
Ich war neugierig, wie einzigartig mein neuer Leasingwagen in den Niederlanden sein würde und wollte die aktuellen Trends bei Neuwagen untersuchen. Über das RDW-Portal für offene Daten habe ich den Datensatz aller in den Niederlanden zugelassenen Fahrzeuge heruntergeladen. Der Datensatz "Open-Data-RDW-Gekentekende_voertuigen" enthält etwa 16,5 Mio. Zeilen und sage und schreibe 96 Spalten. Die Gesamtgröße des Datensatzes zu diesem Zeitpunkt:
du -h ~/Downloads/Open_Data_RDW__Gekentekende_voertuigen_*
# 10G Open_Data_RDW__Gekentekende_voertuigen_20250117.csv
Die Daten haben eine Kopfzeile, sind kommagetrennt und enthalten viele Spalten. Die letzten 5 Spalten sind URL-Verweise auf verschiedene Datensätze. Diese 5 URLs werden für Millionen von Zeilen wiederholt. Viele Spalten mit geringer Kardinalität werden für alle Zeilen wiederholt, z.B. Autotyp, Marke und 'Taxi-Indikator', um nur einige zu nennen. Ein spaltenförmiges Speicherformat wie Parquet oder das interne Format von DuckDB wäre effizienter, um diesen Datensatz zu speichern.

In diesem Blogbeitrag vergleichen wir die Auswirkungen der Dateiformate auf diesen 10 Gb CSV-Datensatz. Wir werden die folgenden Dateiformate vergleichen:
- Roh-CSV
- Komprimiertes Parkett (Snappy)
- Komprimiertes Parkett (zstd)
- DuckDB internes Format
Roh-CSV
Schauen wir uns an, was passiert, wenn wir mit Spark nach dem ersten und letzten Eintrag des Datensatzes suchen und die Timings überprüfen.
# Select first column value at the top and bottom of the dataset:
head -n2 ~/Downloads/Open_Data_RDW_* | tail -n1 | cut -d, -f1
tail -n1 ~/Downloads/Open_Data_RDW_* | cut -d, -f1
# Output:
# first: MR56LN
# last: MR56LG
Laden Sie den Datensatz in eine Spark-Sitzung und erstellen Sie eine temporäre Ansicht zur Abfrage des Datensatzes.
import os
from pyspark.sql import SparkSession
# Default spark session
spark = SparkSession.builder.appName("CarInspector").getOrCreate()
print(spark.version) # 4.0.0-preview 2
raw_csv_file = os.path.expanduser(
"~/Downloads/Open_Data_RDW__Gekentekende_voertuigen_20250117.csv")
# Load dataset as a queryable table
spark.read.csv(raw_csv_file, header=True)
.createOrReplaceTempView("raw_csv")
first = "MR56LN"
last = "MR56LG"
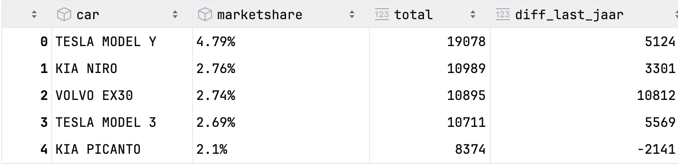
Ich habe eine analytische Abfrage erstellt, um den höchsten Marktanteil für Neuwagen in den Niederlanden zu ermitteln:
-- Step 1: group by brand, type and year, count this group
with cars_brand_per_year as (
select
Merk,
Handelsbenaming,
substring(cast("Datum eerste toelating" as string), 0,4) as jaar,
count(*) total
from raw_csv
where Voertuigsoort = 'Personenauto'
and "Datum eerste toelating" >= 20230101
and "Datum eerste toelating" < 20250101
group by 1, 2, 3
)
-- Step 2: calculate the market share of the top 30 cars
-- Using a sub-query to calculate the total cars this year.
-- Calculate the diff with the previous year, using a window function.
select
jaar, Merk, Handelsbenaming,
round((total /
(select count(*) as year_total from raw_csv
where Voertuigsoort = 'Personenauto'
and substring(cast("Datum eerste toelating" as string), 0, 4) = 2024)
) * 100, 2) || '%' as marketshare,
total,
total - lag(total) over (partition by Merk, Handelsbenaming order by jaar) as diff_last_jaar
from cars_brand_per_year
where jaar = 2024 or jaar = 2024 - 1
order by jaar desc, total desc
limit 30
Die Abfrage einschließlich des Notebooks zum Laden und Ausführen sowohl in Spark als auch in DuckDB finden Sie auf Github als Gist, falls Sie es selbst ausprobieren möchten.
