Spark ist das neue Kind auf dem Block, wenn es um Big Data-Verarbeitung geht. Hadoop ist ebenfalls ein Open-Source-Cluster-Computing-Framework, aber im Vergleich zum Beitrag der Community ist Spark viel populärer. Wie kommt das? Was ist so besonders und innovativ an Spark? Liegt es daran, dass Spark die Verarbeitung von Big Data einfach und für den Entwickler viel zugänglicher macht? Oder liegt es daran, dass die Leistung hervorragend ist, insbesondere im Vergleich zu Hadoop?
Dieser Artikel gibt eine Einführung in die Vorteile der aktuellen Systeme und vergleicht diese beiden Big-Data-Systeme eingehend, um die Leistungsfähigkeit von Spark zu erläutern.
 Verteiltes Rechnen[/caption]
Beim parallelen Rechnen haben alle Aufgaben Zugriff auf gemeinsame Daten, um Informationen auszutauschen und ihre Berechnungen durchzuführen. Beim verteilten Rechnen hat jede Aufgabe ihre eigenen Daten. Der Informationsaustausch erfolgt durch die Weitergabe von Daten zwischen den Aufgaben.
Eines der wichtigsten Konzepte des verteilten Rechnens ist die Datenlokalität, die den Netzwerkverkehr reduziert. Aufgrund der Datenlokalität werden die Daten schneller und effizienter verarbeitet. Es gibt kein separates Speichernetzwerk oder Verarbeitungsnetzwerk.
Apache Hadoop bietet ein Ökosystem für verteiltes Rechnen. Einer der größten Vorteile dieses Ansatzes ist, dass er leicht skalierbar ist und man einen Cluster mit handelsüblicher Hardware aufbauen kann. Hadoop ist so konzipiert, dass es mit Ausfällen der Serverhardware umgehen kann.
Verteiltes Rechnen[/caption]
Beim parallelen Rechnen haben alle Aufgaben Zugriff auf gemeinsame Daten, um Informationen auszutauschen und ihre Berechnungen durchzuführen. Beim verteilten Rechnen hat jede Aufgabe ihre eigenen Daten. Der Informationsaustausch erfolgt durch die Weitergabe von Daten zwischen den Aufgaben.
Eines der wichtigsten Konzepte des verteilten Rechnens ist die Datenlokalität, die den Netzwerkverkehr reduziert. Aufgrund der Datenlokalität werden die Daten schneller und effizienter verarbeitet. Es gibt kein separates Speichernetzwerk oder Verarbeitungsnetzwerk.
Apache Hadoop bietet ein Ökosystem für verteiltes Rechnen. Einer der größten Vorteile dieses Ansatzes ist, dass er leicht skalierbar ist und man einen Cluster mit handelsüblicher Hardware aufbauen kann. Hadoop ist so konzipiert, dass es mit Ausfällen der Serverhardware umgehen kann.
 Stacks von Spark und Hadoop[/caption]
Die Speicherebene ist für ein verteiltes Dateisystem verantwortlich, das Daten auf handelsüblichen Rechnern speichert und eine sehr hohe Gesamtbandbreite im gesamten Cluster bietet. Spark verwendet die Hadoop-Schicht. Das bedeutet, dass man HDFS (das Dateisystem von Hadoop) oder andere von der Hadoop-API unterstützte Speichersysteme verwenden kann. Die folgenden Speichersysteme werden von Hadoop unterstützt: Ihr lokales Dateisystem, Amazon S3, Cassandra, Hive und HBase.
Die Computing-Schicht ist das Programmiermodell für die Verarbeitung großer Datenmengen. Hadoop und Spark unterscheiden sich in diesem Bereich erheblich. Hadoop verwendet eine plattenbasierte Lösung, die durch ein Map/Rece-Modell bereitgestellt wird. Bei einer festplattenbasierten Lösung werden die temporären Daten auf der Festplatte gespeichert. Spark verwendet eine speicherbasierte Lösung mit seinem Spark Core. Daher ist Spark viel schneller. Die Unterschiede in ihren Berechnungsmodellen werden im nächsten Kapitel erörtert.
