
In diesem Blogbeitrag möchten wir Ihnen die Erfahrungen und Ergebnisse vorstellen, die wir bei der Spark-Optimierung mit einem unserer Kunden erzielt haben.
Es wurde festgestellt, dass viele ressourcenintensive Spark-Workflows die zugewiesenen Ressourcen nicht effizient nutzen und optimiert werden können, um Kosten zu sparen. Zu diesem Zweck wurde eine Gruppe von Spark-Spezialisten gebildet.
Um diese Herausforderung zu meistern, haben wir uns auf eine Strategie geeinigt:
- Klassifizieren Sie
- die N ressourcenintensivsten Spark-Workflows zu identifizieren
- die kollektiven Auswirkungen dieser Arbeitsabläufe auf den Ressourcenpool zu analysieren
- Optimieren Sie
- die Leistung der wichtigsten N ressourcenintensiven Arbeitsabläufe zu überprüfen und zu verbessern
- Aktie
- Nutzungsmuster beschreiben, die zu einem ineffizienten Ressourcenverbrauch führen
- eine Reihe von Blogbeiträgen schreiben, um die Ergebnisse zu teilen
- Trainer
- Optimierungshinweise in bestehendes Spark-Training einbetten
- Workshop zur Spark-Optimierung veranstalten
Klassifizieren Sie
Die erste Herausforderung bestand darin, zu verstehen, wie man die Optimierung von über 3000 Arbeitsabläufen angehen sollte. Es war offensichtlich, dass es unmöglich ist, mit den gegebenen Zeit- und Personalressourcen alles zu optimieren.