Ein kleines Beispiel für das Ergebnis: Die Spalte car ist eine Verkettung von Marke und Typ, wobei das doppelte Präfix entfernt wurde:
Verwenden Sie den Befehl timeit magic in Jupyter notebook, um die Zeiten der Abfragen zu messen.
%timeit spark.sql(f"select * from raw_csv where Kenteken='{first}' limit 1").collect()
%timeit spark.sql(f"select * from raw_csv where Kenteken='{last}' limit 1").collect()
%timeit spark.sql(spark_analytical_query).collect()
Und vergleichen Sie dies mit dem Timing bei DuckDB. Das ist kein fairer Vergleich, denn Spark hat die CSV bereits bei der Erstellung der temporären Ansicht geprüft. DuckDB wendet den CSV-Sniffer an, um das CSV-Schema und die Datentypen zu prüfen, bevor es die Daten abfragen kann.
import duckdb
print(duckdb.__version__) # 1.1.3
%timeit duckdb.sql(f"select * from '{raw_csv_file}' where Kenteken='{first}' limit 1").fetchall()
%timeit duckdb.sql(f"select * from '{raw_csv_file}' where Kenteken='{last}' limit 1").fetchall()
%timeit duckdb.sql(duckdb_analytical_query).fetchall()
Die ursprüngliche Abfrage, die ich erstellt habe, konnte nicht in beiden Engines verwendet werden, da der SQL-Dialekt von Spark und DuckDB nicht der gleiche ist. Einige Unterschiede, die ich festgestellt habe:
- Spaltenreferenzen mit Leerzeichen sind unterschiedlich, SparkSQL verwendet ` (Backticks) und DuckDB verwendet " (doppelte Anführungszeichen).
substrist nur in SparkSQL verfügbar,substringsowohl in DuckDB als auch in SparkSQL.- Der Teilstring-Offset in SparkSQL ist 0-basiert, während DuckDB 1-basiert ist. Das ist ärgerlich.
- Die Aufteilung der Zeichenkette erfolgt in DuckDB mit
string_split(str, regex)und in SparkSQL mitsplit(str, regex). Die Funktionsplit_part(str, delimit, index)ist in beiden Engines gleich. - Die Auswahl des letzten Elements eines Arrays ist unterschiedlich, SparkSQL verwendet
element_at(array, -1)und DuckDB verwendetarray[-1]. - Spark führt häufiger ein Auto-Casting von Datentypen durch, während DuckDB bei den Typen strenger ist und ein explizites Casting erfordert. Siehe
substring(<bitint>, ...Beispiel oben.
Dies ist das Ergebnis der Zeitmessung:
| Motor | Dateiformat | Zeitmessung erste Zeile | Zeitmessung letzte Zeile | Zeitangaben analytische Abfrage |
|---|---|---|---|---|
| Spark | CSV | 31 ms | 9 s | 18 s |
| DuckDB | CSV | 7.5 s | 7.4 s | 8.7 s |
Spark ist bei der ersten Zeilensuche sehr viel schneller, aber DuckDB ist bei der letzten Zeilensuche und bei der analytischen Abfrage sehr viel schneller.
Komprimiertes Parkett (Snappy)
Die Erstellung einer Parquet-Datei aus der CSV-Rohdatei ist mit DuckDB ganz einfach. Der Standard-Komprimierungsalgorithmus ist ähnlich wie bei Spark "snappy".
duckdb.sql(f"""
COPY (FROM '{raw_csv_file}')
TO 'raw_snappy.parquet'
(FORMAT 'parquet')
""")
Die Dateigröße der Parkettdatei beträgt jetzt 1,2G und lassen Sie uns die Zeiten für die Abfragen vergleichen.
