Blog
Wie Sie Dagster verwenden, um Google Cloud Functions (oder eine andere externe Ausführungsumgebung) zu orchestrieren

Ich weiß, nicht wahr? Dies sollte eine triviale Aufgabe sein. Sie haben einen bestehenden Code, der z.B. in einer Google Cloud Function eingesetzt wird, und möchten, dass Dagster diesen orchestriert. Das ist z.B. in Airflow einfach zu bewerkstelligen, aber Dagster hat diese Funktionalität erst kürzlich durch das dagster-pipes Bibliothek:
Dagster Pipes ist ein Toolkit für den Aufbau von Integrationen zwischen Dagster und externen Ausführungsumgebungen. Es standardisiert den Prozess der Übergabe von Parametern, der Einspeisung von Kontextinformationen, der Aufnahme von Protokollen und der Sammlung von Metadaten und bleibt dabei unabhängig von der Art und Weise, wie Remote-Berechnungen in diesen Umgebungen gestartet werden. Dies ermöglicht die Trennung von Orchestrierung und Geschäftslogik im Dagster-Ökosystem.
Prima! So können wir die Geschäftslogik in jeder beliebigen Ausführungsumgebung ausführen. Da es noch keine offizielle Integration mit Google Cloud Services gibt, werden wir die Bibliothek dagster-pipes auf die Probe stellen, indem wir sie erweitern, um Google Cloud Functions als externe Ausführungsumgebung zu verwenden.
⚒️ Einrichten
Den Code für diesen Beitrag finden Sie auf GitHub. Wenn Sie mitmachen wollen, verwenden Sie die Anweisungen in der README, um Ihre Umgebung einzurichten.
Das Repository enthält zwei Ordner mit Python-Code:
- dagster: Dies enthält den Quellcode des Dagster DAG. Wir werden diese lokal ausführen. Wenn wir das Asset materialisieren, das die Cloud-Funktion verwendet, sollte das Asset die Cloud-Funktion aufrufen, damit unsere Geschäftslogik ausgeführt wird. Wenn die Cloud-Funktion abgeschlossen ist, nehmen wir die von der externen Ausführungsumgebung generierten Protokolle auf, damit sie in der Dagster-Benutzeroberfläche angezeigt werden.
- cloud_function: Dies enthält den Quellcode der Cloud-Funktion (unsere externe Ausführungsumgebung). Diese Funktion sollte Eingabeparameter und Kontextinformationen (z. B. den Namen des Assets) vom Orchestrator entgegennehmen, unsere Geschäftslogik ausführen und Protokolle an einen geeigneten Ort schreiben, wo sie vom Orchestrator abgeholt werden können.
Für diese Implementierung habe ich mich stark auf die AWS-Lambda-Implementierung von dagster-pipes und den Quellcode von dagster-pipes gestützt.
☁️ Die Cloud-Funktion
Es gibt ein paar Dinge, die wir hier brauchen:
- Die eigentliche Geschäftslogik. Wir generieren einige gefälschte Daten und schreiben sie in eine Deltatabelle im Cloud-Speicher.
- Eine benutzerdefinierte
message writer, die Protokolle, Metadaten und Ereignisse, die in der Ausführungsumgebung generiert werden, erfasst und an einem Ort ablegt, an dem der Orchestrator sie abrufen kann.
Implementierung der Cloud-Funktion
Wenn Sie schon einmal mit Cloud-Funktionen gearbeitet haben, dann sollte Ihnen der Aufbau bekannt vorkommen. Wir haben einen Einstiegspunkt ('main'), der eine flask.Request Eingabe entgegennimmt. Anhand der Anfrage können wir die Trace-ID analysieren und alle Eingaben und Kontextinformationen abrufen, die der Orchestrator an die Ausführungsumgebung übergeben hat. Diese werden wiederum als Eingaben für den open_dagster_pipes Kontextmanager verwendet.
