Blog
Fairness in der KI - Dutch Data Science Week 2019

Auf der Dutch Data Science Week habe ich einen Vortrag über Fairness in der KI gehalten. Der Einfluss der KI auf die Gesellschaft wird immer größer - und nicht alles ist gut. Wir als Data Scientists müssen uns wirklich anstrengen, um nicht in der ML-Hölle zu landen!
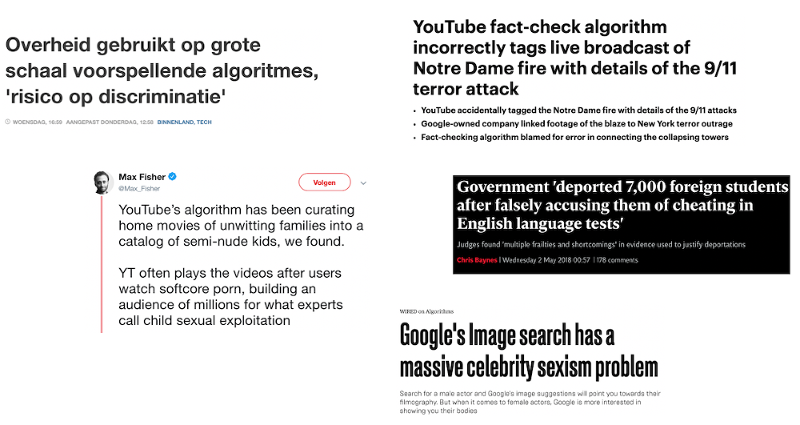
Niederländische Steuerbehörden in den Nachrichten
Ethnisches Profiling durch die niederländischen Steuerbehörden ist ein aktuelles Beispiel für algorithmische (Un-)Fairness. Aus einem Artikel in der Zeitung NRC:
"Eine Kindertagesstätte in Almere schlug Alarm, als nur nicht-niederländische Eltern mit der Streichung des Kinderbetreuungsgeldes konfrontiert wurden [...] Die Steuer- und Zollverwaltung sagt, dass sie die Daten über die niederländische oder nicht-niederländische Staatsangehörigkeit bei der sogenannten automatischen Risikoauswahl für Betrug verwendet."
Nicht-niederländische Eltern ins Visier zu nehmen und niederländische Eltern unberührt zu lassen, ist ein klares Beispiel für unfaire Betrugserkennung! Die niederländischen Behörden haben geantwortet, dass dieser Fehler bereits behoben wurde:
In einer Antwort erklärt die Steuer- und Zollverwaltung, dass die Informationen über die (zweite) Staatsangehörigkeit der Eltern oder des Vermittlers bei dieser Untersuchung nicht verwendet werden [...] "Seit 2014 wird eine zweite Staatsangehörigkeit mit niederländischer Staatsangehörigkeit nicht mehr bei der Basisregistrierung berücksichtigt. Dies wurde eingeführt, um die Diskriminierung von Menschen mit doppelter Staatsbürgerschaft zu verhindern."
Die Nichtverwendung der Nationalität scheint ein guter Schritt zu sein, aber reicht das aus, um faire Entscheidungen zu treffen? Wahrscheinlich nicht: Verzerrungen können immer noch durch Stellvertreter im Datensatz kodiert werden. Zum Beispiel kann die Nationalität immer noch implizit in den Daten durch Beruf, Bildung und Einkommen kodiert werden. Wir müssen Fairness aktiv aus dem System entfernen.
Durchsetzung von Fairness
In meinem Vortrag auf der Dutch Data Science Week habe ich gezeigt, wie man Fairness mit Hilfe eines Fairness-Schiedsrichters durchsetzen kann. Wir beginnen mit einem Standard-Klassifikator, geben die Ergebnisse aber an einen gegnerischen Klassifikator weiter, der wie ein Schiedsrichter agiert. Dieser Schiedsrichter versucht, die Voreingenommenheit aus den Vorhersagen zu rekonstruieren und bestraft den Klassifikator, wenn er eine Unfairness findet.