| Motor | Dateiformat | Zeitmessung erste Zeile | Zeitmessung letzte Zeile | Zeitangaben analytische Abfrage |
|---|---|---|---|---|
| Funke | Parkett (zügig) | 140 ms | 700 ms | 1.4 s |
| DuckDB | Parquet (zügig) | 110 ms | 140 ms | 190 ms |
Spark ist langsamer bei der Suche nach der letzten Zeile und deutlich langsamer bei der analytischen Abfrage aufgrund der teuren Shuffles. Dies ist aufgrund der verteilten Natur von Spark erforderlich. Der Abfrageplan für die analytische Abfrage in Spark lautet:
== Physical Plan ==
AdaptiveSparkPlan (13)
+- TakeOrderedAndProject (12)
+- Project (11)
+- Window (10)
+- Sort (9)
+- Exchange (8) <-- Shuffle 1x
+- Project (7)
+- HashAggregate (6)
+- Exchange (5) <-- Shuffle 2x
+- HashAggregate (4)
+- Project (3)
+- Filter (2)
+- Scan parquet (1)
Komprimiertes Parkett (zstd)
Lassen Sie uns eine Parkettdatei mit dem zstd-Komprimierungsalgorithmus erstellen. Der
duckdb.sql(f"""
COPY (FROM '{raw_csv_file}')
TO 'raw_zstd.parquet'
(FORMAT 'parquet', compression 'zstd')
""")
Das Ergebnis ist:
du -h *.parquet
# 1.2G raw_snappy.parquet
# 726M raw_zstd.parquet
Ich bin erstaunt, dass die Größe im Vergleich zur Snappy-Variante so viel kleiner ist (39%). Diese Größenreduzierung kann sich positiv auf das Laden und Schreiben von Daten auf die Festplatte auswirken. Und ist eine Kostenersparnis für die Cloud-Speicherung. Lassen Sie uns die Zeiten für die Abfragen vergleichen.
| Motor | Dateiformat | Zeitmessung erste Zeile | Zeitmessung letzte Zeile | Zeitangaben analytische Abfrage |
|---|---|---|---|---|
| Spark | Parkett (zstd) | 66 ms | 900 ms | 1.3 s |
| DuckDB | Parquet (zstd) | 130 ms | 150 ms | 230 ms |
Die Spark-Abfrage zum Nachschlagen der ersten Zeile ist schneller. Die analytische Abfrage ist in Spark gleich, aber DuckDB ist in diesem Beispiel im Vergleich zu Snappy Compression ein wenig langsamer.
DuckDB internes Format
Für den letzten Vergleich verwenden wir das interne Format von DuckDB. Dies ist ein binäres Format, das für die Abfrageleistung optimiert ist. Ein Vorteil des internen DuckDB-Formats ist die Möglichkeit, die Daten zu aktualisieren und zu löschen.
# 1: Create a persistent DuckDB database
db = duckdb.connect("duckdb_rdw_cars.db")
# 2: Create an internal table from the CSV file
db.sql(f"""
create table cars as
select *
from read_csv('{raw_csv_file}', header = true)Ã
""")
Das interne Format von DuckDB belegt 1,6 GB und ist damit größer als die Parkettdateien. Die Abfrageleistung ist jedoch deutlich schneller:
| Motor | Dateiformat | Zeitmessung erste Zeile | Zeitmessung letzte Zeile | Zeitangaben analytische Abfrage |
|---|---|---|---|---|
| DuckDB | Intern | 23 ms | 22 ms | 75 ms |
Die analytische Abfrage ist in DuckDB im Vergleich zu den Parkettdateien besonders schnell. Schneller als eine Ente quaken kann, ist die Abfrage beendet!