Zum Beispiel:
- Der Orchestrator übergibt die Eingabe 'dl_bucket' und wir können mit
event["dl_bucket"]darauf zugreifen. - Wir verwenden
pipes.asset_key, um den Namen des Assets im Orchestrierungsdienst abzurufen. - Wir melden den Speicherort der Asset-Tabelle zurück, indem wir dies als Metadaten in der Methode
pipes.report_asset_materializationangeben.
def main(request: flask.Request):
event = request.get_json()
trace_header = request.headers.get("X-Cloud-Trace-Context") or "local"
trace = trace_header.split("/")[0]
with open_dagster_pipes(
params_loader=PipesMappingParamsLoader(event),
message_writer=PipesCloudStorageMessageWriter(
client=google.cloud.storage.Client(),
),
) as pipes:
pipes.log.info(f"Cloud function version: {__version__}")
pipes.log.info(f"Cloud function trace: {trace}")
dl_bucket = event["dl_bucket"]
pipes.log.debug(f"Storing data in bucket {dl_bucket}")
table_location = f"{dl_bucket}/{pipes.asset_key}"
pipes.log.debug(f"Writing data to {table_location}")
df = get_fake_data()
df.write_delta(table_location, mode="append")
pipes.report_asset_materialization(
metadata={"table_location": table_location},
data_version="alpha",
)
# Force the context to be reinitialized on the next request
# see: https://github.com/dagster-io/dagster/issues/22094
PipesContext._instance = None
return "OK", 200
Im Gegensatz zu dem, was Sie vielleicht erwarten, wird dadurch keine direkte Verbindung zwischen dem Orchestrator und der Ausführungsumgebung hergestellt. Die gesamte Kommunikation zurück zum Orchestrator wird über message_writer abgewickelt, das zu einer eigenen Klasse namens PipesCloudStorageMessageWriter.
Im Wesentlichen besteht alles, was diese Message Writer-Klasse tut, darin, einen Kanal zurückzugeben, dessen Aufgabe es ist, alle Ereignisse und Protokolle zu erfassen, während der open_dagster_pipes Kontextmanager aktiv ist, und diese in den Cloud-Speicher zu schreiben, damit der Orchestrator-Prozess sie später herunterladen kann.
class PipesCloudStorageMessageWriterChannel(PipesBlobStoreMessageWriterChannel):
def __init__(
self,
client: google.cloud.storage.Client,
bucket: str,
key_prefix: Optional[str],
*,
interval: float = 10,
):
super().__init__(interval=interval)
self._client = client
self._bucket = client.bucket(bucket)
self._key_prefix = key_prefix
def upload_messages_chunk(self, payload: IO, index: int) -> None:
key = f"{self._key_prefix}/{index}.json" if self._key_prefix else f"{index}.json"
blob = self._bucket.blob(key)
blob.upload_from_string(payload.read())
Ein wichtiges Merkmal des Message Writers ist, dass er mit einer Message Reader (siehe unten) Implementierung im Orchestrator-Prozess gepaart ist. Der Nachrichtenleser ist für die Definition der Variablen 'bucket' und 'key_prefix' verantwortlich. Der Orchestrator fügt diese Variablen dann in den Kontext ein und sendet sie an die Ausführungsumgebung, so dass wir sie hier abrufen können:
...
bucket = _assert_env_param_type(params, "bucket", str, self.__class__)
key_prefix = _assert_opt_env_param_type(params, "key_prefix", str, self.__class__)
...
