Als ich zum ersten Mal KI für die Datenmodellierung einsetzte, sah das resultierende Datenmodell auf dem Papier perfekt aus. Sauberes Schema, richtige Normalisierung, solides SQL im dbt-Projekt. Wir übergaben ihm die DDL und baten um ein Kimball-Modell. Was wir bekamen, war technisch korrekt... und völlig falsch.
Das Problem war nicht die KI. Die Primärschlüssel in diesem Altsystem (das in den neunziger Jahren entwickelt wurde) waren eigentlich keine Primärschlüssel. Technische Zwänge hatten dazu geführt, dass dieselben IDs im Laufe der Zeit immer wieder verwendet wurden. Eine article_code hatte in den verschiedenen Abteilungen unterschiedliche Bedeutungen, aber beide Versionen sahen identisch aus: eine einfache sechsstellige Ganzzahl. Als echte Daten in das Modell einflossen, wurden doppelte Zeilen erzeugt und die logische Kardinalität war nicht mehr gegeben. Wir fingen wieder bei Null an.
Das war vor der aktuellen Generation von KI-Modellen, und wir waren noch nicht einmal in der Nähe der Produktion. Wir prüften, ob KI bei der Datenmodellierung überhaupt helfen konnte. Das Urteil an diesem Tag lautete nein. Das lag nicht daran, dass die KI kein SQL schreiben konnte, sondern daran, dass der richtige Kontext fehlte.
Drei Arten von Kontext
Datensysteme tragen den Kontext in drei Schichten, aber nur eine davon wird aufgeschrieben.
Die erste ist explizit: DDL-Anweisungen, Fremdschlüssel, Code zum Verbinden von Tabellen, Schemadateien, Dokumentation. Dies ist die Ebene, die AI erhält. Es ist auch die einzige Ebene, die konsequent niedergeschrieben wird.
Die zweite ist implizit: die Form der Daten selbst. Spaltennamen, Wertmuster, was vorhanden ist und was nicht. Daraus können Sie eine Menge ableiten: eine article_code, die ganze Zahlen abteilungsübergreifend wiederverwendet, sagt Ihnen etwas. KI-Modelle der neuen Generation (LLMs), wie Opus 4.6, Gemini 3.1 und ChatGpt 5.2, können dies besser als früher und sind jetzt in der Lage, viel mehr Kontexte aus dieser Ebene zu extrahieren.
Der dritte ist der Mensch. Sie entscheidet darüber, ob ein Modell in der Praxis tatsächlich funktioniert. Stammeswissen. Geschäftsregeln. Die Geschichte, warum eine Spalte dienstags eine bestimmte Bedeutung hat und an anderen Tagen nicht. Die Tatsache, dass "Kunde" in der EU-Datenbank etwas anderes bedeutet als in der US-Datenbank. Der Grund, warum es jedes Jahr eine Lücke in den Daten gibt, weil ein Land die Sommerzeit nicht einhält.
Joe Reis schreibt schon seit einer Weile über diese Konvergenz. In seinem Praktische Datenmodellierung Serie bringt er es direkt auf den Punkt: "Während sich die traditionelle Modellierung auf die technische Struktur konzentriert hat, wird eine wichtige Komponente oft übersehen: das gemeinsame Verständnis."
Die 2026 State of Data Engineering Umfrage ergab, dass 82% der Praktiker täglich KI-Tools verwenden, aber nur 11% sagen, dass ihre Datenmodellierung gut läuft. Diese Lücke ist kein Zufall. Es liegt an der fehlenden Kontextebene.
Der Junior-Analyst weiß das bereits
Wenn ein junger Ingenieur zu einem Team stößt, überreichen Sie ihm nicht die DDL und wünschen ihm viel Glück. Das ist der erste Tag. Danach kommt das eigentliche Onboarding: Pair Programming-Sitzungen, bei denen der Kontext, der nicht auf einer Confluence-Seite steht, übertragen wird.
Dinge wie:
- "Jedes Jahr haben wir eine Lücke in den Daten, weil es in diesem Land keine Sommerzeit gibt, also müssen wir eine Rückrechnung durchführen."
- "Wir verwenden dafür drei verschiedene Tabellen, weil das Unternehmen spezifische Regeln für jeden Bereich wünscht.
- "Das Suffix RED bedeutet, dass diese Tabellen für die Berichterstattung auf C-Ebene verwendet werden, aber die gleichen Daten enthalten wie die anderen Tabellen."
