Blog
Ducklake: Eine Reise zur Integration von DuckDB mit Unity Catalog

In diesem Sommer kündigte Databricks das Open-Sourcing von Unity Catalog an. Dies bietet die Möglichkeit, leichtgewichtige Tools wie DuckDB mit Unity Catalog zu kombinieren. In diesem Beitrag zeigen wir Ihnen, wie Sie DuckDB mit dem quelloffenen Unity Catalog integrieren können. Wir führen Sie durch unsere praktischen Erfahrungen, teilen den Einrichtungsprozess mit Ihnen und erkunden sowohl die Chancen als auch die Herausforderungen der Kombination dieser beiden Technologien.
Warum DuckDB mit Unity Catalog integrieren?
DuckDB ist eine prozessinterne analytische Datenbank, die für die schnelle Ausführung von Abfragen entwickelt wurde und sich besonders für analytische Arbeitslasten eignet. Sie erfreut sich aufgrund ihrer Einfachheit und Leistung zunehmender Beliebtheit - derzeit wird sie über 1,5 Millionen Mal pro Woche heruntergeladen. Allerdings bietet DuckDB noch keine Unterstützung für Data Governance.
Unity Catalog bietet Ihnen eine zentralisierte Governance, d.h. Sie erhalten großartige Funktionen wie Zugriffskontrollen und Data Lineage, um Ihre Tabellen sicher, auffindbar und nachvollziehbar zu halten. Unity Catalog kann somit die Lücke in DuckDB-Setups schließen, in denen Governance und Sicherheit eher begrenzt sind, indem es eine robuste Ebene für Management und Compliance hinzufügt. Umgekehrt ist DuckDB für Unternehmen, die Unity Catalog als Governance-Lösung einsetzen, möglicherweise noch keine praktikable Option.
Alles in allem ist diese Integration sowohl für DuckDB-Benutzer als auch für Unity Catalog-Benutzer eine Win-Win-Situation.
Da wir die Data Lakehouse-Technologie mit DuckDB kombinieren, nennen wir unsere Lösung DuckLake. In diesem Blog erfahren Sie, wie das Ganze funktioniert
Ducklake
In diesem Abschnitt zeigen wir, wie wir die Integration mit DuckDB und dem Unity-Katalog erstellt haben. Wir gehen auf die aktuellen Einschränkungen ein und diskutieren die Umgehung für das Hinzufügen von Schreibunterstützung. Außerdem zeigen wir unsere lokale Einrichtung mit Docker Compose.
Einschränkungen (und Chancen!)
Es gibt ein paar Einschränkungen, die Sie beachten sollten, aber diese entwickeln sich schnell weiter und Lösungen sind bereits in Sicht.
-
Unity-Katalog-Authentifizierung: Zum Zeitpunkt der ursprünglichen Entwicklung verwendeten wir Unity Catalog 0.1.0. Diese Version enthielt noch keine rollenbasierte Zugriffskontrolle (Role-Based Access Control, RBAC). Seitdem wurde die Unterstützung dafür in Unity Catalog 0.2.0 hinzugefügt, wodurch unser Setup noch leistungsfähiger wurde. In der nächsten Serie werden wir Ihnen zeigen, wie Sie dies einrichten können - bleiben Sie also dran für diesen Beitrag.
-
Nur-Lese-Delta-Unterstützung: Derzeit kann DuckDB aufgrund seiner Abhängigkeit von
delta-kernel-rsnur von Unity Catalog lesen, was die Operationen auf reine Lesevorgänge beschränkt. Das DuckDB-Team arbeitet aktiv an einer Schreibunterstützung, die definitiv auf der Roadmap steht. In der Zwischenzeit haben wir einen Workaround entwickelt, mit dem Sie in den Unity Catalog schreiben können, so dass Sie weiterarbeiten können, bevor die native Unterstützung eintrifft. -
Motherduck-Integration: Motherduck bietet ein verwaltetes DuckDB-Erlebnis, unterstützt aber leider noch nicht die uc_catalog-Erweiterung, aber das hält uns nicht auf! Um eine ähnliche Notebook-Integration zu erhalten, haben wir eine Lösung mit Jupyter Notebooks entwickelt, einem webbasierten Tool für interaktives Computing.