Wenn wir unser Asset an dieser Stelle materialisieren, sollten diese Protokolle im Cloud-Speicher auftauchen:
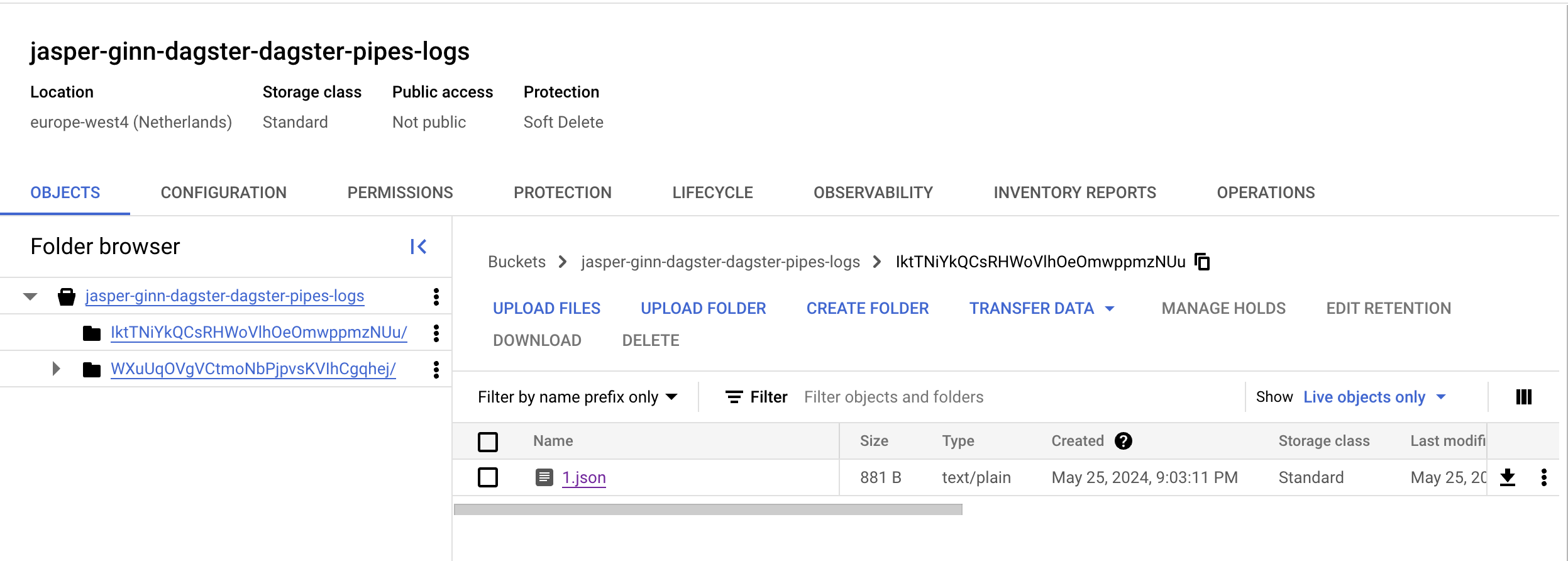
Der Orchestrator
Die Orchestrierungslogik sieht aus wie normaler Dagster-Code. Wir definieren eine Asset-Definition, die eine Ressource verwendet, und richten einen Code-Speicherort mit einem Definitions Objekt ein:
@asset(
description="A cloud function that writes fake data to a delta table.",
)
def cloud_function_pipes_asset(
context: AssetExecutionContext, pipes_function_client: PipesCloudFunctionClient
) -> MaterializeResult:
return pipes_function_client.run(
context=context,
# function_url="http://127.0.0.1:8080",
function_url="https://europe-west4-jasper-ginn-dagster.cloudfunctions.net/dagster-pipes-gcp-nprod",
event={
"dl_bucket": "gs://jasper-ginn-dagster-data-lake/",
},
).get_materialize_result()
defs = Definitions(
assets=[cloud_function_pipes_asset],
resources={
"pipes_function_client": PipesCloudFunctionClient(
message_reader=PipesCloudStorageMessageReader(
bucket="jasper-ginn-dagster-dagster-pipes-logs",
client=google.cloud.storage.Client(),
)
)
},
)
In dem obigen Code: - Wir verwenden eine benutzerdefinierte PipesBlobStoreMessageReader, um Protokolle aus dem Cloud-Speicher zu lesen. - Wir verwenden eine benutzerdefinierte PipesClient Ressource. Diese Ressource ist dafür verantwortlich, z.B. den dagster AssetExecutionContext, Umgebungsvariablen und die Anfragedaten zu analysieren und diese dann an die Klassen und Funktionen zu übergeben, die die Cloud-Funktion auslösen und die Protokolle laden.
Lassen Sie uns diese Teile einzeln auseinandernehmen.
