Blog
You still don't need a feature store

As a consultant you get to deal with a wide variety of tooling and implementations, not all done right. Once, I spent 6 months refactoring a feature store implementation. This was necessary because both the design choice and implementation were wrong. The implementation was a over-engineered custom Feast implementation using unsupported backend data stores. The engineer that implemented it had left the company by the time I joined. It was my task to either fix the implementation or redesign the solution. This drove to understand the problems feature stores solve, and the different approaches to these problems.
During this investigation I found the best blog on feature stores. Unfortunately, the blog post only focuses on train-serve skew. Feature stores solve more than just train-serve skew. Other content on feature stores is often written by feature store providers. This content focuses on the respective feature store implementation. This blog focuses on the principles of technology and the most important problems a feature store solves. These are the four reasons one would adopt a feature store:
- Prevent repeated feature development work
- Prevent repeated computations
- Fetch features not provided through customer input
- Solve train-serve skew
These are the issues addressed by what we will refer to as the “Offline and Online Feature Store”. This type of feature store is the most advanced and complex implementation. The feature store term has a different meaning in different contexts. This blog post helps you understand what a feature store is, explains when you need one, and shows alternative solutions. Let’s discuss what we mean by the above four issues and how they affect your work before we dive into the solutions.
Issues addressed by feature store
Prevent repeated feature development work
Software engineering best practice tells us “Don’t Repeat Yourself” (DRY). This applies to feature engineering logic as well. Sharing features across teams in an organization reduces the time to production for models. Features developed by one team can be reused by another. This becomes more important when a company scales and runs more machine learning models in production. Computing features differently across models can create issues. It can reduce customer's reliability, fairness, and even violating regulatory constraints. A typical case is when regulatory constraints force you to compute features in a specific way.
Mind, data lineage and discoverability become paramount when collaborating on features. Data lineage clarifies what data sources and transformations create a certain feature. A feature is discoverable if it's easy to find and understand. You may, for example, want to know what values it can take. This blog post will not focus on data lineage nor discoverability. Yet, they’re worth mentioniong as a consequence of collaboration.
Prevent repeated computations
As the number of models grows, they will compute more and more features. This increases the demand for compute and your cost. In a naive setup features are (re-)computed each time you train a new model. The same features may even be computed by many models maintained by different teams. This drives computation costs. This is a common issue, especially when working in cloud environments.
Storing your features in a feature store for later use is a great way to prevent repeated computations. Features are computed in a feature engineering pipeline that writes features to the data store. This lets your teams train models without repeating data preparation steps each time. Computing features with each training run can take hours. This slows down development progress and your ability to iterate on a model. Reusing stored features helps to iterate faster. This increases your model development speed.
This pattern reduces computation cost and reduces time to production for models. The feature store can be shared with other teams across your organization. Teams spend less time on developing and maintaining features. This reduces the time to production for models even further.
Fetch features not provided by the consumer
A feature store can be used to fetch features not provided by the consumer of your model. This implies there is a service consuming your model that provides some, but not all, input features. This is only relevant in online serving scenarios, as explained in this blog post. In online serving scenarios it is common for consumers to provide a subset of features Or, the consumer provides only an identifier (for instance, a customer id or item id) to make a prediction for. The sections below explain this in more detail.
Throughout this blog post, online and offline serving will be mentioned. Please have a look at this blog post on machine learning serving architectures if you do not know the difference.
How your model will receive its features?
Let's say you are a Data Scientist working in a model development environment. You have complete access to all historical data. In this environment you prepare features. You train a model with these features. You deploy the model to production when the trained model promises value. In this example you serve the model online. The model consumers provide the model features as input for the model. The model produces predictions for one or more services. You have two options for inference:
- The consumer computes the features your model requires as input
- The consumer sends raw data and compute features during inference time.
- You use a feature store to fetch features not provided by the consumer
What if a new feature needs to be added?
Below diagram shows an example where multiple services consume a model. Moreover, the consumer computes the features. It becomes harder to add or remove features, because your model is coupled with its consumers.
