrufschritt unterstützt, ist die Vektorsuche.
Vektorsuche
Um die für unsere Benutzeranfrage relevanten Dokumente zu finden, verwenden wir die Vektorsuche. Diese Technik basiert auf Vektoreinbettungen. Was ist das? Stellen Sie sich vor, wir betten Wörter ein. Dann sollten Wörter, die semantisch ähnlich sind, im Einbettungsraum näher beieinander liegen. Das Gleiche können wir für Sätze, Absätze oder sogar ganze Dokumente tun. Eine solche Einbettung wird in der Regel durch Vektoren mit 768-, 1024- oder sogar 3072 Dimensionen dargestellt. Allerdings können wir Menschen solche hochdimensionalen Räume nicht visualisieren: wir können nur 3 Dimensionen sehen! Lassen Sie uns zum Beispiel einen solchen Einbettungsraum auf 2 Dimensionen komprimieren, damit wir ihn visualisieren können:
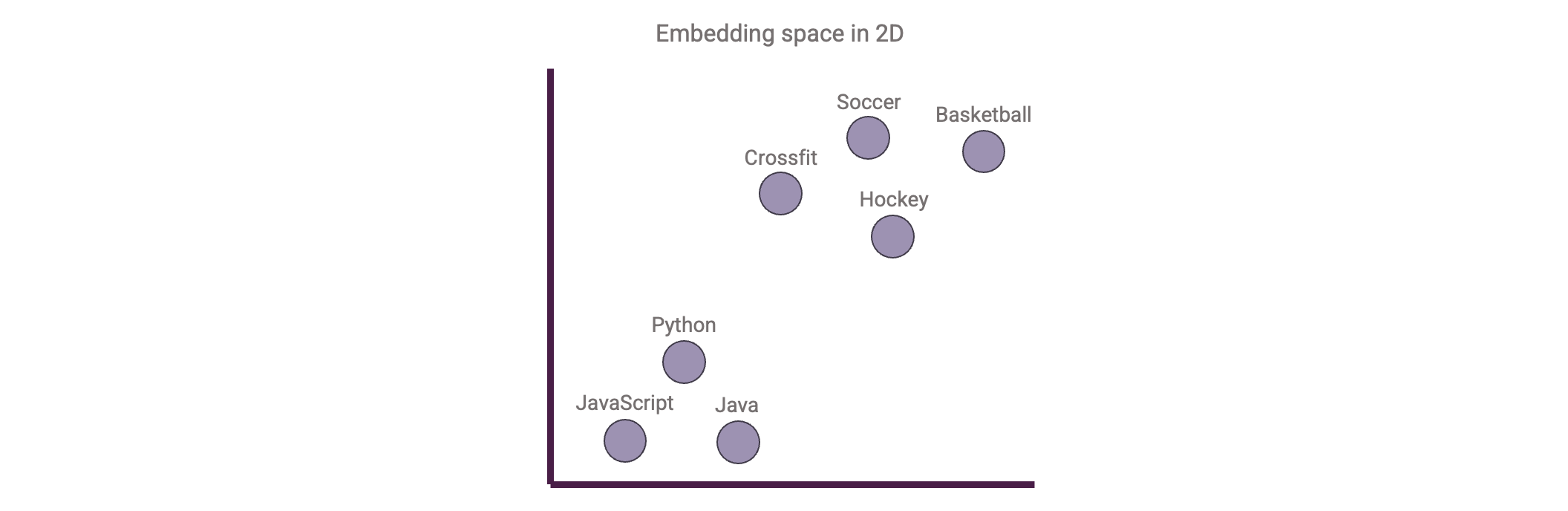
Beachten Sie, dass dies eine stark vereinfachte Erklärung von Vektoreinbettungen ist. Die Erstellung von Vektoreinbettungen von Text - von Wörtern bis hin zu ganzen Dokumenten - ist eine ganz eigene Studie. Am wichtigsten ist jedoch, dass wir mit Einbettungen die Bedeutung des eingebetteten Textes erfassen!
