Blog
Entmystifizierung von MLOps: Vom Notebook zur ML-Anwendung

Was ist dieses Ding namens MLOps? Vielleicht haben Sie schon davon gehört, aber nie wirklich verstanden, was es damit auf sich hat.
In diesem Blogbeitrag werden wir versuchen, MLOps zu entmystifizieren und Sie durch den Prozess zu führen, der Sie von einem Notebook zu Ihrer eigenen ML-Anwendung in Industriequalität führt. Im ersten Teil geht es um das Was und Warum von MLOps und im zweiten Teil um die technischen Aspekte von MLOps.
Dieser Beitrag basiert auf einem Tutorium, das auf der EuroPython 2023 in Prag gehalten wurde: How to MLOps: Experiment tracking & deployment und einem Code Breakfast bei Xebia Data zusammen mit Jeroen Overschie. Der Code wird hier zur Verfügung gestellt. Wir empfehlen Ihnen, dem Code zu folgen, während Sie den technischen Teil dieses Beitrags durcharbeiten.
Operationen des maschinellen Lernens: was und warum
MLOps, was zum Teufel?
Es scheint ein "Ops"-Hype im Gange zu sein. DevOps kommt Ihnen vielleicht bekannt vor, aber heutzutage gibt es noch viel mehr Begriffe: LLMOps, LegOps (nein, nicht Lego-Ops), und natürlich MLOps.
Abb. 1 
Aber was ist MLOps und warum brauchen wir noch einen weiteren "Ops"-Begriff im Bild?
MLOps steht für Machine Learning (ML) Operations. Schauen wir uns an, was das bedeutet.
Datenwissenschaft ist im Allgemeinen nicht operationalisiert
Betrachten Sie einen Datenfluss von einer Maschine oder einem Prozess bis hin zu einem Endbenutzer.
Abb. 2 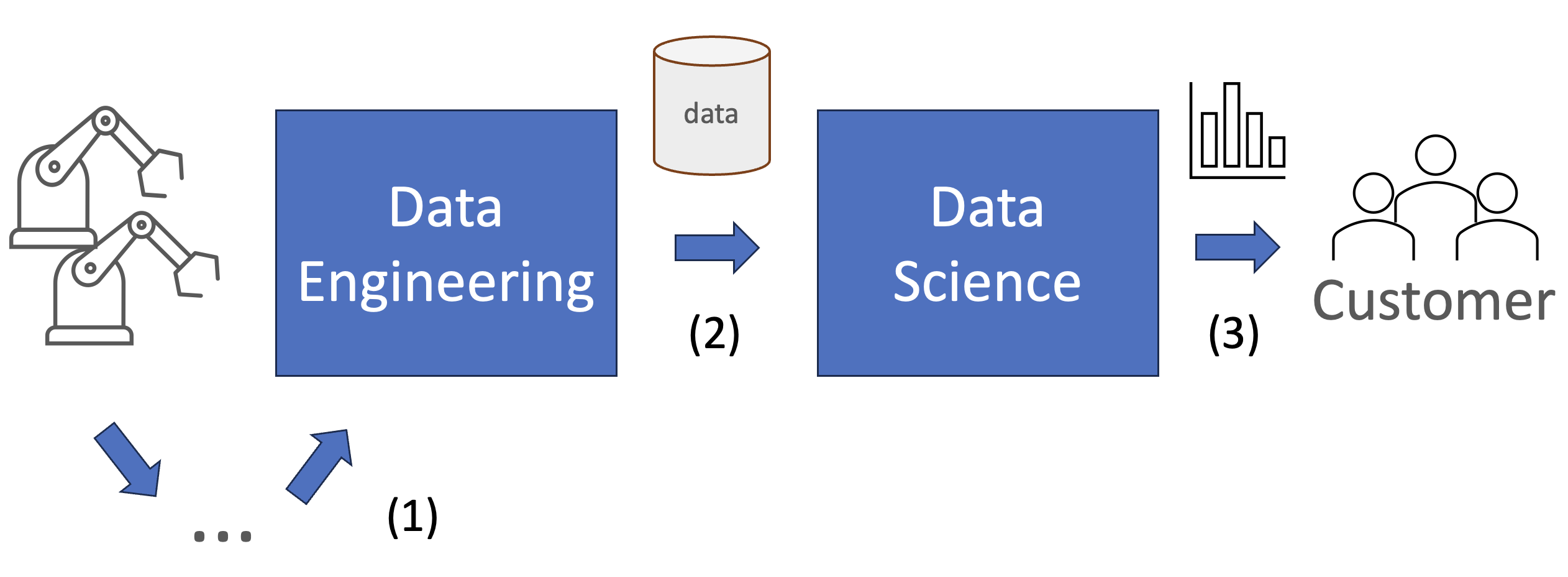
Im Allgemeinen ist der Datenfluss von der Maschine zum Data Engineer (1) gut funktionalisiert. Der Prozess ist automatisiert und es gibt Systeme, die einen zuverlässigen und konstanten Datenfluss gewährleisten.
Das Gleiche könnte man über den Data-Engineering-Schritt (2) sagen, auch wenn dieser von Unternehmen zu Unternehmen unterschiedlich ist. In diesem Schritt werden automatisierte Pipelines eingerichtet, um die Zuverlässigkeit, Qualität und Zugänglichkeit der Daten für das Unternehmen zu gewährleisten. Sagen wir also, auch dieser Schritt ist operationalisiert.
Im letzten Schritt (3) manipulieren Data Scientists (DS) oder Analysten die Daten weiter, um einen bestimmten Geschäftsfall oder Kunden zu bedienen. Das Problem ist, dass dieser Schritt oft vollständig manuell erfolgt und es an Standardisierung und Automatisierung mangelt.