Wir erwarten von der KI, dass sie all dies weiß, indem sie einfach SQL betrachtet.
Ein Junior-Analyst, der in ein neues Team eintritt, verbringt Monate damit, die menschliche Kontextebene zu rekonstruieren. Er stellt Fragen, macht Fehler und baut das Bild langsam auf. Genau das ist das Onboarding. Die KI erhält die DDL und eine Systemaufforderung und wir erwarten, dass sie wie von Zauberhand funktioniert, ohne den monatelangen Kontext, den wir jedem menschlichen Ingenieur geben, bevor wir ihm das System anvertrauen.
Ich habe an einem Projekt gearbeitet, bei dem das Management einen Ingenieur aus dem Ruhestand holen musste. Es handelte sich um ein niederländisches Einzelhandelsunternehmen, und er war die einzige Person, die noch wusste, wie die Daten in dem Altsystem gespeichert waren: was die Codes bedeuteten, warum die Spaltennamen wie kryptische Abkürzungen aussahen (niederländische Kurzschrift von vor Jahrzehnten). An diesem Projekt war keine KI beteiligt. Aber die Lektion lässt sich übertragen: Wenn das menschliche Team diesen Kontext ohne ihn nicht rekonstruieren konnte, hätte eine KI, der das gleiche Schema übergeben wurde, genauso zu kämpfen gehabt.
Sie können die Kardinalität aus dem Code ableiten. Aus der Struktur allein können Sie keine Bedeutung ableiten.
Warum eine bessere Eingabeaufforderung das Problem nicht löst
Die erste Reaktion auf Fehler bei der KI-Modellierung ist in der Regel eine bessere Aufforderung. Mehr Details, mehr Kontext in der Systemmeldung, eine andere Formulierung. Ich habe beobachtet, wie Teams wochenlang damit beschäftigt waren.
Es funktioniert nicht. Das Problem ist nicht die Eingabeaufforderung. Die menschliche Kontextebene wurde nie aufgeschrieben, also gibt es nichts, was man dort hineinschreiben könnte. Sie können Spalten beschreiben. Sie können nicht beschreiben, was Sie nicht wissen. Wenn z.B. nie jemand aufgeschrieben hat, dass eine Spalte dienstags an einem blauen Mond etwas anderes bedeutet, werden Sie nicht danach fragen.
Die Unterscheidung, auf die es hier ankommt, ist die zwischen Prompt-Engineering und Context-Engineering, ein Begriff, den Andrej Karpathy im Jahr 2025 in Umlauf gebracht hat. Bei Prompt Engineering geht es darum, wie Sie fragen. Beim Context Engineering geht es darum, welche Informationen vorhanden sind, bevor das Modell eine Frage sieht. Bei der Datenmodellierung liegt der Fehler nicht vor dem Prompt. Es ist dem Datensystem selbst vorgelagert.
Joel Spolskys Gesetz der undichten Abstraktionen besagt, dass alle nicht-trivialen Abstraktionen bis zu einem gewissen Grad undicht sind: Die zugrunde liegende Komplexität sickert durch. Übertragen auf die Datenmodellierung bedeutet dies, dass eine KI ein Schema generieren kann, das auf dem Papier perfekt aussieht, aber in der Produktion versagt, weil sie nicht weiß, dass Ihr Logistikpartner den Versand unterschiedlich handhabt oder dass "Kunde" in verschiedenen Regionen etwas anderes bedeutet.
Die Abstraktion verbirgt den ungeschriebenen Kontext. Bis etwas kaputt geht.
Die Methodik: Machen Sie zuerst die konzeptionelle Phase
Die Datenmodellierung wurde von Anfang an in drei Ebenen unterteilt: die konzeptionelle, die logische und die physische Ebene. Die konzeptionelle Ebene erfasst das große Ganze: Was sind die grundlegenden Konzepte und wie hängen sie zusammen? Auf der logischen Ebene werden Entitäten, Attribute und Beziehungen definiert. Die physische Ebene setzt all dies in konkrete Datenbankobjekte um: Tabellen, Spalten, Indizes. Die grundlegende Arbeit von Ralph Kimball kodifizierte diese Progression und ist auch heute noch die Grundlage der analytischen Datenmodellierung.
