Die meisten Softwarelösungen auf verschiedenen Plattformen verfügen mit Sicherheit über Suchfunktionen, die Daten aus Datenquellen abfragen und der konsumierenden Anwendung zur Verfügung stellen müssen. Die Suchfunktion einer Anwendung kann ein Suchfeld in der Benutzeroberfläche oder eine interne Datenabfrage sein.
Bei Softwarelösungen mit großen Datenbanken kommt es aus verschiedenen Gründen zu Problemen mit der Ladeleistung, die höchstwahrscheinlich auf die Kombination von Datenstrukturen (z.B. Tabellen-Joins) und Abfragen (z.B. Abfragen) zurückzuführen sind. Dies gilt auch dann, wenn wir auf Datenbankebene Cluster, Indizes, materialisierte Ansichten usw. einführen, um die Abfrageleistung zu verbessern. Die Ausführung von Abfragen verlangsamt sich, wenn die Datensätze und Indizes wachsen.
Lucene
Apache Lucene ist eine leistungsstarke Textsuchmaschine, die sich für nahezu jede Anwendung eignet, die eine Volltextsuche erfordert.(Mehr Details hier.)
Es kann sogar die Funktion "Meinten Sie?" wie bei der Google-Suche unterstützen, die Vorschläge für falsche/unerkannte Wörter liefert.
Warum ist Lucene schneller?
Lucene ist aufgrund seiner invertierten Indextechnik sehr schnell bei der Suche nach Daten. Normalerweise strukturieren Datenquellen die Daten als Objekt oder Datensatz, die ihrerseits Felder und Werte haben. Eine Suche erfolgt von oben nach unten, d.h. es wird nach Objekten gesucht, die Felder mit übereinstimmenden Werten haben, und diese Objekte werden zurückgegeben.
Beim invertierten Index indiziert Lucene alle möglichen Kombinationen von Werten in Dokumenten. Bei der Suche werden zunächst die Wertekombinationen mit einigen schnellen Algorithmen abgeglichen und Dokumente (Objekte) zurückgegeben, die Felder mit diesen Werten enthalten.
Index- und Suchalgorithmen machen Lucene schneller als alle bekannten Datenbanken.
Freigabe von Indexdateien
Da die Erstellung von Lucene-Indizes ein zeitaufwändiger Prozess ist, können die Indizes auf einem Rechner erstellt und an die Entwicklungsteams vor Ort und im Ausland verteilt werden. Die Teams können die Indexdateien dann einfach an einem konfigurierten Ort im Dateisystem ablegen und verwenden.
Architektur
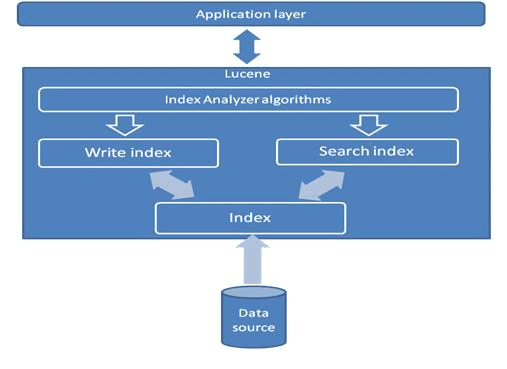
Lucene Indizierung
Programmierer von Softwarelösungen können eine Lucene-Schicht einführen, die alle zugehörigen Daten aus der Datenbank als Dokumente im Lucene-Index indiziert. Dies geschieht programmatisch durch eine einmalige Abfrage der Datenbank, die Erstellung von gemappten Objekten für die Datensätze und die Serialisierung dieser Objekte als Lucene-Dokumente. Diese Dokumente können eine eindeutige ID als Schlüssel haben. Wir können beispielsweise die Details der Abteilungs- und der Angestelltentabelle in einem Objekt zusammenfassen und sie als Dokumente in einem Lucene-Index mit einem Dokument pro Mitarbeiter indizieren. Die Mitarbeiter-ID oder der Code kann der Schlüssel sein.
Lucene kann auch Dokumentdateien wie Word-, PDF-, HTML- und Textdateien indizieren und durchsuchen. Die erstmalige Indizierung von Lucene ist ein kostspieliger Prozess, daher sollten Sie darauf achten, dass die erstmalige Indizierung außerhalb der Hauptgeschäftszeiten erfolgt.
Lucene Suche
Normalerweise würden Entwickler eine Such- oder Abfragefunktion einer Anwendung als Datenbankabfrage programmieren und Datensätze zurückgeben. Mit lucene müssen die Entwickler zunächst den lucene-Index programmatisch abfragen, um schnell die Dokumente zu finden, die den Suchkriterien entsprechen. Die zurückgegebenen Dokumente können nach den gewünschten Daten durchsucht und dem Benutzer angezeigt werden.
Alternativ können Sie auch die Kennung oder ein bestimmtes Feld (z.B. den Mitarbeitercode) aus den zurückgegebenen Dokumenten abrufen. Diese Ids oder Felder können anschließend für die Abfrage der Datenbank verwendet werden. Dies ist sehr nützlich, da Lucene Millionen von Dokumenten schneller durchsuchen kann als Millionen von Datensätzen in der Datenbank. Die Idee ist, Lucene zuerst zu durchsuchen, eine Teilmenge der übereinstimmenden Datensätze zu erhalten und diese Teilmenge zur Abfrage der Datenbank zu verwenden.
Wir haben sehr gute Erfahrungen mit der kombinierten Leistung des Filterns auf dem Lucene-Index gemacht, bevor wir die Datenbank abfragen. Wir haben die bewährte Leistung in alle unsere bestehenden und neuen Softwarelösungen integriert. Die Leistungsverbesserung wurde mit über 150% schneller als die Datenbanksuche protokolliert.
Index aktualisieren
Der Lucene-Index muss häufig aktualisiert werden, wenn Daten in der Datenbank aktualisiert werden. Dies kann asynchron von Programmen mit Threads erledigt werden, die nur die geänderten Datensätze neu indizieren können. Lucene ist in der Lage, einen Snapshot-Index aufrechtzuerhalten, um die Suche in der Anwendung fortzusetzen, auch wenn gerade eine Neuindizierung stattfindet.
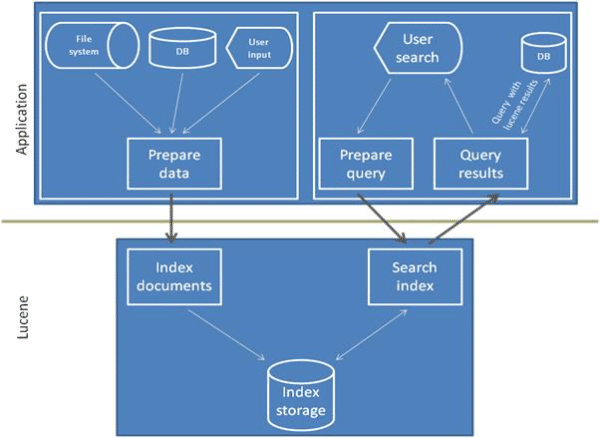
WorkFlow
Verfasst von

Byju Parameshwaran Nair
Unsere Ideen
Weitere Blogs

Wo die GitHub Copilot Erweiterungspunkte die Governance brechen
Viele der jüngsten Ergänzungen des GitHub Copilot-Ökosystems bieten einen echten Mehrwert für einzelne Entwickler, erweitern aber auch die...
Rob Bos


Contact