Um den Mangel an Schreibunterstützung in DuckDB zu beheben, haben wir ein Unity-Plugin für die Bibliothek dbt-duckdb entwickelt. Dbt ist ein beliebtes Tool für die Umwandlung von Daten in einem Data Warehouse oder Data Lake. Es ermöglicht Dateningenieuren und -analysten, modulare SQL-Transformationen zu schreiben, mit integrierter Unterstützung für Datentests und Dokumentation. Das macht dbt zu einer natürlichen Wahl für das Ducklake-Setup.
Außerdem haben wir eine Jupyter-Kernel-Bibliothek, dunky, entwickelt, die es ermöglicht, mit SQL direkt in den Unity-Katalog zu schreiben.
Hier ist ein schematischer Überblick über die Integration mit dbt und Jupyter: 
Abhilfe schreiben
Die Umgehung umfasst die folgenden Schritte:
- Konvertieren Sie DuckDB-Abfrageergebnisse in eine speicherinterne Apache Arrow-Tabelle.
- Konvertieren Sie das Arrow-Tabellenschema mit der Bibliothek pyarrow-unity in ein Unity-Katalogschema.
- Das Schreiben der Tabelle beinhaltet:
- Erstellen einer Unity-Katalog-Tabelle.
- Schreiben der In-Memory-Tabelle Arrow in eine Delta-Tabelle.
Hier ist eine schematische Übersicht über diese Schreibumgehung:
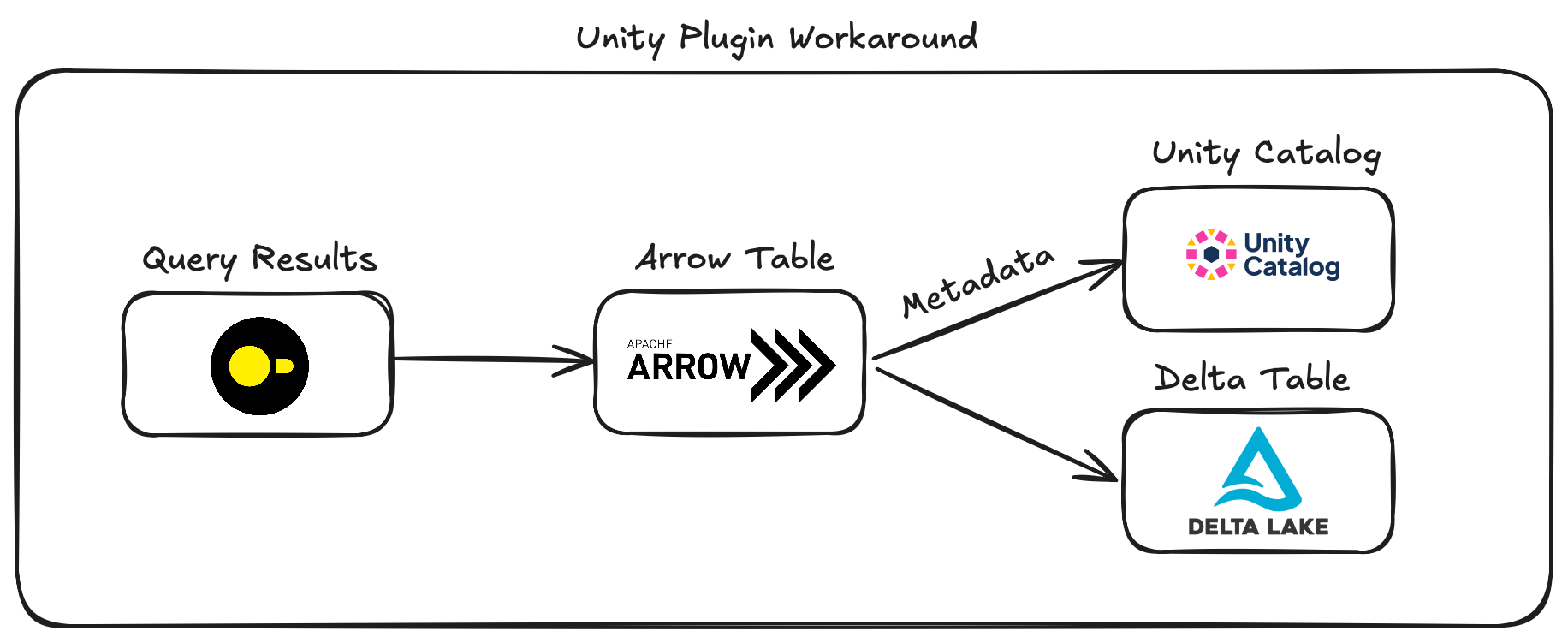
Dieser Workaround ist zwar effektiv, aber niemals so effizient wie eine native DuckDB-Lösung. Die Konvertierung von DuckDB-Abfrageergebnissen in eine Arrow-Tabelle führt zusätzliche Schritte ein. Zum Beispiel muss DuckDB seine interne Datenstruktur wie Vektoren und Chunks auf das Spaltenformat von Arrow abbilden. Das bedeutet, dass jede Spalte in ein Arrow-Array konvertiert wird und jeder Datentyp wie INTEGER und VARCHAR auf Arrow-Datentypen abgebildet wird (z.B. pa.int32() und pa.string()). Glücklicherweise macht die integrierte Unterstützung von DuckDB für Apache Arrow diese Konvertierung effizient und nahtlos.
