
In diesem Blogbeitrag untersuchen wir die relativen Kosten der verschiedenen Sprachlaufzeiten auf AWS Lambda. Viele Sprachen können heute mit AWS Lambda verwendet werden, daher konzentrieren wir uns auf vier interessante Sprachen. Wir haben das gesamte Projekt auf GitHub zur Verfügung gestellt, denn ohne den unterstützenden Code für eine potenzielle Peer Review sind alle Benchmarking-Ansprüche, die wir machen, unseriös.
Treffen Sie die Teilnehmer
-
Rust: Laut StackOverflow ist Rust seit 2016 die beliebteste Programmiersprache der Entwickler. Rust bietet auch die beste Kombination aus Leistung und Sicherheit unter den Mainstream-Sprachen, was es natürlich zu einer interessanten Wahl für AWS Lambda macht. Rust wurde erst im November 2023 für AWS Lambda eingeführt, so dass sich wahrscheinlich viele Leute fragen, ob sie es ausprobieren sollen.
-
Scala: Xebia verfügt über einen umfangreichen Hintergrund in der JVM-Entwicklung, einschließlich der Entwicklung von AWS Lambda. Wir zielen für unser Experiment auf die JVM 21 ab und verwenden Scala als Sprachfrontend und Ökosystem, aber man kann durchaus ähnliche Ergebnisse für Java und Kotlin erwarten. Wir sind uns bewusst, dass wir stattdessen ein Tool wie feral verwenden könnten, um eine JavaScript-Laufzeitumgebung anzusteuern, und dass dies sicherlich zu einem anderen Ergebnis führen könnte. Aber wir verzichten darauf, weil wir einen JVM-basierten Kandidaten für eine bessere Abdeckung des Lösungsraums wollen.
-
Python: In den letzten Jahren war Python stets eine der am meisten verwendeten und gefragten Sprachen. Datadog berichtet, dass Python eine der ersten Wahl für die Entwicklung von AWS Lambda ist. Wir verwenden
mypyfür die Sicherheit, die ein statisches Typsystem bietet. -
TypeScript: Für die meisten Softwareentwickler ist Programmieren gleichbedeutend mit Webprogrammierung, und JavaScript ist nach wie vor die am häufigsten verwendete Programmiersprache von allen. Node.js wurde aus dem Wunsch heraus geboren, den gesamten Entwicklungsstapel zu vereinheitlichen, und diese Technologie wird für AWS Lambda gut unterstützt. Wir verwenden TypeScript aus demselben Grund, aus dem wir
mypyverwenden.
Für die Schönste
Natürlich wollen wir jedem der Teilnehmer gegenüber fair sein, also müssen wir zunächst eine geeignete Rubrik formulieren.
-
Der spezifische Wettbewerb sollte sich auf reale Anwendungsfälle beziehen, die Unternehmen und Lösungen zu AWS Lambda führen. Mit anderen Worten, der Wettbewerb muss ernsthaft sein und die daraus resultierenden Benchmarks sollten nützlich und umsetzbar sein.
-
Wo immer möglich, sollten für jeden Teilnehmer die gleichen Implementierungstechniken verwendet werden. Wenn eine Abweichung unvermeidlich ist, muss sie beschrieben und begründet werden.
-
Die Implementierung sollte normalen Code verwenden, gängigen Algorithmen folgen und solide Praktiken einhalten. Keine Implementierung sollte besser (oder schlechter) abschneiden als eine andere, weil sie zu viel (oder zu wenig) clever ist.
-
Verwenden Sie die offiziellen AWS-SDKs und keine Alternativen von Drittanbietern.
-
Die Gesamtkosten für die Reproduktion der Benchmarks sollten gering sein, falls jemand den Wettbewerb für sich selbst wiederholen möchte.
Der Wettbewerb
Der Wettbewerb umfasst drei Dienste, die in einer linearen Pipeline angeordnet sind, und zwei Benchmark-Tests.
Die Dienstleistungen
Hier ist das Systemdiagramm für unseren Wettbewerb:

Ein Benutzer stößt den Prozess an, indem er über seinen Webbrowser den Generatordienst https-a kontaktiert. Der Dienst events-a ruft diese Ereignisse ab, verarbeitet sie und sendet die Ergebnisse an einen anderen On-Demand-Kinesis-Ereignisstrom (B). Der Dienst events-b ruft diese Ereignisse ab und leitet sie ohne weitere Verarbeitung direkt an DynamoDB weiter.