Die PipesBlobStoreMessageReader
Diese Klasse ist für das Lesen von Protokollen zuständig, die vom 'Message Writer' (siehe oben) in den Cloud-Speicher geschrieben wurden. Das Wichtigste in dieser Klasse ist die download_messages_chunk Methode. Diese Methode ruft die Protokolle ab, die als JSON-Einträge in einem Cloud-Speicher-Bucket gespeichert sind. Wenn der Eintrag nicht existiert, gibt sie None zurück. So weiß der Leser, dass er fertig ist.
def download_messages_chunk(self, index: int, params: PipesParams) -> Optional[str]:
key = f"{params['key_prefix']}/{index}.json"
bucket = self.client.bucket(self.bucket)
blob = bucket.blob(key)
if blob.exists():
return blob.download_as_text()
else:
return None
Die PipesClient
Die PipesClientist dafür verantwortlich, z.B. den dagster AssetExecutionContext, Umgebungsvariablen und die Anfragedaten zu analysieren und diese dann an die Klassen und Funktionen zu übergeben, die die Cloud-Funktion auslösen und die Protokolle laden. Der wichtige Teil des Codes in PipesClient besteht darin, die Anfragedaten zu konstruieren und die Cloud-Funktion aufzurufen:
...
if isinstance(self._context_injector, PipesCloudFunctionEventContextInjector):
payload_data = {
**event,
**session.get_bootstrap_env_vars(),
}
else:
payload_data: Mapping[str, Any] = event # type: ignore
response = invoke_cloud_function(
url=function_url,
data=payload_data,
)
...
Im Hintergrund passiert hier eine ganze Menge, aber wichtig ist, dass die Methode session.get_bootstrap_env_vars alle Kontextinformationen, die in den Assets gespeichert sind
AssetExecutionContext
und anderen Pipeline-Parametern gespeichert sind, in eine Ereignis-Nutzlast packt und diese an die Cloud-Funktion sendet.
Erinnern Sie sich daran, dass wir in der Cloud-Funktion message writer dieses Codestück verwendet haben, um den Bucket und key_prefix zu erhalten, wenn wir Protokolle in den Cloud-Speicher schreiben:
...
bucket = _assert_env_param_type(params, "bucket", str, self.__class__)
key_prefix = _assert_opt_env_param_type(params, "key_prefix", str, self.__class__)
...
Diese beiden Parameter werden auch durch die Methode session.get_bootstrap_env_vars in die Nutzlast injiziert, weshalb wir in der Cloud-Funktion auf sie zugreifen können. Diese beiden Variablen wiederum sind in der Klasse PipesCloudStorageMessageReader über ihre Methodeget_params definiert:
@contextmanager
def get_params(self) -> Iterator[PipesParams]:
key_prefix = "".join(random.choices(string.ascii_letters, k=30)) # nosec
yield {"bucket": self.bucket, "key_prefix": key_prefix}
Beachten Sie, dass wir zwar den Aufruf der Cloud-Funktion aufrufen müssen, dies aber nicht zwangsläufig tun müssen, um Protokolle abzurufen. Wenn die Methode PipesClient.run abgeschlossen ist, gibt sie ein PipesClientCompletedInvocation Klasse. Diese Klasse ruft dann die entsprechende Funktion zum Herunterladen von Protokollen mit Hilfe der Klasse message reader auf.
✨ Materialisierung des Vermögenswerts
Wir sollten nun in der Lage sein, das Asset zu materialisieren und die Protokolle aus der externen Ausführungsumgebung abzurufen. Führen Sie just dd aus, um den dagster Webserver zu starten und das Asset zu materialisieren!