Docker Compose Einrichtung
Docker ist eine Plattform, die es Entwicklern ermöglicht, Anwendungen und Abhängigkeiten in Container zu verpacken. Wir werden Docker Compose verwenden, um die Dienste (Unity Catalog, Jupyter usw.) lokal zu verwalten und auszuführen. Hier finden Sie einen Überblick über die Einrichtung von Docker Compose:
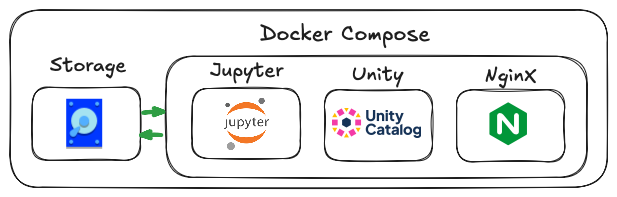
Wir verwenden Docker Compose, um vier Dienste zu hosten:
- Unity-Katalog: Die Version 0.1.0 läuft. Das Docker-Image stammt vom godatadriven dockerhub.
- Unity Katalog UI: Eine Web-Benutzeroberfläche zum Durchsuchen des Katalogs.
- Jupyter: Ermöglicht die Interaktion mit dbt-Modellen und die Abfrage des Unity-Katalogs. Wir verwenden ein minimales Jupyter-Image von quay.io. Während des Builds fügen wir die dbt-duckdb mit dem Unity-Plugin hinzu.
- Nginx: Ein Reverse-Proxy, der es externen Diensten ermöglicht, mit der Unity Catalog API zu kommunizieren. Dadurch kann die Jupyter-Erweiterung für die Unity-Katalog-Seitenleiste, junity, Tabellen abrufen.
Jaffle Shop Demo
Um unsere Einrichtung zu demonstrieren, verwenden wir das Beispiel jaffle_shop. Der Jaffle-Shop ist ein fiktiver E-Commerce-Shop, der häufig für dbt-Demos verwendet wird. Dieses dbt-Beispiel wandelt Rohdaten in die Modelle customer und order um.
Alle in diesem Blog verwendeten Beispielmaterialien finden Sie hier
Konfiguration
In der profiles.yml definieren wir Folgendes:
jaffle_shop:
outputs:
dev:
type: duckdb
catalog: unity
attach:
- path: unity
alias: unity
type: UC_CATALOG
extensions:
- name: delta
- name: uc_catalog
repository: http://nightly-extensions.duckdb.org
secrets:
- type: UC
token: 'not-used'
endpoint: 'http://uc:8080'
aws_region: 'eu-west-1'
plugins:
- module: unity
target: dev
Diese Konfiguration verknüpft DuckDB mit Unity Catalog und richtet die erforderlichen Erweiterungen und Geheimnisse ein. Zusätzlich für Modelldefinitionen:
{{ config(
materialized='external_table',
location="{{ env_var('LOCATION_PREFIX') }}/customers",
plugin = 'unity'
)
}}
Wir geben die Materialisierung external_table und einen Speicherort an (lokal oder in der Cloud, wie AWS S3).
