Blog
MLOps: Warum und wie man End-to-End-Produktteams aufbaut

Machine Learning Operations (MLOps) hat in den letzten Jahren mit dem Versprechen, DevOps auf Machine Learning anzuwenden, an Popularität gewonnen. Es zielt darauf ab, den mühsamen Prozess der Erstellung robuster, zuverlässiger und skalierbarer maschineller Lernsysteme zu rationalisieren, die für die Endbenutzer bereit sind.
Doch trotz der vielversprechenden Möglichkeiten werden bis 2022 schätzungsweise weniger als 20% der Modelle für maschinelles Lernen in die Produktion gebracht.
Warum schaffen es nur so wenige Unternehmen, ML-Modelle in die Produktion zu bringen, und noch weniger schaffen dies zuverlässig und effizient?
Eine Lücke zwischen Datenwissenschaft und IT verhindert, dass Ihre ML-Modelle die Produktion erreichen
Data-Science-Teams sind großartig darin, nah am Geschäft zu sein und geschäftliche Herausforderungen mit datengesteuerten Lösungen zu finden und anzugehen.
Ein schneller und iterativer Ansatz bei der Ideenfindung und Exploration, den ersten Phasen des Lebenszyklus des maschinellen Lernens (siehe Abbildung 1), ist der schnellste Weg, um Ergebnisse für die Interessengruppen des Unternehmens zu erzielen. Teams, die sich in diesem Bereich auszeichnen, werden zu Recht belohnt.
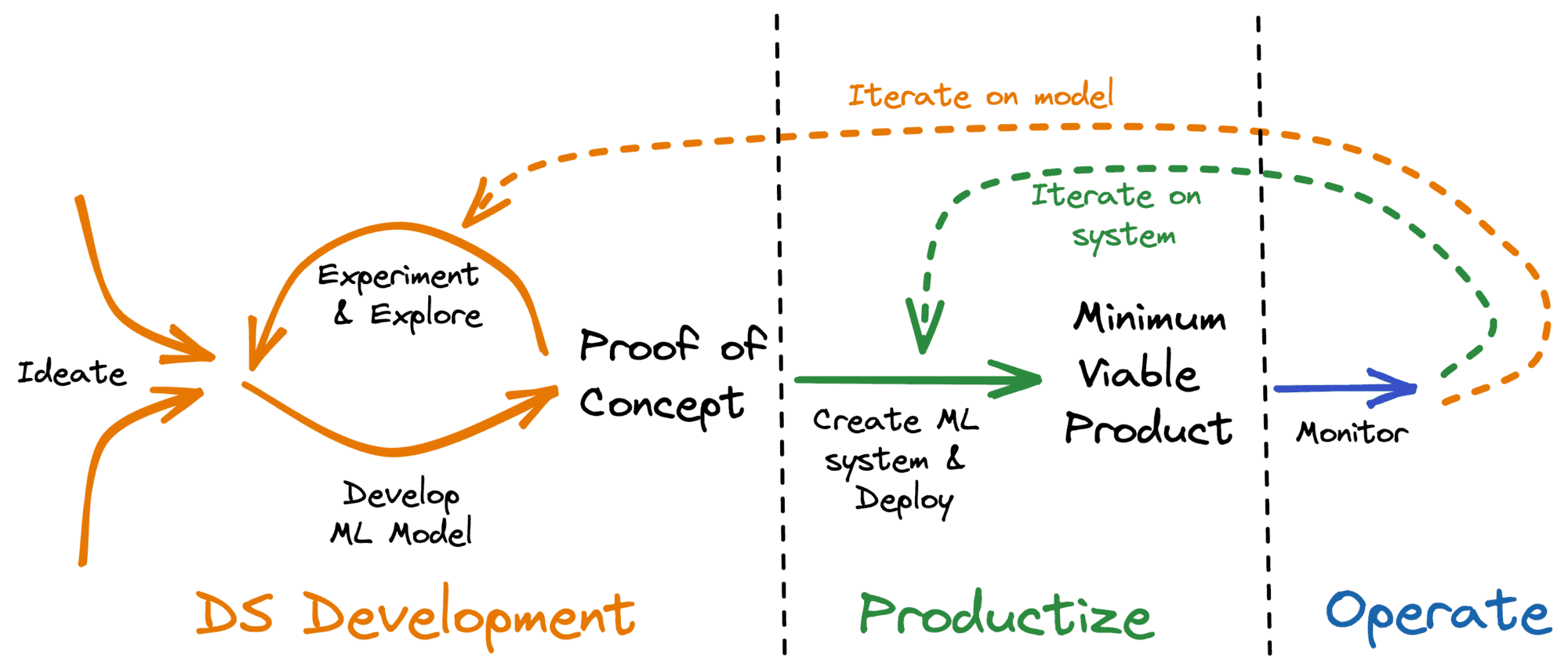
Abbildung 1: Typischer Lebenszyklus eines Data-Science-Produkts
Sobald jedoch ein Proof-of-Concept (PoC) entwickelt wurde, stoßen viele Teams auf eine Mauer und sind nicht in der Lage, ML-Modelle in Systeme umzuwandeln, die in der Produktion laufen und einen Mehrwert für das Unternehmen schaffen.