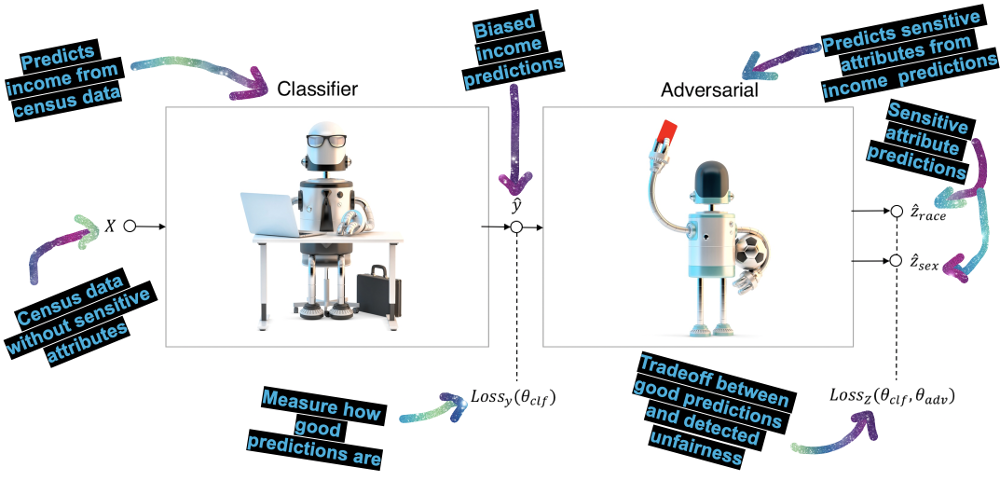
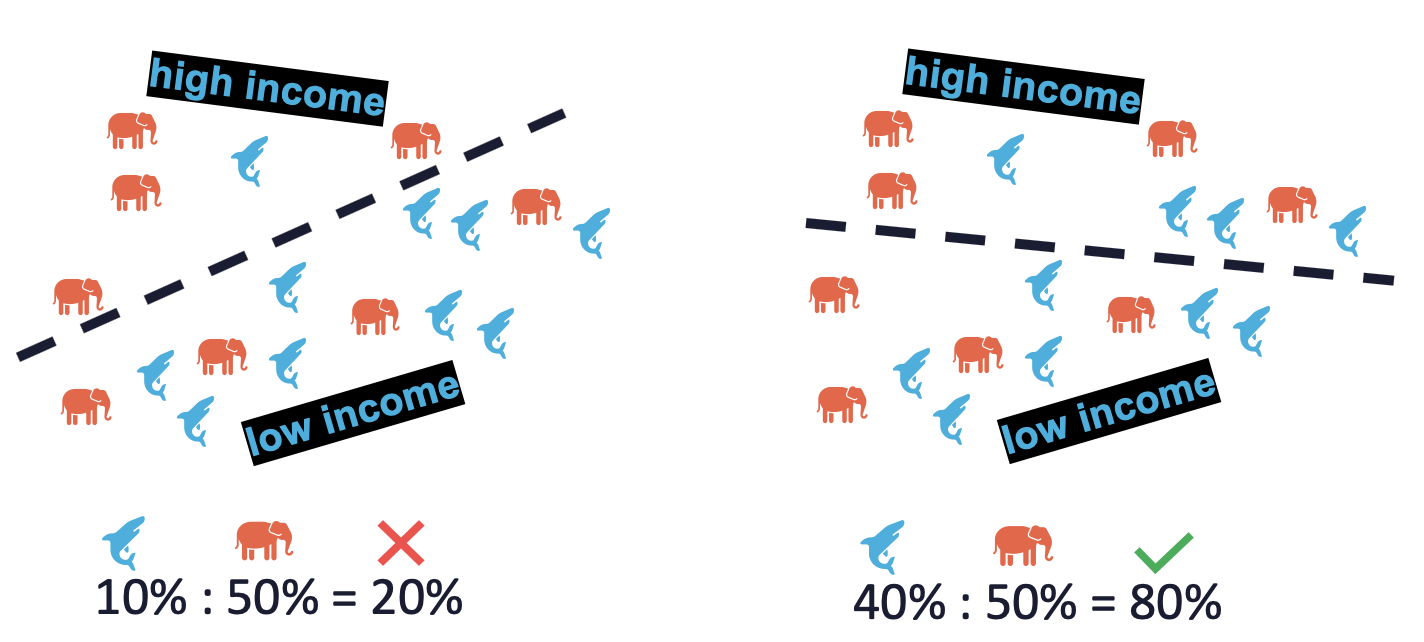
Wir können die p%-Regel verwenden, um zu prüfen, ob dies funktioniert. Diese Regel misst die demografische Gleichheit, indem sie die ungleichen Auswirkungen auf eine Gruppe von Menschen quantifiziert. Die p%-Regel ist definiert als das Verhältnis von:
- die Wahrscheinlichkeit eines positiven Ergebnisses, wenn das sensible Attribut wahr ist;
- und die Wahrscheinlichkeit eines positiven Ergebnisses, wenn das sensible Attribut falsch ist;
Ein Algorithmus gilt als fair, wenn er mindestens (p%):100% ist - wobei (p%) oft auf 80% festgelegt wird.