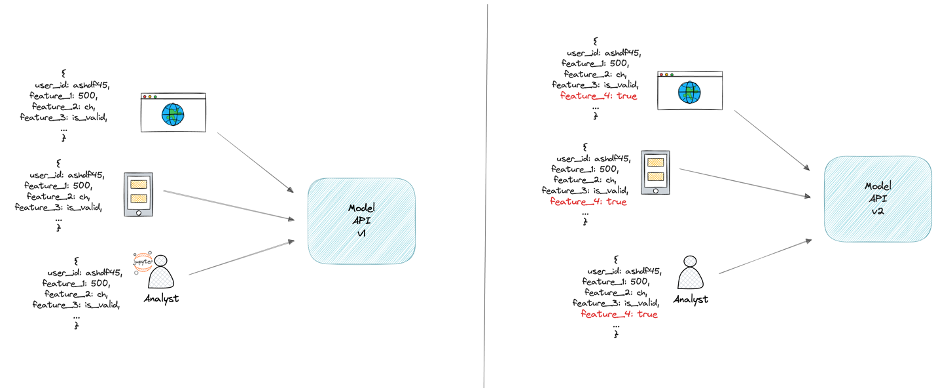
Changing features requires all services consuming your model to adopt this feature. You need to support two versions of your models to guarantee business continuity. Your model is coupled with its consuming applications. This means each change to your model means a change to its consumers. Making changes to your model starts to become a nightmare. Additionally, there’s the risk of train-serve skew. Consumers likely compute features differently than your model did at training time. This results in train-serve skew.
Computing features during inference
The second option suffers from most of the issues of the former. Model and consumers are still tightly coupled. Consumers need to provide all data instead of only features. This makes the interface between model and consumer complex. Consumers need to be updated when a new feature is added that requires new input data. Providing the raw data for a feature reduces the chance on train-serve skew. This pattern introduces new issues for features that require a lot of data to compute. The request can get very big and computing predictions can become slow.
These suboptimal patterns above show the need for the third option; a feature store to fetch data from that is not provided by the consumer. Later in this blog post we will show different ways to implement this.
Solve train-serve skew
Train-serve skew is one of the most prevalent bugs in production machine learning. Train-serve skew occurs if your feature input distribution is different at serving time than at training time. This is often caused by the difference between model training and serving environment. The model training environment is where model development. In this environment you prepare data and features. In the model serving environment your model computes predictions for its consumers.
Applying different data processing logic during training than serving likely results in different feature values provided to the model. Different feature values mean a different feature distribution between training and serving. This means train-serve skew occurs. As a result, your model will perform worse at serving time than at training time. Train-serve skew is most common in online serving.
Train-serve skew example
Let’s look at an example to illustrate how train-serve skew can occur in your machine learning system. Let's take fraud detection as an example. Your fraud detection model may leverage stateful features. A stateful feature is a feature that changes with each event. For instance, a data scientist created a feature to compute the average transaction amount for a credit card in the last 10 minutes. This is illustrated in the image below this paragraph. Each transaction is an event, and the average amount feature changes with each transaction. In an online serving environment this means your model needs the latest view of features. Stateful features need to be updated in real-time fashion as new data arrives.
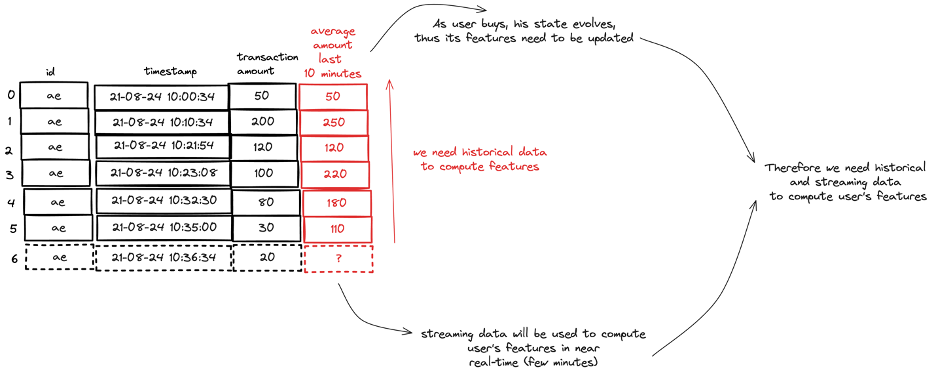
During development we use interactive notebooks and query historical data stored on a data lake or warehouse. We convert this logic to a batch pipelines when moving to production. All data is available, so creating stateful features using window functions is straight forward.