Da sie nicht über die Fähigkeiten und das Fachwissen verfügen, um eine produktionsreife Software zu erstellen, wenden sich diese Data-Science-Teams an eine IT-/Ops-Abteilung, um ihre Lösungen produktiv zu machen. Doch die Übergabe eines PoC an ein Ops-Team ist alles andere als reibungslos.
Am Ende passiert eines von 3 Dingen:
- Das Data-Science-Modell wird an die IT übergeben. Die IT-Abteilung führt es aus, ohne es zu verstehen (Blackbox), und vernachlässigt oft die Überwachung und Wartung der Inhalte dieser Blackbox. Wenn die Leistung des Modells nachlässt, merkt das niemand und niemand fühlt sich verantwortlich, das Problem zu beheben.
- Das Data Science-Modell wird von einem IT-Team neu erstellt, das viel Zeit und Mühe investiert. Das Unternehmen muss Monate (oder Jahre) warten, bis das Modell nutzbar ist. Wenn währenddessen oder danach Verbesserungen erforderlich sind, fehlen dem IT-Team die Fähigkeiten, diese einzubauen. Damit beginnt der Übergabeprozess von neuem.
- Das Modell wird nie in die Produktion überführt: sein wahrer Wert kommt nie zum Tragen.
Warum Übergaben in der Datenwissenschaft problematisch sind
Übergaben bilden einen problematischen Engpass, der aus 3 Gründen verhindert, dass Modelle die Produktion erreichen:
- Maschinelle Lernsysteme sind komplex
- Maschinelle Lernsysteme sind zum Zeitpunkt der Übergabe unausgereift
- Die beiden Seiten der Übergabe sprechen unterschiedliche Sprachen
Lassen Sie uns eintauchen.
Grund 1: Maschinelle Lernsysteme sind komplex
Ein Produkt für maschinelles Lernen hat mehrere bewegliche Teile: Modell, Daten und Code. Jede Komponente entwickelt sich weiter, und jede Weiterentwicklung kann Änderungen in anderen Teilen erfordern: Der Code erfordert Fehlerkorrekturen oder die Daten weichen ab? Das Modell muss möglicherweise neu trainiert werden. Die Daten gewinnen eine neue Dimension oder verlieren eine bestehende? Dann muss ein neuer Code geschrieben und das Modell neu trainiert werden.
Diese drei beweglichen Teile führen zu maschinellen Lernsystemen, die aus vielen verschiedenen Komponenten bestehen, wie in der Abbildung unten hervorgehoben wird. Diese Komplexität erhöht die Schwierigkeit der Übergabe und die Wahrscheinlichkeit von Fehlern.