Ausführungskosten Service
Mit demselben Team haben wir kürzlich einen Dienst für die Kostenschätzung von Workflows entwickelt, die auf den On-Premise-Clustern laufen. Die Kostenmetriken sind - Gesamt- und Durchschnittsressourcenverbrauch (CPU und Speicher) durch einen Workflow und jeden seiner Schritte während eines repräsentativen Zeitraums - Tag, Woche, Monat.
Ein Blick auf die kumulative Verteilung (CDF) des Speicherverbrauchs durch Workflows gab uns einen deutlichen Hinweis darauf, dass wir die Anzahl der Workflows in unserer Fokusgruppe reduzieren können.
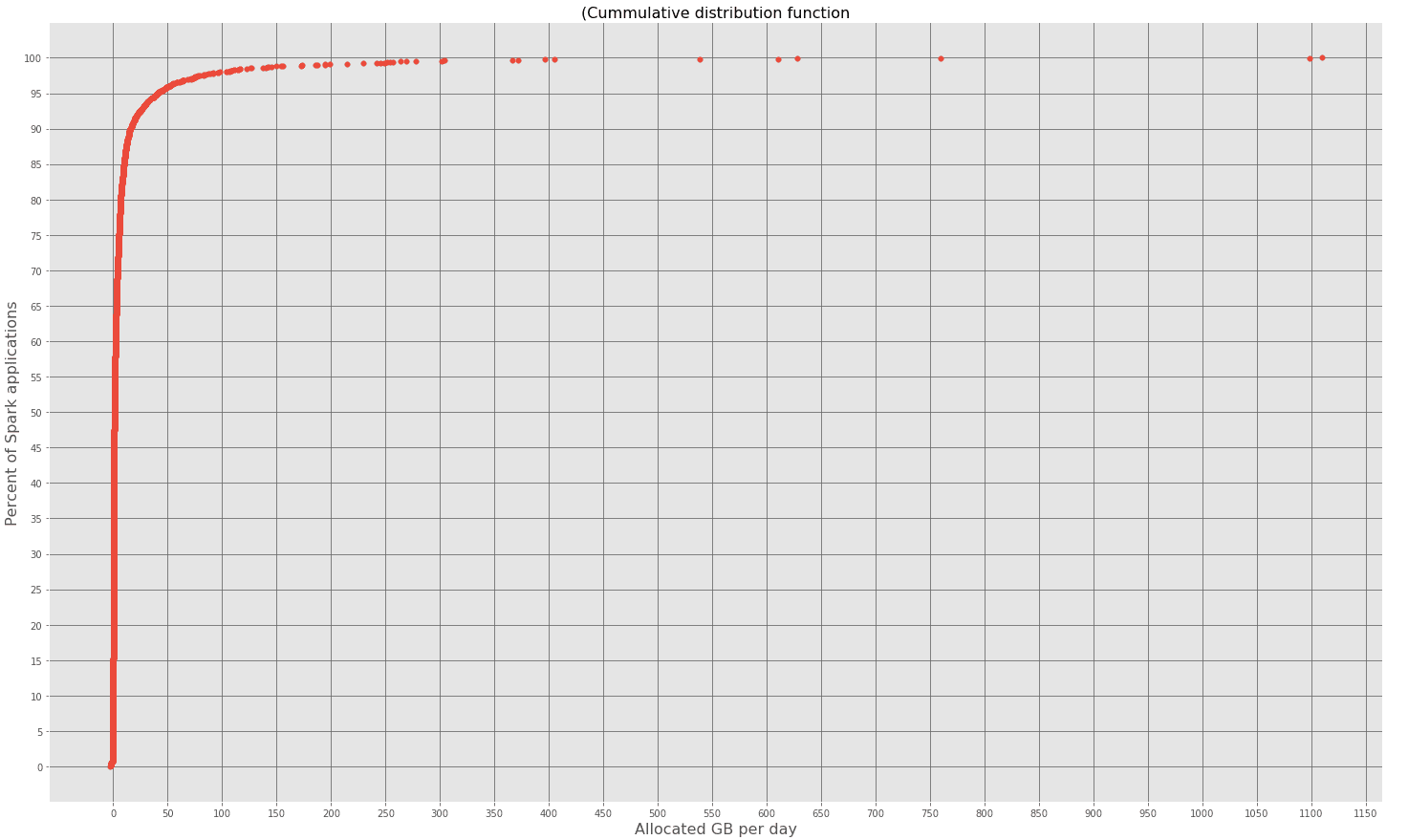
95 Prozent der Spark-Workflows weisen nicht mehr als 35 GB pro Tag zu. Wenn wir die letzten 5 Prozent betrachten, können wir erhebliche Abweichungen feststellen (50 - 1100 GB/Tag). Diese Ausreißergruppe werden wir weiter analysieren.
Identifizieren Sie die ressourcenintensivsten Arbeitsabläufe
Nach einigen Untersuchungen wurde beschlossen, Ad-hoc-Analysen auf dem Cost Service aufzubauen, die den Ressourcenverbrauch pro Workflow überwachen und normalisieren. Wir lassen die Analyse jede zweite Woche laufen, um die Dynamik des Ressourcenverbrauchs zu überwachen. Es war wichtig, Workflows zu eliminieren, die Backfill-Aufgaben ausführten, und sie aus der Zielgruppe zu entfernen.