Einrichten der Einrichtung
docker compose up --build -d
Nachdem die Dienste eingerichtet sind und laufen, ist die Jupyter-Oberfläche unter http://localhost:8888/lab?token=ducklake und die Unity Catalog UI unter http://localhost:3000 zugänglich . Wie erwartet, werden die Beispieltabellen in der Unity Catalog UI sichtbar sein.
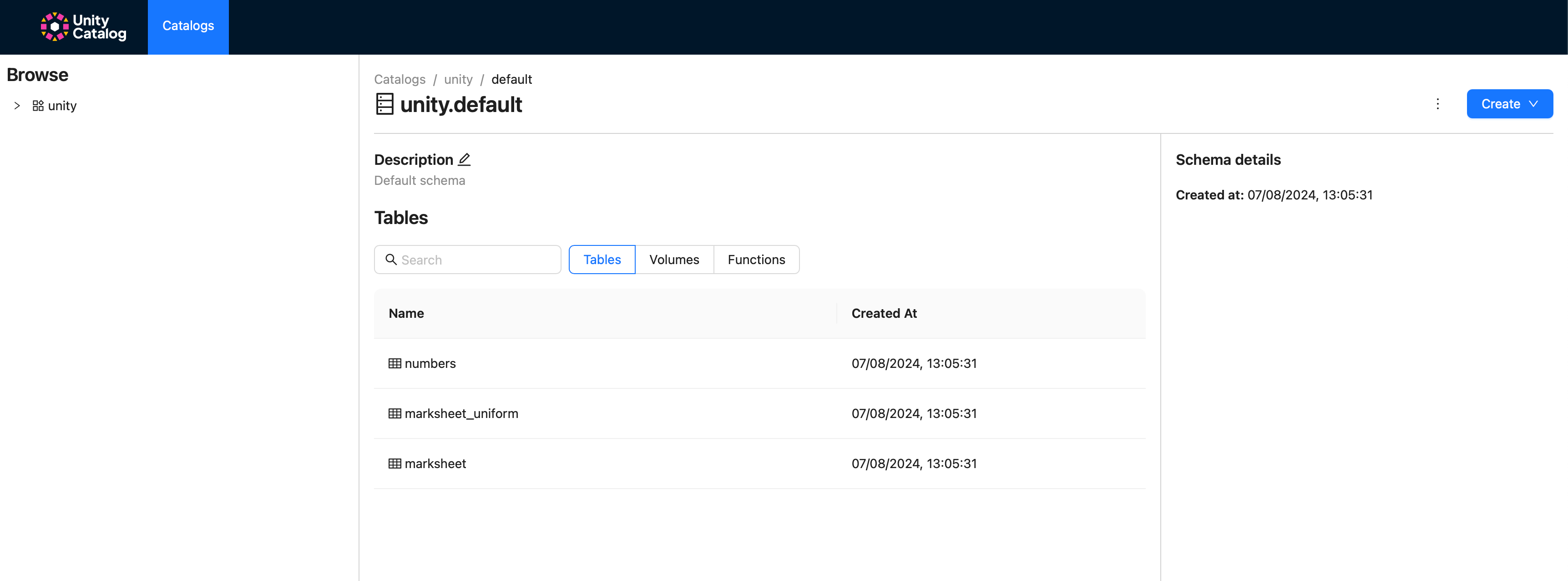