Lassen Sie uns ein Beispiel betrachten:
Abb. 3 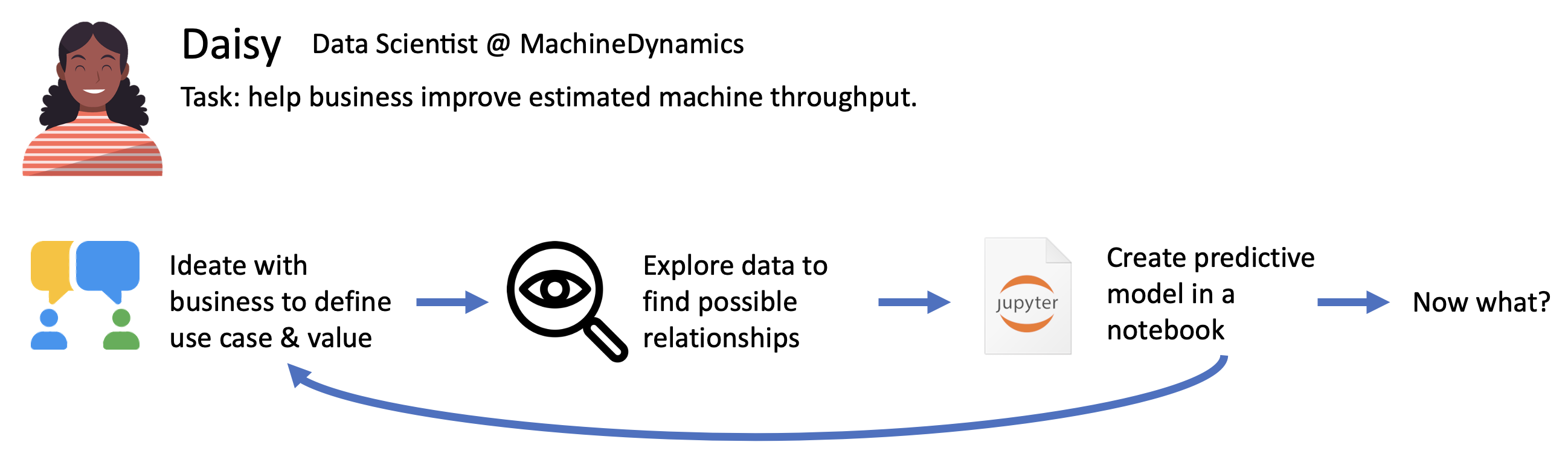
Daisy the DS folgt in der Regel demselben iterativen Prozess von der Idee für einen Anwendungsfall bis zur Erstellung einer Lösung in einem Notizbuch. Auf dem Weg dorthin erfindet sie das Rad vielleicht mehrmals neu. Außerdem lautet die große Frage am Ende: "Was nun?" Wie kommen wir vom Notebook zu einer tatsächlichen nachhaltigen ML-Lösung in der Produktion?
Ideales Szenario: der Lebenszyklus von MLOps
Im Idealfall folgt ein Projekt (oder Produkt) dem so genannten "MLOps-Lebenszyklus", der in verschiedenen Formen und Ausprägungen definiert werden kann. Die wichtigsten Aspekte dieses Lebenszyklus sind, dass er (1) durchgängig ist: vom Design bis zum Betrieb, und (2) iterativ: jeder Schritt im Zyklus kann viele Male wiederholt werden.
Abb. 4 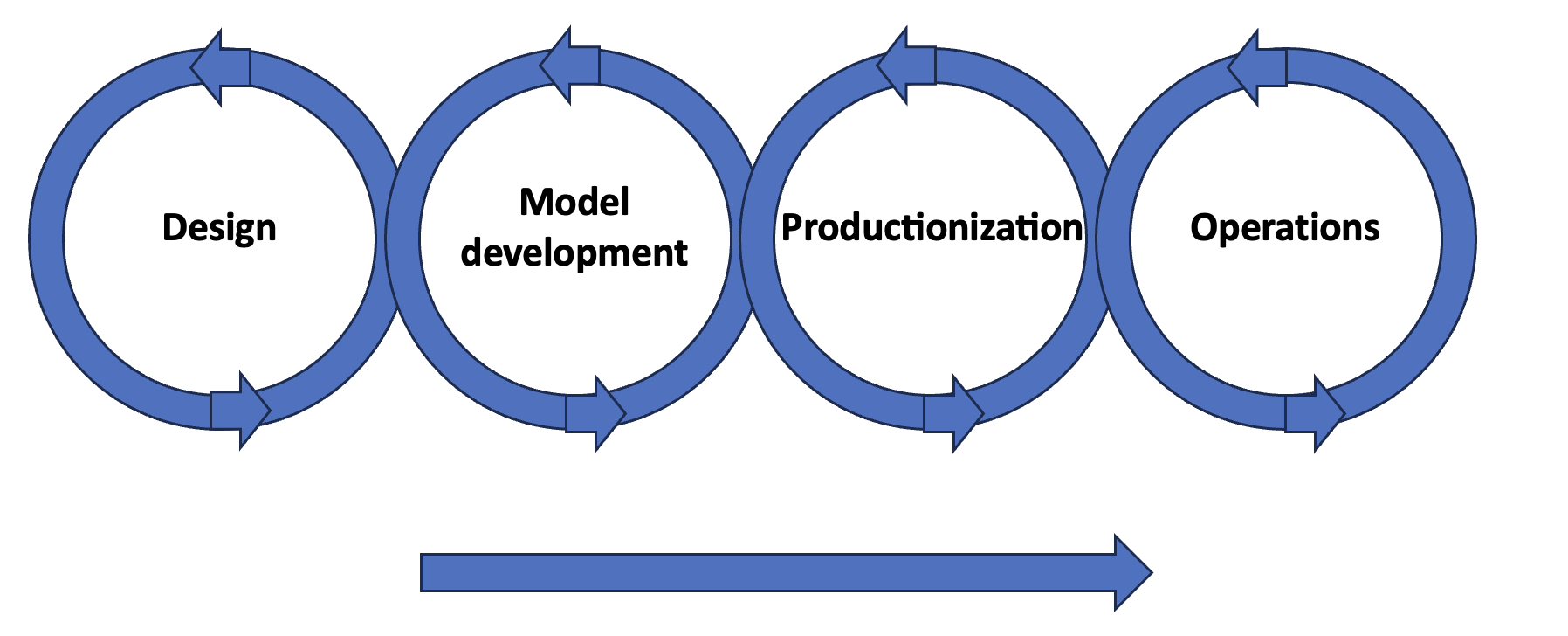
Jede der verschiedenen Phasen dient einem bestimmten Zweck:
- Design: Definition des Anwendungsfalls, Umfang und Bewertung des Geschäftswerts
- Modellentwicklung: Erstellen einer funktionierenden Lösung und Validierung
- Produktion: Paketierung/Containerisierung von Code, Erstellung einer Pipeline für Training und Bereitstellung
- Betrieb: Bereitstellung, Überwachung und Wartung
Gemeinsamer ML-Lebenszyklus
Das Problem mit Daisy in Abb. 3 ist, dass sie nicht dem Lebenszyklus von MLOps folgt, sondern nur einem Teil davon.