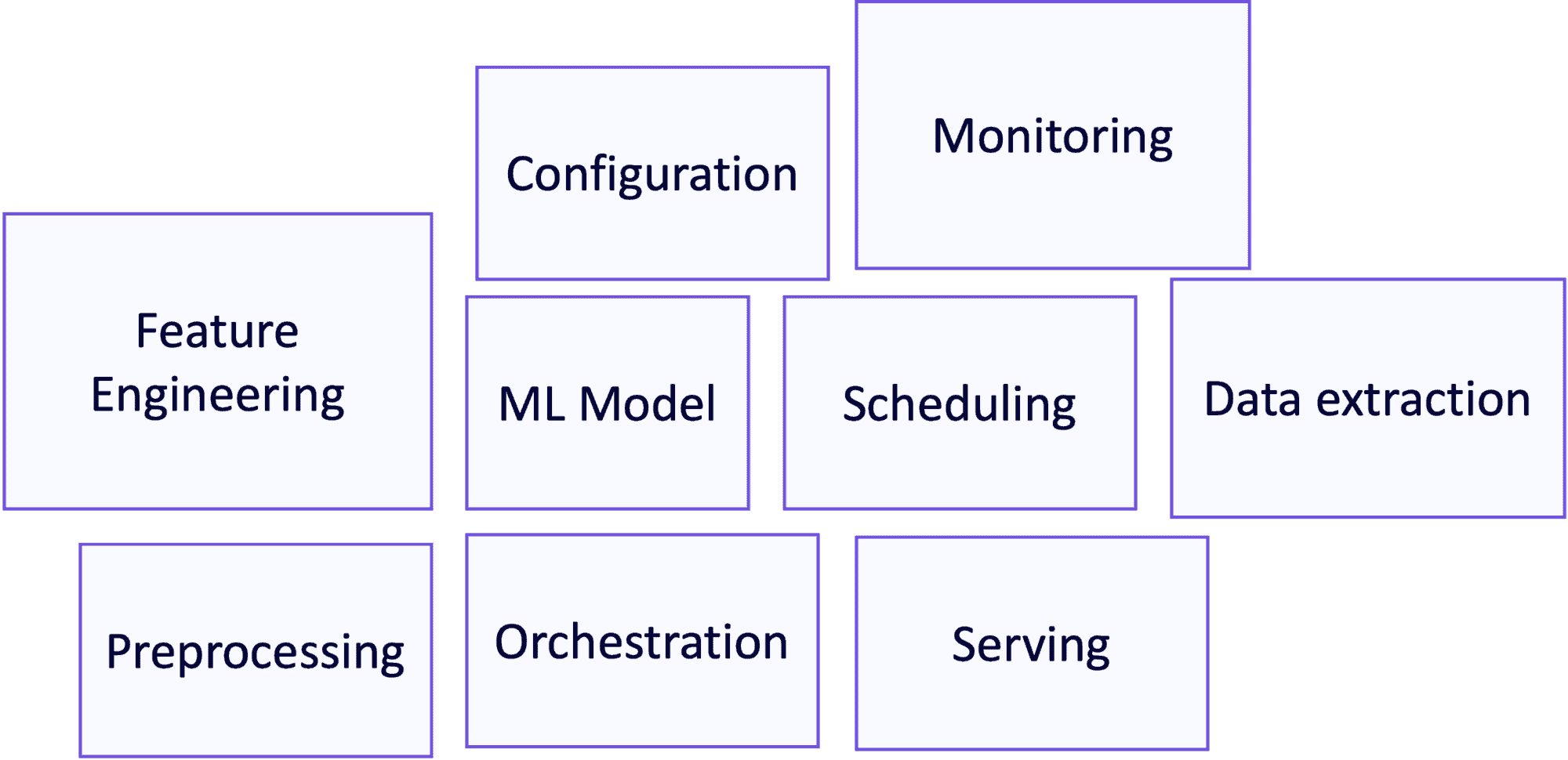
Abbildung 2: Komponenten in einem typischen ML-System
Grund 2: Maschinelle Lernsysteme sind zum Zeitpunkt der Übergabe unausgereift
Datenwissenschaftlern mangelt es oft an den Fähigkeiten, ausgereifte Produkte für maschinelles Lernen zu entwerfen und zu entwickeln.
Das Hauptziel der Datenwissenschaft besteht darin, dem Unternehmen schnell einen Mehrwert zu bieten. Datenwissenschaftler arbeiten meist mit Notebooks und schnellen Feedbackschleifen, um den Stakeholdern die Ergebnisse zu präsentieren.