Gruppierung von Spark-Workflows nach CPU-Verbrauch in Bereichseimern
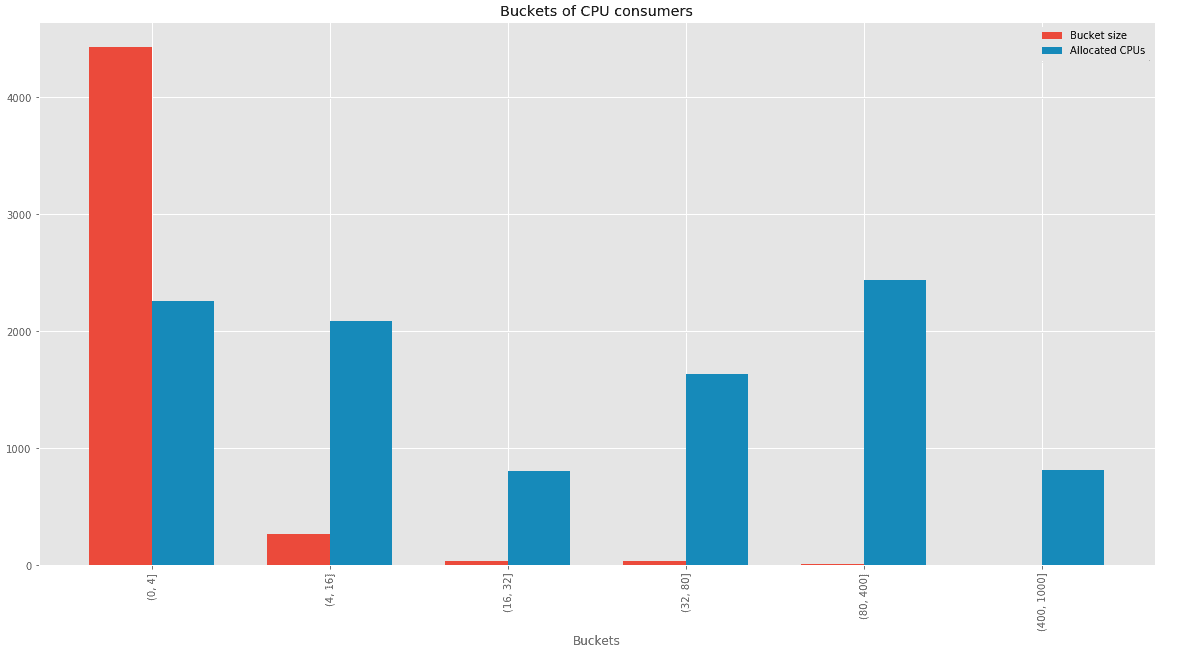
Erklärung des Diagramms: zum Beispiel das erste Balkenpaar (0:4] - Spark-Workflows, die zwischen 0 und 4 CPUs pro Tag verbrauchen. Blauer Balken - Gesamtmenge der CPUs, die pro Tag von den Workflows im Bucket zugewiesen werden. Roter Balken - Anzahl der Spark-Workflows im Bucket.
Aus diesem Diagramm wissen wir, dass 3 Buckets (32, 80], (80, 400], (400, 100] insgesamt 49 Spark-Workflows sind, die etwa 50% der CPUs der insgesamt von Spark-Workflows zugewiesenen CPUs zuweisen.
Datengesteuerte Entscheidung
Auf der Grundlage der bereitgestellten Analyse haben wir die Schätzung des theoretischen Gewinns erstellt. Die oben erwähnten 49 Spark-Workflows machen etwa 1 % der gesamten Spark-Workflows aus. Insgesamt erzeugen Spark-Workflows 30% der Cluster-Last. Wenn wir dieses 1 % der Workflows so optimieren, dass sie 50 % weniger CPU verbrauchen, führt dies zu einer Verringerung der Clusterlast um 15 %. Die Annahme, dass wir eine 50%ige CPU-Reduzierung erreichen können, ist ziemlich optimistisch. Aber wenn wir mindestens 25% erreichen, was uns machbar erschien, wäre das schon ein großer Erfolg - eine Reduzierung von 7% der Clusterlast. Diese Schätzung war gut genug, um die Optimierungsphase zu beginnen.
Optimieren Sie
Beschreibung der Umgebung
Es gibt zwei Cluster, die am stärksten von Spark-Workflows belastet wurden, weshalb sie für das Optimierungsschlachtfeld ausgewählt wurden.
Design der Cluster:
- YARN-Ressourcenmanager
- HDFS v2 primärer Datenspeicher
- Hive und Spark Verarbeitungsmaschinen
- Spark und Hadoop zentralisierte History Server
- Oozie und Airflow Workflow-Scheduler
Technische Ergebnisse: optimierte Arbeitsabläufe
Nachdem wir die Arbeitsabläufe definiert hatten, die als erstes in Angriff genommen werden sollten, begannen wir damit, sie einen nach dem anderen zu untersuchen.