DuckDB gegen Unity-Katalog ausführen
Wenn das Setup läuft, können wir die dbt-Modelle erstellen. 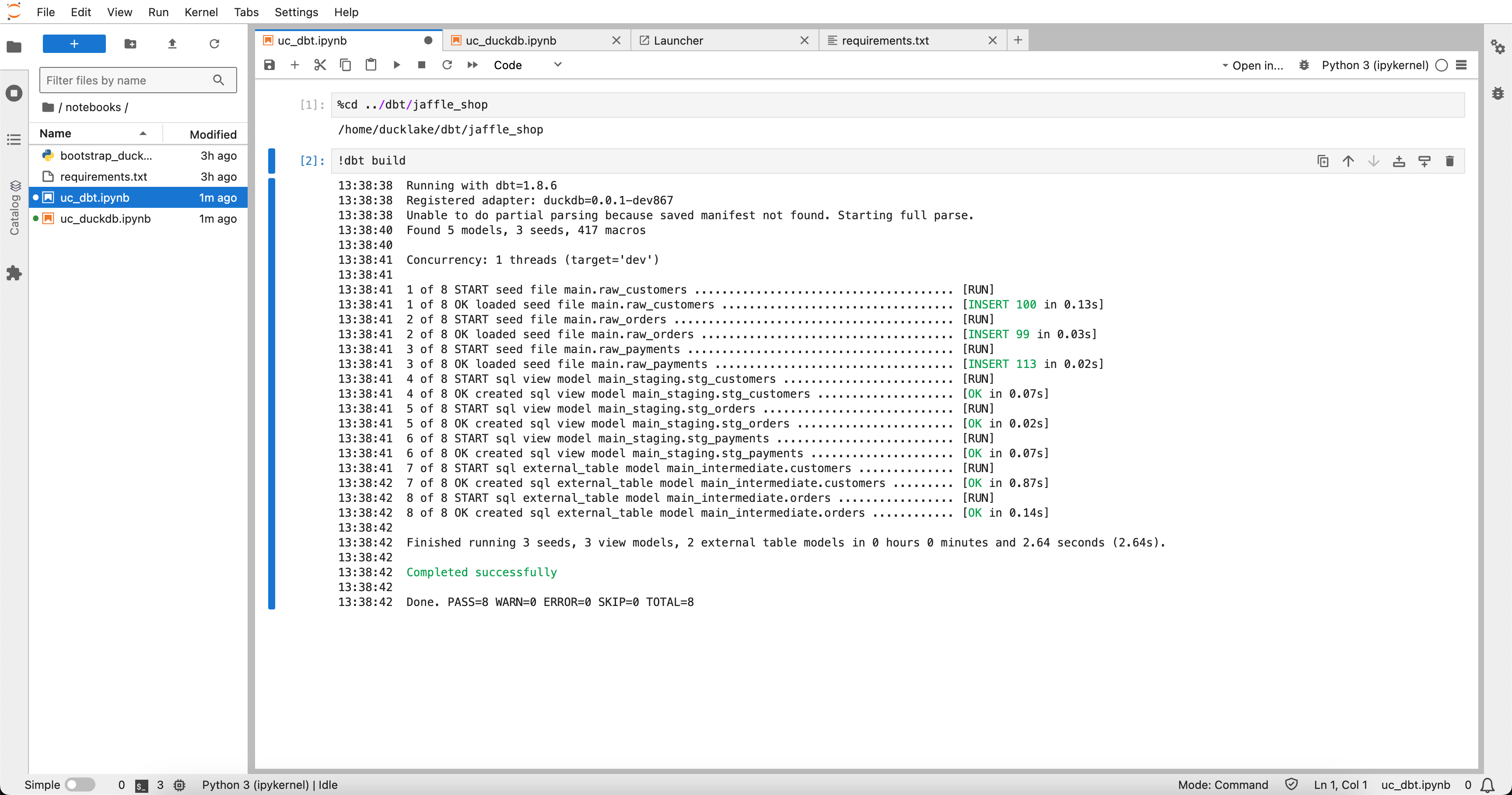 Erfolgreich! Die dbt-Modelle sind erstellt, und wir können die Tabellen nun interaktiv abfragen.
Erfolgreich! Die dbt-Modelle sind erstellt, und wir können die Tabellen nun interaktiv abfragen.