Diese schnellen Schleifen können jedoch zu einem ungeprüften und nicht dokumentierten Endergebnis führen. Außerdem kann das Wissen über das Modell und die Gründe für bestimmte Entscheidungen im Kopf des Datenwissenschaftlers bleiben und nirgendwo kodifiziert werden.
Wieder einmal eine schwierige Übergabe, jetzt aufgrund mangelnder Reife.
Grund 3: Die beiden Seiten der Übergabe sprechen unterschiedliche Sprachen
Data-Science-Teams und IT-Teams unterscheiden sich in den Tools, die sie verwenden, in den Prozessen, die sie befolgen, und in den Mitarbeitern, die sie beschäftigen - die beiden Seiten haben einen unterschiedlichen Bezugsrahmen, was zu Missverständnissen führt.
Auch hier geht es den Datenwissenschaftlern darum, dem Unternehmen schnell einen Mehrwert zu bieten. Geschwindigkeit ist wichtig und die Tools spiegeln diesen Kompromiss wider: Python, Pandas und Jupyter-Notebooks sind allesamt hervorragend für Geschwindigkeit geeignet.
Für Datenwissenschaftler ist die Technik im Vergleich zur aufregenden und herausfordernden "wissenschaftlichen" Arbeit der Datenerforschung, der Erstellung von Modellen und der Entdeckung des Geschäftswerts eher nebensächlich.
IT-Ingenieure hingegen konzentrieren sich auf die Entwicklung zuverlässiger, skalierbarer Lösungen. Je weniger Aufmerksamkeit sie im Betrieb benötigen, desto weniger Bereitschaftsdienst ist erforderlich. Das Ergebnis? Ein Stack, der sich auf die Zuverlässigkeit konzentriert: Spark, Scala und andere JVM-basierte Sprachen.
Für diese Ingenieure sind Datenwissenschaftler eine Quelle für schlechten Code. Warum schreiben Sie ihn also nicht einfach neu?
Sie brauchen Data Science Produktteams für MLOps
Angesichts dieser potenziellen Probleme bei der Übergabe ist es am besten, diese Übergabe ganz zu vermeiden.
Um den Betrieb von Systemen für maschinelles Lernen in der Produktion zu vereinfachen, sollten Sie durchgängige Produktteams bilden, die über die Fähigkeiten, das Mandat und die Verantwortung für den gesamten Lebenszyklus des maschinellen Lernens verfügen.
Dies hat mehrere Vorteile:
- Kurze Kommunikationswege zwischen Datenwissenschaftlern und Ingenieuren.
- Einfaches Formulieren von Gemeinsamkeiten zwischen allen Experten.
- Einfaches Überwachen, Pflegen und Iterieren eines Modells, sobald es in die Produktion überführt wurde.
Gehen Sie von der Aufteilung von DS Dev und Ops (Abbildung 3) zu durchgängigen Data Science Produktteams (Abbildung 4) über.
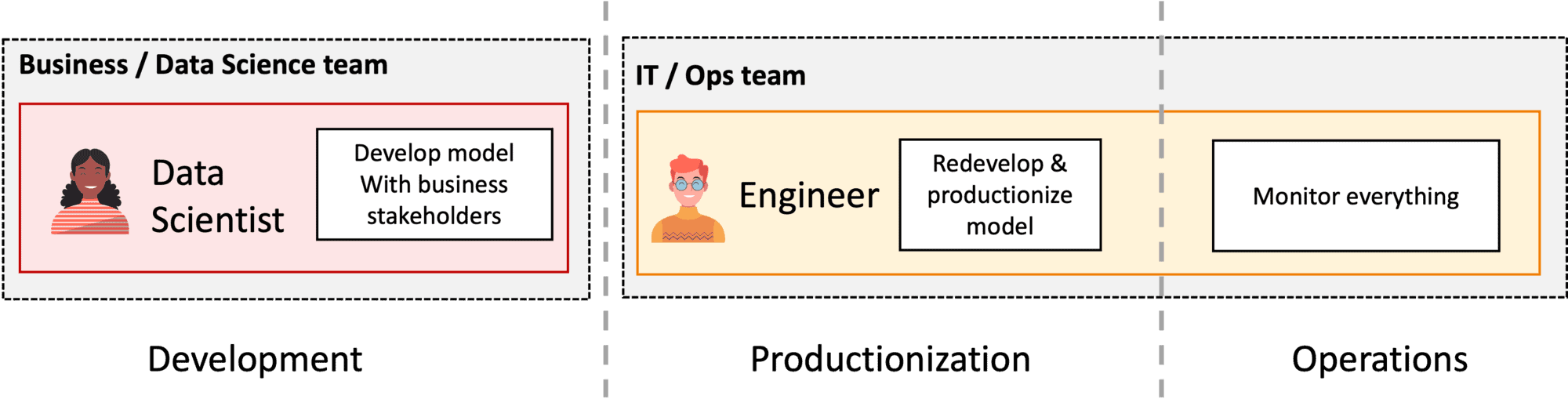
Abbildung 3: Teamstruktur mit getrennten Bereichen Data Science und Ops.