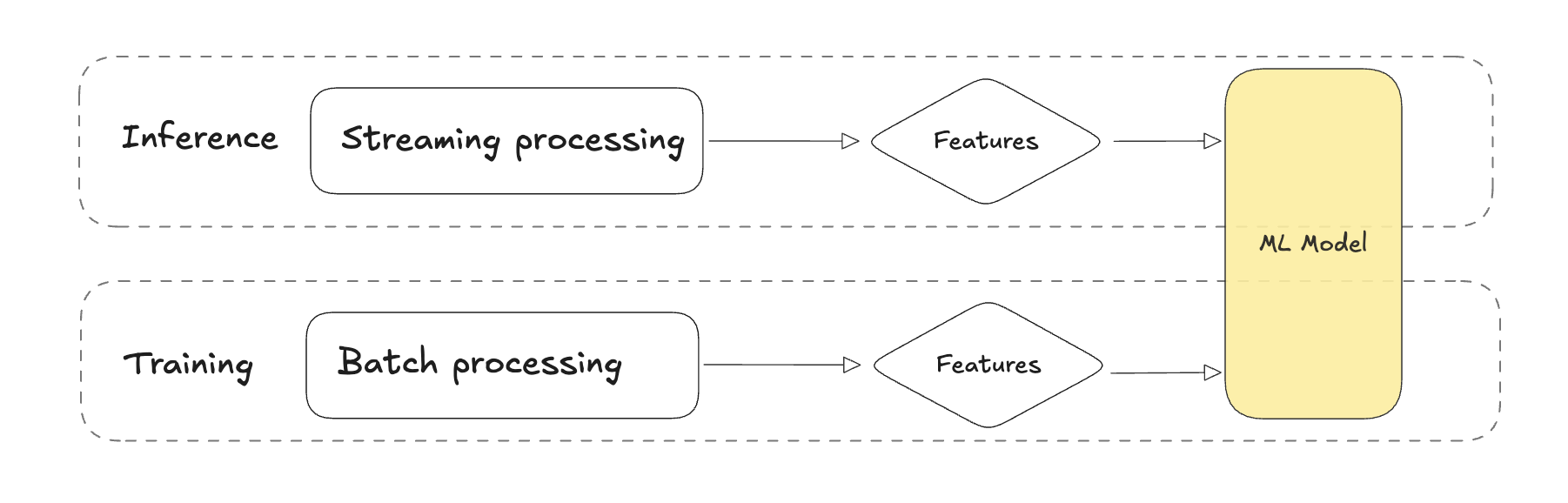
At inference time we serve our models online in a production environment. At inference time the same logic must be applied. It needs to be fast as we want the most recent view of the world with all data up till the point of the new transaction. Your streaming inference pipeline is likely a different application. This application may use different technology than your training pipeline. Technology that is optimized to compute stateful features with fast response times. In summary, if training and serving logic are separated, a change in one of them may lead to train-serve skew. All changes need to be synchronized to prevent this.
Solutions
There are different solutions to each of the challenges described above. Some of the solutions may not be what you would consider a feature store, hence the title of this article. This shows there are alternative solutions that do not require a feature store. The applicability of each of the patterns depends on your model serving architecture. Some of the patterns can be combined. One pattern can cover the other’s shortcomings to better address the challenges a feature store aims to solve. These combinations will be highlighted in the coming sections.
In-model preprocessing
This first solution comes from the blog post referenced in the introduction. The ML Design Patterns book describes it in more detail. The pattern solves train-serve skew by incorporating preprocessing logic within the model code. The same preprocessing logic will be applied during training as in production.