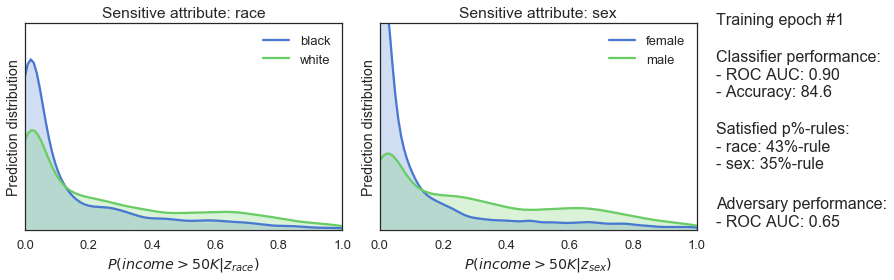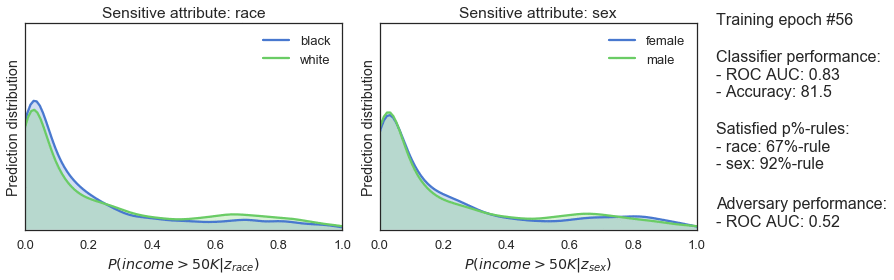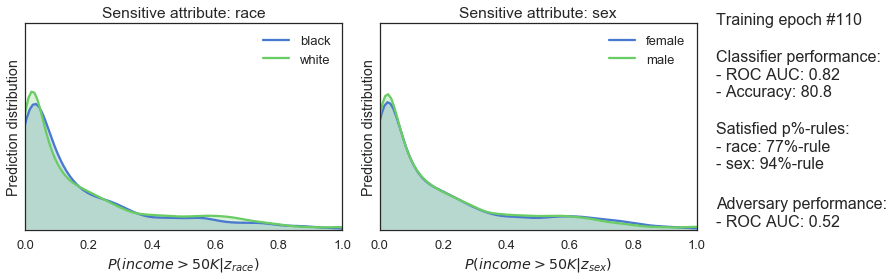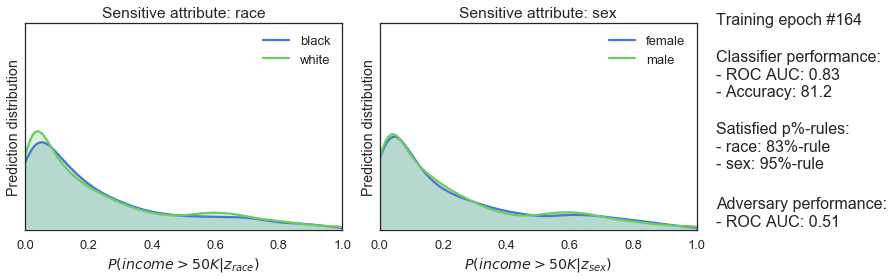
Während des Trainings wechseln sich der Klassifikator und die Gegenpartei ab. Der Gegenspieler versucht, sensible Klassen aus der Ausgabe des Klassifizierers vorherzusagen und berechnet eine Unfairness-Strafe. Während der Klassifikator an der Reihe ist, versucht er, seine Vorhersagen zu verbessern und fair zu sein, was durch eine Standard-Leistungsstrafe und die Fairnessstrafe erzwungen wird. Mit der Zeit bleibt der Klassifikator prädiktiv und wird fairer - wie die steigende p%-Regel in der Abbildung unten zeigt.
Sich anstrengen
Es ist schön, ein Problem lösen zu können, aber es erfordert viel Aufwand, um nicht in der ML-Hölle zu landen. Fairness beim maschinellen Lernen ist nicht einfach: Es gibt viel mehr Metriken und Ansätze zur Auswahl als die p%-Regel und gegnerisches Training. Das Training fairer Algorithmen ist auch nur ein kleiner Teil des Puzzles: Fairness sollte ein Teil Ihres Produktprozesses sein. YouTube zum Beispiel sollte sein Produkt ständig ändern und verbessern, da immer wieder
Die Folien meines Vortrags auf der DDSW finden Sie hier.
Sind Ihre Algorithmen fair?
Möchten Sie mehr über die Durchsetzung von Fairness in Algorithmen für maschinelles Lernen erfahren? GoDataDriven hat zwei Kurse, die Ihnen helfen werden, dieses Thema zu verstehen:
- Data Science for Product Owners - Dieser Kurs richtet sich an Personen, die zwischen den Datenteams und dem Unternehmen sitzen. Sie sorgen dafür, dass KI-Lösungen wertvoll, aber auch fair sind
- Advanced Data Science with Python - Dieser technische Kurs vermittelt Ihnen alles, was Sie über maschinelles Lernen mit Python wissen müssen.
Verfasst von
Henk Griffioen
Unsere Ideen
Weitere Blogs




Contact