Abb. 5 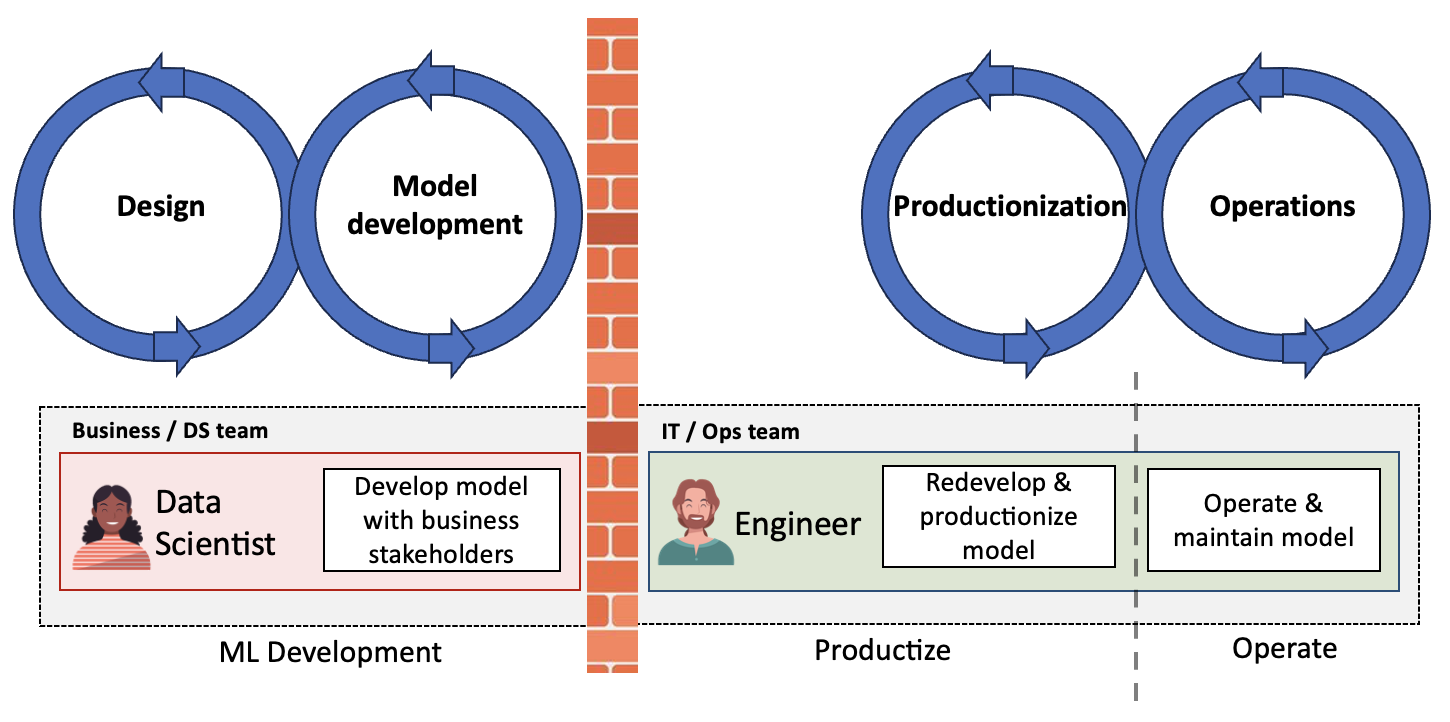
In vielen Unternehmen sind verschiedene Teams für unterschiedliche Teile des Lebenszyklus zuständig, wie in Abb. 5 dargestellt. Dies wird in diesem Blogpost ausführlicher beschrieben: MLOps: Warum und wie man End-to-End-Produktteams aufbaut.
Das ist ein Problem, weil es dabei zu einer großen Übergabe kommt. Diese Übergabe kann Folgendes verursachen:
- Verlust von Informationen, da das Betriebsteam nicht in die Entwicklung einbezogen wurde
- Zeitverlust durch häufiges Hin- und Herfahren
- Ausfälle. Das Ops-Team weiß möglicherweise nicht, wie man Modellfehler erkennt oder behebt, und das DS-Team weiß möglicherweise nicht, wie man Betriebsfehler erkennt oder behebt.
Mit anderen Worten, die Kluft zwischen den verschiedenen Teams im Laufe des MLOps-Lebens kann viele Kopfschmerzen verursachen.
MLOps: Schließen Sie die Lücke zwischen DS und Ops
Das Ziel von MLOps ist es, die Lücke zwischen Data Science (oder ML) und dem operativen Geschäft zu schließen und die Übergabe abzuschaffen. Ein weit verbreiteter Irrglaube ist, dass dies nur mit Technologie erreicht werden kann. Um die Lücke wirklich zu schließen und ML zu operationalisieren, müssen wir uns jedoch auf drei Achsen konzentrieren: Menschen, Prozesse und Technologie.
Abb. 6 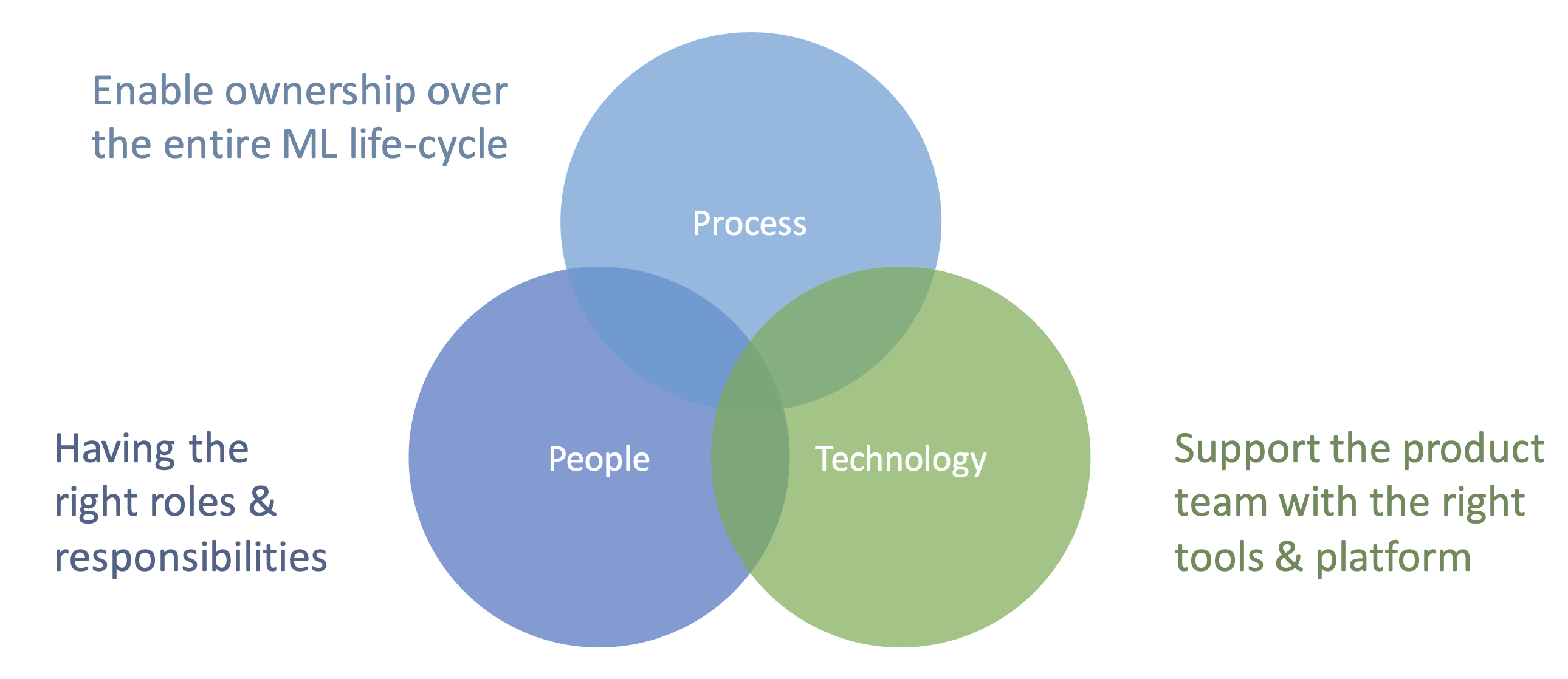
Im Fall von Daisy können wir zum Beispiel funktionsübergreifende Teams mit den richtigen Rollen und Verantwortlichkeiten einsetzen. Statt getrennter Teams, die an einem einzigen Projekt beteiligt sind, erhalten wir ein Team, das für den gesamten ML-Lebenszyklus verantwortlich ist.