Wie Reis im Jahr 2025 schrieb: "Die physische Modellierung ist allgegenwärtig; sie ist die Standardmethode, die ich heute bei der Datenmodellierung sehe." Teams, die unter Druck standen, zwängten die Designarbeit in zweiwöchige Sprints. Sprints ersetzten Blaupausen. Die konzeptionellen und logischen Phasen verschwanden still und leise. Und dbt machte es noch einfacher, sie zu überspringen. Wie Reis im Jahr 2023 schrieb: "Ich glaube, wenn man mit dbt arbeitet, vergisst man leicht, dass das dbt-Modell immer noch ein Datenmodell ist, das leicht zu erstellen und zu implementieren ist, aber wenn man es erklären muss, liefert dbt nur ein Liniendiagramm und nicht, wie sich die Inhalte zueinander verhalten."
KI-Modelle und Agenten brauchen diese Pläne, um sich in unseren Datensystemen zurechtzufinden. Sie auszulassen ist so, als würden Sie jemanden beauftragen, ein altes Haus zu renovieren, ohne vorher nach dem Elektroplan zu fragen. Sie werden Löcher in die Wände machen. Ohne Baupläne, so sagte mir ein Freund eines Freundes, werden einige dieser Löcher beim Versuch, ein Gemälde aufzuhängen, auf Gasleitungen treffen...
Die konzeptionelle Phase externalisiert die menschliche Kontextebene, bevor eine einzige SQL-Zeile geschrieben wird:
- Topologie: welche Einheiten existieren und wie sie zusammenhängen. Keine Tabellen. Konzepte.
- Taxonomie: wie Entitäten klassifiziert und benannt werden, welche Varianten es gibt und wie sie zusammenhängen.
- Ontologie: formale Definitionen, Geschäftsregeln, die Einschränkungen, die erklären, warum Dinge so funktionieren, wie sie funktionieren.
- Glossar: Vereinbarte Terminologie, die Mehrdeutigkeiten zwischen Teams und Systemen beseitigt.
Denken Sie an das Eingangsbeispiel zurück: Topologie ist die Beziehung zwischen Kunde, Bestellung und Artikel. Ontologie ist die Regel, dass article_code unterschiedliche Dinge mit Abteilung meint, die Einschränkung, die niemand aufgeschrieben hatte. Das ist es, was das Modell kaputt gemacht hat.
Hier ist eine Version dieses Problems, die ich schon mehr als einmal gesehen habe. Ein internationales Unternehmen führt einen Routinebericht durch: Kundenzahl nach Region. Die EU liefert 12.000. Die USA liefern 4.200. Niemand weiß, warum das Verhältnis falsch aussieht. Die Zahlen stammen aus der gleichen Spalte, customer_id, in einer Tabelle, die eigentlich dieselbe sein sollte.
Ein fünfminütiges Telefonat mit John vom US-Vertrieb klärt die Sache. In der EU ist ein Kunde eine natürliche Person mit einer Rechnungsbeziehung. In den USA ist ein Kunde eine juristische Person - ein Unternehmen, das einen Vertrag unterzeichnet hat. Die Personen innerhalb dieses Unternehmens werden als Kunden bezeichnet. Gleicher Spaltenname, völlig andere Maserung.
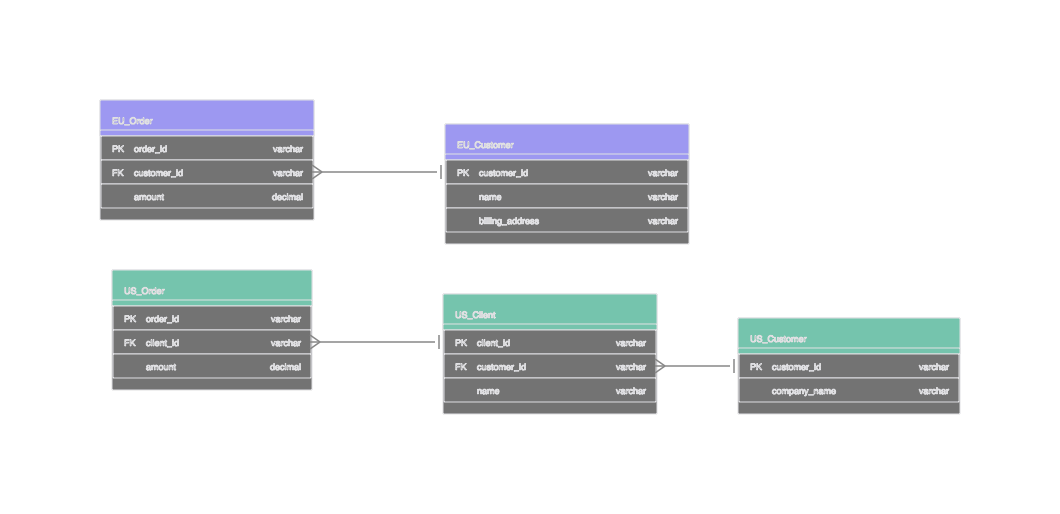
Die Lösung ist weder eine Migration noch ein Refactoring. Es geht um drei Zeilen in einer Tabelle:
John hatte die Antwort die ganze Zeit. Sie aufzuschreiben war die Modellierung.