Die Cluster-Manager unterscheiden sich ein wenig von den anderen Komponenten. Sie sind für die Verwaltung der Rechenressourcen und deren Nutzung für die Planung der Anwendungen der Benutzer zuständig. Hadoop verwendet seinen eigenen Clustermanager (YARN). Spark kann über eine Vielzahl von Cluster-Managern laufen, darunter YARN, Apache Mesos und ein einfacher Cluster-Manager namens Standalone Scheduler.
Ein einzigartiges Konzept von Spark sind die High-Level-Pakete. Sie bieten viele Funktionalitäten, die in Hadoop nicht verfügbar sind. Man kann diese Ebene auch als eine Art Abstraktionsebene sehen, durch die Code viel einfacher zu verstehen und zu erstellen ist. Diese Pakete sind
Stacks von Spark und Hadoop[/caption]
Die Speicherebene ist für ein verteiltes Dateisystem verantwortlich, das Daten auf handelsüblichen Rechnern speichert und eine sehr hohe Gesamtbandbreite im gesamten Cluster bietet. Spark verwendet die Hadoop-Schicht. Das bedeutet, dass man HDFS (das Dateisystem von Hadoop) oder andere von der Hadoop-API unterstützte Speichersysteme verwenden kann. Die folgenden Speichersysteme werden von Hadoop unterstützt: Ihr lokales Dateisystem, Amazon S3, Cassandra, Hive und HBase.
Die Computing-Schicht ist das Programmiermodell für die Verarbeitung großer Datenmengen. Hadoop und Spark unterscheiden sich in diesem Bereich erheblich. Hadoop verwendet eine plattenbasierte Lösung, die durch ein Map/Rece-Modell bereitgestellt wird. Bei einer festplattenbasierten Lösung werden die temporären Daten auf der Festplatte gespeichert. Spark verwendet eine speicherbasierte Lösung mit seinem Spark Core. Daher ist Spark viel schneller. Die Unterschiede in ihren Berechnungsmodellen werden im nächsten Kapitel erörtert.
Die Cluster-Manager unterscheiden sich ein wenig von den anderen Komponenten. Sie sind für die Verwaltung der Rechenressourcen und deren Nutzung für die Planung der Anwendungen der Benutzer zuständig. Hadoop verwendet seinen eigenen Clustermanager (YARN). Spark kann über eine Vielzahl von Cluster-Managern laufen, darunter YARN, Apache Mesos und ein einfacher Cluster-Manager namens Standalone Scheduler.
Ein einzigartiges Konzept von Spark sind die High-Level-Pakete. Sie bieten viele Funktionalitäten, die in Hadoop nicht verfügbar sind. Man kann diese Ebene auch als eine Art Abstraktionsebene sehen, durch die Code viel einfacher zu verstehen und zu erstellen ist. Diese Pakete sind
 Hadoop Berechnungsmodell: Map/Reduce[/caption]
Hadoop Berechnungsmodell: Map/Reduce[/caption]
 Spark-Berechnungsmodell: RDD[/caption]
Spark-Berechnungsmodell: RDD[/caption]
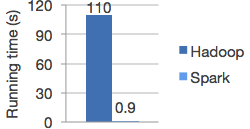 Leistung Hadoop vs. Spark[/caption]
Hinter den Kulissen leistet Spark eine Menge, z.B. die Verteilung der Daten über Ihren Cluster und die Parallelisierung der Operationen. Beachten Sie, dass es sich bei der verteilten Datenverarbeitung um eine speicherbasierte Datenverarbeitung handelt. Die Daten zwischen den Transformationen werden nicht auf der Festplatte gespeichert. Deshalb ist Spark auch so viel schneller.