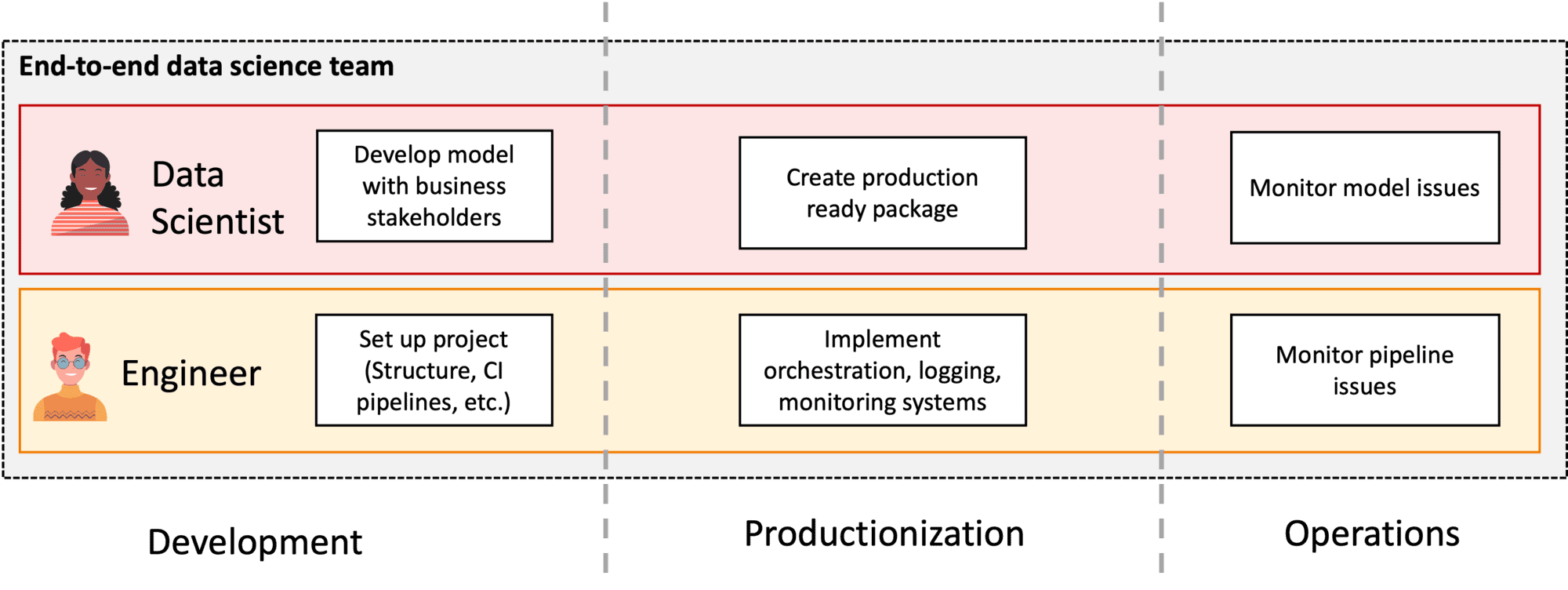
Abbildung 4: Durchgängige Data Science Produktteams
Lassen Sie uns einen genaueren Blick auf die Voraussetzungen für erfolgreiche End-to-End-Teams werfen:
- Die richtigen Rollen und Fähigkeiten, um die Verantwortung für ML-Produkte zu übernehmen.