Was die Arbeitsweise betrifft, haben wir den folgenden Ansatz verfolgt:
- bestimmte Arbeitsabläufe zu untersuchen
- notwendige Optimierungen vorschlagen
- den Eigentümer des Workflows kontaktieren, um die notwendigen Änderungen zu besprechen und umzusetzen
Wie erwartet standen Spark-Workflows, die eine große Menge an Daten verarbeiten, ganz oben auf der Liste. Im Durchschnitt sind dies Spark-Workflows, die Datensätze zwischen 5 und 27 TB verarbeiten. Sie können sich vorstellen, dass bei diesen Datenmengen selbst kleine Optimierungen eine große Wirkung haben können. Nachdem wir einige Workflows untersucht hatten, entdeckten wir gemeinsame Muster, die sich für eine Optimierung eignen.
Änderungen der Konfiguration
Zu Beginn der Initiative bestand unsere Absicht darin, so wenig Code wie möglich anzurühren und Spark-Workflows zu optimieren, indem wir in erster Linie die Konfiguration optimieren. Die Idee dahinter war, schnell Ergebnisse zu erhalten, möglichst ohne zusätzlichen Aufwand (Testen, Neuverteilung, Datenmigration). Eine der nützlichsten Einstellungen während dieses Prozesses war spark.sql.shuffle.partitions. Der Standardwert von 200 ist bei den Datensätzen, mit denen wir gearbeitet haben, kaum sinnvoll. Er führte zu großen Shuffle-Partitionen, die eine enorme Auslastung des Speichers und der Festplatte verursachten, was die Ausführung des Workflows erheblich verlangsamte. Spark erstellt eine Aufgabe für eine Partition. Wenn die Partition also zu groß ist, passt sie nicht in den Speicher des Executors. Bei einigen Spark-Workflows führte die Erhöhung der Anzahl der Shuffle-Partitionen bereits zu einer Leistungssteigerung von 30%.



Code-Prüfung
Wenn die Änderung der Konfiguration keine weiteren Leistungssteigerungen oder Ressourceneinsparungen brachte, war der nächste logische Schritt, den Code selbst zu überprüfen. Die meisten Workflows wurden mit dem Ziel erstellt, so schnell wie möglich Ergebnisse zu erzielen. Deshalb war die Effizienz der Arbeitsabläufe meist zweitrangig. Die wichtigsten Teile, auf die wir uns konzentrierten, waren: Repartition Statement, Vorhandensein von UDFs, Join Keys, Komplexität der Transformationen. Spark-Workflows enthielten eine Vielzahl von repartition() Anweisungen und häufig auch Debugging-Informationen. Die Repartitionierung kann sehr nützlich sein, um unnötiges Mischen zu vermeiden und die Ergebnisse in einer Weise zu speichern, die für die weitere Verarbeitung geeignet ist. Aber in vielen Fällen wurde die Repartitionierung in der Mitte der Transformation angewendet, was nur eine zusätzliche Mischphase einführte, anstatt sie zu reduzieren. Auch bei der Repartitionierung ohne Angabe einer Partitionsspalte werden die Daten nicht deterministisch verteilt, wodurch während der Ausführung des Workflows zusätzliche Mischvorgänge erforderlich sind. Die Anweisung df.cache().count() ohne eine ihr zugewiesene Variable war recht häufig zu finden. Sie veranlasst Spark dazu, den gesamten Datensatz in den Speicher zu holen. Sie hatte kaum einen anderen Zweck als die Anzeige der Datensatzgröße während der Entwicklung von Workflows. Allein durch das Entfernen dieser Anweisung könnte der Workflow viel effizienter gestaltet werden.