Leistung Hadoop vs. Spark[/caption]
Hinter den Kulissen leistet Spark eine Menge, z.B. die Verteilung der Daten über Ihren Cluster und die Parallelisierung der Operationen. Beachten Sie, dass es sich bei der verteilten Datenverarbeitung um eine speicherbasierte Datenverarbeitung handelt. Die Daten zwischen den Transformationen werden nicht auf der Festplatte gespeichert. Deshalb ist Spark auch so viel schneller.
Paralleles Rechnen
Zunächst müssen wir die Unterschiede zwischen Hadoop und dem herkömmlichen Ansatz des parallelen Rechnens verstehen, bevor wir die Unterschiede zwischen Hadoop und Spark vergleichen können. [caption id="" align="aligncenter" width="638"]Verteiltes Rechnen[/caption]
Beim parallelen Rechnen haben alle Aufgaben Zugriff auf gemeinsame Daten, um Informationen auszutauschen und ihre Berechnungen durchzuführen. Beim verteilten Rechnen hat jede Aufgabe ihre eigenen Daten. Der Informationsaustausch erfolgt durch die Weitergabe von Daten zwischen den Aufgaben.
Eines der wichtigsten Konzepte des verteilten Rechnens ist die Datenlokalität, die den Netzwerkverkehr reduziert. Aufgrund der Datenlokalität werden die Daten schneller und effizienter verarbeitet. Es gibt kein separates Speichernetzwerk oder Verarbeitungsnetzwerk.
Apache Hadoop bietet ein Ökosystem für verteiltes Rechnen. Einer der größten Vorteile dieses Ansatzes ist, dass er leicht skalierbar ist und man einen Cluster mit handelsüblicher Hardware aufbauen kann. Hadoop ist so konzipiert, dass es mit Ausfällen der Serverhardware umgehen kann.
Stapel
Um die Hauptunterschiede zwischen Spark und Hadoop zu verstehen, müssen wir uns ihre Stacks ansehen. Beide Stacks bestehen aus mehreren Schichten. [caption id="" align="aligncenter" width="522"]Stacks von Spark und Hadoop[/caption]
Die Speicherebene ist für ein verteiltes Dateisystem verantwortlich, das Daten auf handelsüblichen Rechnern speichert und eine sehr hohe Gesamtbandbreite im gesamten Cluster bietet. Spark verwendet die Hadoop-Schicht. Das bedeutet, dass man HDFS (das Dateisystem von Hadoop) oder andere von der Hadoop-API unterstützte Speichersysteme verwenden kann. Die folgenden Speichersysteme werden von Hadoop unterstützt: Ihr lokales Dateisystem, Amazon S3, Cassandra, Hive und HBase.
Die Computing-Schicht ist das Programmiermodell für die Verarbeitung großer Datenmengen. Hadoop und Spark unterscheiden sich in diesem Bereich erheblich. Hadoop verwendet eine plattenbasierte Lösung, die durch ein Map/Rece-Modell bereitgestellt wird. Bei einer festplattenbasierten Lösung werden die temporären Daten auf der Festplatte gespeichert. Spark verwendet eine speicherbasierte Lösung mit seinem Spark Core. Daher ist Spark viel schneller. Die Unterschiede in ihren Berechnungsmodellen werden im nächsten Kapitel erörtert.
Die Cluster-Manager unterscheiden sich ein wenig von den anderen Komponenten. Sie sind für die Verwaltung der Rechenressourcen und deren Nutzung für die Planung der Anwendungen der Benutzer zuständig. Hadoop verwendet seinen eigenen Clustermanager (YARN). Spark kann über eine Vielzahl von Cluster-Managern laufen, darunter YARN, Apache Mesos und ein einfacher Cluster-Manager namens Standalone Scheduler.