https-a
Dies ist ein Generator von Kinesis-Ereignissen, der als Katalysator für die anderen Dienste dient. Es handelt sich um einen einfachen Webdienst, der akzeptiert:
-
Ein
seedParameter, der zum Primen eines Pseudozufallszahlengenerators verwendet wird. -
Ein
charsParameter, der die Anzahl der alphanumerischen Zeichen angibt, die pseudozufällig generiert werden sollen. Die sich daraus ergebende Nutzlast definiert eine beliebige Arbeitseinheit für die nachgelagerte rechenintensive Verarbeitung. Diese Nutzlast ist ein abstraktes Surrogat für ein wichtiges Datenpaket in einem realen Prozess. Der Parameter ist einstellbar, um verschiedene Eingabegrößen zu berücksichtigen. -
Ein
hashesParameter, der angibt, wie oft jede Nutzlast iterativ gehasht werden soll. Ein kryptographischer Hash wird als abstrakter Ersatz für einige rechenintensive Prozesse verwendet, z.B. LLM-Ausführung, Signalverarbeitung, Simulation von Flüssigkeitsdynamik, Proteinfaltung, Code-Optimierung, Graph-Optimierung usw. Der Parameter ist anpassbar, um unterschiedliche algorithmische Kosten und Komplexitäten zu berücksichtigen. -
Ein
messagesParameter, der angibt, wie viele Kinesis-Ereignisse auf einmal erzeugt werden sollen. Die maximale Injektionsgröße ist500.
JSON ist die Währung unserer Dienste. Der Generator erzeugt JSON-Dokumente, die Folgendes umfassen:
-
Eine UUID, die die Nutzlast kennzeichnet.
-
Die Nutzlast selbst.
-
Die Anzahl der Hash-Vorgänge für die Nutzdaten.
Hier ist ein Beispieldokument, in dem chars=1024 und hashes=100:
{
"uuid": "1115bcd4-95a4-4d1d-8d48-6769ae919cdc",
"doc": "W7ckP4Mc1crUrkdKsxB8VTIwgGpaVnt8qOLhogAYYFU0r4HU1LY5PLWGJyuJWrX2UvZc4goASfnGZgtpWX7CkjsFag7ElQk4dKv8oufwi2OUH23yuxnk7ils51PHPRNOftyijP3FIAeW9m8NOPIweep0ylLt68XpAtAPAyDbNK26F5QJto0ri7fnj9eECN1f8xmbMZBckDz2sXKAuJmDg7ZgKyccLzzI9ZHhNMtOTaqfvXWpkfDYaV2aUvRcfzuMabDCEEoNpqzZE8tPQ1TBRa3Eqm56eYTTutJZuO1Jb94O",
"hashes": 100
}
Beachten Sie, dass das Dokument den Hash noch nicht enthält. Der nächste Dienst in der Pipeline führt die eigentliche Berechnung durch. Der Generator zeichnet lediglich den Umfang der zu erledigenden Arbeit auf. Der Generator sendet seine Nachkommenschaft an einen On-Demand-Kinesis-Ereignisstrom, der unkreativ A genannt wird und von dem der Dienst events-a Gebrauch machen wird. Der Einfachheit und Zweckmäßigkeit halber verzichten wir auf einen Benchmark dieses Dienstes. Daher müssen wir ihn nur einmal implementieren und können eine beliebige Sprache als Laufzeitumgebung wählen. Wir entscheiden uns für Rust.
events-a
Dieser Dienst hasht Elemente, die an den Ereignisstrom A gesendet werden, und sendet die Ergebnisse dann an den Ereignisstrom B. Wir verwenden SHA3-512 als kryptografische Hash-Funktion, unter anderem, weil eine Hardware-Beschleunigung nicht so leicht verfügbar ist wie bei früheren Algorithmen der SHA-Familie. Wir verschlüsseln zunächst die pseudozufällig generierte Nutzlast und verschlüsseln dann iterativ die aufeinanderfolgenden kryptografischen Digests, bis die Zielanzahl erreicht ist. Wenn also in einem Dokument hashes=100 angegeben ist, gibt es einen anfänglichen Payload-Hash, gefolgt von 99 Digest-Hashes. Dieses Diagramm veranschaulicht den Prozess:
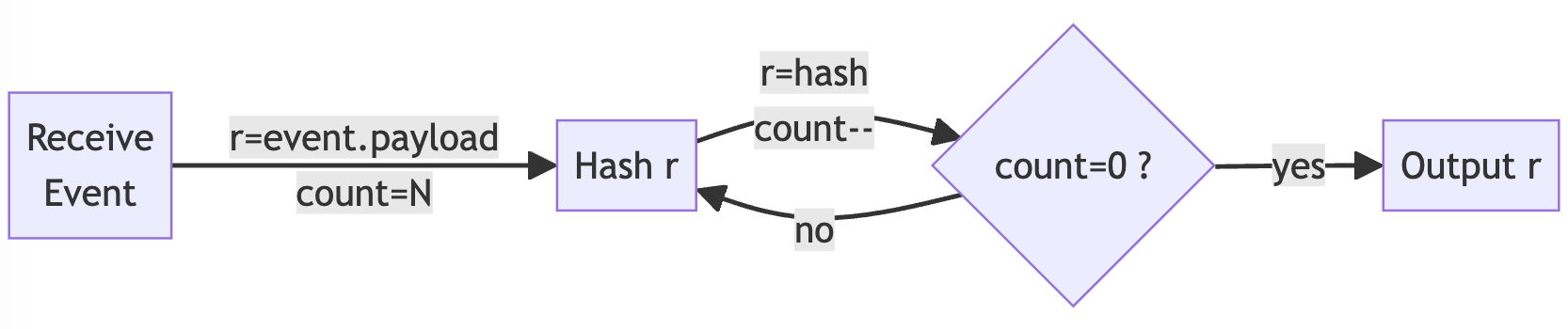
Das Ergebnis ist eine Variante des eingehenden JSON-Dokumentformats, die um eine hash Eigenschaft erweitert wurde:
{
"uuid": "1115bcd4-95a4-4d1d-8d48-6769ae919cdc",
"doc": "W7ckP4Mc1crUrkdKsxB8VTIwgGpaVnt8qOLhogAYYFU0r4HU1LY5PLWGJyuJWrX2UvZc4goASfnGZgtpWX7CkjsFag7ElQk4dKv8oufwi2OUH23yuxnk7ils51PHPRNOftyijP3FIAeW9m8NOPIweep0ylLt68XpAtAPAyDbNK26F5QJto0ri7fnj9eECN1f8xmbMZBckDz2sXKAuJmDg7ZgKyccLzzI9ZHhNMtOTaqfvXWpkfDYaV2aUvRcfzuMabDCEEoNpqzZE8tPQ1TBRa3Eqm56eYTTutJZuO1Jb94O",
"hashes": 100,
"hash": "38BCD7FB1629C1F1596186969928120E6C7A4ACABBEF1A6A26EE3835D0BACCB616FB6F1030FADA1852BD67CB6B557E1C661C71112227CC060114E777F44DECF9"
}
events-b
Dieser Dienst nimmt einfach Elemente entgegen, die an den Event Stream B gesendet werden, und leitet sie wortwörtlich an DynamoDB weiter. Wir bemühen uns, so wenig Arbeit wie möglich zu verrichten, mit maximaler Parallelität und Asynchronität beim Einfügen. Wo immer möglich, rufen wir die API für das Einfügen in die Datenbank asynchron auf, und zwar einmal für jedes ausgehende Element, und dann fassen wir die Futures zusammen und warten auf ihre aggregierte Fertigstellung. Das folgende Diagramm zeigt, wie einfach der Dienst ist:
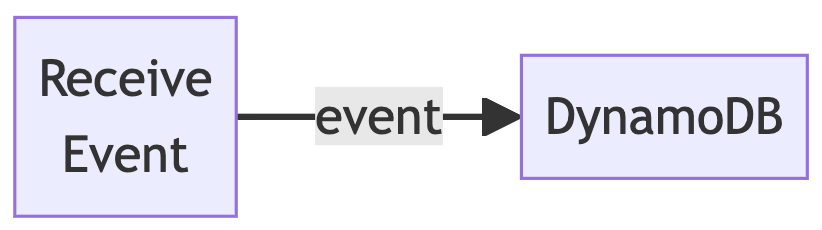
Messung
Nachdem wir nun die Struktur des Wettbewerbs untersucht haben, lassen Sie uns nun zu den Bewertungskriterien kommen. Wir wollen möglichst einen Vergleich von Äpfeln zu Äpfeln, sind aber bereit, zusätzliche Ressourcen bereitzustellen, wenn sie für eine der folgenden Aufgaben erforderlich sind
bestimmten Teilnehmer, um seine Aufgaben zu erfüllen. Zusätzliche Ressourcen verursachen zusätzliche Kosten auf der Plattform. Daher vermerken wir, wenn Abweichungen unvermeidlich sind, und dokumentieren die Auswirkungen solcher Anpassungen auf die Endkosten.
Lassen Sie uns die Basiskennzahlen festlegen:
-
Jedem Lambda stehen 128 MB RAM zur Verfügung. Dadurch bleibt die Ausführung der Dienste kostengünstig. Wir gehen davon aus, dass eine Vergrößerung des verfügbaren Speichers die Rechenleistung verbessert, indem das Paging des Betriebssystems, der Overhead des Deallocators oder die Belastung durch den Garbage Collector usw. reduziert wird. Natürlich ist der erhöhte Speicherbedarf eine zweite Kostenachse auf der Plattform, so dass in jedem realen Einsatzszenario untersucht werden muss, wo der Sweet Spot liegt.
-
Jedem Lambda stehen 15 Minuten zur Ausführung zur Verfügung. Das ist ein gewaltiges Übermaß an Zeit für den zu berücksichtigenden Arbeitsumfang, was perfekt ist, um eine doppelte Zählung der Rechenzeit aufgrund von Ausführungszeitüberschreitungen und Funktionswiederholungen zu vermeiden.