Abb. 7 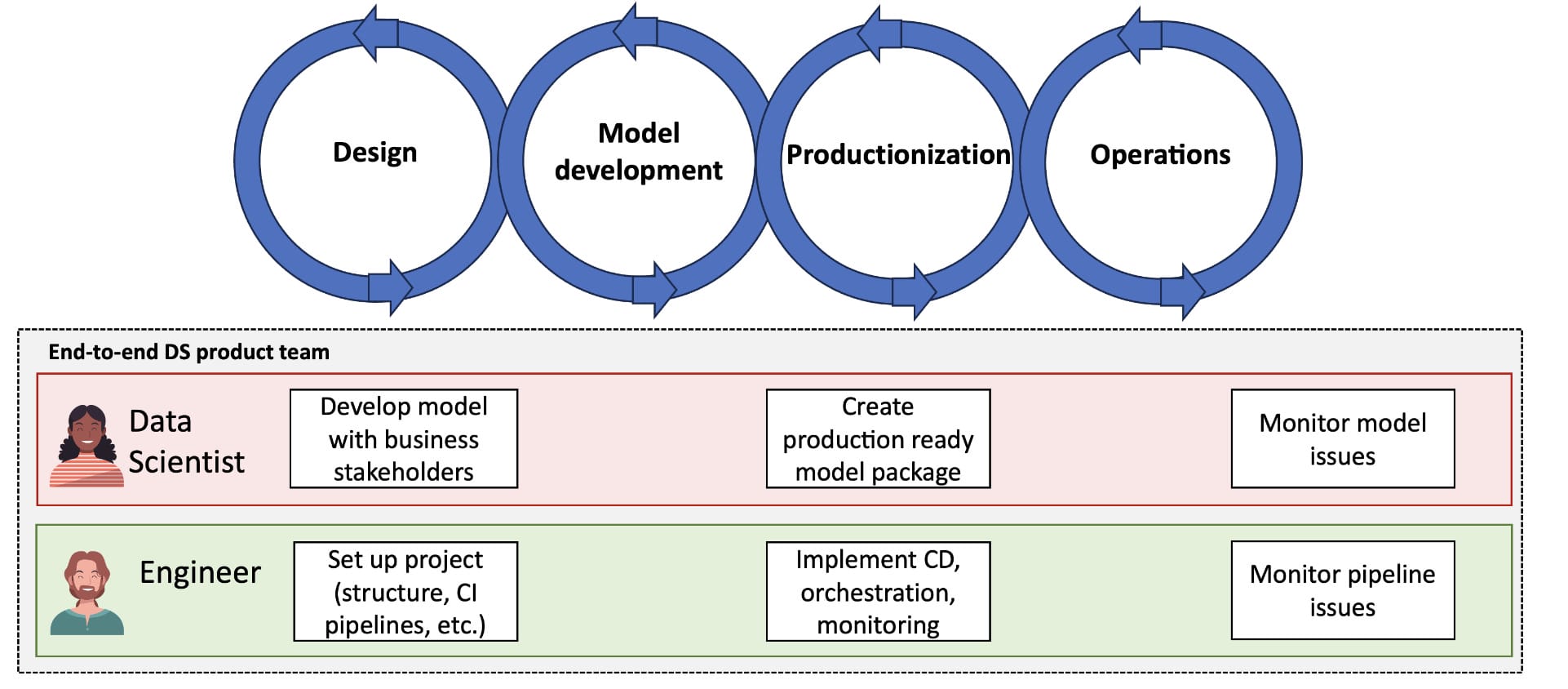
Was für eine Erleichterung, keine Kopfschmerzen mehr! Zumindest, wenn wir davon ausgehen, dass auch die richtigen Technologien und Prozesse vorhanden sind.
Leider ist dies nur selten der Fall. Daher werden wir im Folgenden einige der technischen Aspekte der Überführung Ihrer ML-Lösung vom Notebook in die Produktion näher beleuchten.
Operationalisierung des Prozesses vom Notizbuch zur Produktion
Nehmen wir an, wir haben ein Notizbuch, in dem wir eine ML-Lösung entwickeln. Welche Schritte können wir operationalisieren? Die Liste ist zu lang, als dass wir alles abdecken könnten, wie z.B. die Versionierung und Paketierung Ihres Codes, die Standardisierung Ihrer Entwicklungsumgebung und so weiter. Im Folgenden werden wir uns darauf konzentrieren, wie wir den Prozess der Experimentverfolgung, der Bereitstellung und des Einsatzes operationalisieren können. Es werden einige gängige Open-Source-Tools wie MLflow besprochen, aber die gleichen Prinzipien gelten auch für andere Tools, die Sie auf dem Markt finden können.
Experiment verfolgen
Eines der ersten Dinge, die wir operationalisieren können, ist der Prozess der Entwicklung, Validierung und des Vergleichs verschiedener Modelle.
Wenn Sie alleine an einem Projekt arbeiten, brauchen Sie eine strukturierte Methode, um den Überblick über Ihre bisherigen Experimente zu behalten. Wenn Sie mit mehreren Kollegen zusammenarbeiten, brauchen Sie eine Möglichkeit, die Fortschritte der anderen zu verfolgen, um zu verhindern, dass Sie das Rad neu erfinden.