In this case your serialized model will contain the preprocessing logic. The downside of this approach is computing the preprocessing logic on all raw data each time you invoke the model. This results in high computational overhead if you run a lot of experiments on the same dataset. It also increases latency at serving time. Especially, if your model computes aggregate features over a long historical period. Computing the total value of all transactions over the last year is an example of such feature.
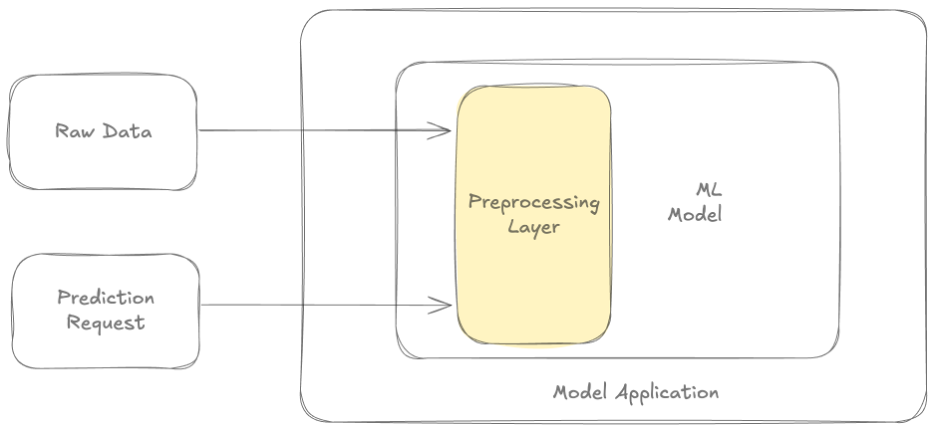 Image adapted from Do you really need a feature store?
Image adapted from Do you really need a feature store?
Solves:
- Train-serve skew
Transform pattern
We can create the preprocessing logic as a separate transformation function. This addresses the computational overhead of the “In-model preprocessing” pattern. The transformation function executes in the training pipeline and during online inference. This promotes using the same logic during training and online inference. Using this pattern reduces the risk of train-serve skew.
Think of the transform function as a function imported from a library. During training we can store the preprocessed data for later use. This avoids recomputing the same preprocessing logic. Most ML frameworks support the transform pattern one way or another. This solution suffers from the same latency drawback as the in-model processing.
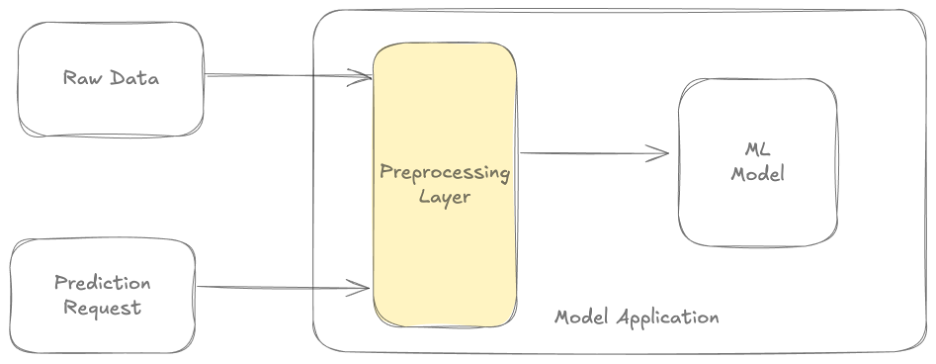 Image adapted from Do you really need a feature store?
Image adapted from Do you really need a feature store?
Solves:
- Train-serve skew
- Prevent duplicating computations
Precomputed features
An important functionality of a feature store is to provide a common API for applications to query features. You can use this pattern when serving your model offline in batch. A pipeline applies feature engineering logic and stores features in a data store. The features in the data store can be used during training and serving.