-
Jedes Lambda verwendet dedizierte Kinesis-Streams und DynamoDB-Tabellen, damit die Interaktion der Funktionen in der Middleware-Schicht die Analyse nicht erschwert.
-
Jedes Lambda verarbeitet insgesamt 2.000 eingehende Ereignisse. Wir weisen den Generator an, die Ereignisse in Stapeln von 500 in den Ereignisstrom
Aeinzuspeisen. -
Wir verwenden die Standardeinstellungen, wenn wir keine Konfigurationswerte angeben. Diese Einfachheit macht die Einrichtung des Experiments und die Erstellung der Benchmarks einfacher.
Benchmarks
Wir berechnen zwei verschiedene Benchmarks:
-
Die maximale Ereignis-Chargengröße für
events-aundevents-bist auf1festgelegt. Dieser Fall ist keineswegs repräsentativ für reale Anwendungsfälle, aber er minimiert die Variabilität und den Unbestimmtheitsgrad bei der Messung. So können wir eine Art idealisierte Stückkosten extrapolieren. Wir bezeichnen dies in den folgenden Ergebnissen als Benchmark #1. -
Die maximale Ereignisstapelgröße für
events-aundevents-bist auf64festgelegt. Dieser Fall entspricht eher der Praxis. Die damit verbundenen Abweichungen sind in fast allen realen Anwendungsfällen vorhanden und geben uns einen Einblick in typische Muster. Wir bezeichnen dies in den folgenden Ergebnissen als Benchmark #2. Wir verwenden die folgende Cloudwatch Logs (CWL) Insights-Abfrage, um die Benchmarks selbst zu definieren:
filter @type = "REPORT"
| parse @log /d+:/aws/lambda/(?<function>.*)/
| stats
count(*) as calls,
sum(@duration + coalesce(@initDuration, 0)) as sum_duration,
avg(@duration + coalesce(@initDuration, 0)) as avg_duration,
pct(@duration + coalesce(@initDuration, 0), 0) as p0,
pct(@duration + coalesce(@initDuration, 0), 25) as p25,
pct(@duration + coalesce(@initDuration, 0), 50) as p50,
pct(@duration + coalesce(@initDuration, 0), 75) as p75,
pct(@duration + coalesce(@initDuration, 0), 90) as p90,
pct(@duration + coalesce(@initDuration, 0), 95) as p95,
pct(@duration + coalesce(@initDuration, 0), 100) as p100
group by function, ispresent(@initDuration) as coldstart
| sort by coldstart, function
Lassen Sie uns das aufschlüsseln:
-
Der reguläre Ausdruck wählt die AWS Lambda-Zielfunktion aus. Wir verwenden ihn, um die passenden Implementierungen von
events-aundevents-bauszuwählen. -
Wir gruppieren die Ergebnisse nach Funktion und Kaltstartanzeige.
-
Alle Zeitangaben sind in Millisekunden (ms) angegeben.
-
functionist die Funktion selbst. -
coldstartist1, wenn die Funktion kalt gestartet wurde und0, wenn sie warm gestartet wurde. Bei einem Kaltstart muss AWS Lambda die Funktion intern bereitstellen und eine entsprechend konfigurierte Ausführungsumgebung starten. Kaltstarts können je nach Paketgröße und Sprachlaufzeit viel langsamer sein als Warmstarts. -
callsist die Anzahl der Funktionsaufrufe. -
sum_durationist die gesamte abrechenbare Zeit. -
avg_durationist die durchschnittliche abrechenbare Zeit. -
pxsind Leistungsperzentile. Konkret gibtpxan, dassx% der Stichproben in der Gruppe innerhalb dieser Zeit abgeschlossen haben. So wurden 25 % der Proben in der Zeit vonp25abgeschlossen, 50 % in der Zeit vonp50und so weiter. -
p0ist also die minimale beobachtete Fertigstellungszeit für eine Stichprobe in der Gruppe. -
Und
p100ist somit die maximale beobachtete Fertigstellungszeit für eine Probe in der Gruppe.
Die Endnote für jede Benchmark ist die Summe der Summen der vier Gruppen:
-
events-aWarmstart. -
events-bWarmstart. -
events-aKaltstart. -
events-bKaltstart.
Diese Punktzahl gibt die gesamte abrechenbare Rechenzeit an. Dies ist die Zahl, die jeder Teilnehmer minimieren möchte, da sie sich direkt in reduzierten Kosten auf der AWS Lambda-Plattform niederschlägt.
Die Ergebnisse
Okay, genug vom Prozess! Jetzt kommt der Moment, auf den Sie gewartet haben: Es ist an der Zeit, sich die saftigen Ergebnisse anzusehen. Wir betiteln die Ergebnistabellen mit dem ungefähren Endergebnis.