Das gängigste Open-Source-Tool, mit dem Sie dies tun können, ist MLflow. Die meisten ML-Plattformen für Unternehmen (Vertex AI, Azure ML, Sagemaker) sind mit MLflow integriert.
Wie passt sie also in den Prozess? Sehen wir uns das Feld "Datenwissenschaft" in Abb. an. 2:
Abb. 8 ![]()
Der Prozess kann wie folgt aussehen:
- Sie und Ihre Kollegen entwickeln verschiedene Modelle mit unterschiedlichen Leistungswerten.
- Jeder Durchlauf jeder Person wird auf einem zentralen Experiment-Tracking-Server (MLflow) protokolliert. Sie können das Modell, den Code, die Punktzahlen und sogar die Zahlen auf dem Server protokollieren. So können Sie verschiedene Durchläufe leicht vergleichen und sehen, wer die beste Punktzahl hat.
- Das Modell mit der besten Punktzahl wird für die "Produktion" ausgewählt. Beachten Sie jedoch, dass wir es immer noch selbst dorthin bringen müssen! Wir können das beste registrierte Modell markieren, so dass wir es in späteren Schritten einfach wieder laden können.
Modell serviert
Wir können nun unsere Experimente verfolgen und das beste Modell auswählen. Unser Endbenutzer kann es jedoch noch nicht verwenden, denn wir können nicht erwarten, dass der Endbenutzer unser Notebook nimmt, das Modell lädt und es selbst ausführt...
Abb. 9 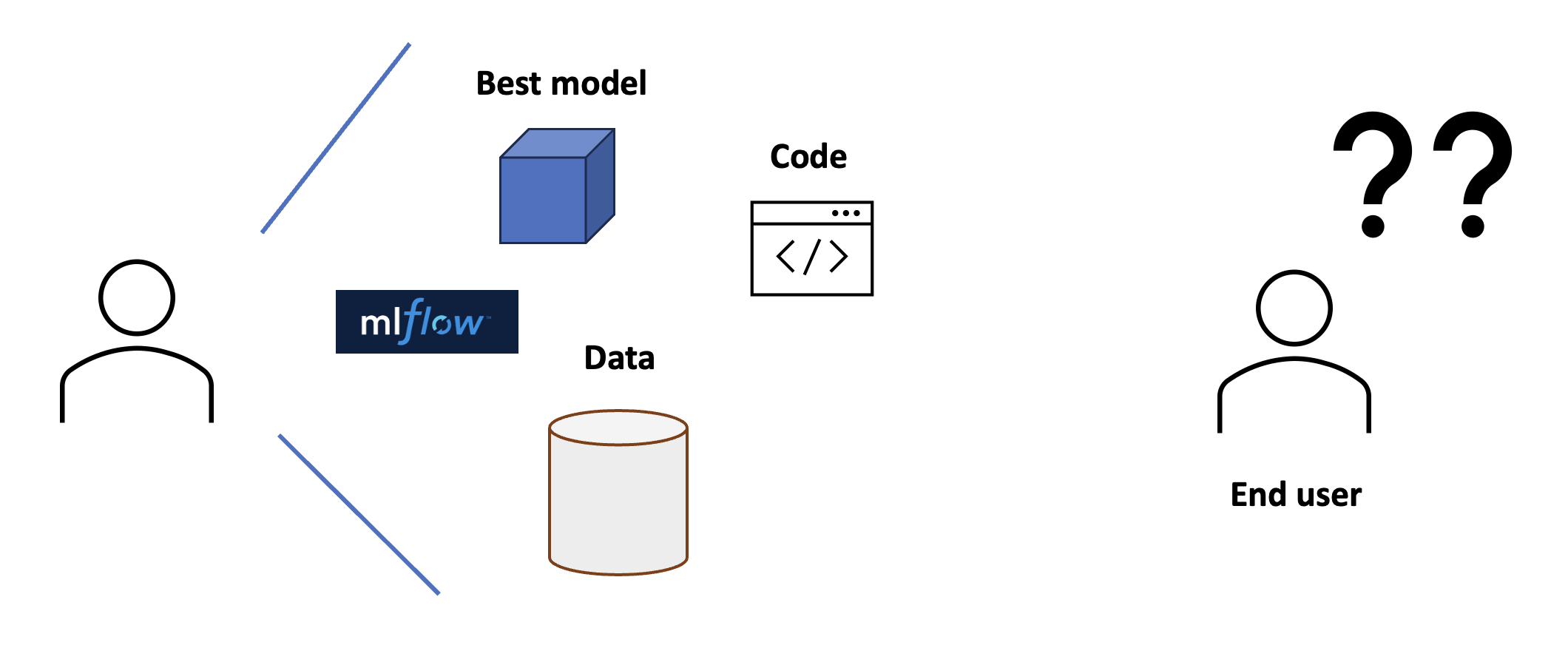
Stattdessen können wir unserem Modell dienen. Das Ausliefern kann verschiedene Formen annehmen. Wir können Batch-Prognosen bereitstellen oder wir können das Modell direkt über eine API bereitstellen. In unserem Fall gehen wir davon aus, dass Prognosen auf Abruf erforderlich sind, und entscheiden uns daher für die API.
Wenn wir unsere Lösung in eine API verpacken, muss sich der Benutzer nicht um die Logik und den Code kümmern, sondern nur um die Interaktionen mit der API. Außerdem kann jetzt auch jede andere Programmiersprache mit unserer API interagieren, da sie sich an ein standardisiertes Webprotokoll hält.
Eine einfach zu verwendende Open-Source-Bibliothek, die für die Erstellung einer API in Python verwendet werden kann, ist FastAPI.
Abb. 10 
An diesem Punkt werden Sie wahrscheinlich vom Notizbuch zu einem strukturierten Python-Paket wechseln. Dies ist nicht nur notwendig, um Ihre API zu schreiben, sondern hat auch den Vorteil, dass es Modularisierung, Linting und Unit-Tests ermöglicht, um die Codequalität zu gewährleisten.
Containerisierung
Jetzt können wir unser Modell bedienen und Daten (z.B. die Temperatur) an den API-Endpunkt senden, um Vorhersagen zurückzubekommen (z.B. den vorhergesagten Maschinendurchsatz). Allerdings läuft die API immer noch auf unserem eigenen Computer! Das heißt, wenn wir unseren Laptop schließen, ist unser Dienst nicht mehr verfügbar. Das ist nicht ideal. Wo sollten wir unsere API ausführen?