Analytische Abfrage
Das Bild wird von der analytischen Abfrage mithilfe der in PyCharm eingebauten Plot-Funktionen erstellt:
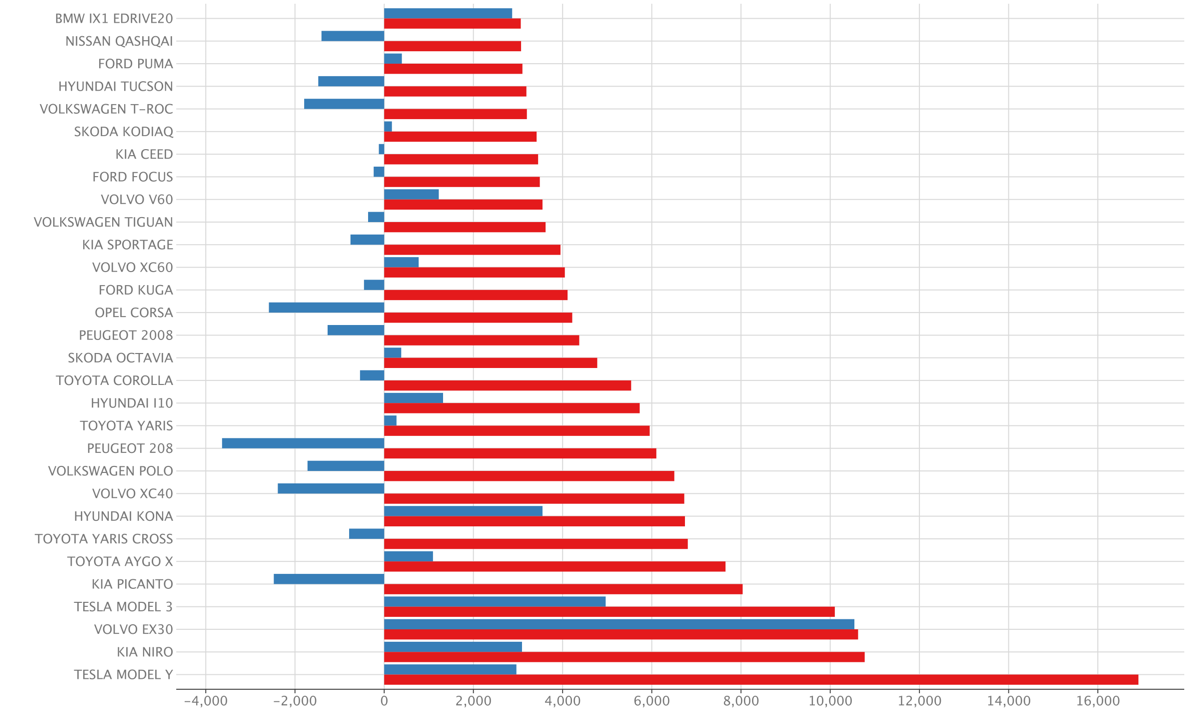 RDW-Datensatz: 22-dez-2024
RDW-Datensatz: 22-dez-2024
red: absolute Zahl der verkauften Autos im Jahr 2024blue: absolute Differenz zum Vorjahr
Die Ergebnisse sind vergleichbar mit autoweek verkoopcijfers, das zum Zeitpunkt der Erstellung leicht veraltet war. Die Datumsauswahl zur Bestimmung der Jahre könnte auch auf einer anderen Spalte basieren.
Fazit
In diesem Blogbeitrag haben wir die Auswirkungen der Dateispeicherung auf einen 10-Gb-Datensatz verglichen. Die Verwendung eines "rohen" Formats wie CSV ist in Bezug auf Speichergröße und Abfrageleistung ineffizient. Nach der Komprimierung der Datei in ein Parkett mit Snappy-Komprimierung schrumpft die Größe der Daten erheblich (x8,7). Der De-facto-Standard für die Komprimierung ist snappy, aber zstd ist eine gute Alternative mit einem noch besseren Kompressionsverhältnis (x14,3). Ziehen Sie die Verwendung von zstd für Ihre Parkettdateien (und Delta-Lake-Dateien) in Betracht, um die Dateigröße und damit die Kosten für den Cloud-Speicher zu reduzieren und die Ladezeiten der Daten zu erhöhen.
# Change default compression codec from snappy to zstd:
spark.conf.set("spark.sql.parquet.compression.codec", "zstd")
DuckDB ist eine gute Alternative für Spark, wenn Sie mit analytischen Abfragen auf angemessenen Datenmengen arbeiten. Die beste Leistung wird mit dem internen Format von DuckDB erzielt.
Falls Sie sich über meinen neuen Leasingwagen wundern. Es ist auf Platz 137, der Mazda 3 mit einem Marktanteil von 0,148% im Jahr 2024. Das ist ein relativ einzigartiges Auto.
Sie können die Notizbuch-Liste auf Github einsehen.
Verfasst von

Alexander Bij
Unsere Ideen
Weitere Blogs



Contact