4. Platz: Scala


Wir konnten Scala nicht dazu bringen, einen der beiden Benchmarks mit nur 128 MB RAM durchzuführen, so dass wir der Funktion 512 MB RAM geben mussten, um überhaupt mithalten zu können. Ein kurzer Abstecher zum AWS Lambda Pricing Calculator und einige grundlegende Dateneingaben zeigen, dass eine Vervierfachung des Speichers die speicherbezogenen Kosten vervierfacht - sie sind linear gekoppelt.
3. Platz: TypeScript


2. Platz: Python


Das offizielle AWS SDK für Python, boto3bietet keinen asynchronen Client an. Die Netzwerkaufrufe an die entfernte API sind natürlich von Natur aus asynchron. Der Kontrollfluss des Clients ist jedoch synchron, d.h. die Funktion wird dadurch benachteiligt, dass sie auf den Abschluss eines API-Aufrufs warten muss, bevor sie den nächsten starten kann. Es gibt ein inoffizielles AWS SDK, das einen asynchronen Client bereitstellt, aioboto3aber wir haben es nicht verwendet, um die oben genannten Regeln einzuhalten. Trotz dieses Handicaps schneidet Python wirklich gut ab und übertrifft die anderen Teilnehmer bisher deutlich.
1. Platz: Rust


Aber Rust ist unser gekrönter König der Leistung. Sein One-at-a-time-Benchmark (#1) übertrifft den One-at-a-time-Benchmark von Python um ~373% und sogar den 64-at-a-time-Benchmark von Python (#2) um ~186%. Und die Verwendung einer Stapelgröße von 64 verbessert die Leistung von Rust um weitere ~232%.
Fazit
Lassen Sie uns die Ergebnisse für Benchmark #1 zusammenfassen:

-
Cold
events-a: Dies ist die Summe aller Cold-Aufrufe vonevents-ain Millisekunden. -
Warm
events-a: Dies ist die Summe aller Warmaufrufe vonevents-ain Millisekunden. -
Cold
events-b: Dies ist die Summe aller Cold-Aufrufe vonevents-bin Millisekunden. -
Warm
events-b: Dies ist die Summe aller Warmaufrufe vonevents-bin Millisekunden. -
Summe der ms für alle Aufrufe: Dies ist die Summe, in Millisekunden, aller Aufrufe der Wettbewerbssprache, unabhängig von Dienst oder Starttemperatur. Sie ergibt sich einfach aus der Summe von
Cold ,Warm ,Cold undWarm . Mit anderen Worten, dies ist die oben ermittelte Endpunktzahl. -
Ausgeführte Lambda-Funktionsaufrufe: Dies ist die Gesamtzahl der Funktionsaufrufe, unabhängig von Dienst oder Starttemperatur. Sie lautet in unseren Benchmarks immer
4,000. -
Durchschnittliche ms pro Aufruf: Dies ist die durchschnittliche Aufrufzeit, in Millisekunden, eines Aufrufs der Wettbewerbssprache, unabhängig von Dienst oder Starttemperatur. Sie wird ermittelt, indem die Summe der ms für alle Aufrufe durch die getätigten Lambda-Funktionsaufrufe geteilt wird.
-
128MB Inkremente: Dies ist die Menge an RAM, die von der Wettbewerbssprache verwendet wird, als Anzahl von 128MB RAM-Schritten. Dieser Wert dient als Kostenmultiplikator. Nur für Scala ist er
512MB / 128MB = 4; für die anderen drei Sprachen ist er einfach1. -
Abgerechnete Einheiten pro Anruf: Dies ist die durchschnittliche Anzahl von Abrechnungseinheiten, berechnet als Durchschnittliche ms pro Anruf mal 128MB-Schritte. Dies ist unsere abstrakte Kostenmetrik, die eine relative Analyse der Wettbewerber ermöglicht.