Diese Begriffe stammen aus der Bibliothekswissenschaft und der Katalogisierung und wurden in den 1970er und 80er Jahren auf die Datenmodellierung übertragen. Auch wenn die meisten Teams heute denken, dass diese konzeptionelle Ebene Zeitverschwendung ist. Sobald diese Ebene existiert, sagt die schriftliche Aufzeichnung Ihres Datensystems endlich, was es bedeutet, und nicht nur, wie es aussieht. Die KI kann mit dem gesamten Bild arbeiten. Das logische Modell folgt von selbst.
Die physische Implementierung (dbt-Modelle, Staging, Marts) wird fast mechanisch. In Grundlagen der Analysetechnikgehen wir in Kapitel 5 diesen gesamten Prozess durch - vom konzeptionellen Entwurf über die logische Modellierung bis hin zur physischen dbt-Implementierung, wobei wir reale Projektmuster als Grundlage verwenden.
Wie es aussieht, wenn es funktioniert
Ein kürzlich durchgeführtes Projekt für ein Reisebüro in den Niederlanden hatte zum Ziel, drei Altsysteme innerhalb eines engen Zeitrahmens auf Databricks zu migrieren. Wir begannen mit der Sondierung, Befragungen von Interessengruppen und dem Aufbau einer gemeinsamen Definitionsschicht, bevor wir die Daten anfassten. Als wir die Metadaten in den alten Datenbanken überprüften, fanden wir mehr als 2.000 SQL-Dateien, die wir überprüfen mussten. In der zur Verfügung stehenden Zeit war es nahezu unmöglich, alle Daten manuell durchzugehen.
Die KI-Richtlinie des Kunden erlaubte es uns, mit Metadaten und SQL-Strukturen zu arbeiten, nicht mit echten Kundendaten. Wir verwendeten Claude Code, um 2.400 SQL-Objekte in ein paar Stunden zu scannen. Er schlug eine erste Taxonomie, Topologie und Definitionen vor. Diese Dokumente bildeten die Grundlage für ein logisches Datenmodell: Entitäten, die nach Geschäftskonzepten benannt wurden, Beziehungen, die sich nach den Regeln richteten, die das Unternehmen tatsächlich befolgte, Einschränkungen, die explizit gemacht wurden, bevor ein einziges dbt-Modell geschrieben wurde.
Dann kam der eigentliche Test. Einer der Hauptbeteiligten begann, das Design in Frage zu stellen, die Zukunftssicherheit in Frage zu stellen und nach Anwendungsfällen zu fragen, die noch nicht entwickelt worden waren. "Wie schaffen Sie Upselling?"
Wir wussten genau, worauf er hinauswollte. Denn das logische Datenmodell existierte bereits, aufbauend auf der konzeptionellen Ebene. Der Stakeholder prüfte ein Modell, das bereits seine Sprache sprach. Seine Fragen waren keine Lücken in unserem Denken. Die meisten von ihnen waren bereits durch das logische Modell abgedeckt, das nur existierte, weil wir zuerst die konzeptionelle Grundlage geschaffen hatten.
Die Lücken, die auftauchten, waren wirklich neue Funktionen, Dinge, die vom aktuellen System völlig abwichen. Designänderungen, nicht fehlendes Wissen. Die konzeptionelle Phase stand unter Druck.