UDF's
Die meisten Workflows enthielten eine Vielzahl von UDFs. Da in diesem Fall Python die Hauptsprache für Spark-Workflows ist, brachte die Verwendung von UDFs für jede kleine und große Aktion eine Menge Overhead und verringerte die Leistung drastisch. Der Grund dafür war, dass der Hauptanwendungsfall für Spark-Workflows mit der Datenwissenschaft zusammenhängt. Deshalb enthalten Workflows eine anspruchsvolle Logik, die besser lesbar ist, wenn sie in eine separate Funktion und/oder ein Paket ausgelagert wird. Die meisten Spark-Workflows enthalten UDFs für jede einfache Transformation wie das Parsen von JSON-Daten, das Explodieren von Arrays oder die Anwendung von Regex-Filtern. Wenn Sie diese UDFs durch Spark-Basisfunktionen wie DSL/SQL-Anweisungen ersetzen, verbessert sich die Leistung der Workflows drastisch.
Datenschieflage
Trotz all dieser Beispiele und Muster waren einige Workflows außergewöhnlich gut geschrieben, aber gut, manchmal hat man ja auch einen lang laufenden Spark-Workflow. Der nächste Schritt war, die Daten zu überprüfen.
Datenschieflage ist im Allgemeinen ein schwieriges Problem und schwer zu erkennen. Vor allem, wenn Sie viele Phasen in Ihrem Spark-Workflow haben und jede Phase im Durchschnitt einige Terabytes an Daten verarbeitet. Wenn die Tasks und/oder die Stages feststecken, die CPU-Auslastung niedrig ist und Sie viele Out of Memory-Fehler haben, könnte dies ein Symptom für die schiefen Daten sein. Der Hauptbeweis dafür, dass die Daten verzerrt sind, ist eine drastisch unterschiedliche Größe der Partitionen. Es gibt eine Reihe von Techniken, die helfen könnten, aber in jedem Fall ist das ein langer Weg der Anpassung. Um die Schieflage von Daten zu beheben, können Sie eine neue Partitionierung, das Senden von Daten, das Salzen von Daten und/oder die Änderung des Verbindungsschlüssels verwenden. Aber im Allgemeinen gibt es keine feste Lösung für Probleme mit Datenschiefständen. Natürlich können Sie viele notwendige Informationen über Spark-Workflows über die Spark-Benutzeroberfläche erhalten, aber um einen besseren Überblick über die Ressourcenzuweisung zu bekommen, haben wir Sparklint ausgiebig genutzt.
Als Beispiel haben wir einen Spark-Workflow genommen, der etwa 6 Stunden lang lief und 500 GB Daten verarbeitete. Nach der Untersuchung des Codes und der Metriken aus der Spark-Benutzeroberfläche und Sparklint waren die wichtigsten Probleme dieses Workflows die Schieflage der Daten und die enorme Größe der Partitionen beim Shuffle. Die Größe der Shuffle-Partitionen konnte relativ einfach durch die Einstellung des Parameters spark.sql.shuffle.partitions gelöst werden. Das Problem der Datenschieflage wurde durch die Suche nach dem richtigen Verknüpfungsschlüssel gelöst, wofür die Kenntnis der verarbeiteten Datenstruktur erforderlich ist. Nach Anwendung der Verbesserungen benötigt die optimierte Version des Spark-Workflows etwa eine Stunde für die Ausführung und der Ressourcenverbrauch wurde um 77% gesenkt.