Wir können die abgerechneten Einheiten pro Anruf in dem folgenden Balkendiagramm darstellen:
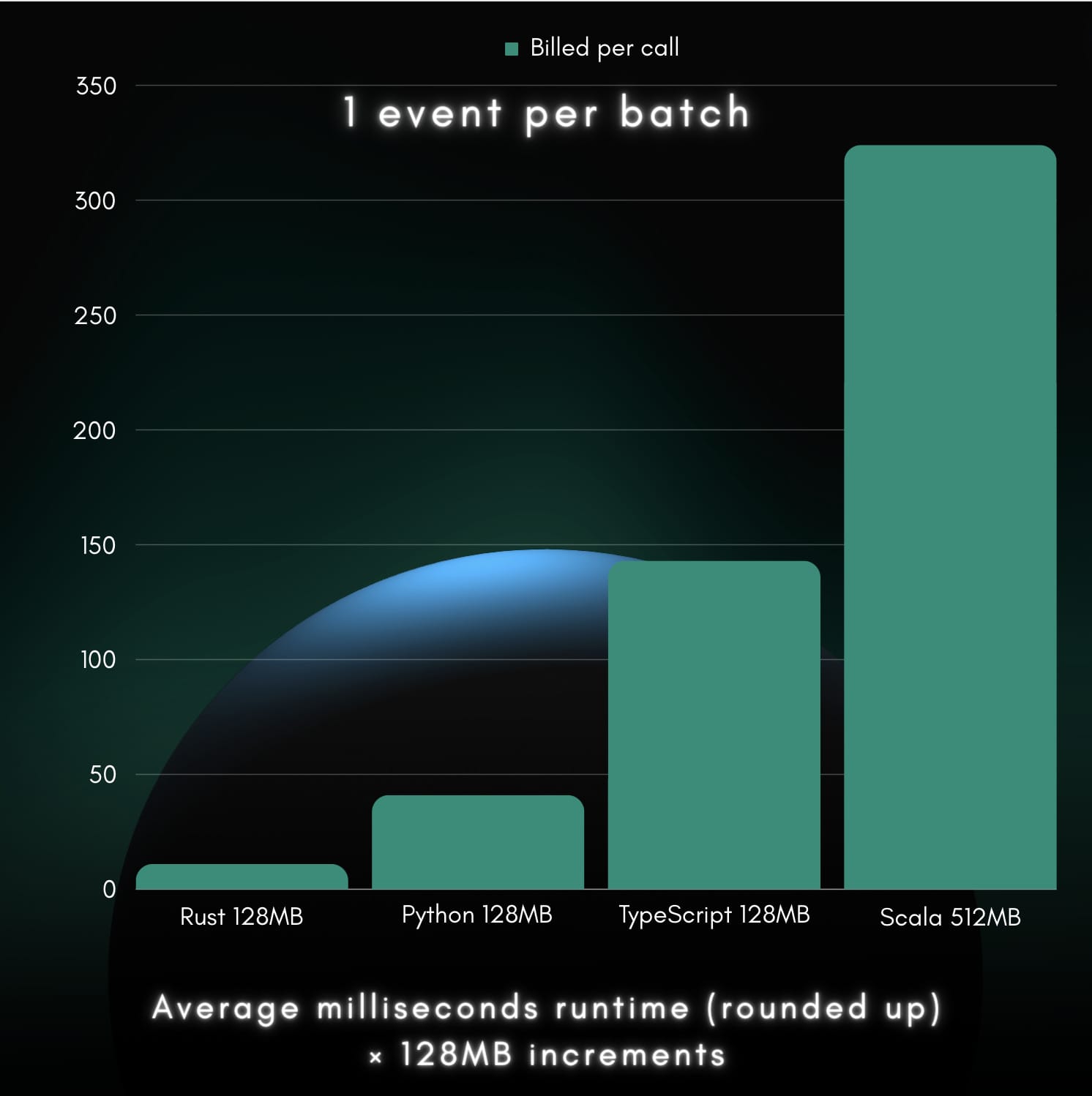
Mit ein paar einfachen mathematischen Berechnungen können wir Kostenquoten als Entscheidungshilfe ermitteln. Da Rust die niedrigsten fakturierten Einheiten pro Anruf lieferte (11), dividieren wir die Werte der vier Wettbewerber durch den Wert von Rust, um unsere Kostenquoten zu erhalten:
-
Rost:
11 / 11 = 1 -
Python:
41 / 11 ≈ 3.73 -
TypeScript:
143 / 11 = 13 -
Scala:
324 / 11 ≈ 29.45
Wenn Sie also 20.000 USD pro Monat für eine Lambda-Funktion ausgeben, die in Scala (oder einer anderen JVM-Zielsprache) geschrieben wurde, können Sie davon ausgehen, dass Sie nach der Portierung auf Rust nur noch 20,000 / 29.45 ≈ 679.12 pro Monat für dasselbe Verhalten zahlen: eine Ersparnis von ~96,6 %. Mit ein wenig Arbeit können Sie diese Ergebnisse mit dem AWS Lambda Pricing Calculator selbst nachweisen:
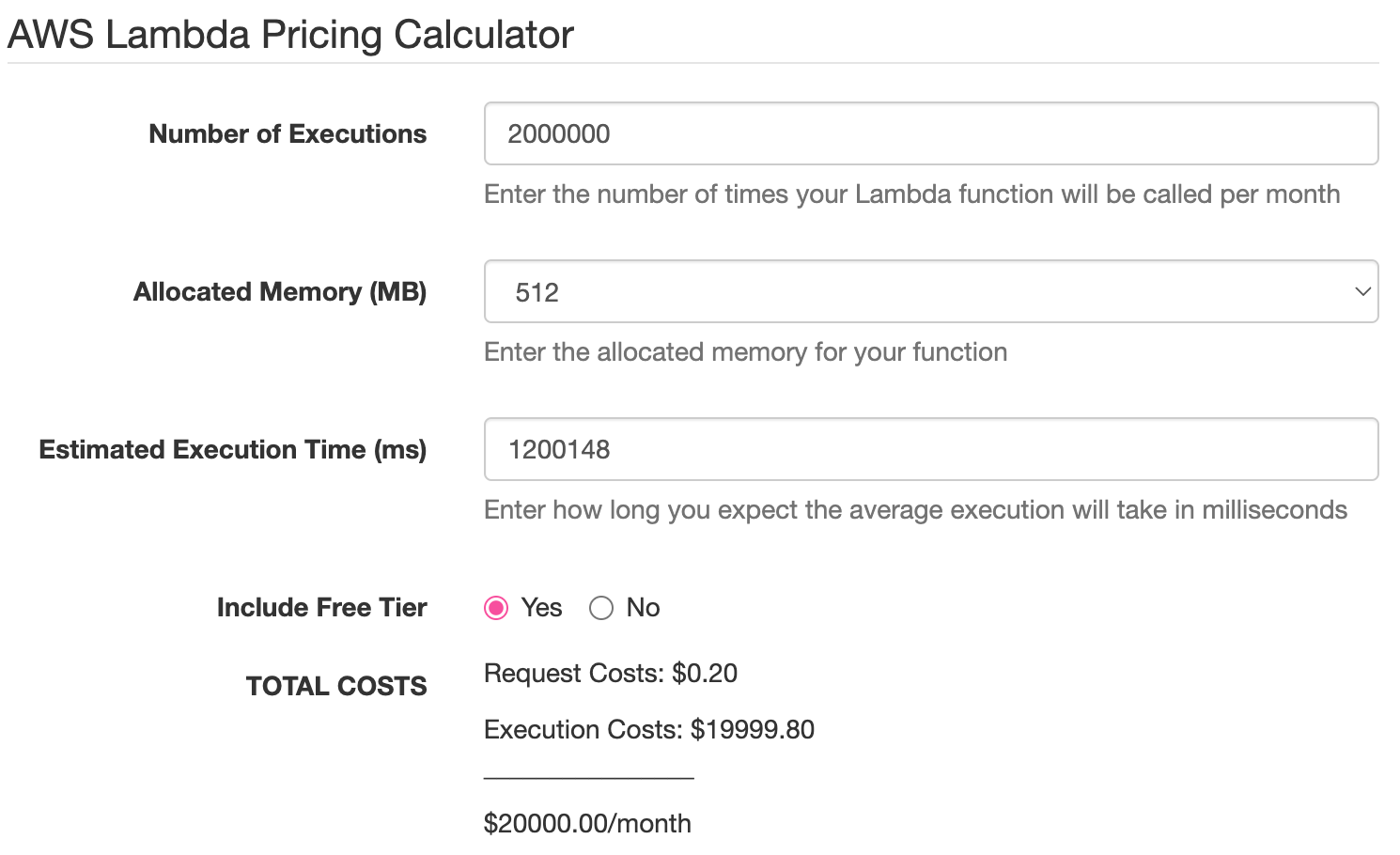
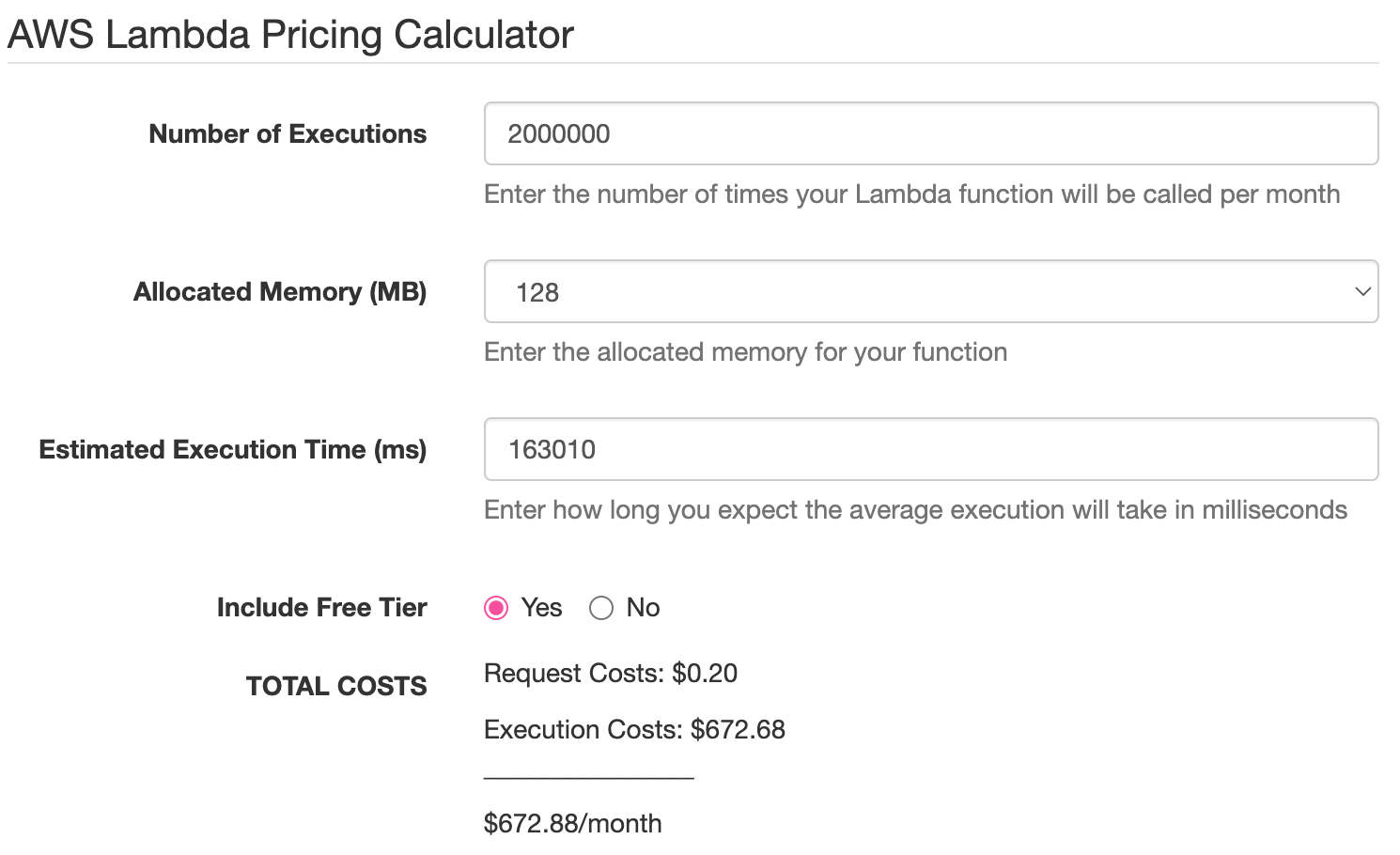