- Ein Plattformteam, das das Data Science Produktteam unterstützen kann
- Das richtige organisatorische Umfeld, um Data Science in der Produktion zum Erfolg zu führen.
Anforderung 1: Die richtigen Rollen und Fähigkeiten, um die Verantwortung für ML-Produkte zu übernehmen
In einem Data-Science-Produktteam gibt es mindestens zwei Rollen: Data Scientists und Machine Learning Engineers.
Datenwissenschaftler konzentrieren sich in erster Linie auf das Modell selbst, während ML-Ingenieure sich auf das System als Ganzes konzentrieren. Gemeinsam tragen sie die Verantwortung für den gesamten Lebenszyklus des maschinellen Lernens:
- Entwicklung
- Produktisierung
- Betrieb
Während der Entwicklung erforschen die Data Scientists die Daten und den Problemraum und erstellen Modelle zur Lösung des Geschäftsproblems. Die Ingenieure für maschinelles Lernen helfen ihnen dabei, indem sie Software-Engineering-Anleitungen und Best Practices bereitstellen und die Pipelines für die kontinuierliche Integration (CI) einrichten.
Während der Produktisierung konzentrieren sich die Datenwissenschaftler auf die Überarbeitung ihres PoC-Modells in ein produktionsreifes (Python)-Paket, während sich die Ingenieure für maschinelles Lernen auf die Einrichtung von Orchestrierungspipelines und die Überwachung konzentrieren. Im Endeffekt verwandeln die Ingenieure das maschinelle Lernmodell in ein maschinelles Lernsystem.
Datenwissenschaftlern fehlt es vielleicht an den nötigen Fähigkeiten, um Code in Produktionsqualität zu schreiben. In diesem Fall ist es gut, dass es Ingenieure gibt, die sie coachen können.
Während des Betriebs schließlich konzentrieren sich die Datenwissenschaftler auf die Überwachung des Modells, während sich die Ingenieure für maschinelles Lernen auf die Überwachung des restlichen Systems konzentrieren.
Anforderung 2: Ein Plattformteam, das das Data Science-Produktteam unterstützen kann
Ein gutes Plattformteam hilft bei der effizienten Skalierung von Data Science über mehrere Produktteams hinweg.
Ohne sie könnte das Produktteam zu viele Aufgaben übernehmen und seine Mitglieder auf zu viele Fachgebiete verteilen: maschinelles Lernen, Daten und Plattformwissen werden alle benötigt, um die benötigte Infrastruktur und die Rohdaten bereitzustellen.
In großen Unternehmen mit mehreren Data-Science-Teams wird die Wiederverwendbarkeit zu einem Schlüsselfaktor. Ein Team für eine Plattform für maschinelles Lernen kann Produktteams dabei unterstützen, ihre Produkte effizienter zu erstellen.
Die Erstellung und Pflege einer solchen Plattform ist jedoch nicht so einfach, wie wenn Sie einfach einen Anbieter beauftragen und dessen neueste ML-Plattform kaufen. Mit diesem Ansatz haben Sie Ihre einzelnen Produktteams noch nicht auf den Erfolg des maschinellen Lernens in der Produktion vorbereitet.
Die Herausforderung liegt in folgendem Zielkonflikt: Wie kann sichergestellt werden, dass die Plattform eine ausreichend hohe Abstraktionsebene bietet, um die Arbeit zu erleichtern, und gleichzeitig flexibel genug ist, um den individuellen Anforderungen der einzelnen Anwendungsfälle gerecht zu werden?
Die Modelle des goldenen Pfades und des gepflasterten Pfades (wie sie von Spotify propagiert werden) sind praktische Rahmenwerke, um dies zu erreichen. Spotify meint dazu: "Die Idee hinter den Goldenen Pfaden ist nicht, Ingenieure einzuschränken oder zu ersticken oder Standards um ihrer selbst willen festzulegen. Mit Golden Paths müssen Teams das Rad nicht neu erfinden, haben weniger Entscheidungen zu treffen und können ihre Produktivität und Kreativität für höhere Ziele einsetzen. "
Diese goldenen und gepflasterten Wege beruhen in hohem Maße auf der Erstellung von Vorlagen und Anleitungen, um Teams zu unterstützen und ihnen gleichzeitig die Freiheit zu geben, Anpassungen vorzunehmen, wenn dies für bestimmte Anwendungsfälle erforderlich ist.
