Fairness wird unter Forschern und Praktikern im Bereich des maschinellen Lernens immer mehr zu einem heißen Thema. Die Branche ist sich bewusst, dass ihre Modelle einen großen Einfluss auf die Gesellschaft haben und dass ihre Vorhersagen nicht immer vorteilhaft sind. In einem früheren Blog hat Stijn gezeigt, wie kontradiktorische Netzwerke verwendet werden können, um fairere Vorhersagen zu treffen. In diesem Blogbeitrag geht es um die Implementierung, so dass Sie als Praktiker in der Lage sind, Ihre eigenen fairen Klassifikatoren zu erstellen.
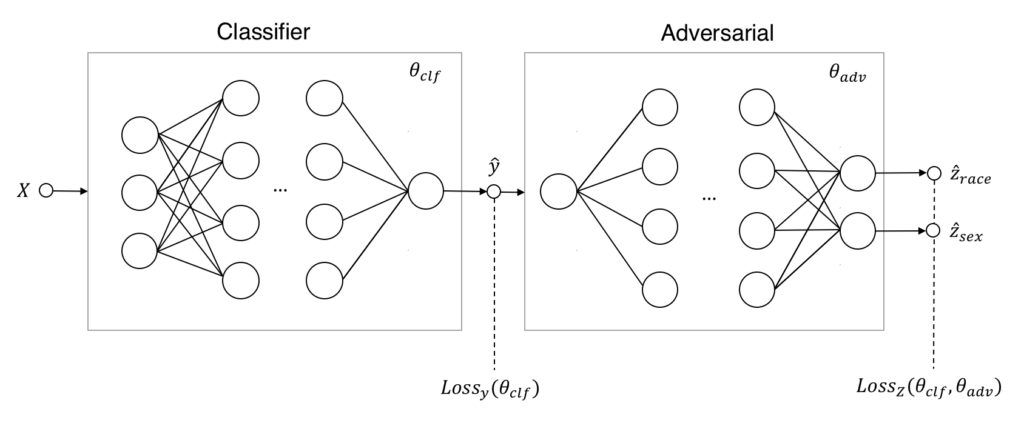
Beginnen wir mit einer kurzen Rekapitulation, wie adversarische Netzwerke helfen können, Unfairness zu bekämpfen. Anstatt nur einen einzigen Klassifikator zu haben, der Vorhersagen macht hat{y} mit Daten X, führen wir einen Gegner ein, der versucht vorherzusagen, ob der Klassifikator für die sensiblen Attribute Z unfair ist. Der Klassifikator muss mit dem Gegner in einem Nullsummenspiel konkurrieren: Der Klassifikator muss gute Vorhersagen machen, wird aber bestraft, wenn der Gegner unfaire Entscheidungen feststellt. Das Endergebnis dieses Spiels ist hoffentlich ein fairer Klassifikator, der auch gut in der Vorhersage ist.
Daten
Unser Ziel ist es, das Einkommensniveau auf der Grundlage von persönlichen Merkmalen wie Alter, Bildung und Familienstand vorherzusagen. Das Problem ist, dass unser Standardklassifikator unfair gegenüber Schwarzen und Frauen ist. Wenn alle anderen Attribute gleich sind, werden Frauen zum Beispiel ein niedrigeres Einkommen vorhersagen als Männer - obwohl das Geschlecht nicht Teil der persönlichen Attribute ist. Verzerrungen wie diese können spezifisch für einen Datensatz sein oder sogar die reale Welt widerspiegeln, aber wir wollen nicht, dass sie zu ungerechten Vorhersagen führen. Wir beginnen mit unserem Datensatz aus dem vorherigen Blog. Wir haben die folgenden Pandas DataFrames:X_trainX_test: Attribute, die für die Vorhersage verwendet werden - wie Alter und Heimatlandy_trainy_test: Ziel, das wir vorhersagen wollen - wenn jemand mehr als 50K verdientZ_trainZ_test: Empfindliche Attribute - Ethnie und Hautfarbe
Dataset und DataLoader verwenden. Ein DataLoader nimmt ein Dataset und hilft Ihnen beim Mischen und Stapeln Ihrer Stichproben.
