
Ich hatte kürzlich das Vergnügen, eine MapReduce-basierte Graphpartitionierung durchzuführen. Hier finden Sie einen Beitrag darüber, wie ich das gemacht habe. Ich habe mich für Cascading entschieden, um meine MR-Aufträge zu schreiben, da es viel weniger wortreich ist als Java-basiertes MR. Der Graph-Algorithmus besteht aus einem Schritt zur Vorbereitung der Eingabedaten und einem iterativen Teil, der bis zur Konvergenz läuft. Das Programm verwendet einen Hadoop-Zähler, um die Konvergenz zu überprüfen und stoppt die Iteration, sobald diese erreicht ist. Der gesamte Code ist verfügbar. Außerdem enthält die Erklärung bunte Bilder von Diagrammen. (Und alles ist sehr informell geschrieben und es gibt keine Mathematik.) Ich habe einen Graphen und er sieht so aus (dieser Graph ist unverbunden, aber wir werden später auch vollständig verbundene Graphen anhand eines Partitionierungskriteriums partitionieren):
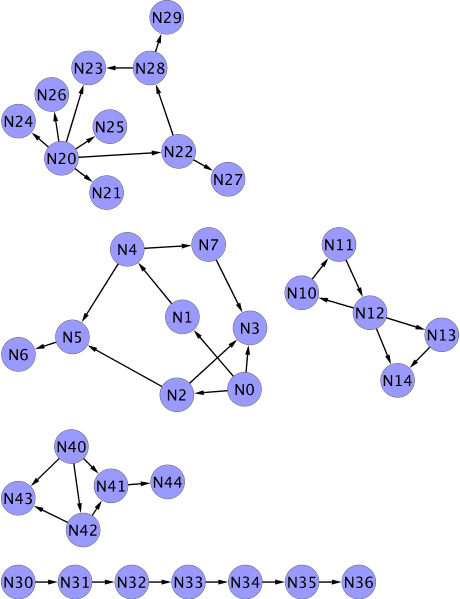
Das stimmt nur, wenn Sie den Graphen visualisieren. In Wirklichkeit handelt es sich nur um eine Textdatei, die eine Liste von Kanten in Form von Quell- und Zielknoten-IDs enthält. Der obige Graph sieht so aus:
0,1 0,2 0,3 1,4 4,5 5,6 2,3 2,5 4,7 7,3 10,11 11,12 12,10 12,13 12,14 13,14 20,21 20,22 20,23 20,24 20,25 20,26 22,27 22,28 28,23 28,29 30,31 31,32 32,33 33,34 34,35 35,36 40,41 40,42 40,43 42,43 42,41 41,44
Unser Ziel ist es nun, jede Kante in der Liste mit einer Partitionsnummer zu versehen. Der Graph ist potenziell sehr groß und passt nicht in den Speicher eines einzelnen Rechners. Das gibt uns einen Vorwand, MapReduce für die Partitionierung zu verwenden. Sobald die Partitionierung erfolgt ist, können wir später die verschiedenen Teile des Graphen unabhängig voneinander analysieren. Hoffentlich ist jede Partition klein genug, um in den Speicher zu passen, so dass wir sie auch visualisieren können.
Der Algorithmus, den wir anwenden werden, ist der folgende:
Wandeln Sie die Kantenlisten in eine Adjazenzlisten-Darstellung um Kennzeichnen Sie jeden Quellknoten + Adjazenzliste mit einer Partitions-ID, die der größten Knoten-ID im Datensatz entspricht. Also Partitions-ID = max(Quellknoten-ID, Zielknoten-IDs). Finden Sie für jede Knoten-ID die größte Partitions-ID, zu der der Knoten gehört. Wenn also ein Knoten Teil von zwei oder mehr Adjazenzlisten ist, finden Sie diejenige, die die größte Partitions-ID hat. Setzen Sie die Partitions-ID jedes Datensatzes auf die größte Partitions-ID, die in Schritt 3 gefunden wurde Wiederholen Sie Schritt 3 und 4, bis sich nichts mehr ändert. Wir gehen dies Schritt für Schritt durch. Wir werden zwar alles mit MapReduce machen, aber wir verwenden Cascading als Abstraktionsschicht über MapReduce. Bei Cascading denken Sie nicht in Mappern und Reduktoren, sondern in Datensatzverarbeitung mit Tupeln, auf die Sie Funktionen, Aggregate, Gruppierungen und Joins anwenden. Das Schreiben von MapReduce-Aufträgen ist mühsam, umständlich und sehr zeitaufwändig. Wenn Sie es nicht unbedingt aus Leistungs- oder anderen Gründen benötigen, sollten Sie das Schreiben von MapReduce-Aufträgen zugunsten einer Abstraktionsschicht vermeiden. Davon gibt es viele in einer Reihe von Sprachen (Java, Scala, Clojure). Die Verwendung von Cascading bedeutet, dass wir einfache Ideen aus der Datensatzverarbeitung wie 'group by', 'join', 'for each record' und 'for every group' usw. verwenden. Dies ist auch genau die Art und Weise, wie Sie Cascading-Flows schreiben.