This pattern is also common when serving a model online. The customer provides part of the input data. The model application will fetch the rest of the feature input data from a data store. This feature data can be shared with teams across the organization. In this section we will assume these pre-computed features are not shared. This helps to scope the discussion. A single ML team computes these features and maintains them in a data store.
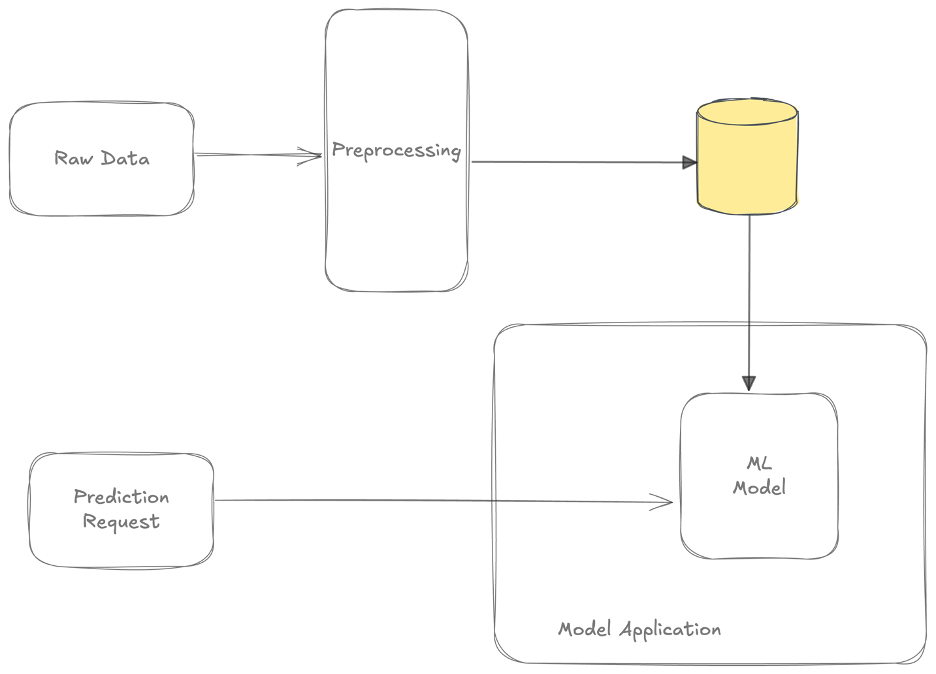
This pattern is commonly applied in combination with models trained in batch. The preprocessing of data is executed periodically in batches. Features are typically written to a key-value data store. Models can fetch features with low latency ideal for online serving. We call these features; batch features. The disadvantage to batch features solution is that your feature data can be stale. Your features will only include data up and to the last time you executed the preprocessing. For many features this is not a problem at all. For example, it’s fine to compute the total sum of all transactions in a day feature once a day. Almost all models that requiring features to be fetched use batch ones.
Solves:
- Prevent duplicating computations
Feature catalog
To prevent repeated development work we do not need to share a data store. Teams can share features definitions to prevent them from reinventing the wheel. This is how a feature catalog promotes collaboration. Have a look at this blog post on streamlining data science workflows.
A feature catalog provides a central place where all feature definitions are defined. A feature catalog is implemented as code and typically maintained in git. The code can be imported by various teams to quickly get started with a new model. Having feature definitions in code enables generating data lineage based. The dependencies between functions show how each feature are created. This makes it immediately clear to every Data Scientist how a feature is computed. Having multiple teams collaborating on the same features will improve quality. It also makes it easier for new data professionals to get started.