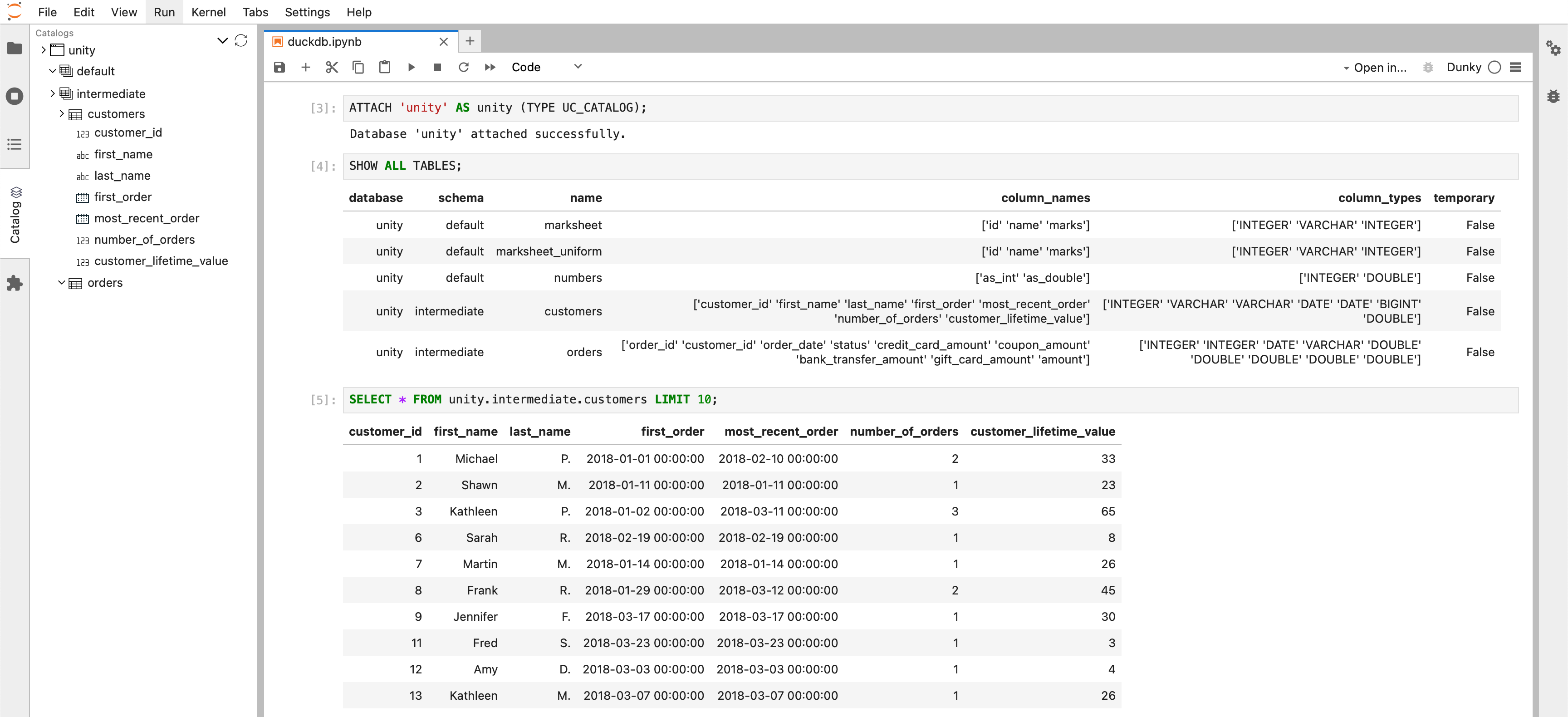
Die Seitenleistenerweiterung des Unity-Katalogs, junity, ermöglicht die einfache Erkundung des Katalogs und das nahtlose Einfügen von Tabellenpfaden in Notizbuchzellen.
Neben der Abfrage ermöglicht der Dunky Jupyter-Kernel auch die interaktive Erstellung neuer Unity-Katalogtabellen und bietet damit eine flexiblere Möglichkeit, Daten innerhalb des Katalogs zu verwalten.