Die Screenshots zeigen einen Unterschied zwischen dem erwarteten und dem offiziellen Wert von nur 679.12 - 672.88 = 6.24: weniger als 1% Fehler.
Abschließende Gedanken
Betrachten Sie diese als Richtlinien und nicht als Evangelium. Ihr eigener Anwendungsfall kann einen oder mehrere Aspekte des hier vorgestellten Kalküls verändern. Vielleicht lebt Ihr Prozess lange genug, damit sich die JVM richtig aufwärmen kann, und der dynamische Übersetzer überholt schließlich die statischen Optimierungen, die von einem nativen Compiler durchgeführt werden. Oder vielleicht haben Sie einen Transpiler, der es Ihnen ermöglicht, Ihre bevorzugte interpretierte Sprache zu schreiben, diese aber mit nativer Geschwindigkeit auszuführen. Oder vielleicht können Sie eine leicht verfügbare, gut getestete Bibliothek nutzen, die nur gute Bindungen für Ihre Sprache hat, und diese Bibliothek macht den Leistungsvorteil einer schnelleren Sprache zunichte.
Aber wenn alle anderen Dinge gleich sind, kann Rust Ihnen helfen, die Leistung zu verbessern, die Betriebskosten zu senken, die Sicherheit zu erhöhen und die Produktivität der Entwickler zu steigern. Lassen Sie sich nicht vom Mangel an Rust-Talenten im eigenen Haus entmutigen: Xebia ist auf Spitzentechnologie spezialisiert, darunter auch Rust, und wir können Ihnen bei einem reibungslosen Übergang helfen. Setzen Sie sich noch heute mit uns in Verbindung, um zu erfahren, wie unser Rust-Team Ihre Projekte auf die nächste Stufe heben kann und dafür sorgt, dass sie schneller, reibungsloser und kostengünstiger in der Cloud ablaufen.
Besonderer Dank
Abschließend möchte ich mich bei meinen Xebianer-Kollegen Paul LaCrosse und Valentin Kasas bedanken, die mir bei der Entwicklung, dem Benchmarking, der Erstellung von Assets, der Korrektur und der Überprüfung der Vernunft geholfen haben. Ich glaube, ich bin immer noch zurechnungsfähig, und das habe ich ihnen zu verdanken.
Verfasst von
Todd Smith
Rust Solution Architect at Xebia Functional. Co-maintainer of the Avail programming language.




Contact