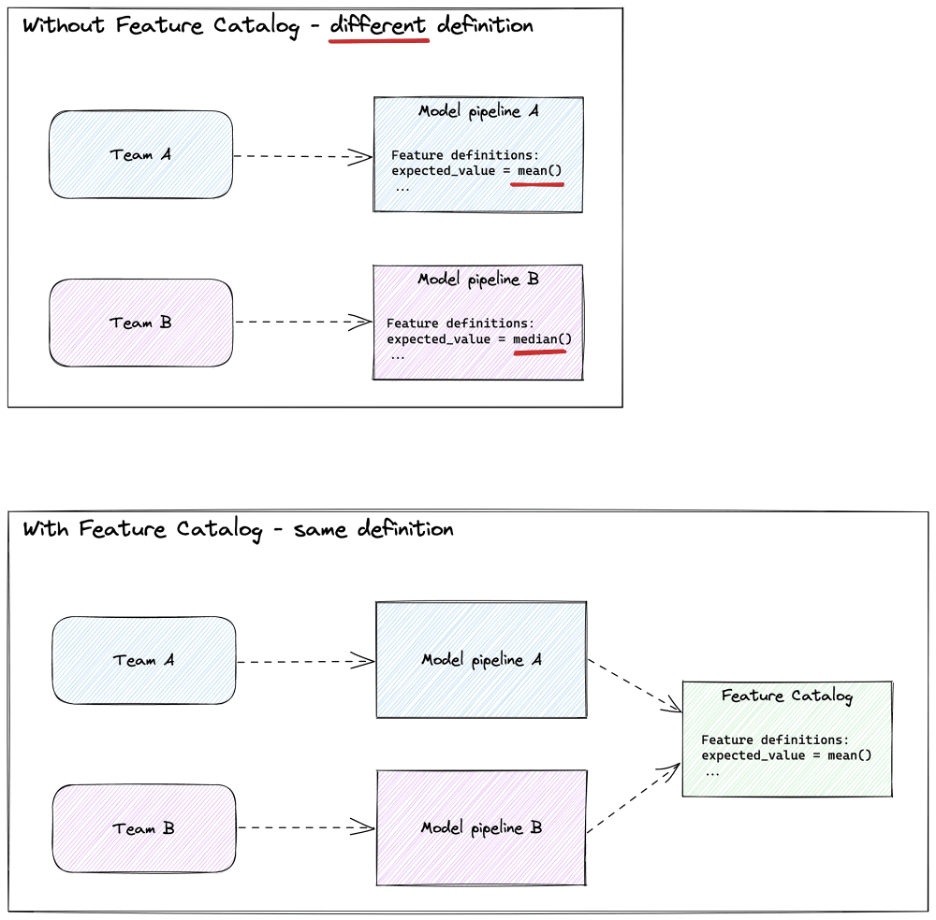
Say, a new data scientist builds a loan credit prediction model. The model automates the process of giving loans to new applicants. The company has another model already in production for fraud detection. This model calculates features based on historical payment behavior. It is likely historical payment behavior will impact applicant's loan status. We can reuse the feature implementation in the new model. This greatly benefits the Data Scientist by speeding up model development.
The advantage of using a feature catalog is loose coupling between teams. Yet, we still promote reuse. Teams share a dependency on code-level. It is simple to implement migration strategies in case of a breaking change in feature logic. Each team can upgrade the feature catalog version at their own pace.
This pattern is commonly used when serving models offline in batch. Although, in online models can use a feature catalog by combining it with the Transform pattern.
Solves:
- Prevent duplicating feature development work
Offline feature store
An offline feature store is a feature registry where all features are stored. It will work as a shared data store. You can explore feature definitions, check lineage, and query features. Features can be queried from training and serving environments. Think of it as a data warehouse for your features. Teams can contribute, share and discover features for their use cases. This promotes features reuse across teams within an organization. As the name says, this is an offline store, so it’s not used for online serving scenarios.