Ein einzigartiges Konzept von Spark sind die High-Level-Pakete. Sie bieten viele Funktionalitäten, die in Hadoop nicht verfügbar sind. Man kann diese Ebene auch als eine Art Abstraktionsebene sehen, durch die Code viel einfacher zu verstehen und zu erstellen ist. Diese Pakete sind
- Spark SQL ist das Paket von Spark für die Arbeit mit strukturierten Daten. Es ermöglicht die Abfrage von Daten über SQL.
- Spark Streaming ermöglicht die Verarbeitung von Live-Datenströmen, z. B. von Protokolldateien oder einem Twitter-Feed.
- MLlib ist ein Paket für Funktionen des maschinellen Lernens. Ein praktisches Beispiel für maschinelles Lernen ist die Spam-Filterung.
- GraphX ist eine Bibliothek, die eine API für die Manipulation von Graphen (z.B. sozialen Netzwerken) und die Durchführung von graphparallelen Berechnungen bietet.
Berechnungsmodell
Der Hauptunterschied zwischen Hadoop und Spark ist das Berechnungsmodell. Ein Berechnungsmodell ist der Algorithmus und die Menge der zulässigen Operationen zur Verarbeitung der Daten. Hadoop verwendet das Map/Rece-Verfahren. Ein map/reduce umfasst mehrere Schritte. [caption id="" align="aligncenter" width="596"]Hadoop Berechnungsmodell: Map/Reduce[/caption]
- Diese Daten werden verarbeitet und auf einer Schlüssel/Wert-Basis indiziert. Diese Verarbeitung wird von der Map-Aufgabe übernommen.
- Dann werden die Daten auf der Grundlage der Schlüssel zwischen den Knoten gemischt und sortiert. So dass jeder Knoten alle Werte für einen bestimmten Schlüssel enthält.
- Die Reduzierungsaufgabe führt Berechnungen für alle Werte der Schlüssel durch (z.B. Zählen der Gesamtwerte eines Schlüssels) und schreibt diese auf die Festplatte.
Spark-Berechnungsmodell: RDD[/caption]
- Lesen von Eingabedaten und dadurch Erstellen eines RDD.
- Umwandlung von Daten in neue RDDs (bei jeder Iteration und im Speicher). Jede Umwandlung von Daten führt zu einem neuen RDD. Für die Transformation von RDDs gibt es viele Funktionen, die Sie verwenden können, wie map, flatMap, filter, distinct, sample, union, intersection, subtract, usw. Bei map/reduce steht Ihnen nur die map-Funktion zur Verfügung. (..)
- Aufrufen von Operationen zum Berechnen eines Ergebnisses (Ausgabedaten). Auch hier stehen viele Aktionen zur Verfügung, wie z.B. collect, count, take, top, reduce, fold, usw., anstatt nur reduce mit map/reduce.
Leistung Hadoop vs. Spark[/caption]
Hinter den Kulissen leistet Spark eine Menge, z.B. die Verteilung der Daten über Ihren Cluster und die Parallelisierung der Operationen. Beachten Sie, dass es sich bei der verteilten Datenverarbeitung um eine speicherbasierte Datenverarbeitung handelt. Die Daten zwischen den Transformationen werden nicht auf der Festplatte gespeichert. Deshalb ist Spark auch so viel schneller.
Fazit
Alles in allem ist Spark der nächste Schritt auf dem Gebiet der Big Data-Verarbeitung und hat gegenüber Hadoop mehrere Vorteile. Die Innovation von Spark liegt in seinem Berechnungsmodell. Die größten Vorteile von Spark gegenüber Hadoop sind- Seine In-Memory-Computing-Funktionen, die Geschwindigkeit liefern
- Pakete wie Streaming und maschinelles Lernen
- Einfache Entwicklung - man kann nativ in Scala programmieren
Verfasst von
Jan Toebes
Unsere Ideen
Weitere Blogs



Contact
Let’s discuss how we can support your journey.