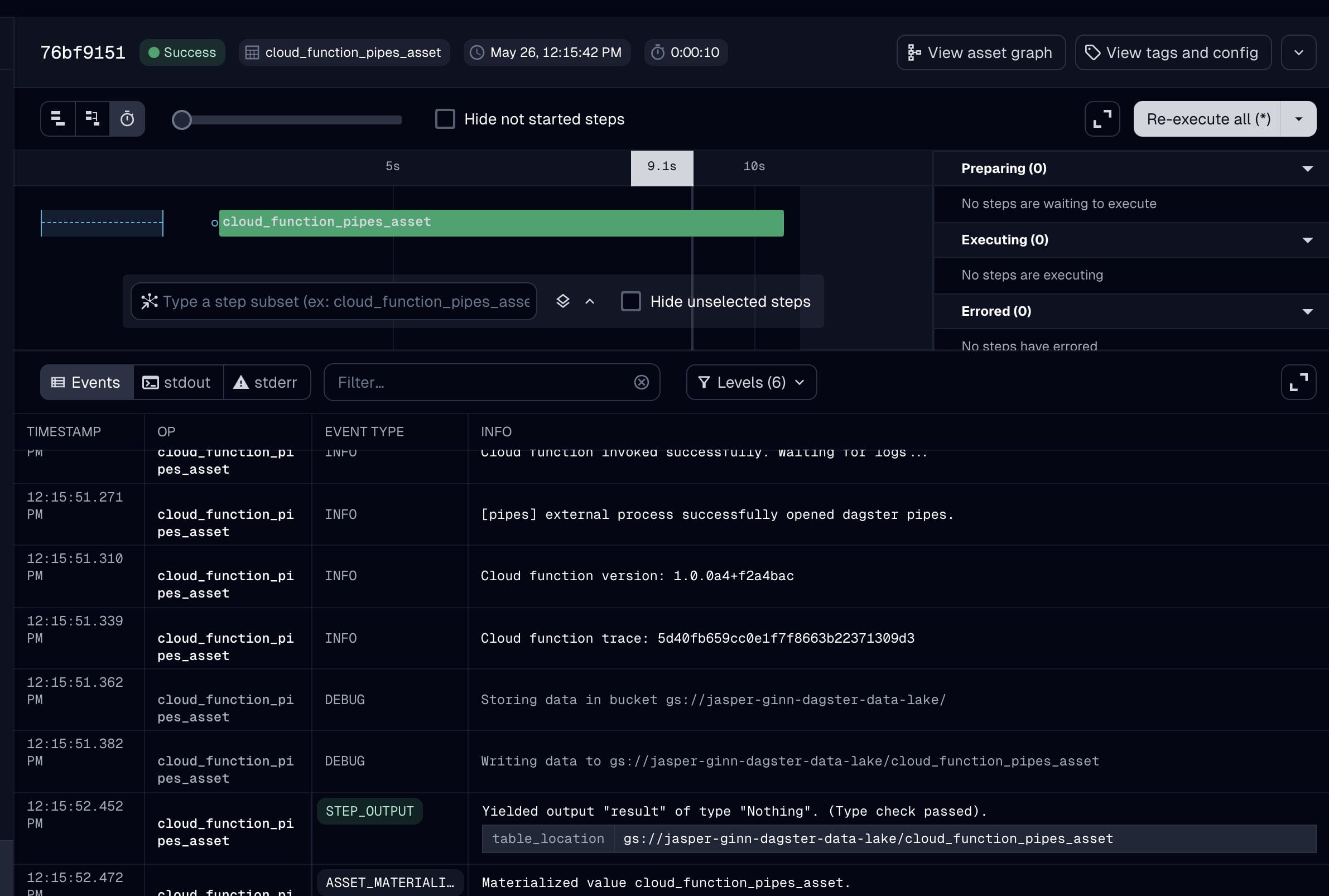
Wie Sie sehen können, wurde das Asset materialisiert, und die Metadaten und Protokolle wurden anschließend von dagster gesammelt und sind in der Benutzeroberfläche verfügbar.
Ceci n'est pas une pipe
Die von der Bibliothek 'dagster-pipes' bereitgestellte Funktionalität ist eine nützliche Funktion, die es Benutzern ermöglicht, Dienste in externen Ausführungsumgebungen zu orchestrieren. In diesem Beitrag haben wir die Bibliothek erweitert, indem wir Google Cloud Functions als externe Ausführungsumgebung hinzugefügt haben. Wenn Sie daran interessiert sind, Ihre eigene externe Ausführungsumgebung hinzuzufügen, dann schauen Sie sich die Dokumentation an.
Mit Dreamstudio generiertes Bild
Verfasst von

Jasper Ginn




Contact