1. Wandeln Sie die Kantenlisten in eine Adjazenzlisten-Darstellung um
Für den ersten Schritt müssen wir die Darstellung des Graphen in Adjazenzlisten ändern. Das bedeutet, dass wir für jeden Knoten eine Liste der Zielknoten erstellen, die von diesem Knoten aus erreichbar sind. Das bedeutet im Grunde, dass wir das tun müssen:
- Nach Quellknoten gruppieren
- Geben Sie für jede Gruppe den Quellknoten und eine Liste aller Zielknoten aus.
In Cascading können Sie dies mit einer einfachen Gruppierung nach und einem Aggregator tun. Wir werden uns den Code etwas später ansehen, aber zunächst gehen wir zu Schritt 2 über, da Schritt 1+2 eigentlich ein einziges Stück Code und ein einziger MapReduce-Durchlauf sind.
2. Kennzeichnen Sie jeden Quellknoten + Adjazenzliste mit einer Partitions-ID
In Schritt 2 müssen wir jede der Kombinationen aus Quellknoten und Adjazenzliste mit einer Partitionsnummer versehen. Während des gesamten Algorithmus werden wir immer versuchen, die Partitionsnummer zu maximieren. Zu Beginn gibt es keine Partitions-IDs, so dass wir die größte Knoten-ID aus jedem Datensatz als Partitions-ID für diesen Datensatz verwenden. Wenn Sie Schritt 1+2 ausführen, sollte die Graphendarstellung wie folgt aussehen:
Teil. Quell-Adjazenz ID Knotenliste
43 42 43,41 44 41 44 43 40 43,42,41 36 35 36 35 34 35 34 33 34 33 32 33 32 31 32 31 30 31 29 28 29,23 28 22 28,27 26 20 26,25,24,23,22,21 14 13 14 14 12 14,13,10 12 11 12 11 10 11 7 7 3 6 5 6 7 4 7,5 5 2 5,3 4 1 4 3 0 3,2,1
Lassen Sie uns nun einen Blick auf den Code werfen.
öffentlich Klasse PrepareJob { öffentlich int laufen(Zeichenfolge Eingabe, Zeichenfolge Ausgabe) { Schema sourceScheme = neu TextDelimited(neu Felder("Quelle", "Ziel"), ","); Tippen Sie auf Quelle = neu Hfs(sourceScheme, Eingabe); Schema sinkScheme = neu TextDelimited(neu Felder("Partition", "Quelle", "Liste"), "t"); Tippen Sie auf Waschbecken = neu Hfs(sinkScheme, Ausgabe, SinkMode.ERSETZEN); Pfeife vorbereiten. = neu Pfeife("vorbereiten"); //Parse string to int's, //auf diese Weise erhalten wir eine numerische Sortierung anstelle einer Textsortierung vorbereiten. = neu Jede(vorbereiten., neu Identität(Integer.TYP, Integer.TYP)); //GROUP BY Quellknoten ORDER BY Ziel DESCENDING vorbereiten. = neu GroupBy(vorbereiten., neu Felder("Quelle"), neu Felder("Ziel"), true); //Für jede Gruppe führen Sie den Aggregator ToAdjacencyList aus vorbereiten. = neu Jede(vorbereiten., neu ToAdjacencyList(), Felder.ERGEBNISSE); Eigenschaften Eigenschaften = neu Eigenschaften(); FlowConnector.setApplicationJarClass(Eigenschaften, PrepareJob.Klasse); FlowConnector flowConnector = neu FlowConnector(Eigenschaften); Fluss Durchfluss = flowConnector.verbinden("originalSet", Quelle, Waschbecken, vorbereiten.); //GO! Durchfluss.vollständig(); return 0; } //In der Kaskadierung benötigt ein Aggregator ein Kontextobjekt, um den Status zu halten privat Klasse ToAdjacencyListContext { int Quelle; int Partition = -1; ListeInteger> Ziele = new ArrayListInteger>(); } private class ToAdjacencyList