Die treibende Kraft hinter dem ganzen Projekt war die zukünftige Funktionalität des Marketings: Anwendungsfälle, die nur in Gesprächen mit den Beteiligten existierten, nichts aufgeschrieben, alles im Kopf des leitenden Marketingspezialisten, der die Initiative vorantrieb. Ein Bild davon zu bekommen, wie die Dinge jetzt liefen, war der einfache Teil. Der schwierigere Teil - und der Teil, den KI überschaubar machte - bestand darin, das Vorhandene zu scannen und schnell genug eine Grundlage zu schaffen, um echte Gespräche mit den Stakeholdern zu führen, bevor der Zeitplan auslief.
Das Problem hört nicht bei dem Projekt auf
Die obige Methode löst das Kontextproblem auf der Projektebene. Aber die gleiche Lücke besteht auch auf zwei anderen Ebenen, und beide beginnen, Lösungen zu finden.
Auf individueller Ebene beginnt jede KI-Sitzung bei Null. Sechs Monate täglicher Unterhaltungen sind etwa 19,5 Millionen Token verlorener Kontext. MemPalace, ein Open-Source-Projekt, das diese Woche von Milla Jovovich und dem Entwickler Ben Sigman veröffentlicht wurde, geht dieses Problem direkt an. Es speichert jede Konversation lokal in einer navigierbaren Hierarchie: Flügel für Projekte, Räume für Themen, Hallen für Erinnerungstypen. Das Ergebnis ist eine 96,6%ige Wiederauffindbarkeit bei nahezu null Kosten, ohne Abhängigkeit von der Cloud oder Verlust bei der Zusammenfassung.
Auf der organisatorischen Ebene ist das Problem noch größer. Wie Timo Dechau kürzlich beobachtete: Claude-Sitzungen sind persönlich und isoliert. Ihr Kontext ist der Ihre. Es gibt keine Wissensschicht, die sich über Teams, Projekte oder die Zeit erstreckt. Datenkataloge, semantische Schichten und geregelte Glossare schaffen hier Abhilfe, wenn sie als lebendiges Organisationsgedächtnis und nicht als Compliance-Overhead behandelt werden. Die konzeptionellen Artefakte aus der obigen Methodik (Topologie, Taxonomie, Ontologie, Glossar) sind das Rohmaterial. Wenn sie projektübergreifend genutzt werden, setzen sie sich zusammen.
Keiner von beiden löst das Problem allein. MemPalace gibt dem Praktiker ein Gedächtnis. Die Organisationsebene gibt dem Team eines. Beide hängen von der gleichen Grundlage ab: Kontext, der tatsächlich aufgeschrieben wurde.
Die Freischaltung ist keine bessere KI
Ich habe schon Teams gesehen, die dies mit Aufforderungen wie "Geben Sie mir ein Kimball-Sternschema mit diesen Tabellen" versucht haben. Das Modell liefert etwas. Das tut es immer. Aber was es liefert, füllt die Lücken in den Informationen, die ihm gegeben wurden, mit Annahmen auf, und manchmal tauchen diese Annahmen als Halluzinationen auf. Wir geben dem Modell die Schuld. Das Modell hat das getan, wozu es mit unvollständigen Informationen konzipiert wurde.
Kimballs Methodik hat immer mit der konzeptionellen Phase begonnen. Dann die logische. Die physische zuletzt. Diese Reihenfolge besteht, weil jede Ebene von der vorhergehenden abhängt. Wenn Teams die physische Ebene überspringen, werden die Annahmen stillschweigend übernommen. Wenn KI die physische Phase überspringt, treten sie lautstark zutage.
Die Frage ist nicht, ob KI Ihre Daten modellieren kann. Jedes Team, das dies versucht hat, stellt fest, dass sie es kann. Aber erst, nachdem sie die Arbeit geleistet haben, die Kimball beschrieben hat: Beginnen Sie mit den Konzepten, einigen Sie sich darauf, was die Dinge bedeuten, erstellen Sie das Bild, bevor Sie das Modell erstellen.
Der Kontext war immer die Aufgabe. Die KI machte es einfach unmöglich, sie zu ignorieren.
Ich schreibe über Daten und KI in der Praxis in Navigating the Data & AI Landscape. Die Muster in diesem Beitrag tauchen in den Ausgaben w6, w10 und w11 auf. Dieser Beitrag ist der Rahmen, um den ich kreiste. Wenn er Anklang gefunden hat, finden Sie die wöchentlichen Beobachtungen zuerst im Newsletter.
Verfasst von

Ricardo Granados
Unsere Ideen
Weitere Blogs




Contact