Wie ihre Pendants aus der Datenwissenschaft sind auch diese Plattformteams selbst Produktteams. Sowohl das Plattform- als auch das Datenwissenschaftsteam sind für die Erstellung und den Betrieb produktionsreifer Produkte verantwortlich und betreiben diese dann (siehe Abbildung 5).
Beide Teams sollten sich darauf konzentrieren, ihre Kunden zu bedienen.
Für das Plattformteam sind die Use-Case-Teams ihre Kunden. Für das Anwendungsfallteam sind diese Kunden die Geschäftsinteressenten, die ein Data Science-Produkt benötigen.
Enge und schnelle Kundenfeedback-Zyklen helfen bei der iterativen Entwicklung kundenorientierter Produkte, die dem Unternehmen einen echten Mehrwert bieten.
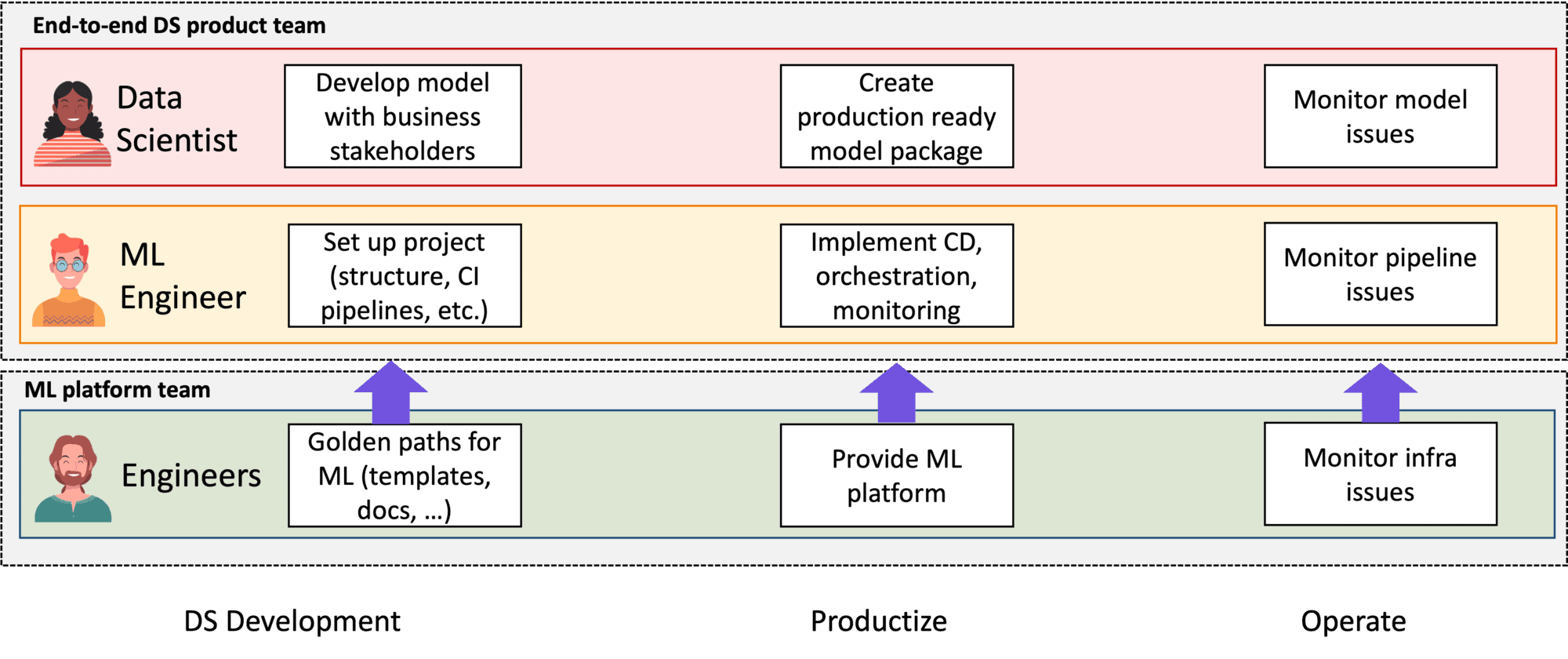
Abbildung 5: Teamstruktur eines Data Science-Produktteams mit einem Plattformteam
Anforderung 3: Das richtige organisatorische Umfeld, um Data Science in der Produktion zum Erfolg zu führen.