extends BaseOperationToAdjacencyListContext> implementiert AggregatorToAdjacencyListContext> { public ToAdjacencyList() { super(new Felder("partition", "Quelle", "Liste")); } @Override public void start( FlowProcess flowProcess, AggregatorCallToAdjacencyListContext> aggregatorAufruf) { //Quellknoten speichern ToAdjacencyListContext Kontext = neu ToAdjacencyListContext(); Kontext.Quelle = aggregatorAufruf.getGroup().getInteger("Quelle"); aggregatorAufruf.setKontext(Kontext); } @Override public void aggregate( FlowProcess flowProcess, AggregatorCallToAdjacencyListContext> AggregatorAufruf) { ToAdjacencyListContext Kontext = AggregatorAufruf.getContext(); TupleEntry Argumente = aggregatorAufruf.getArguments(); //Setzen Sie die Partitions-ID auf max(Quell-ID, Ziel-IDs) int Ziel = Argumente.getInteger("Ziel"); wenn (Kontext.Partition == -1) { Kontext.Partition = Ziel > Kontext.Quelle ? Ziel : Kontext.Quelle; } //Hinzufügen jedes Ziel in die Adjazenzliste Kontext.Ziele.hinzufügen(Ziel); } @Override public void complete( FlowProcess flowProcess, AggregatorCallToAdjacencyListContext> aggregatorAufruf) { ToAdjacencyListContext Kontext = aggregatorAufruf.getContext(); / /Ausgabe eines einzelnen Tupels mit der Partition, dem Quellknoten und der Adjazenzliste Tupel Ergebnis = neu Tupel( Kontext.Partition, Kontext.Quelle, StringUtils.joinObjects(",", Kontext.Ziele)); aggregatorAufruf.getOutputCollector().hinzufügen(Ergebnis); } } }
(Wenn Ihnen das alles sehr umständlich und seltsam vorkommt, sollten Sie sich vielleicht zuerst über die Cascading-Dokumentation informieren.
Hier gibt es zwei interessante Dinge. Erstens geben wir in der Gruppe nach einen zusätzlichen Sortierparameter an. Dies führt dazu, dass eine zweite Sortierung durch Cascading angewendet wird. Außerdem legen wir fest, dass die Sortierreihenfolge absteigend sein soll. Das bedeutet im Grunde, dass in jeder Gruppe der Datensatz mit der größten Zielknoten-ID zuerst sortiert wird. Zweitens verwenden wir im Aggregator einfach immer die erste Zielknoten-ID als Partitions-ID, es sei denn, die Quellknoten-ID ist größer, dann verwenden wir diese. Wir müssen nicht mehr prüfen, ob die erste Zielknoten-ID die größte ist, da dies vom MapReduce-Framework beim Sortieren garantiert wird. Die sekundäre Sortierung ist eine nützliche Funktion in MapReduce, die Sie häufig für diese Art von Aufgaben verwenden werden. Im Allgemeinen können Sie damit Dinge im Streaming-Verfahren erledigen, für die Sie sonst eine ganze Gruppe in den Speicher zwischenspeichern müssten, bevor Sie die Gruppe verarbeiten können.
Übrigens: Den gesamten Code für diesen Beitrag finden Sie hier: Graph Partitioning and other fun with Cascading and Neo4j . Um den Code auszuführen, müssen Sie Hadoop auf Ihrem lokalen Rechner richtig eingerichtet haben. Wenn Sie das Maven-Build ausführen, wird ein Job-Jar erzeugt, das Sie mit 'hadoop jar' ausführen können. Sehen Sie sich die Graph Partitioning and other fun with Cascading and Neo4j - main class für Argumente und Verwendung an.