Ein Dataset nimmt in der Regel PyTorch-Tensoren auf und gibt sie zurück, keine Zeilen aus einem Pandas DataFrame. Fügen wir dem TensorDataset, damit wir eine Dataset mit unseren Pandas DataFrames initialisieren können:
import torch
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
class PandasDataSet(TensorDataset):
def __init__(self, *dataframes):
tensors = (self._df_to_tensor(df) for df in dataframes)
super(PandasDataSet, self).__init__(*tensors)
def _df_to_tensor(self, df):
if isinstance(df, pd.Series):
df = df.to_frame()
return torch.from_numpy(df.values).float()
train_data = PandasDataSet(X_train, y_train, Z_train)
test_data = PandasDataSet(X_test, y_test, Z_test)DataLoader, die gemischte Stapel unseres Trainingssets zurückgibt:
train_loader = DataLoader(train_data, batch_size=32, shuffle=True, drop_last=True)
print('# training samples:', len(train_data))
print('# batches:', len(train_loader))
> # training samples: 15470
> # batches: 483train_loader bzw. test_data. Wir erhalten Datenstapel, wenn wir über train_loader iterieren. test_data wird zum Testen unserer Vorhersagen verwendet.
Einkommensprognosen
Mit unseren Datensätzen definieren und trainieren wir den Klassifikator, der Einkommensvorhersagen machen soll. Dieser Klassifikator ist gut in der Vorhersage des Einkommensniveaus, aber wahrscheinlich unfair - er wird nur für seine Leistung und nicht für seine Fairness bestraft. Die PyTorch'snn Modul macht die Implementierung eines neuronalen Netzwerks einfach. Wir erhalten eine voll funktionsfähige Netzwerkklasse, indem wir von nn.Module erben und die Methode .forward() implementieren. Unser Netzwerk besteht aus drei sequentiellen versteckten Schichten mit ReLu-Aktivierung und Dropout. Die sigmoidale Schicht wandelt diese Aktivierungen in eine Wahrscheinlichkeit für die Einkommensklasse um.
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class Classifier(nn.Module):
def __init__(self, n_features, n_hidden=32, p_dropout=0.2):
super(Classifier, self).__init__()
self.network = nn.Sequential(
nn.Linear(n_features, n_hidden),
nn.ReLU(),
nn.Dropout(p_dropout),
nn.Linear(n_hidden, n_hidden),
nn.ReLU(),
nn.Dropout(p_dropout),
nn.Linear(n_hidden, n_hidden),
nn.ReLU(),
nn.Dropout(p_dropout),
nn.Linear(n_hidden, 1),
)
def forward(self, x):
return F.sigmoid(self.network(x)clf = Classifier(n_features=n_features)
clf_criterion = nn.BCELoss()
clf_optimizer = optim.Adam(clf.parameters())DataLoader zurückgegebenen Batches.
N_CLF_EPOCHS = 2
for epoch in range(N_CLF_EPOCHS):
for x, y, _ in data_loader:
clf.zero_grad()
p_y = clf(x)
loss = clf_criterion(p_y, y)
loss.backward()
clf_optimizer.step()- Setzen Sie die für unseren Klassifikator relevanten Gradienten auf Null.
- Lassen Sie den Klassifikator
clffür eine Chargexvorhersagen, ump_yzu erhalten. - Berechnen Sie den Verlust anhand der Vorhersagen und der tatsächlichen Antwort.
- Backpropagieren Sie den Verlust mit einer
.backward(), um die Gradienten zu erhalten und die Fehler zu verringern. - Lassen Sie den Optimierer des Klassifizierers einen Optimierungsschritt mit diesen Gradienten durchführen.
Unfairness aufspüren
Nachdem wir den Klassifikator trainiert haben, definieren und trainieren wir nun den Gegenspieler. Ähnlich wie der Klassifikator besteht auch unser Gegenspieler aus drei Schichten. Allerdings stammt die Eingabe aus einer einzigen Klasse (der vorhergesagten Einkommensklasse) und die Ausgabe besteht aus zwei sensiblen Klassen (Geschlecht und Ethnie). Bei unserer endgültigen Lösung wird es einen Kompromiss zwischen der Leistung des Klassifizierers und der Fairness für unsere sensiblen Attribute geben. Wir werden den gegnerischen Verlust optimieren, um diesen Kompromiss zu berücksichtigen: Der Lambda-Parameter gewichtet den gegnerischen Verlust jeder Klasse. Dieser Parameter wird später auch verwendet, um die Leistung des Gegners gegenüber der Leistung des Klassifizierers zu skalieren. Indem wirnn.BCELoss anweisen, nicht zu reduzieren, erhalten wir die Verluste für jede einzelne Probe und Klasse anstelle einer einzigen Zahl. Multiplizieren Sie dies mit unserer lambdas und bilden Sie den Durchschnitt, um den gewichteten Verlust zu erhalten, der unser Indikator für Unfairness ist.