Wie kann man dies für RAG nutzen? Nun, anstatt Wörter einzubetten, können wir stattdessen unsere Quelldokumente einbetten. Dann können wir auch die Frage des Benutzers einbetten und eine Vektorähnlichkeitssuche mit diesen Dokumenten durchführen:
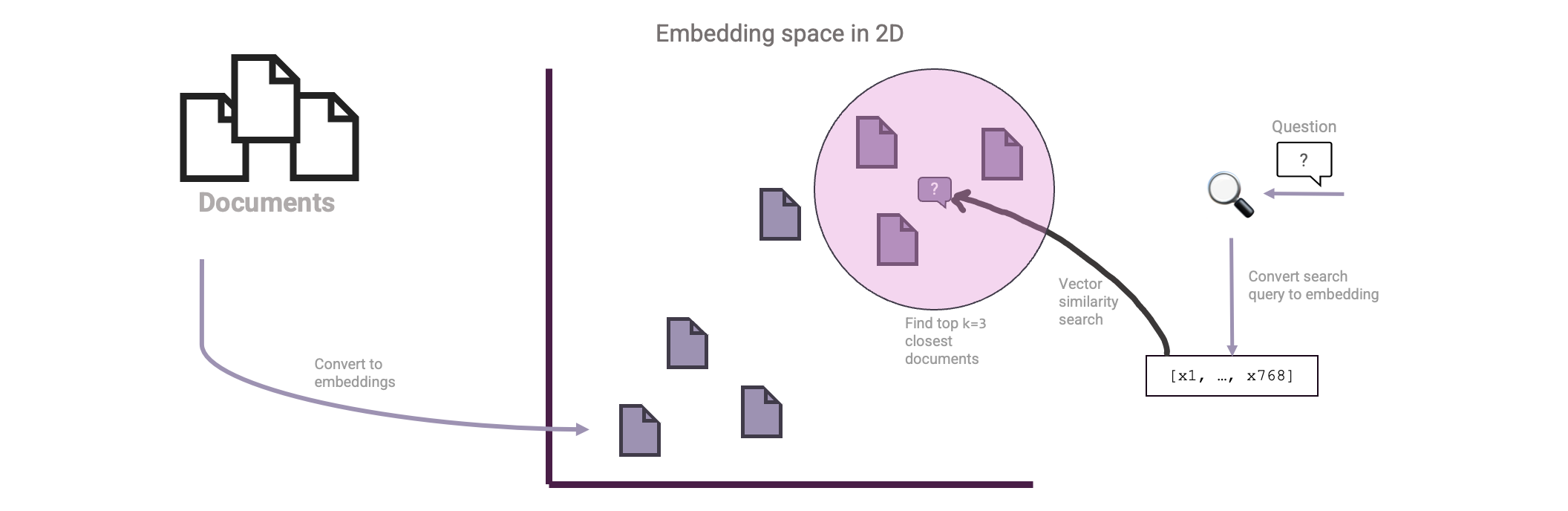
Großartig! Jetzt haben wir die nötigen Zutaten, um unsere erste Einrichtung zum Abrufen von Dokumenten zu konstruieren:
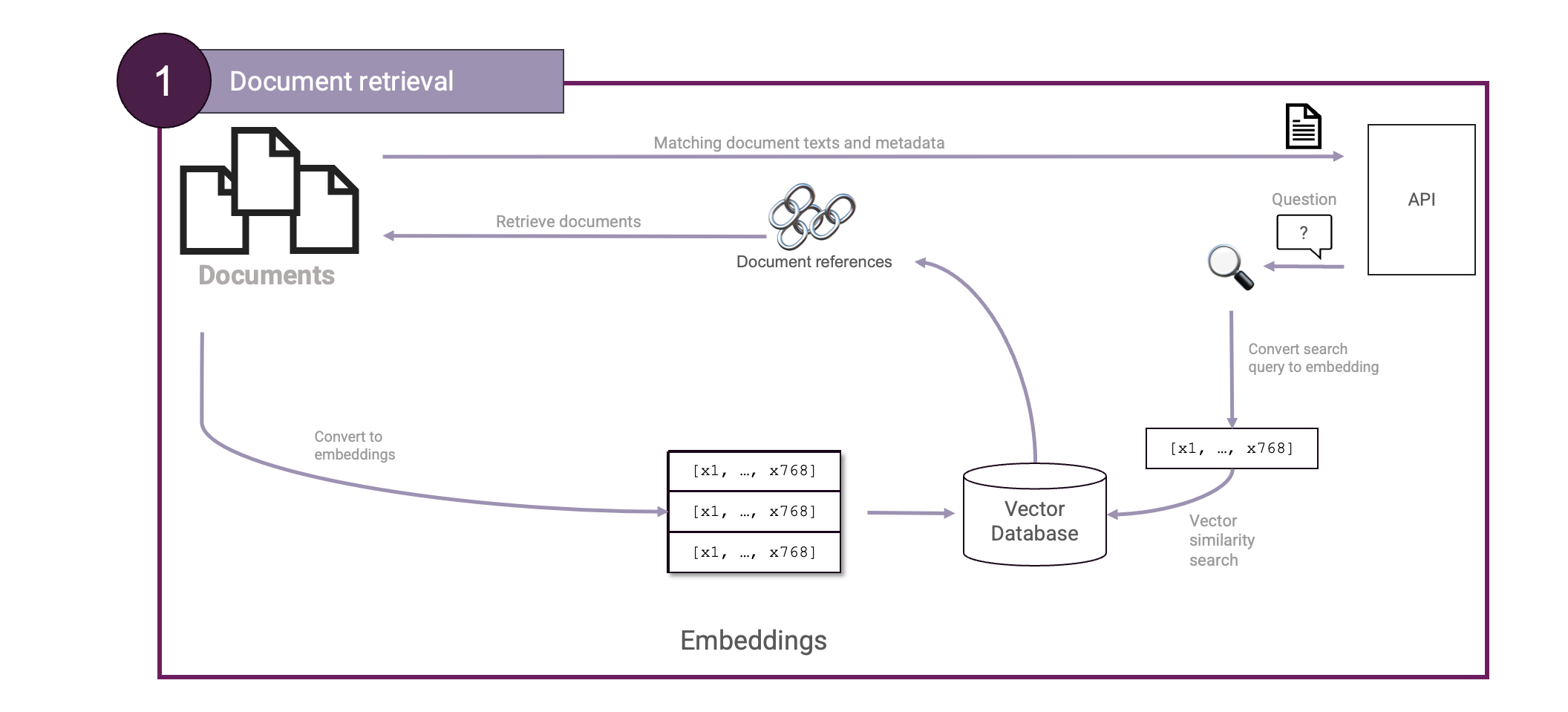
Der nächste Schritt ist die Generierung der Antwort. Dabei werden die gefundenen Kontextteile an einen LLM weitergegeben, der daraus eine endgültige Antwort formt. Wir wollen das einfach halten und verwenden dafür eine einzige Eingabeaufforderung:
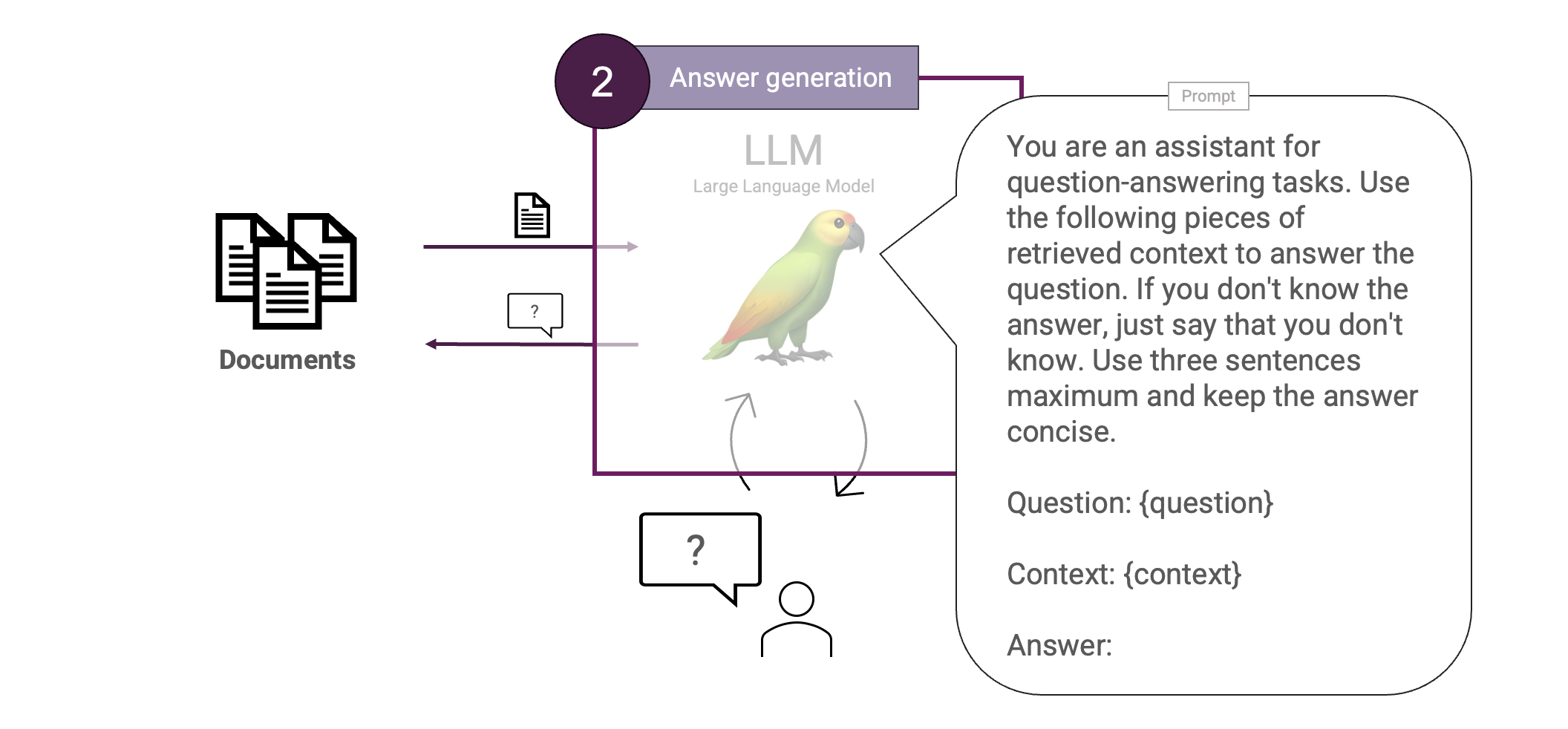
Super. Damit ist unsere erste vollständige Version des Basic RAG abgeschlossen. Um unser RAG-System zu testen, brauchen wir einige Daten. Ich war kürzlich bei PyData und dachte mir, wie cool es wäre, eine RAG auf der Grundlage ihres Zeitplans zu erstellen. Lassen Sie uns eine RAG auf der Grundlage des Zeitplans von PyData Eindhoven 2024 entwerfen.
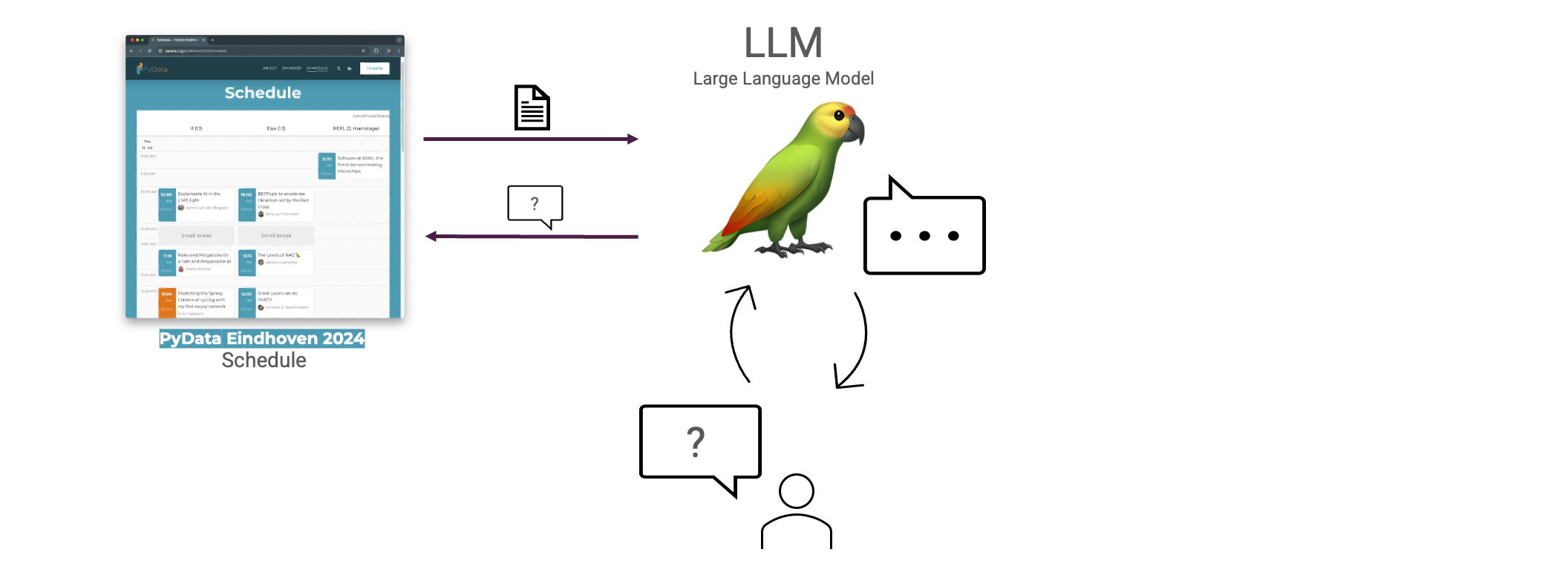
Wie können wir also einen solchen Zeitplan in eine Vektordatenbank einlesen? Wir nehmen jede Sitzung und formatieren sie als Markdown, wobei wir die Struktur des Zeitplans mit Hilfe von Kopfzeilen berücksichtigen.