Wenn Sie die Ergebnisse von Schritt 1+2 visualisieren, erhalten Sie das folgende Diagramm. Die Knoten sind entsprechend der Partitions-ID eingefärbt. Knoten mit der gleichen Farbe haben also die gleiche Partitions-ID. Technisch gesehen weisen wir die Partitions-IDs nicht den Knoten, sondern den Kanten zu. Die Knotenpartition ergibt sich aus der eingehenden Kante mit der größten Partitions-ID.

Übrigens: Im Repo gibt es ein Graph Partitioning and other fun with Cascading and Neo4j - Stück Python-Code, das die Ausgabe des Jobs (die Form der Adjazenzliste) übernimmt und eine GML-Darstellung des Graphen ausgibt. Die GML-Darstellung kann wiederum von Cytoscape gelesen werden, das ich zur Erstellung der Bilder verwendet habe.
Wie Sie sehen können, hat der erste Schritt bereits Quellknoten mit allen Zielen gleich markiert. Nun geht es an den iterativen Teil des Prozesses, der den Graphen durchläuft und die Partitionen auf alle dazugehörigen Knoten erweitert.
3. Finden Sie für jede Knoten-ID die größte Partitions-ID, zu der sie gehört
Im nächsten Schritt werden wir für jeden Knoten prüfen, welche die größte Partitions-ID ist, zu der er gehört. Wenn Sie sich den Knoten N23 in der obigen Abbildung ansehen, werden Sie feststellen, dass er zwei eingehende Kanten hat. Eine von N28 und eine von N20. Das bedeutet, dass N23 in zwei verschiedenen Adjazenzlisten enthalten ist, nämlich in der mit dem Quellknoten N20 und in der mit dem Quellknoten N28. Wenn wir also alle Partitions-IDs und Knoten-IDs nehmen und nach Knoten-IDs gruppieren, gibt es eine Gruppe für den Knoten N23, die zwei Partitions-IDs enthält: 26 und 29 (das sind die größten Knoten-IDs in den Datensätzen für N20 bzw. N28). Auf diese Weise können wir herausfinden, welches die größte Partitions-ID ist, zu der jeder Knoten gehört. Die Schritte sind:
- Nehmen Sie für jeden Quellknoten den Datensatz: Quellknoten = Quellknoten-ID, Knoten = Quellknoten-ID, Partition = Partitions-ID
- Fügen Sie für jeden Zielknoten in jeder Adjazenzliste den Eintrag hinzu: Quellknoten = Quellknoten-ID, Knoten = Zielknoten-ID, Partition = Partitions-ID
- Gruppieren Sie die Datensätze nach Knoten, sortiert nach Partitions-ID absteigend
- Merken Sie sich für jede Gruppe die größte Partitions-ID in der Gruppe (das ist die erste, wegen der Sortierung)
- Geben Sie für jeden Datensatz den Datensatz aus: Quellknoten, Zielknoten, größte Partitions-ID
Hier ist ein Beispiel für einen kleinen Teil des Diagramms:
-- Eingabe: Teil. Quelladjazenz ID Knotenliste 29 28 29,23 26 20 26,25,24,23,22,21
-- Datensätze erstellen: Quellknotenpartition Knoten 28 28 29 28 29 29 28 23 29 20 20 26 20 26 26 20 25 26 20 24 26 20 23 26 20 22 26 20 21 26
-- Nach Knoten gruppieren: Gruppe für Knoten 28 = 28 28 29 Gruppe für Knoten 29 = 28 29 29 Gruppe für Knoten 23 (beachten Sie die Reihenfolge) = 28 23 29 20 23 26 Gruppe für Knoten 20 = 20 20 26 Der Rest wurde entfernt.
-- Ausgabe: Quellknotenpartition Knoten 28 28 29 28 29 29 28 23 29 20 20 26 20 26 26 20 25 26 20 24 26 20 23 29 <=== DIESE wurde von 26 auf 29 aktualisiert! 20 22 26 20 21 26
Wie Sie im Beispiel sehen können, maximiert der Algorithmus die Partitions-ID an jeder der Kanten, wenn eine andere Kante gefunden wird, die einen Knoten teilt und eine größere Partitions-ID hat. Während dieses Schritts behalten wir auch den Quellknoten für jeden Knoten, den wir verarbeiten, im Auge. Dies ist erforderlich, da wir in der Lage sein müssen, den Graphen aus dieser Liste wieder zu rekonstruieren. Außerdem müssen wir im nächsten Schritt die Partitions-ID auf jeder der Adjazenzlisten aktualisieren.