class Adversary(nn.Module):
def __init__(self, n_sensitive, n_hidden=32):
super(Adversary, self).__init__()
self.network = nn.Sequential(
nn.Linear(1, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, n_sensitive),
)
def forward(self, x):
return F.sigmoid(self.network(x))
lambdas = torch.Tensor([200, 30])
adv = Adversary(Z_train.shape[1])
adv_criterion = nn.BCELoss(reduce=False)
adv_optimizer = optim.Adam(adv.parameters())
N_ADV_EPOCHS = 5
for epoch in range(N_ADV_EPOCHS):
for x, _, z in data_loader:
adv.zero_grad()
p_y = clf(x).detach()
p_z = adv(p_y)
loss = (adv_criterion(p_z, z) * lambdas).mean()
loss.backward()
adv_optimizer.step()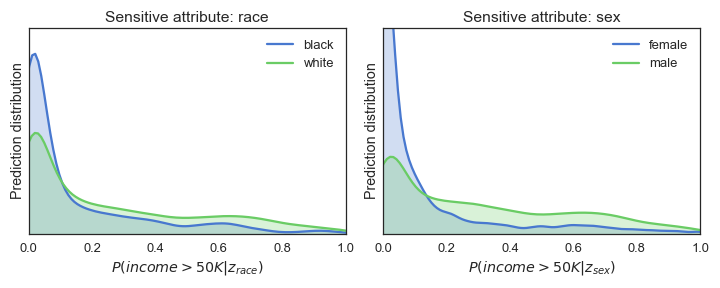 Leider hat der Wechsel des Frameworks den Klassifikator nicht auf magische Weise fairer gemacht. Das sehen wir an der Wahrscheinlichkeitsregel p% und an den Verteilungen, aber auch an der ROC AUC-Punktzahl des Gegners. Ein Wert von mehr als 0,5 zeigt an, dass der Gegner in der Lage ist, Unfairness zu erkennen.
Leider hat der Wechsel des Frameworks den Klassifikator nicht auf magische Weise fairer gemacht. Das sehen wir an der Wahrscheinlichkeitsregel p% und an den Verteilungen, aber auch an der ROC AUC-Punktzahl des Gegners. Ein Wert von mehr als 0,5 zeigt an, dass der Gegner in der Lage ist, Unfairness zu erkennen.
Training für Fairness
Da wir nun einen unfairen Klassifikator und einen Gegner haben, der in der Lage ist, die Unfairness zu erkennen, können wir sie in das Nullsummenspiel verwickeln, um den Klassifikator fair zu machen. Denken Sie daran, dass der faire Klassifizierer entsprechend bestraft wird:min_{theta_{clf}}left[Loss_{y}(theta_{clf})-lambda Loss_{Z}(theta_{clf},theta_{adv})right].lambda stellt den Kompromiss zwischen diesen beiden Begriffen dar: Er wägt die Bestrafung durch den Gegner gegen die Vorhersageleistung ab.
Der Gegner lernt mit dem gesamten Datensatz und der Klassifikator erhält nur die einzelne Charge, was dem Gegner einen leichten Vorteil beim Lernen verschafft. Die Verlustfunktion für den Klassifikator wird in seinen ursprünglichen Verlust plus den gewichteten negativen Verlust des Gegners geändert.