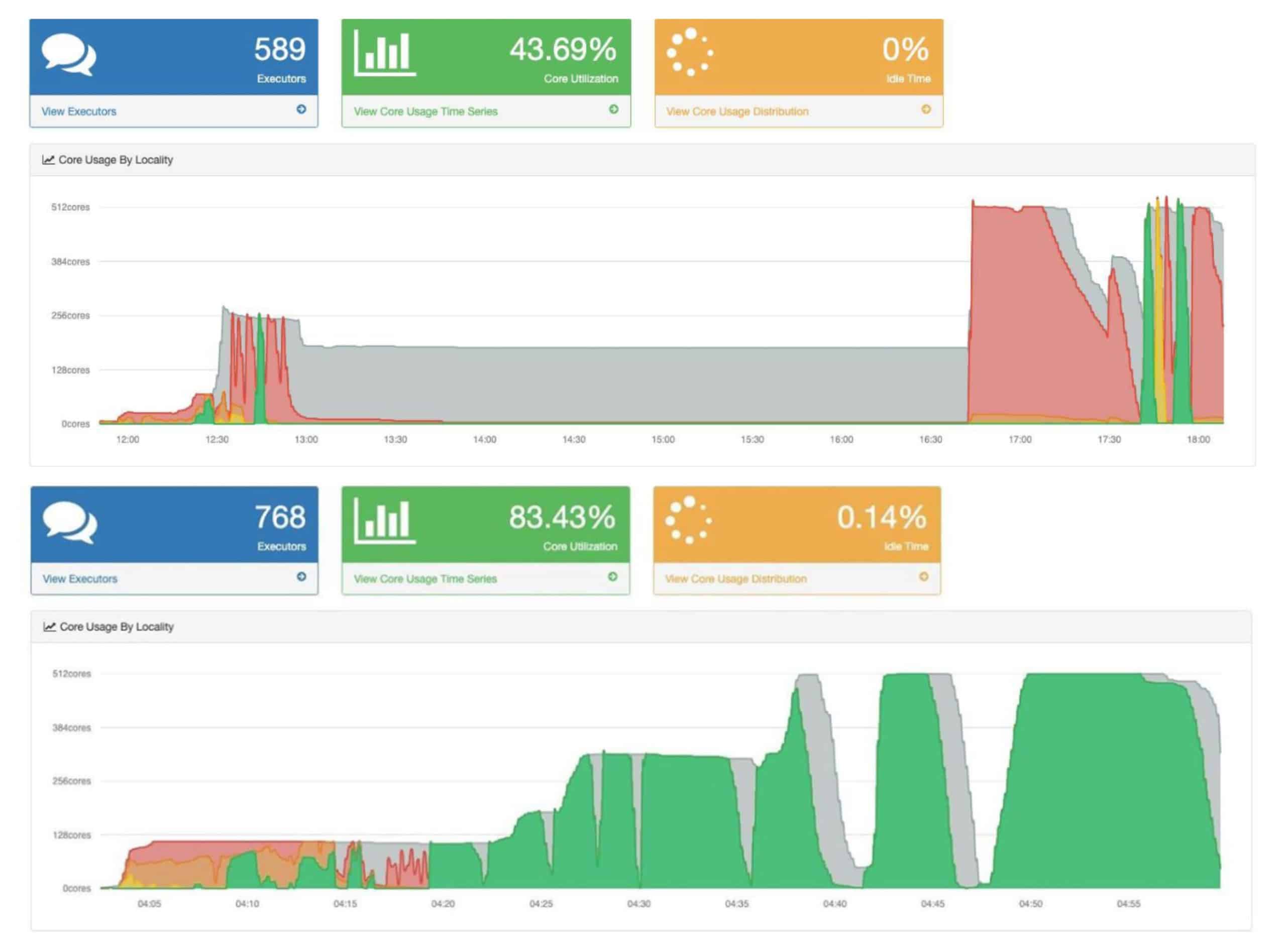
Ein weiteres bemerkenswertes Beispiel für eine Optimierung wurde durch die Änderung der zugrunde liegenden Datenstruktur erreicht. Einer der größten Workflows verwendete ORC als Speicherformat. Nach der Anpassung von Bucketing und Partitionierung konnte die Leistung des Workflows um das 100-fache verbessert werden.