4. Setzen Sie die Partitions-ID eines jeden Datensatzes auf die größte in Schritt 3 gefundene Partitions-ID
In diesem Schritt nehmen wir die Ausgabe von Schritt 3 und machen einfach fast den gleichen Trick noch einmal. Jetzt gruppieren wir nach der ID des Quellknotens und ordnen wieder nach der Partitions-ID absteigend. Aus jeder der Gruppen rekonstruieren wir die Adjazenzliste und setzen die Partitions-ID für diese Liste auf die erste, die in der Gruppe auftaucht (die wiederum die größte ist).
In diesem Beispiel wird der in Schritt 3 verwendete Teil des Diagramms fortgesetzt. Sie erhalten das folgende Ergebnis:
-- Input: source node partition node 28 28 29 28 29 29 28 23 29 20 20 26 20 26 26 20 25 26 20 24 26 20 23 29 20 22 26 20 21 26
-- Nach Quellknoten gruppieren: Gruppe für Quelle 28: 28 28 29 <=== NICHT IN ADJAKENZLISTE EINBEZIEHEN 28 29 29 28 23 29 Gruppe für Quelle 20: 20 23 29 20 20 26 <=== NICHT IN ADJAKENZLISTE EINBEZIEHEN 20 26 26 20 25 26 20 24 26 20 22 26 20 21 26
-- Erstellen Sie die Adjazenzliste neu, indem Sie die erste Partitions-ID als Partitions-ID verwenden: part. source adjacency list ID node 29 28 29,23 29 20 23,26,25,24,22,21 <=== THIS ONE GOT UPDATED FROM 26 TO 29
Hier wurde die Partitions-ID für eine Reihe von Kanten aktualisiert. Beachten Sie, dass wir in der Gruppierung auch den Quellknoten erhalten, der auf sich selbst als einen der Datensätze verweist (weil wir ihn in Schritt 3 erstellt haben). Wir müssen ein wenig Logik hinzufügen, um dies nicht in die Adjazenzlisten aufzunehmen.
Nach einer Iteration sieht das Diagramm nun wie folgt aus:

5. Wiederholen Sie Schritt 3 und 4, bis sich nichts mehr ändert.
Jedes Mal, wenn Sie die Schritte 3+4 wiederholen, wird eine weitere Tiefenebene des Diagramms aufgeteilt. Viele Graphen sind tatsächlich nicht sehr tief(sechs Trennungsgrade). Wir können die Iteration über den Graphen beenden, wenn bei der letzten Iteration nichts aktualisiert wurde. Dies zu implementieren ist relativ einfach. Wir behalten einfach einen Zähler während des Jobs und erhöhen ihn jedes Mal um eins, wenn wir eine Partitions-ID aktualisieren. Wenn nach der Ausführung der Schritte 3+4 der Zähler auf Null bleibt, können wir den Prozess beenden. In Cascading haben Sie Zugriff auf die Jobzähler von Hadoop wie in normalem MapReduce.