Unser RAG-System ist jetzt voll funktionsfähig. Wir haben alle Sitzungen eingebettet und sie in eine Vektordatenbank aufgenommen. Dann können wir mithilfe der Vektorähnlichkeitssuche Sitzungen finden, die der Frage des Benutzers ähnlich sind, und die Frage anhand einer vordefinierten Aufforderung beantworten. Testen wir es aus!
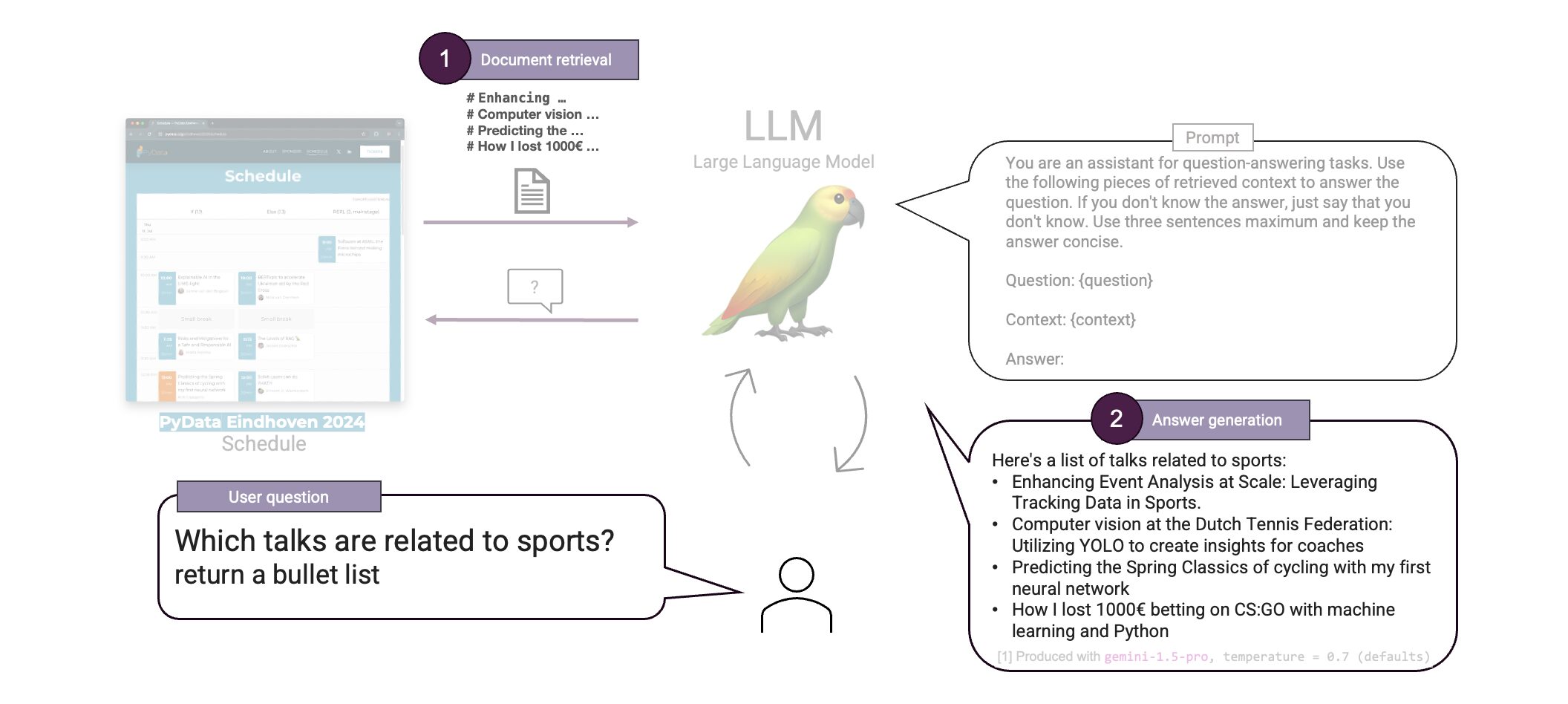
Das ist toll! Unsere RAG konnte die Frage richtig beantworten. Wenn wir uns den Zeitplan ansehen, sehen wir, dass die aufgelisteten Vorträge tatsächlich alle mit Sport zu tun haben. Wir haben gerade ein erstes RAG-System aufgebaut.
Es gibt jedoch einige Punkte, die verbessert werden können. Wir betten die Sitzungen jetzt in ihrer Gesamtheit ein. Das Einbetten großer Textabschnitte kann jedoch problematisch sein, denn:
- ❌ Einbettungen können gesättigt werden und an Bedeutung verlieren
- ❌ Ungenaue Zitate
- ❌ Großer Kontext → hohe Kosten
Was wir also tun können, um dieses Problem zu lösen, ist, den Text in kleinere Stücke aufzuteilen und diese dann einzubetten. Dies ist Chunking.
Chunking
Beim Chunking besteht die Herausforderung darin, zu bestimmen , wie der Text aufgeteilt werden soll, um dann diese kleineren Teile einzubetten. Es gibt viele Möglichkeiten, Text zu chunking. Sehen wir uns zunächst eine einfache Möglichkeit an. Wir erstellen Abschnitte mit fester Länge:

Character Text Splitter mit
chunk_size = 25. Dies ist eine unrealistisch kleine Stückgröße, wird aber nur als Beispiel verwendet. Dies ist nicht ideal. Wörter, Sätze und Absätze werden nicht beachtet und an ungünstigen Stellen getrennt. Das mindert die Qualität unserer Einbettungen. Wir können das besser machen. Versuchen wir es mit einem anderen Splitter, der versucht, die Struktur des Textes besser zu berücksichtigen, indem er Zeilenumbrüche (¶) mit einbezieht:

Rekursiver Zeichentext-Splitter mit
chunk_size = 25. Dies ist eine unrealistisch kleine Stückgröße, wird aber nur als Beispiel verwendet. Dies ist besser. Die Qualität unserer Einbettungen ist jetzt besser, weil wir sie besser aufteilen. Beachten Sie, dass chunk_size = 25 nur als Beispiel verwendet wird. In der Praxis werden wir größere Brockengrößen wie 100, 500 oder 1000 verwenden. Probieren Sie aus, was bei Ihren Daten am besten funktioniert. Experimentieren Sie aber vor allem auch mit verschiedenen Text-Splittern. Im Abschnitt LangChain Text Splitters finden Sie viele davon und das Internet ist voll von anderen.
Jetzt, wo wir unseren Text in Chunks unterteilt haben, können wir diese Chunks einbetten und in unsere Vektordatenbank einfügen. Wenn wir dann den LLM unsere Frage beantworten lassen, können wir ihn auch bitten, anzugeben, welche Chunks er bei der Beantwortung der Frage verwendet hat. Auf diese Weise können wir genau feststellen, auf welche Informationen sich der LLM bei der Beantwortung der Frage gestützt hat, so dass wir dem Benutzer Zitate zur Verfügung stellen können:

Das ist großartig. Zitate können in einer RAG-Anwendung sehr mächtig sein, um die Transparenz und damit auch das Vertrauen der Benutzer zu verbessern. Zusammengefasst hat das Chunking die folgenden Vorteile:
- Einbettungen sind aussagekräftiger
- Präzise Zitate
- Kürzerer Kontext → geringere Kosten
Wir können nun unseren Schritt der Dokumentensuche mit Chunking erweitern:
Wir haben unser Basic RAG mit Vektorsuche und Chunking eingerichtet. Wir haben auch gesehen, dass unser System Fragen korrekt beantworten kann. Aber wie gut ist es tatsächlich? Nehmen wir die Frage"Wovon handelt der Vortrag, der mit Maximizing beginnt?" und lassen Sie sie auf unseren RAG los:
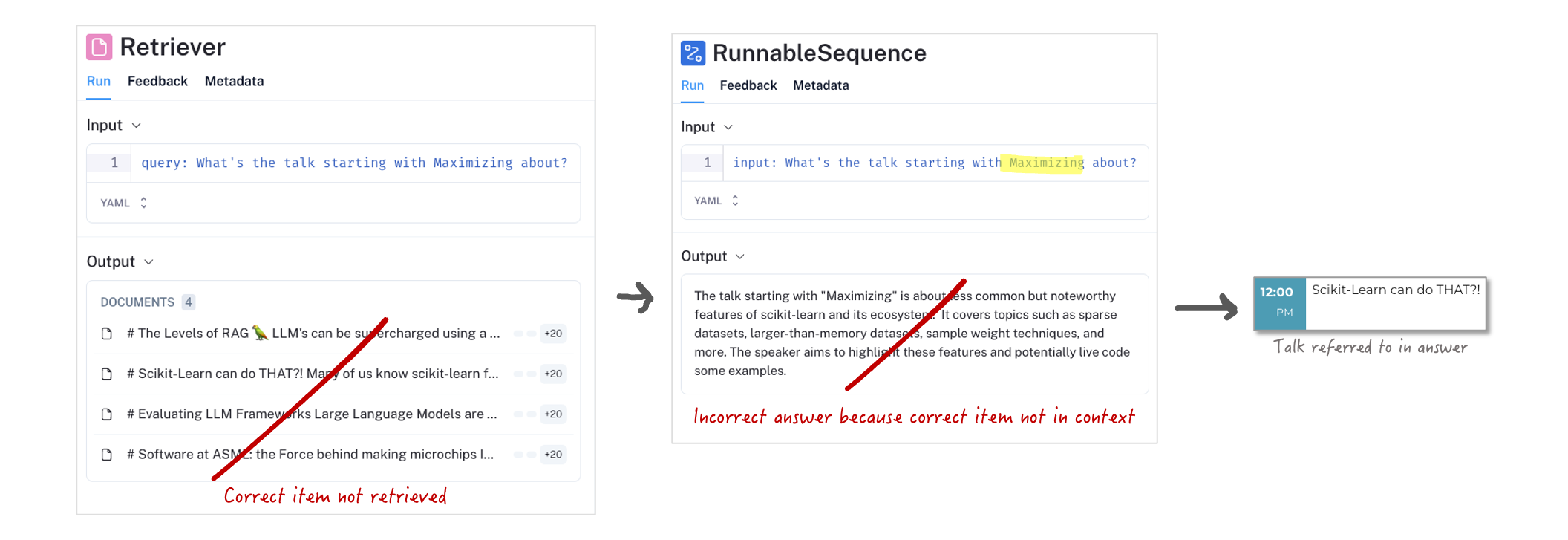
Die angezeigte Benutzeroberfläche ist LangSmith, ein GenAI-Überwachungstool. Die Open-Source-Alternative ist LangFuse.
Autsch! Diese Antwort ist völlig falsch. Dies ist nicht der Vortrag, der mit Maximizing beginnt. Der beschriebene Vortrag trägt den Titel Scikit-Learn can do THAT?!, der eindeutig nicht mit dem Wort Maximizing beginnt.
Aus diesem Grund benötigen wir eine weitere Suchmethode, wie die Stichwortsuche. Da wir auch die Vorteile der Vektorsuche beibehalten möchten, können wir die beiden Methoden zu einer Hybrid-Suche kombinieren.
Ebene 2: Hybride Suche
Bei der Hybriden Suche versuchen wir, zwei Ranking-Methoden zu kombinieren, um das Beste aus beiden Welten zu erhalten. Wir werden die Vektorsuche mit der Stichwortsuche kombinieren, um eine hybride Suche zu erstellen. Dazu müssen wir eine geeignete Einstufungsmethode auswählen. Gängige Ranking-Algorithmen sind:
- TF-IDF : Term Häufigkeit - Inverse Dokument Häufigkeit
- Okapi BM-25 : Okapi Best Matching 25