Nicht nur Spark
Manchmal hatte die Optimierung nichts mit Spark selbst zu tun, zumindest nicht direkt. Bei der Optimierung von Spark-Workflows fanden wir einige von ihnen, die "schließlich erfolgreich" waren. Das bedeutet, dass sie nach einer bestimmten (jedes Mal unterschiedlichen) Anzahl von Versuchen erfolgreich abgeschlossen wurden. Als wir uns die fehlgeschlagenen Versuche genauer ansahen, stellte sich heraus, dass die Workflows mit spark.shuffle.FetchFailedException mit der Fehlermeldung too many open files fehlschlugen. Obwohl die Fehlermeldung recht aussagekräftig ist, war es dennoch schwierig, das Problem zu lösen. Das Hauptproblem war, dass das Problem nicht reproduzierbar war. Das heißt, wenn Sie den Spark-Workflow erneut ausführen, kann es sein, dass er erfolgreich und ohne Probleme abgeschlossen wird.
Nach einer Untersuchung wurde festgestellt, dass das Problem nur auf bestimmten Knoten im Cluster auftrat. Jeder Spark-Workflow hat mindestens zwei Wiederholungsversuche, wobei die Verteilung der Knoten zufällig erfolgt. Wenn also genügend Versuche unternommen werden, wird der Workflow am Ende erfolgreich abgeschlossen. Nach dieser Feststellung war es einfach, das Problem zu beheben, indem die maximale Anzahl offener Dateideskriptoren auf bestimmten Knoten auf einen vernünftigen Wert (in unserem Fall 64K) erhöht wurde. Danach wurden die Workflows, die einige Versuche brauchten, um zu enden, bereits nach dem ersten Versuch beendet. Da der Workflow dadurch stabiler wurde, konnten wir die Zeit, in der der Workflow auf einem Cluster Ressourcen beanspruchte, reduzieren.
Teilen & Coachen
Die Kommunikation mit den Spark-Anwendern war während dieses Prozesses aus zwei Gründen sehr wichtig: Da täglich neue Spark-Workflows entwickelt werden, ist es wichtig, Erkenntnisse und Best Practices auszutauschen, um die Codestandards und die Qualität zu verbessern. Andererseits hat die Änderung der Konfiguration bestehender Workflows Auswirkungen auf deren Leistung und Wartung, die mit den Geschäftszielen und damit den Workflow-Eigentümern abgestimmt werden sollten. Obwohl wir uns auf die technische Seite konzentrierten, bestand eines der Ziele der Initiative darin, das gewonnene Wissen den Spark-Benutzern durch Dokumentation, Schulungsmaterial und Workshops zugänglich zu machen.
Errungenschaften
Die Initiative war 4 Monate lang aktiv und führte zu einer Reduzierung der Ressourcennutzung in Bezug auf Speicher und CPU für den Spark-Workflow um insgesamt 7%.
Die Initiative stieß bei den Spark-Benutzern auf große Resonanz. In einigen Fällen reichte es aus, Spark-Benutzern die vorgeschlagene Optimierung zur Verfügung zu stellen, während in anderen Fällen ein tieferes Eintauchen in die Interna von Spark erforderlich war. Um das Wissen zu fördern, haben wir verschiedene Blogbeiträge mit den Ergebnissen veröffentlicht und einen Workshop vorbereitet. All diese Zusammenarbeit führte zu erheblichen Veränderungen in der Kultur und den Ansätzen für die Implementierung von Spark-Workflows.
Es ist immer wichtig, die Ergebnisse der geleisteten Arbeit abzuschätzen. Obwohl diese Initiative klar messbare Ergebnisse in Bezug auf die Reduzierung der zugewiesenen Ressourcen und den kulturellen Wandel hat, zeigte sie auch die Notwendigkeit eines klaren und strukturellen Ansatzes für das Problem der Optimierung. Eines der wichtigsten Ergebnisse war die Einsicht, dass technische Verbesserungen Hand in Hand mit mentalen Veränderungen gehen sollten. Die Klärung und Betonung der Notwendigkeit, optimale Spark-Workflows zu schreiben, war ebenso wichtig wie die Optimierung selbst.




Contact