Abb. 11 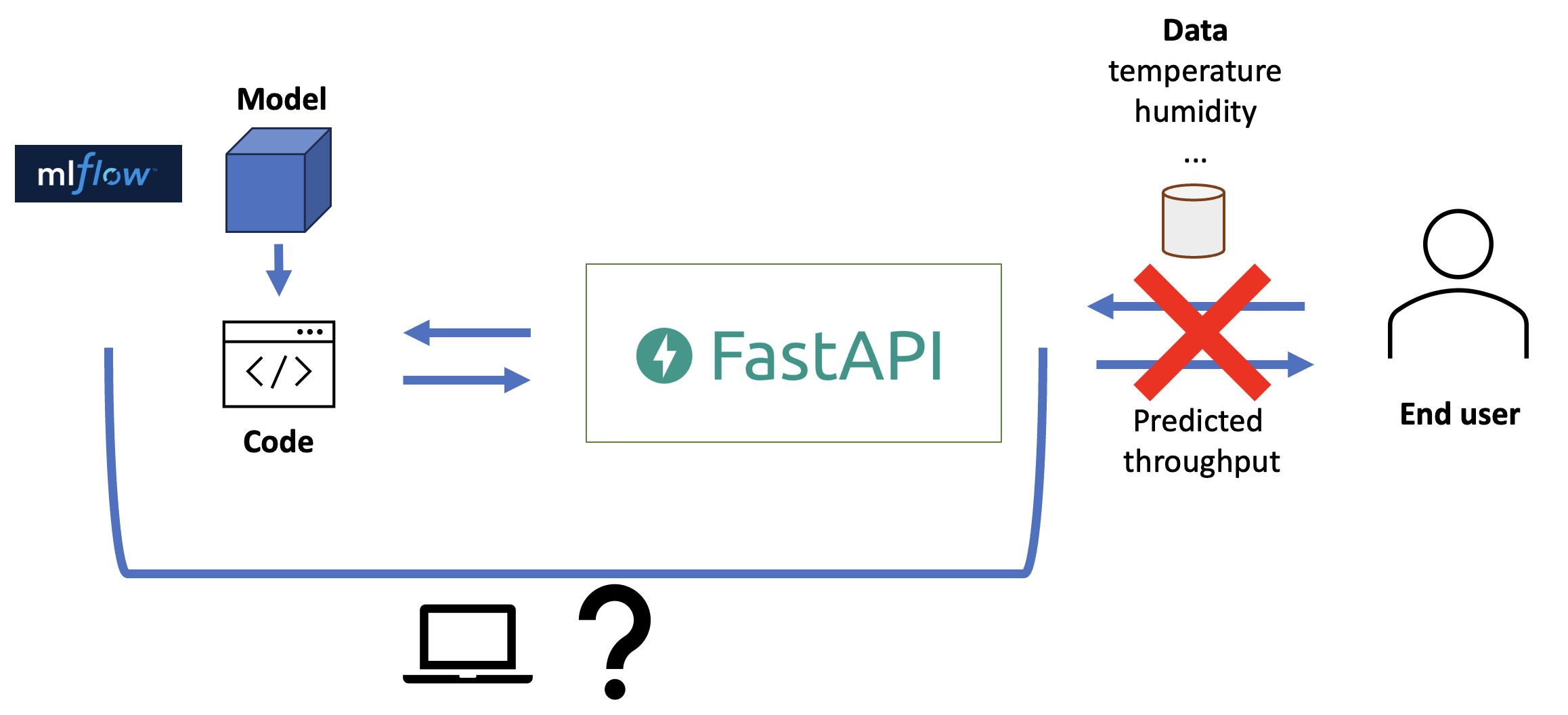
Stattdessen brauchen wir einen Server, auf dem unsere API läuft. Es ist jedoch nicht garantiert, dass unser Code auf einem Server funktioniert: Er könnte ein anderes Betriebssystem verwenden, eine andere Python-Version installiert haben und es könnten bereits andere Bibliotheken installiert sein, die mit unseren in Konflikt stehen.
Um sicherzustellen, dass unser Code auf dem Server läuft, müssen wir unsere Anwendung containerisieren. Ein Container ist ein isolierter Prozess, der auf jedem Betriebssystem ausgeführt werden kann. Er ist die laufende Instanz eines Container-Images, einer Datei, die alles enthält, was unsere Anwendung zum Laufen braucht: Python-Version, Abhängigkeiten, Dateien, Einstiegsbefehle usw.
Ein gängiges Open-Source-Tool, mit dem Sie Ihre Anwendungen in Container packen können, ist Docker. Die meisten, wenn nicht sogar alle Enterprise-Serving-Lösungen erlauben die Ausführung von Docker-Images auf ihren Servern. Voraussetzung ist, dass das Container-Image an einem Ort registriert ist, auf den Sie über das Internet zugreifen können. Für die Registrierung von Docker-Images können wir DockerHub verwenden, ähnlich wie wir Github für die Registrierung unseres Codes oder MLflow für die Registrierung unserer ML-Modelle verwenden.
Abb. 12 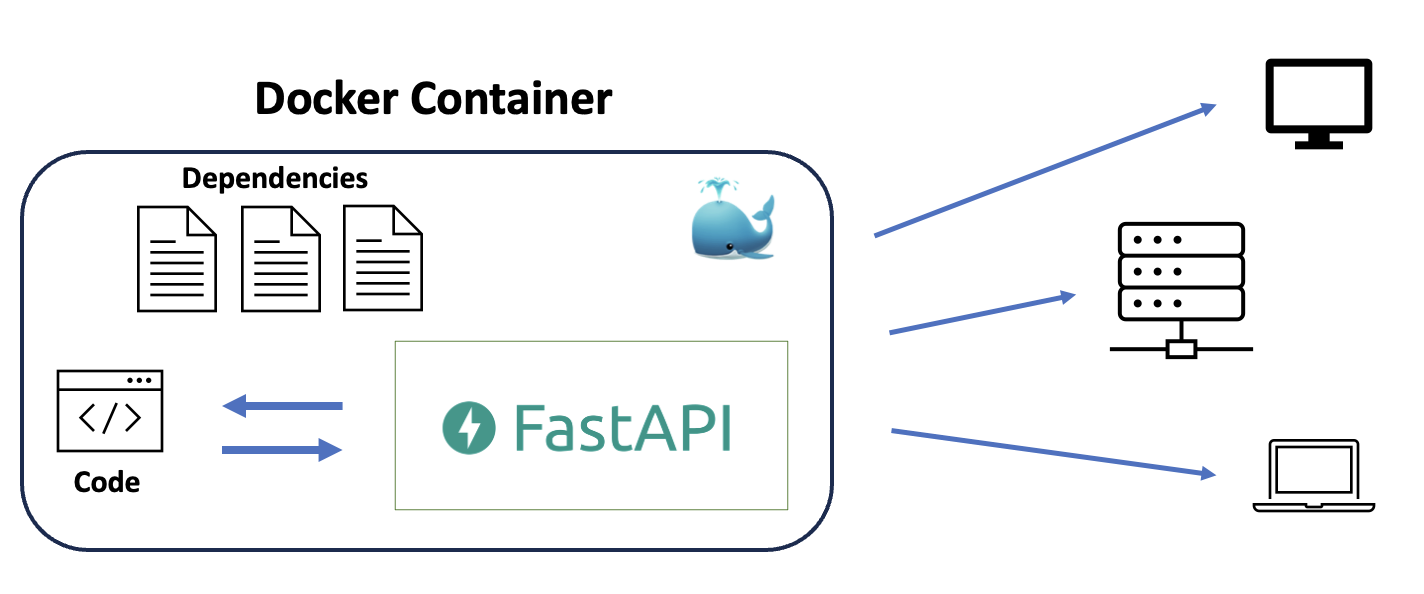
Deployment
Der letzte Schritt, um unsere Lösung den Endbenutzern zugänglich zu machen, besteht darin, sie auf einem Server bereitzustellen. Aber auf welchem Server, und wie bekommen wir sie dorthin?