In der obigen Abbildung können Sie sehen, dass die erste Iteration von Schritt 3+4 tatsächlich alle Partitionen bis auf eine findet. Die Partition mit den Knoten N30 bis N36 ist problematisch, weil der längste Pfad, der innerhalb der Partition existiert, sehr lang ist (6 Kanten). Damit der Algorithmus alle Kanten vollständig markieren kann, müssen wir eine Reihe von Iterationen durchführen. Manchmal ist es Ihnen nicht so wichtig, alle vollständigen Partitionen zu finden, denn möglicherweise sind diese baumartigen Teile des Graphen für Sie nicht so interessant. In diesem Fall können Sie das Abbruchkriterium etwas abändern. Sie könnten zum Beispiel aufhören zu laufen, wenn der Zähler unter einem bestimmten Schwellenwert liegt oder wenn die Differenz zwischen dem Zähler des vorherigen Laufs und dem des letzten Laufs unter einem bestimmten prozentualen Schwellenwert liegt. Dies wird dazu führen, dass einige sehr kleine Partitionen nicht mehr mit dem Ort verbunden sind, an den sie gehören, so dass Sie diese bei der weiteren Verarbeitung wahrscheinlich ignorieren sollten. Das obige Diagramm benötigt 5 Iterationen, um zu konvergieren. Hier ist das Endergebnis:

Schauen wir uns etwas mehr Code an:
öffentlich Klasse IterateJob { öffentlich int laufen(Zeichenfolge Eingabe, Zeichenfolge Ausgabe, int maxIterations) { boolean fertig = false; int iterationCount = 0; während (!fertig) { Schema sourceScheme = neu TextDelimited(neu Felder("Partition", "Quelle", "Liste"), "t"); Schema sinkScheme = neu TextDelimited(neu Felder("Partition", "Quelle", "Liste"), "t"); //SNIPPED SOME BOILERPLATE... Pfeife Iteration = neu Pfeife("Iteration"); //Für jeden Eingabedatensatz erstellen Sie einen Datensatz pro Knoten (Schritt 3) Iteration = neu Jede(Iteration, neu FanOut()); //GROUP BY node ORDER BY partition DESCENDING Iteration = neu GroupBy( Iteration, neu Felder("Knoten"), neu Felder("Partition"), true); //Für jede Gruppe, erstellen Sie Datensätze mit der größten Partition Iteration = neu Jede( Iteration, neu MaxPartitionToTuples(), Felder.ERGEBNISSE); //GROUP BY Quellknoten ORDER BY Partition DESCENDING (Schritt 4) Iteration = neu GroupBy( Iteration, neu Felder("Quelle"), neu Felder("Partition"), true); //Für jede Gruppe erstellen Sie die Adjazenzliste neu //mit der größten Partition //Dieser Schritt aktualisiert auch den Zähler Iteration = neu Jede( Iteration, neu MaxPartitionToAdjacencyList(), Felder.ERGEBNISSE); //SNIPPED SOME BOILERPLATE... //Den Zählerwert aus dem Fluss ablesen lang updatedPartitions = Durchfluss.getFlowStats().getCounterValue( MaxPartitionToAdjacencyList.ZÄHLER_GRUPPE, MaxPartitionToAdjacencyList.PARTITIONEN_AKTUALISIERT_ZÄHLER_NAME); // Sind wir fertig? fertig = updatedPartitions == 0 || iterationCount == maxIterations - 1; iterationCount++; } return 0; } //Kontextobjekt für die Speicherung des Status im Aggregator privat Klasse MaxPartitionToAdjacencyListContext { int Quelle; int Partition = -1; ListeInteger> Ziele; public MaxPartitionToAdjacencyListContext() { this.Targets = new ArrayListInteger>(); } } @WarnungenUnterdrücken("serial") private class MaxPartitionToAdjacencyList extends BaseOperationMaxPartitionToAdjacencyListContext> implementiert AggregatorMaxPartitionToAdjacencyListContext> { //Konstanten für Zählernamen verwendet öffentlich endgültig Zeichenfolge PARTITIONEN_AKTUALISIERT_ZÄHLER_NAME = "Aktualisierungen der Partitionen"; öffentlich endgültig Zeichenfolge ZÄHLER_GRUPPE = "Diagramme"; public MaxPartitionToAdjacencyList() { super(new Felder("partition", "Quelle", "Liste")); } @Override public void start( FlowProcess flowProcess, AggregatorCallMaxPartitionToAdjacencyListContext> aggregatorAufruf) { //Initialisieren Sie den Kontext MaxPartitionToAdjacencyListContext Kontext = neu MaxPartitionToAdjacencyListContext(); Kontext.Quelle = aggregatorAufruf.getGroup().getInteger("Quelle"); aggregatorAufruf.setKontext(Kontext); } @Override public void aggregate( FlowProcess flowProcess, AggregatorCallMaxPartitionToAdjacencyListContext> aggregatorAufruf) { //Neuerstellung des Gaphs und Aktualisierung des Zählers bei Änderungen MaxPartitionToAdjacencyListContext Kontext = aggregatorAufruf.getContext(); TupleEntry Argumente = aggregatorAufruf.getArguments(); int Partition = Argumente.getInteger("Partition"); wenn (Kontext.Partition == -1) { Kontext.Partition = Partition; } sonst wenn (Kontext.Partition > Partition) { flowProcess.inkrementieren(COUNTER_GROUP, PARTITIONEN_AKTUALISIERT_ZAEHLER_NAME, 1); } //Ignorieren Sie den Quellknoten bei der Erstellung der Liste int Knoten = Argumente.getInteger("Knoten"); wenn (Knoten != Kontext.Quelle) { Kontext.Ziele.hinzufügen(Knoten); } } @Override public void complete( FlowProcess flowProcess, AggregatorCallMaxPartitionToAdjacencyListContext> aggregatorAufruf) { //Ausgabe der Liste MaxPartitionToAdjacencyListContext Kontext = aggregatorAufruf.getContext(); Tupel Ergebnis = neu Tupel( Kontext.Partition, Kontext.Quelle, StringUtils.joinObjects(",", Kontext.Ziele)); aggregatorAufruf.getOutputCollector().hinzufügen(Ergebnis); } } @SuppressWarnungen({ "serial", "rawtypes", "unchecked" }) private class MaxPartitionToTuples extends BaseOperation implementiert Puffer { public MaxPartitionToTuples() { super(new Felder("partition", "Knoten", "Quelle")); } @Override public void operate(FlowProcess flowProcess, PufferAufruf bufferCall) { IteratorTupleEntry> itr = bufferCall.getArgumentsIterator(); int maxPartition; TupleEntry Eintrag = itr.nächste(); maxPartition = Eintrag.getInteger("partition"); emitTuple(bufferCall, maxPartition, Eintrag); während (itr.hasNext()) { Eintrag = itr.nächste(); emitTuple(bufferCall, maxPartition, Eintrag); } } privat void emitTuple(PufferAufruf bufferCall, int maxPartition, TupleEntry Eintrag) { Tupel Ergebnis = neu Tupel( maxPartition, Eintrag.getInteger("Knoten"), Eintrag.getInteger("Quelle")); bufferCall.getOutputCollector().hinzufügen(Ergebnis); } } @SuppressWarnungen({ "serial", "rawtypes" }) privat Klasse FanOut erweitert BaseOperation implementiert Funktion { öffentlich FanOut() { super(3, neu Felder("Partition", "Knoten", "Quelle")); } @Override öffentlich void betreiben(FlowProcess flowProcess, FunktionsAufruf functionCall) { TupleEntry args = functionCall.getArguments(); int Partition = args.getInteger("Partition"); int Quelle = args.getInteger("Quelle"); Tupel Ergebnis = neu Tupel(Partition, Quelle, Quelle); functionCall.getOutputCollector().hinzufügen(Ergebnis); für (Zeichenfolge Knoten : args.getString("Liste").geteilt(",")) { Ergebnis = neu Tupel(Partition, Integer.parseInt(Knoten), Quelle); functionCall.getOutputCollector().hinzufügen(Ergebnis); } } } }
Der obige Code ist der Code für die Schritte 3, 4 und 5. Die ungekürzte, vollständige Version finden Sie im Github Repo.
Vollständig verbundene Graphen
In Wirklichkeit sind die meisten Graphen vollständig verbunden und nicht wie in unserem Beispiel unverbunden. Wenn es in Ihrem Graphen beispielsweise um Clickstream-Daten geht, gibt es oft einen Crawler oder ein großes Unternehmensnetzwerk, in dem alle dieselbe IP-Adresse haben, die alles im Graphen miteinander verbindet. In einem solchen Fall wird der Algorithmus nur eine einzige Partition ausgeben, was nicht sehr hilfreich ist. In einem nächsten Beitrag (in Kürze) werden wir uns ansehen, wie wir den Algorithmus so modifizieren können, dass er eine Partitionierung verbundener Graphen vornimmt, indem er ein Kriterium verwendet, um bestimmte Teile nicht miteinander zu verknüpfen, selbst wenn eine Verbindung besteht. Bleiben Sie dran! Natürlich befindet sich der Code dafür bereits im Repo, Sie können ihn also ausprobieren und herausfinden, wie er funktioniert.
Unsere Ideen
Weitere Blogs




Contact