Data Science findet oft an der Schnittstelle zwischen Wirtschaft und IT statt. Das richtige organisatorische Umfeld für das Team ist daher entscheidend für ihren Erfolg.
Sie müssen so nah wie möglich am Geschäft sein, sollten aber auch ein angesehenes Mitglied der IT-Organisation sein.
Warum Data-Science-Produktteams eng mit dem Unternehmen zusammenarbeiten müssen
Data-Science-Produktteams arbeiten eng mit ihren geschäftlichen Interessenvertretern zusammen, die oft wertvollen fachlichen Input liefern können. Diese Zusammenarbeit stellt sicher, dass das Team Lösungen entwickelt, die vom Unternehmen gewünscht werden, denen es vertraut und die letztendlich einen Mehrwert bieten.
Wenn Sie dies nicht tun, führt dies dazu, dass Geschäftsinteressenten aufgrund von Vertrauens- und Kommunikationsproblemen eher Excel-basierte Prognosen als leistungsfähigere und genauere datenwissenschaftliche Modelle verwenden.
Warum Data-Science-Produktteams Teil der IT sein müssen
Produkte für maschinelles Lernen sind eine der vielen Komponenten innerhalb einer IT-Infrastruktur und sollten auch als solche behandelt werden.
Werden diese Teams nicht als Teil der IT betrachtet, besteht die Gefahr, dass die Integration in die Standard-IT-Infrastruktur scheitert.
Nehmen wir als Beispiel einen unserer Kunden, dessen Ingenieure und Datenwissenschaftler in einem einzigen Team arbeiteten und die Verantwortung für ihre ML-Produkte übernehmen wollten. Das Team wurde jedoch nicht als Teil der IT-Abteilung betrachtet, was sie daran hinderte, ihre Produkte innerhalb der Standard-IT-Systeme zu entwickeln und zu betreiben. Dadurch waren sie gezwungen, ihre Aufgaben an eine andere Abteilung zu übergeben.
Diese organisatorischen Herausforderungen sind oft komplex, für jedes Unternehmen einzigartig und schwer zu lösen.
Es ist wichtig, sich bewusst zu machen, dass es sie geben könnte und in welcher Lage sich Data Science-Teams befinden könnten. Als Unternehmen flink zu sein und die Kommunikationswege so kurz wie möglich zu halten, sind allgemeine Tipps, die auch hier oft gelten.
Schlussfolgerung: Eine ganzheitliche Sichtweise ist der Schlüssel zu MLOps
Wenn Sie über MLOps lesen, werden oft viele Tools und Plattformbegriffe eingeführt: Feature Stores, Experiment Tracking & Model Registries, um nur einige zu nennen.
Viele Unternehmen konzentrieren sich dann auf diese Komponenten, wenn sie versuchen, ihre MLOps-Fähigkeiten zu verbessern.
Werkzeuge und Technik sind jedoch nur ein Teil des Problems. Bei MLOps geht es um Menschen, Prozesse und die Organisation als Ganzes.
Der Schlüssel zum Erfolg bei MLOps ist der Aufbau von Teams, die über die erforderlichen Fähigkeiten und Verantwortlichkeiten verfügen, um produktionsreife maschinelle Lernlösungen zu entwickeln und zu betreiben.
Sind Sie daran interessiert, mehr über die Besonderheiten der Einrichtung von Data Science Use-Case-Teams und Plattformteams zu erfahren? Bleiben Sie dran für die nächsten Blogs, die sich mit diesem Thema näher beschäftigen werden.
Verfasst von
Daniel Willemsen
Daniel is a Machine Learning Engineer at GoDataDriven. He focuses on helping teams move their data science use-cases through the entire machine learning life-cycle: from ideation to production and maintainance.
Unsere Ideen
Weitere Blogs




Contact