Nehmen wir an, Sie haben keine eigenen Server und wollen sich auch nicht mit der Verwaltung des gesamten Netzwerks herumschlagen, das damit verbunden ist. Daher werden wir unsere Lösung bei einem der Cloud-Anbieter
Abb. 13 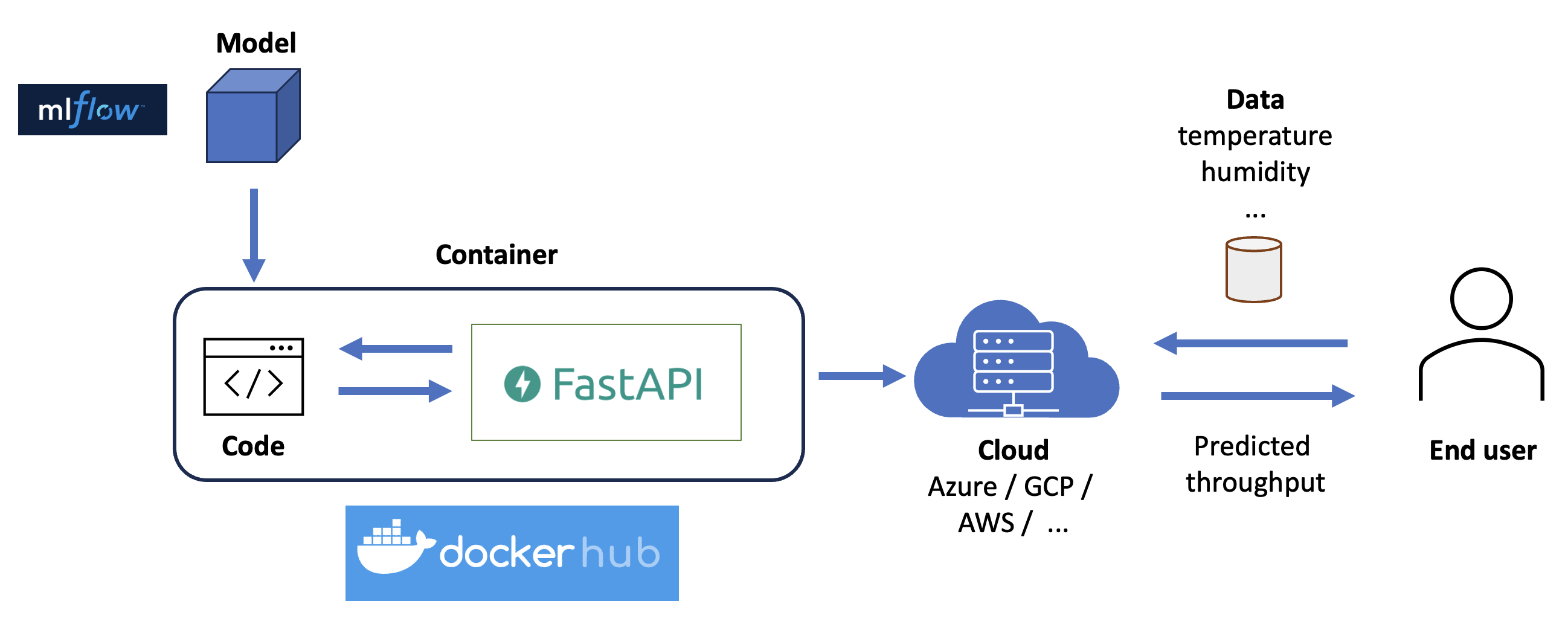
Egal, ob Sie sich für Azure Container Instances, Google Cloud Run oder AWS Fargate entscheiden, alle diese Serving-Lösungen ermöglichen in der Regel verschiedene Arten der Bereitstellung Ihrer Container:
- Über die Benutzeroberfläche (UI) des Anbieters
- Über Ihre Befehlszeilenschnittstelle (CLI)
Beide Optionen sollten zum gleichen Ergebnis führen, daher empfehlen wir Ihnen, beide auszuprobieren. Option (1) hat den Vorteil, dass Sie schnell Ergebnisse sehen. Option (2) hat den Vorteil, dass sie eine Automatisierung und Reproduzierbarkeit ermöglicht.
Sind Sie noch bei uns? Hoffentlich haben Sie Ihre App jetzt in der Cloud bereitgestellt und können einige Anfragen an sie senden. Lassen Sie uns nun im letzten Abschnitt den ganzen Kram automatisieren.
Kontinuierliche Integration und kontinuierliche Bereitstellung (CI/CD)
Wir sind bereits von einem lokalen Notebook über einen Container in die Cloud gegangen. Aber wir können noch besser werden!
Bisher haben wir die Dinge selbst ausgeführt, entweder über die Benutzeroberfläche oder über die Befehlszeilenschnittstelle. Aber wir können diesen Prozess automatisieren, so dass unsere Anwendung automatisch in der Cloud bereitgestellt wird, wenn wir eine neue Version des Codes in unserem Repository veröffentlichen.
Dazu können wir Github Actions verwenden, ein CI/CD-Tool, das mit GitHub integriert ist.