N_EPOCH_COMBINED = 165
for epoch in range(1, N_EPOCH_COMBINED):
# Train adversary
for x, y, z in data_loader:
adv.zero_grad()
p_y = clf(x)
p_z = adv(p_y)
loss_adv = (adv_criterion(p_z, z) * lambdas).mean()
loss_adv.backward()
adv_optimizer.step()
# Train classifier on single batch
for x, y, z in data_loader:
pass # Ugly way to get a single batch
clf.zero_grad()
p_y = clf(x)
p_z = adv(p_y)
loss_adv = (adv_criterion(p_z, z) * lambdas).mean()
clf_loss = clf_criterion(p_y, y) - (adv_criterion(adv(p_y), z) * lambdas).mean()
clf_loss.backward()
clf_optimizer.step()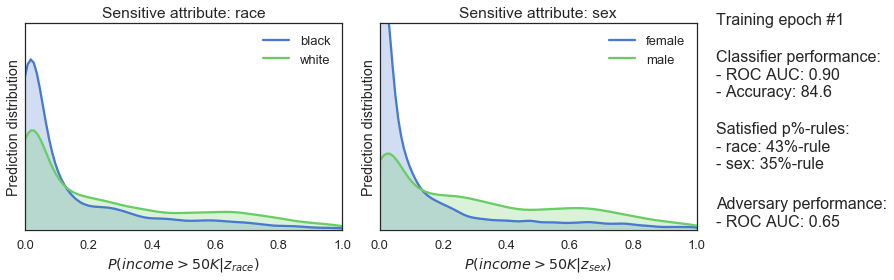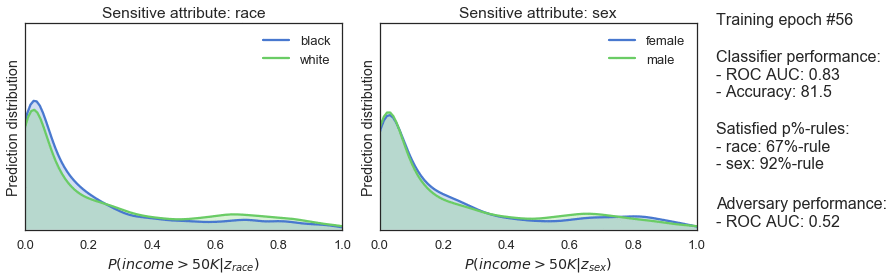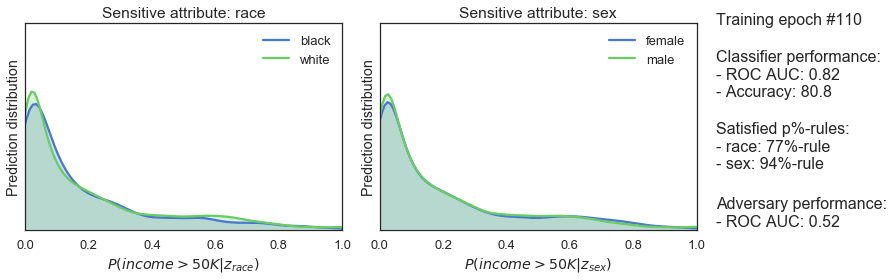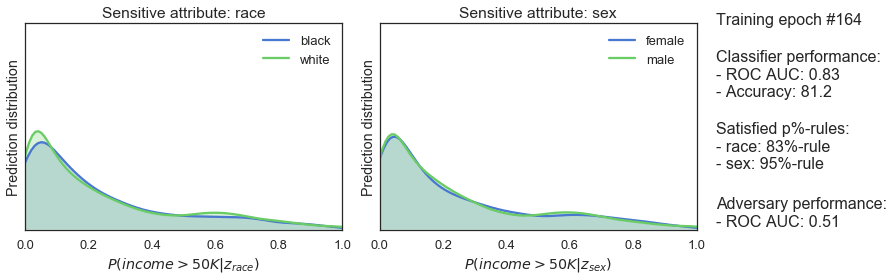
Fazit
Dieser Blog führte Sie durch die Schritte zur Implementierung eines fairen Klassifizierers in PyTorch. Sie finden diese und die ursprüngliche Keras-Implementierung in unserem GitHub Repo. Bitte eröffnen Sie einen Pull Request, wenn Sie dieses Modell erfolgreich auf Ihren Datensatz angewendet haben! Ein großes Lob an Stijn für die ursprüngliche Umsetzung und die Überprüfung dieses Blogs!Verbessern Sie Ihre Python-Kenntnisse, lernen Sie von den Experten!
Bei GoDataDriven bieten wir eine Vielzahl von Python-Kursen an, die von den besten Experten auf diesem Gebiet unterrichtet werden. Kommen Sie zu uns und verbessern Sie Ihr Python-Spiel:- Data Science with Python Foundation - Möchten Sie den Schritt von der Datenanalyse und -visualisierung zu echter Datenwissenschaft machen? Dies ist der richtige Kurs.
- Advanced Data Science with Python - Lernen Sie, Ihre Modelle wie ein Profi zu produzieren und Python für maschinelles Lernen zu verwenden.
Verfasst von
Henk Griffioen




Contact