... von denen wir BM-25 als eine verbesserte Version von TF-IDF betrachten können. Wie können wir nun die Vektorsuche mit einem Algorithmus wie BM-25 kombinieren? Wir haben jetzt zwei separate Rankings, die wir zu einem verschmelzen wollen. Hierfür können wir die Reciprocal Rank Fusion verwenden:
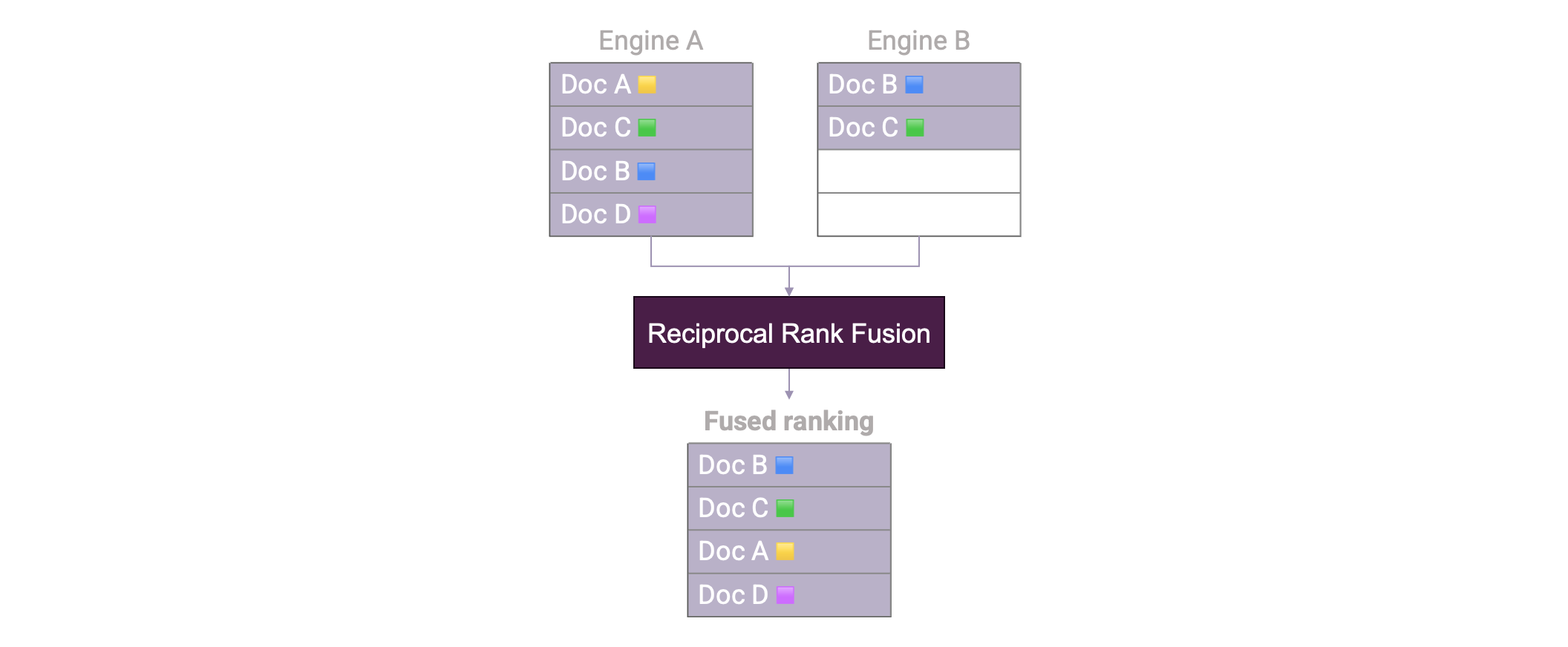
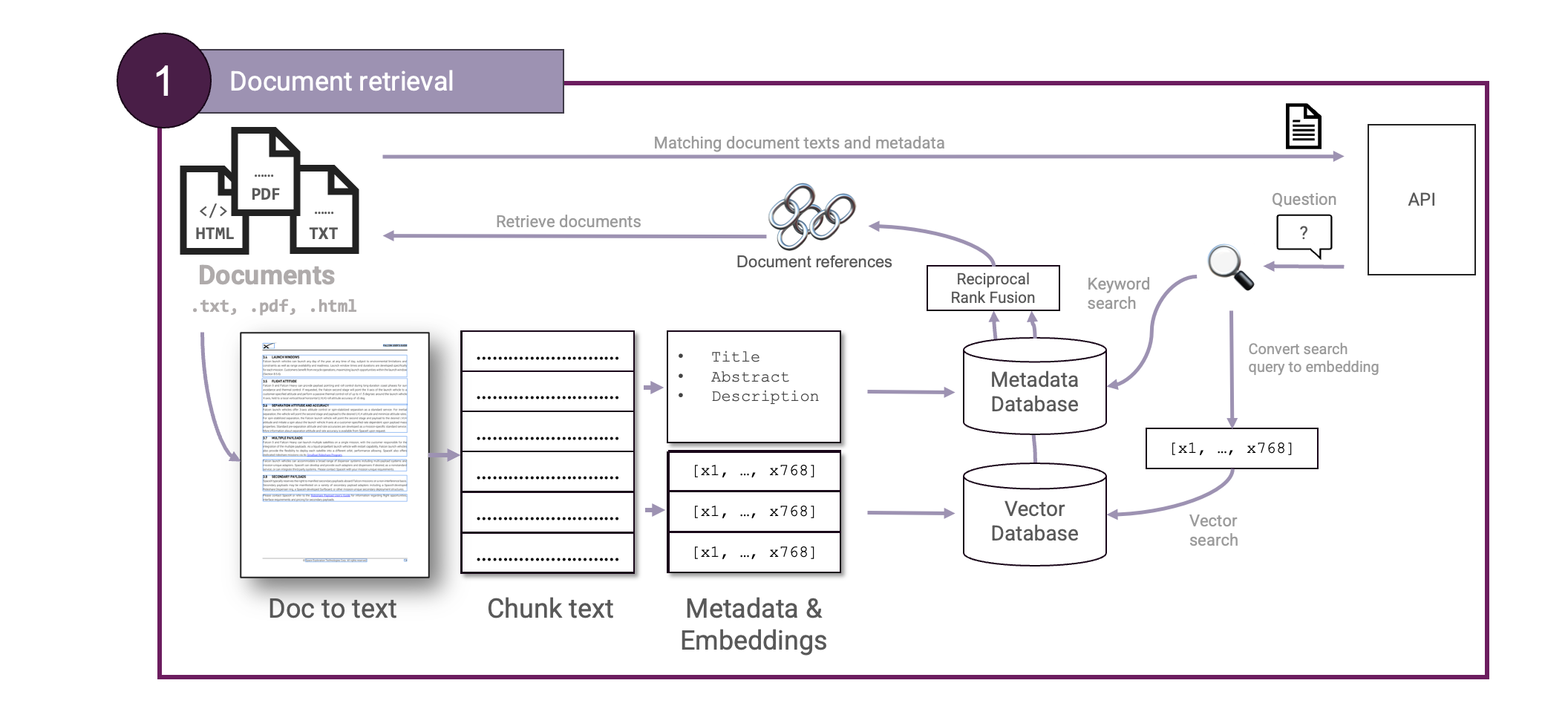
Reciprocal Rank Fusion ist sehr nützlich, um zwei Rankings zu kombinieren. Auf diese Weise können wir nun sowohl die Vektorsuche als auch die Schlagwortsuche zum Abrufen von Dokumenten verwenden. Wir können nun unseren Schritt der Dokumentensuche erweitern, um eine hybride Suche einzurichten:
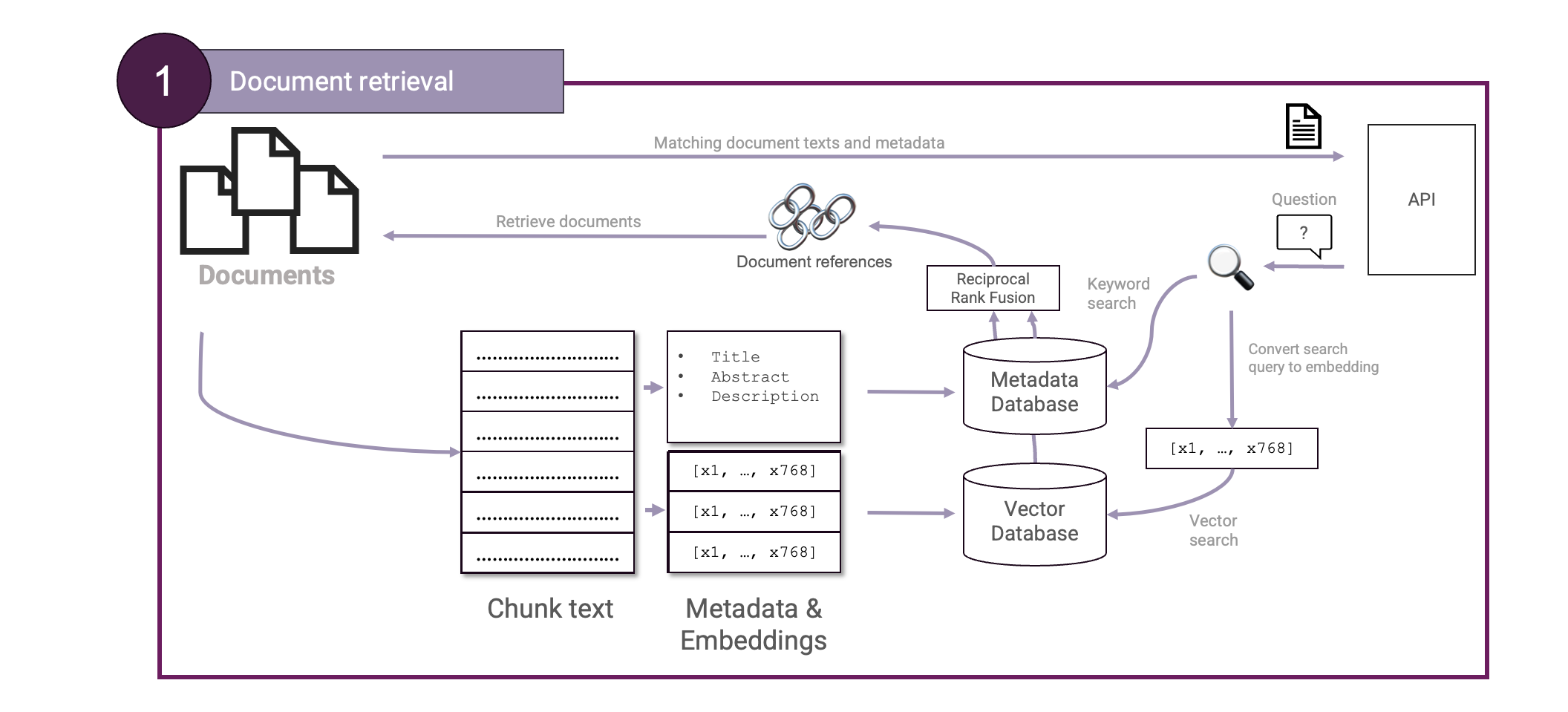
Wenn ein Benutzer eine Suche durchführt, wird eine Anfrage sowohl an unsere Vektordatenbank als auch an unsere Stichwortsuche gestellt. Nachdem die Ergebnisse mit Reciprocal Rank Fusion zusammengeführt wurden, werden die besten Ergebnisse ausgewählt und an unseren LLM weitergeleitet.
Nehmen wir noch einmal die Frage"Worum geht es bei dem Gespräch, das mit Maximieren beginnt?", wie wir es in Stufe 1 getan haben, und sehen wir uns an, wie unsere RAG mit der Hybriden Suche damit umgeht:
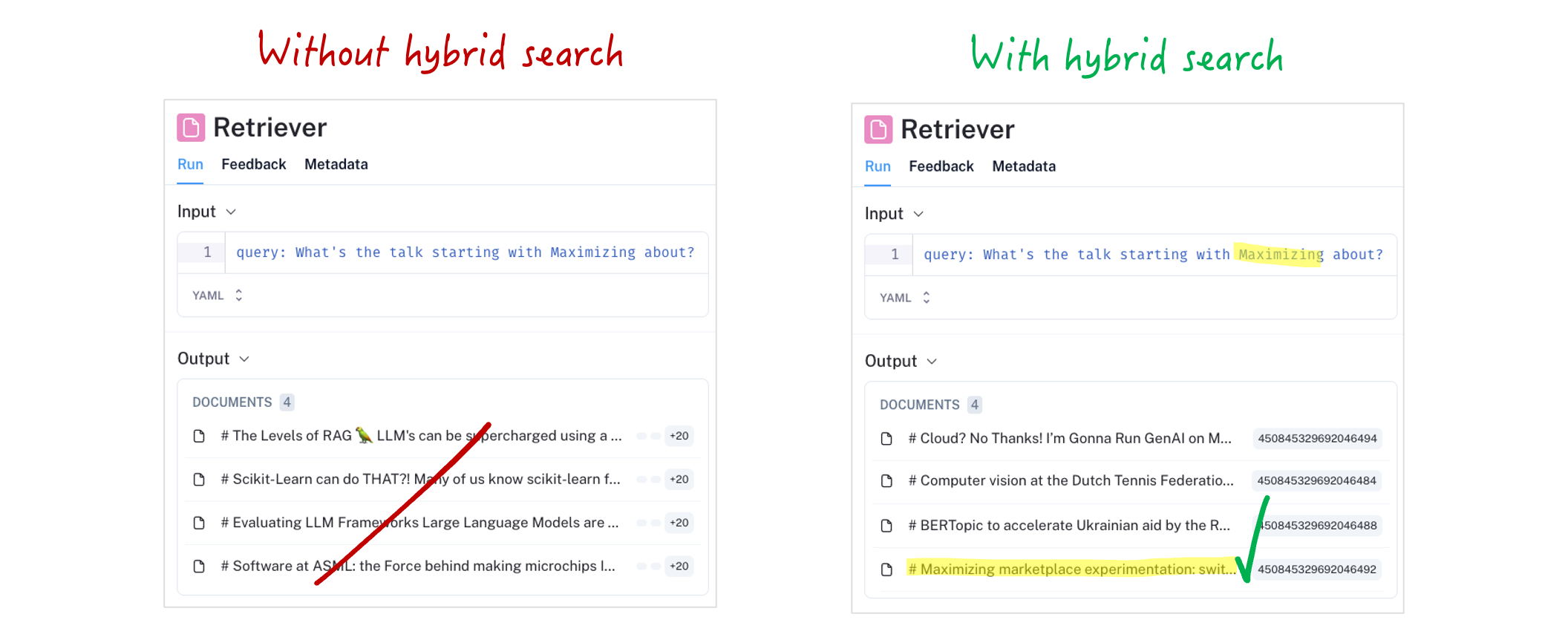
Das ist schon viel besser! Das gesuchte Dokument wurde nun so hoch eingestuft, dass es in unserem Abrufschritt auftaucht. Dies geschah, indem die in der Suchanfrage verwendeten Begriffe aufgewertet wurden. Ohne das Dokument, das im Kontext unserer Eingabeaufforderung verfügbar war, hätte uns der LLM unmöglich die richtige Antwort geben können. Schauen wir uns sowohl den Abrufschritt als auch den Generierungsschritt an, um zu sehen, was unser LLM jetzt auf diese Frage antwortet:

Das ist die richtige Antwort ✓. Wenn dem LLM der richtige Kontext zur Verfügung steht, erhalten wir auch die richtige Antwort. Das Abrufen des richtigen Kontexts ist die wichtigste Funktion unserer RAG: Ohne sie kann uns der LLM unmöglich die richtige Antwort geben.
Wir haben nun gelernt, wie man ein grundlegendes RAG-System erstellt und wie man es mit Hybrid Search verbessert. Die Daten, die wir geladen haben, stammen aus dem Zeitplan von PyData Eindhoven 2024, der praktischerweise im JSON-Format verfügbar war. Aber was ist mit anderen Datenformaten? In der realen Welt kann es vorkommen, dass wir gebeten werden, andere Formate wie HTML, Word und PDF in unsere RAG aufzunehmen.

Formate wie HTML, Word und vor allem PDF können in Bezug auf ihre Struktur sehr unberechenbar sein, was es uns schwer macht, sie konsistent zu parsen. PDF-Dokumente können Bilder, Diagramme, Tabellen, Text, einfach alles enthalten. Nehmen wir also diese Herausforderung an und steigen wir auf Stufe 3 auf: Fortgeschrittene Datenformate.
Stufe 3: Erweiterte Datenformate
Auf dieser Ebene geht es darum, anspruchsvolle Datenformate wie HTML, Word oder PDF in unser RAG zu übernehmen. Dies erfordert zusätzliche Überlegungen, um es richtig zu machen. Im Moment konzentrieren wir uns auf PDFs.
Nehmen wir also einige PDFs als Beispiel. Ich habe einige Dokumente über die Falcon 9 Rakete von Space X gefunden:
 |
 |
 |
|---|---|---|
| Benutzerhandbuch (pdf) | Kostenvoranschläge (pdf) | Fähigkeiten & Dienstleistungen (pdf) |
Jetzt wollen wir diese Dokumente zunächst in Rohtext zerlegen, so dass wir den Text anschließend chunk- und einbetten können. Zu diesem Zweck verwenden wir einen PDF-Parser für Python wie pypdf. Praktischerweise gibt es einen LangChain-Loader für pypdf:
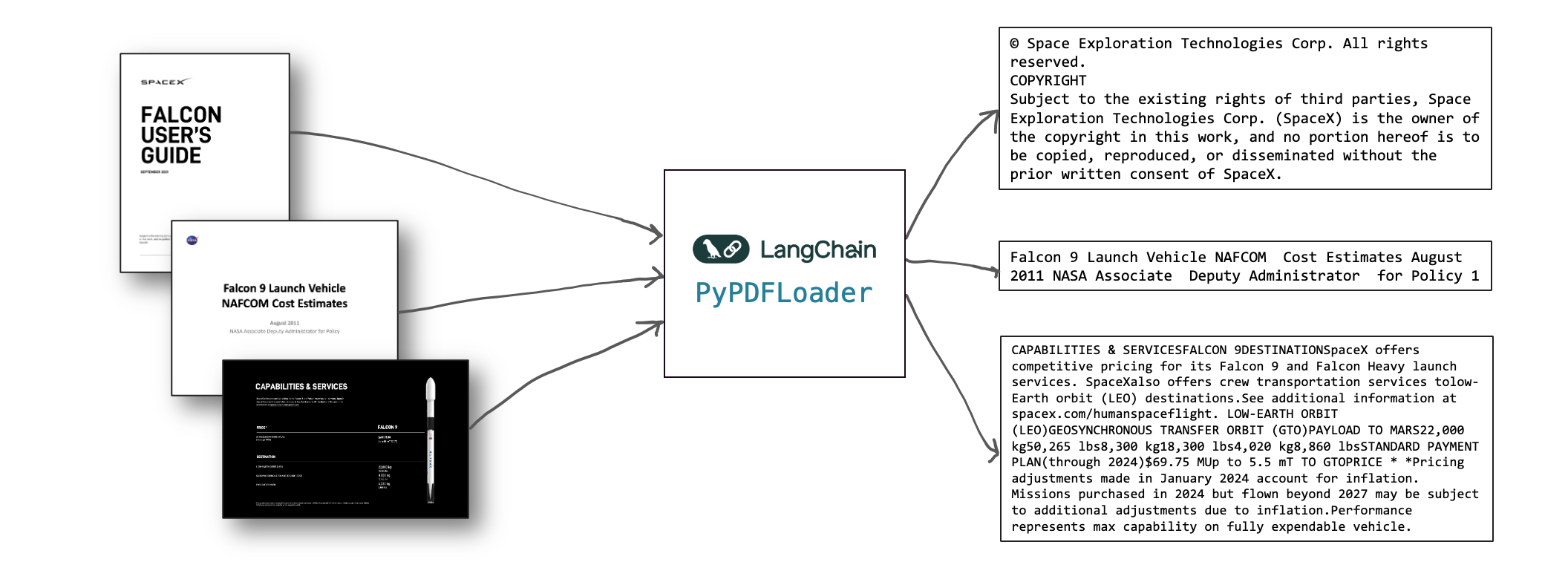
Mit pypdf können wir diese PDFs in Rohtext umwandeln. Beachten Sie, dass es noch viele weitere Möglichkeiten gibt, siehe die LangChain API-Referenz. Es werden sowohl Offline-, lokale als auch Cloud-Lösungen angeboten, wie GCP Document AI, Azure Document Intelligence oder Amazon Textract.
Wenn wir einen solchen Schritt zum Parsen von Dokumenten eingerichtet haben, müssen wir unseren Schritt zum Abrufen von Dokumenten erweitern, um diese neue Komponente zu berücksichtigen:
Zeit, unser RAG zu testen! Wir haben den Rohtext in unsere Vektordatenbank eingebettet und aufgenommen und können nun Abfragen dazu machen. Lassen Sie uns nach den Kosten für den Start einer Falcon 9-Rakete fragen:

Prima, das ist die richtige Antwort. Versuchen wir es mit einer anderen Frage:"Wie hoch ist die Nutzlast, die ich mit der Falcon 9 Rakete zum Mars transportieren kann?":

Aua! Unsere RAG hat diese Antwort völlig falsch verstanden. Sie besagt, dass wir die doppelte Nutzlast auf den Mars bringen können, als erlaubt ist. Das ist ziemlich ungünstig, falls Sie sich auf eine Reise zum Mars vorbereiten wollten.
Wir müssen herausfinden, was schief gelaufen ist. Schauen wir uns den Kontext an, der an den LLM übergeben wurde:

Das erklärt so einiges. Der Kontext, den wir an den LLM weitergeben, ist schwer zu lesen und enthält eine Tabelle, die auf unübersichtliche Weise kodiert ist. Genau wie uns fällt es dem LLM schwer, daraus einen Sinn zu ziehen. Daher müssen wir diese Informationen in der Eingabeaufforderung besser kodieren, damit unser LLM sie verstehen kann.
Wenn wir Tabellen unterstützen möchten, können wir einen zusätzlichen Verarbeitungsschritt einführen. Eine Möglichkeit ist die Verwendung von Computer-Vision-Modellen zur Erkennung von Tabellen in unseren Dokumenten, wie table-transformer. Wenn eine Tabelle erkannt wird, können wir ihr eine besondere Behandlung zukommen lassen. Wir können zum Beispiel Tabellen in unserer Eingabeaufforderung als Markdown kodieren:

Nachdem wir die Tabelle in unserem Python-Code erkannt und in ein natives Format geparst haben, können wir sie anschließend in Markdown kodieren. Übergeben wir sie stattdessen an unseren LLM und sehen wir, was er diesmal antwortet:
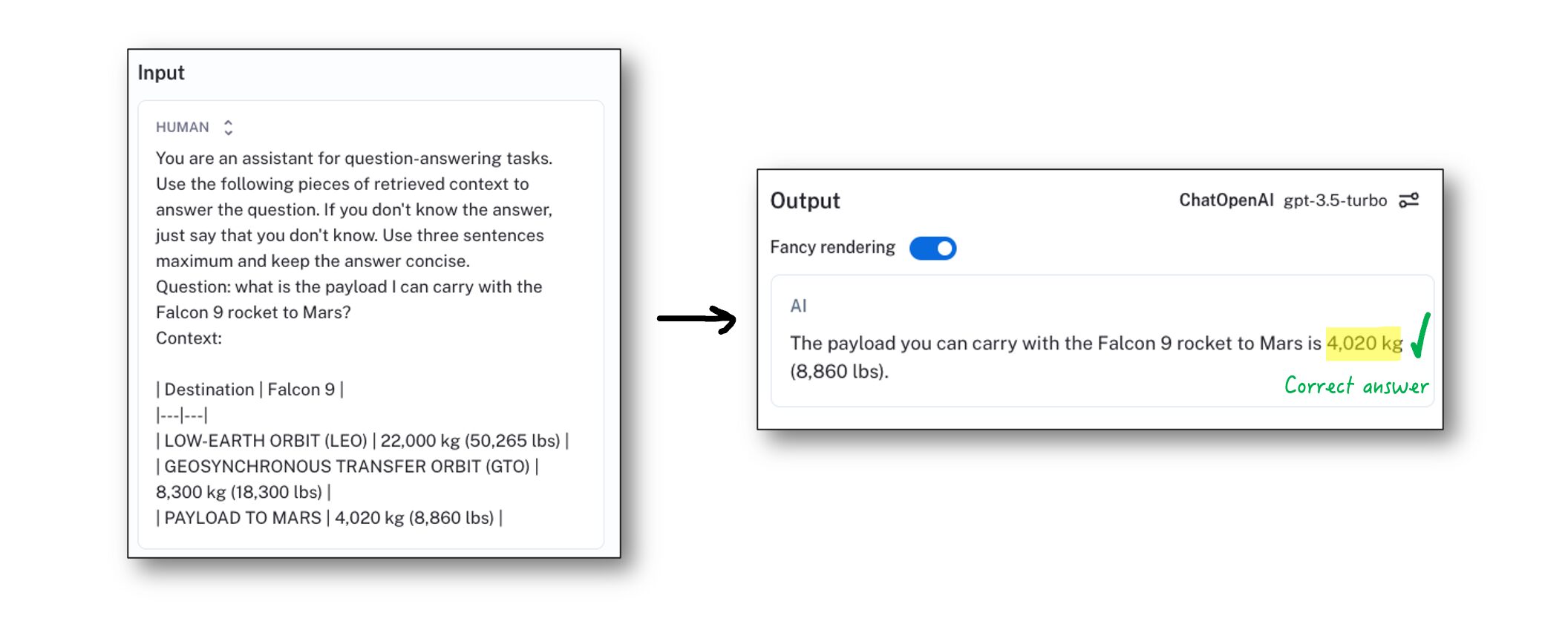
Hurra! Diesmal haben wir es richtig gemacht. Der von uns verwendete LLM konnte die Markdown-Tabelle problemlos interpretieren und den richtigen Wert für die Beantwortung der Frage ermitteln. Beachten Sie, dass wir die Tabelle in unserem Abfrageschritt immer noch abrufen können müssen. Bei dieser Vorgehensweise wird davon ausgegangen, dass wir einen Abfrageschritt entwickelt haben, der in der Lage ist, die Tabelle anhand der Benutzerfrage abzurufen.
Allerdings muss ich etwas zugeben. Das Modell, das wir für diese Aufgabe verwendet haben, war GPT-3.5 turbo, ein reines Textmodell. Es gibt inzwischen neuere Modelle, die mehr als nur Text verarbeiten können, nämlich multimodale Modelle. Schließlich haben wir es mit PDFs zu tun, die man auch als eine Reihe von Bildern betrachten kann. Können wir solche multimodalen Modelle nutzen, um unsere Fragen besser zu beantworten? Lassen Sie es uns in Level 4: Multimodal herausfinden.
Ebene 4: Multimodal
Auf dieser letzten Ebene werden wir uns mit den Möglichkeiten der multimodalen Modelle befassen. Eines davon ist GPT-4o, das für Mai 2024 angekündigt wurde:

Dies ist ein sehr leistungsfähiges Modell, das Audio, Bild und Text verstehen kann. Das heißt, wir können es mit Bildern als Teil einer Eingabeaufforderung füttern. Wenn wir in unserem Suchschritt die richtigen PDF-Seiten abrufen können, können wir diese Bilder in die Eingabeaufforderung einfügen und dem LLM unsere ursprüngliche Frage stellen. Das hat den Vorteil, dass wir Inhalte verstehen können, die bisher nur schwer in Text zu kodieren waren. Außerdem sind Inhalte, die wir als Text interpretieren und kodieren, mehr Konvertierungsschritten ausgesetzt, wodurch das Risiko besteht, dass Informationen bei der Übersetzung verloren gehen.
Nehmen wir zum Beispiel dieselbe Tabelle, die wir zuvor hatten, und beantworten wir die Frage mit einem multimodalen Modell. Wir können die abgerufenen PDF-Seiten als Bilder kodieren und sie direkt in die Eingabeaufforderung einfügen:

Beeindruckend. Der LLM hat die richtige Antwort gegeben. Wir sollten uns jedoch darüber im Klaren sein, dass das Einfügen von Bildern in die Eingabeaufforderung mit einer ganz anderen Token-Verwendung einhergeht als die Markdown-Tabelle, die wir zuvor als Text eingefügt haben:

Das ist ein immenser Anstieg der Kosten. Multimodale Modelle können unglaublich leistungsfähig sein, um Inhalte zu interpretieren, die sonst nur sehr schwer in Text zu kodieren sind, solange es die Kosten wert ist ✓.
Schlusswort
Wir haben RAG in 4 Komplexitätsstufen erforscht. Wir sind vom Aufbau unserer ersten einfachen RAG zu einer RAG übergegangen, die multimodale Modelle nutzt, um Fragen auf der Grundlage komplexer Dokumente zu beantworten. Jede Stufe bringt neue Komplexitäten mit sich, die auf ihre eigene Weise gerechtfertigt sind. Zusammengefasst sind die RAG-Stufen:
| Stufe 1 Basic RAG |
Level 2 Hybride Suche |
Level 3 Fortgeschrittene Datenformate |
Level 4 Multimodal |
|---|---|---|---|
| Die wichtigsten Schritte von RAG sind 1) Abruf und 2) Generierung. Wichtige Komponenten dafür sind Einbettung, Vektorsuche unter Verwendung einer Vektordatenbank, Chunking und ein Large Language Model (LLM). | Die Kombination von Vektorsuche und Schlagwortsuche kann die Abrufleistung verbessern. Die Suche nach spärlichem Text kann mit: TF-IDF und BM- 25. Reciprocal Rank Fusion kann verwendet werden, um zwei Suchmaschinen-Rankings zusammenzuführen. | Unterstützt Formate wie HTML, Word und PDF. PDF kann Bilder, Diagramme, aber auch Tabellen enthalten. Tabellen benötigen eine gesonderte Behandlung, z.B. mit Computer Vision, um die Tabelle dann dem LLM als Markdown zur Verfügung zu stellen. | Multimodale Modelle können Audio, Bilder und sogar Video verarbeiten. Solche Modelle können bei der Verarbeitung komplexer Datenformate helfen, indem sie z.B. PDFs als Bilder in das Modell einspeisen. Wenn die zusätzlichen Kosten den Nutzen wert sind, können solche Modelle unglaublich leistungsfähig sein. |
RAG ist eine sehr leistungsfähige Technik, die Unternehmen viele neue Möglichkeiten eröffnen kann. Die RAG-Stufen helfen Ihnen dabei, die Komplexität Ihrer RAG zu verstehen und zu erkennen, was mit RAG schwierig und was einfacher zu machen ist. Also: Was ist Ihr Level?
Wir wünschen Ihnen viel Erfolg beim Aufbau Ihrer eigenen RAG.
Verfasst von

Jeroen Overschie
Machine Learning Engineer
Jeroen is a Machine Learning Engineer at Xebia.




Contact