Abb. 14. 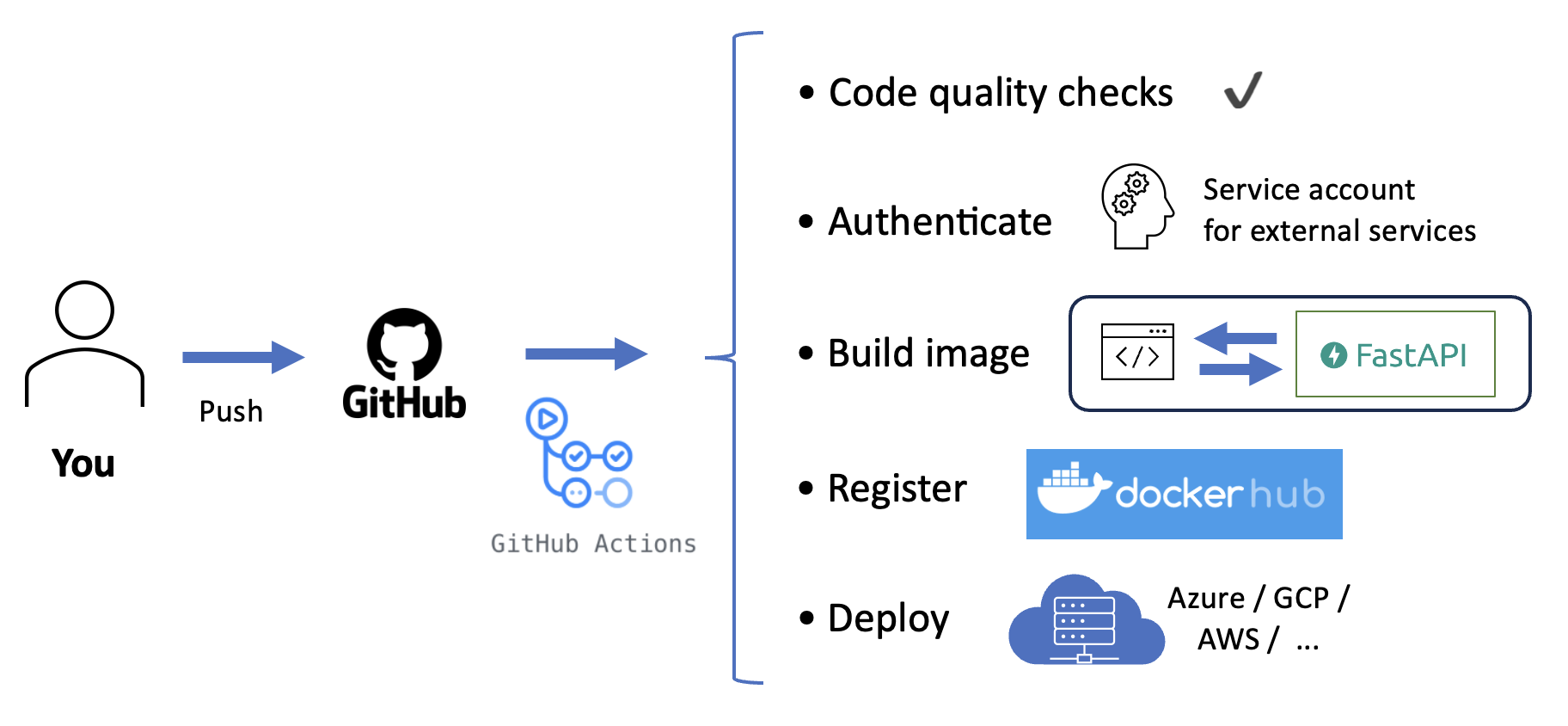
Wir können eine CI/CD-Pipeline als yaml Datei implementieren, in der wir angeben, welche Schritte und Befehle Github in welcher Reihenfolge ausführen soll. In unserem Fall könnten wir die folgenden Schritte einfügen:
- Kontinuierliche Integration: Führen Sie Code-Qualitätsprüfungen und Unit-Tests durch.
- Kontinuierliche Bereitstellung: Erstellen, Registrieren und Bereitstellen unseres Docker-Images
Wichtig ist jedoch, dass Github in unserem Namen mit externen Diensten wie DockerHub und dem Cloud-Anbieter interagieren muss. Jedes Mal, wenn Github unsere CI/CD-Pipeline ausführt, muss es sich mit gültigen Anmeldedaten bei dem externen Dienst "anmelden". Diese Anmeldedaten müssen zu den Github-Geheimnissen hinzugefügt werden, die Sie in Ihren Repository-Einstellungen finden.
Wo finden Sie nun diese Anmeldeinformationen? Das hängt vom jeweiligen Anbieter ab, aber im Allgemeinen ist es eine gute Praxis, für diesen Zweck ein Dienstkonto und nicht Ihr eigenes Konto zu verwenden. Im letzteren Fall kommt es zu oft vor, dass bei einem Mitarbeiter eines Unternehmens die Dienste ausfallen, weil sein persönliches Konto gelöscht wurde. In der Anleitung zeigen wir Ihnen, wie Sie die Zugangsdaten für ein Dienstkonto für Azure und GCP erhalten können.
Versuchen Sie, den Code zu ändern (z. B. in einem Fork des Repositorys), und beobachten Sie, wie die CI/CD-Pipeline alle Schritte zur Aktualisierung Ihres ML-Dienstes in der Cloud durchführt
Zusammenfassung
Unternehmen tun sich oft schwer damit, ihre ML-Lösungen zum Laufen zu bringen und einen Mehrwert zu erzielen. In diesem Blogpost haben wir gesehen, dass dieses Problem oft durch die Kluft zwischen Data Science und Operations verursacht wird. Wir haben auch gesehen, wie MLOps darauf abzielt, diese Lücke entlang der Achsen Menschen, Prozesse und Technologie zu schließen.
In Bezug auf Mitarbeiter und Prozesse haben wir aufgezeigt, wie funktionsübergreifende End-to-End-Teams die Verantwortung für den gesamten MLOps-Lebenszyklus übernehmen können, so dass keine Übergaben mehr erforderlich sind. Im Hinblick auf die Technologie haben wir uns mit dem Prozess befasst, wie man von einem Notebook zu einem brauchbaren ML-Service in der Cloud kommt und diesen operationalisiert.
Es gibt vieles, was wir nicht behandelt haben, wie z.B. die Überwachung, die Einrichtung einer geeigneten Cloud-Infrastruktur oder auch das Änderungsmanagement, das erforderlich ist, um Unternehmen dazu zu bringen, mit einer MLOps-Mentalität zu denken. Dennoch hoffen wir, dass dieser Beitrag einige konkrete Einblicke in allgemeine Probleme, die Sie vielleicht erkennen, und mögliche Lösungen, die Sie erforschen können, gegeben hat.
Möchten Sie mehr erfahren? Schauen Sie sich unsere Schulungen (z.B. diese oder diese) und Dienstleistungen an, und halten Sie Ausschau nach unserem kommenden MLOps-Whitepaper!
Verfasst von
Yke Rusticus
Unsere Ideen
Weitere Blogs




Contact