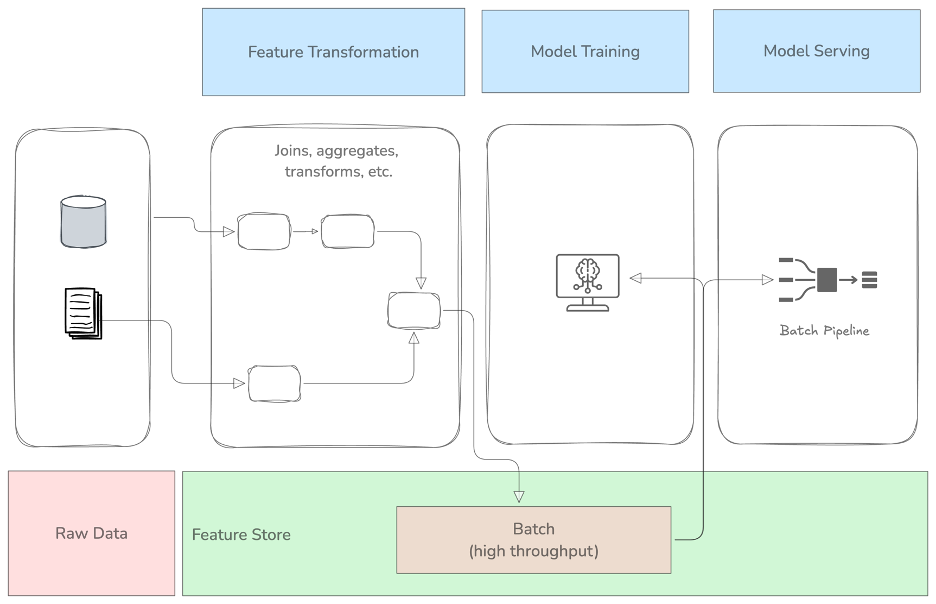 The role of the offline feature store in the machine learning workflow
The role of the offline feature store in the machine learning workflow
The architecture above exemplifies the overall architecture for an offline feature store. It shows how it integrates with tasks in a machine learning workflow starting from raw data to model serving.
An offline feature store simplifies querying features for entities for which we need to compute a prediction. It provides a unified API where you can provide an identifier for an entity, and the feature store will provide the features, as shown below.
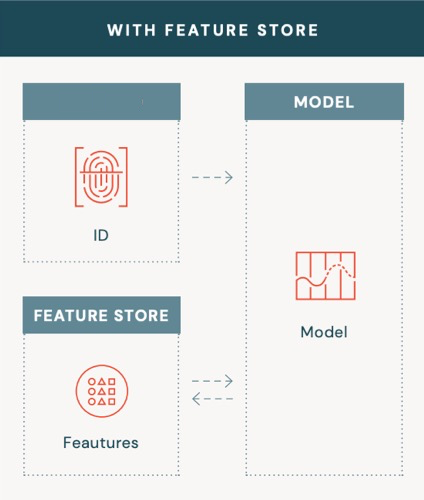
Image from Databricks’ Comprehensive Guide to Feature stores
Organizations implementing this pattern to share features across teams must be aware. Sharing a data source between two models creates a data dependency. Both models need to make a change if one of the models wants to change a feature. Feature versioning helps, yet it still requires additional coordination between teams. Supporting multiple versions of a feature means computing it multiple times. This voids the argument that feature stores prevent repeated computation.
The feature catalog can serve as a precursor to an offline (and/or online) feature store. It provides a simpler way of collaborating. Two teams using the same feature logic have a soft dependency. It is a smaller step to share data if teams collaborate on a code level already. Sharing data creates a harder data dependency and reduces computation cost.
Solves:
- Prevent duplicating feature development work
- Prevent duplicating computations
Offline and online feature store
The offline and online feature store combines the benefits of the offline feature store with the capability to serve online features with low latency. The online feature store is only relevant when serving your model online.
Model can query features
The online feature store addresses the problem when customer features need to be fetched and are not provided by the consumer, or caller. Below image exemplifies this.
 Image from Databricks’ Comprehensive Guide to Feature stores
Image from Databricks’ Comprehensive Guide to Feature stores
This pattern decouples model consumers from the model application. It allows the model and consumers to change independently. With a feature store, the only input requirement is the entity ID being used to fetch those features. Features are precomputed and stored. Adding new features to the machine learning application happens without the consumers needing to know.
The 'online' component of a feature store
Online feature stores often provide a mechanism through which features can be materialized to an online view. This materialization can be executed periodically. Features in the online store will be as stale as the last time the online store materialized. This is fine in many cases, as described earlier in the precomputed features section.