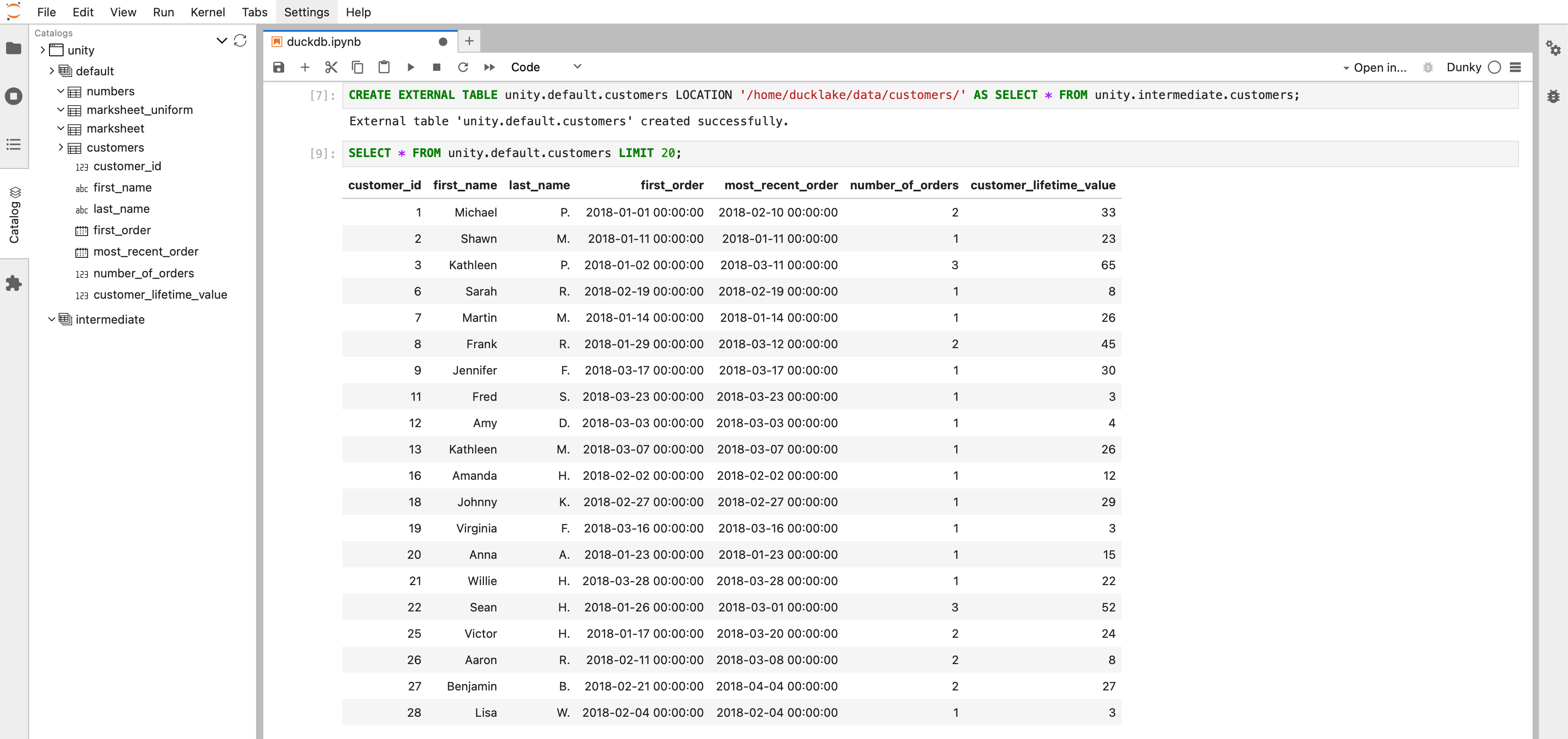
Sie finden die Notizbücher im Verzeichnis der Notizbücher hier
Fazit
In diesem Beitrag haben wir gezeigt, wie DuckDB mit Hilfe von dbt und Jupyter-Notebooks in Unity Catalog integriert werden kann. Obwohl es einige Einschränkungen gibt, konnten wir eine funktionierende lokale Umgebung einrichten, in der DuckDB mit Unity Catalog interagiert. Die Echtzeit-Updates in der Unity Catalog UI bestätigen, dass DuckDB und Unity Catalog vollständig integriert sind.
Was kommt als Nächstes?
☁️ Umzug in die Cloud (AWS)
Nachdem die lokale Einrichtung abgeschlossen ist, können wir uns nun mit den Optionen für die Cloud-Bereitstellung befassen. Im nächsten Beitrag werden wir uns mit der Einrichtung von Ducklake in AWS befassen.
Hinzufügen von RBAC-Unterstützung
Wie bereits erwähnt, ist RBAC noch nicht für Unity Catalog verfügbar, aber es wird bald erwartet. Sobald es veröffentlicht wird, werden wir RBAC in unser Setup integrieren, um eine granulare Rechteverwaltung für verschiedene Benutzer zu ermöglichen.
❄️ Polaris Integration
Wir haben auch begonnen, mit der Integration von Polaris in dieses System zu experimentieren. Wir freuen uns darauf, Ihnen unsere Ergebnisse in einem zukünftigen Beitrag mitzuteilen, bleiben Sie also dran!
Verfasst von
Frank Mbonu
Frank is a Data Engineer at Xebia Data. He has a passion for end-to-end data solutions and his experience encompasses the entire data value chain, from the initial stages of raw data ingestion to the productionization of machine learning models.




Contact