Most online feature stores also provide a means of continuously update the materialized view. This is done by streaming updates. Use cases low latency data are fraud detection, dynamic pricing, and recommender systems. Frequent data updates reduce the staleness of the features in the online features store. It increases the complexity, cost of maintenance, and runtime cost of features. An offline and online feature store is often maintained by a dedicated data platform team specialized in streaming data.
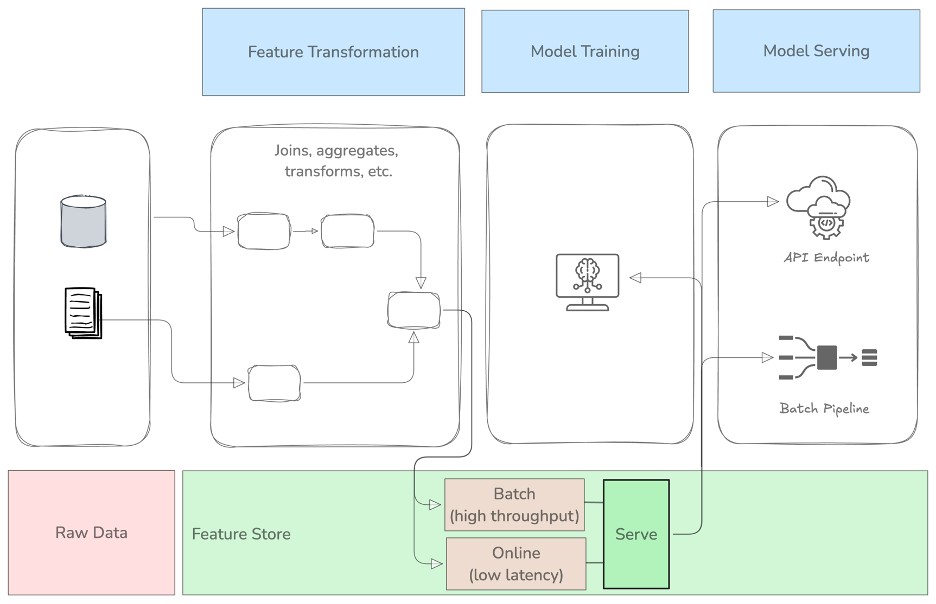 The role of the offline and online feature store in the machine learning workflow
The role of the offline and online feature store in the machine learning workflow
In the above diagram, the offline and online feature store components are combined in a single view. We see that the serve component of our feature store has two different strategies: batch, and online. The batch part contains a database optimized for high throughput. The online part serves features from a database optimized for low latency. The latter is needed for predictions requiring features to be updated and served in (near) real-time.
Solving train-serve skew
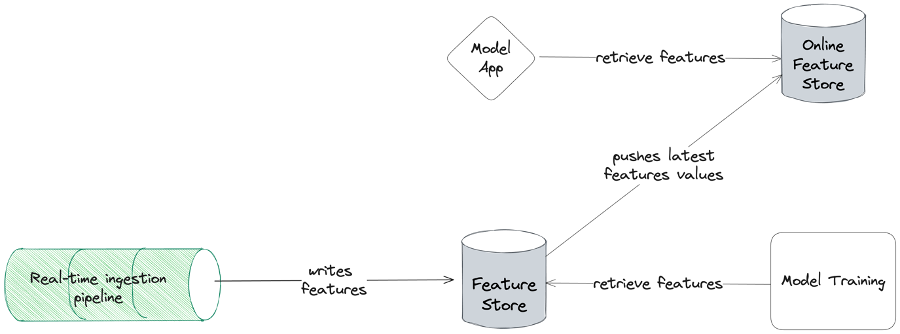
The above diagram shows how an offline and online feature store relates to the training and serving environment. An online feature store is a database optimized for reads where features can be retrieved by model applications. But how exactly is the online feature store solving the train-serve skew? By having a single pipeline writing your features to your feature store. Remember, ensuring features are computed the same way in training and serving environment is a way to prevent train-serve skew.
The goal of an offline and online feature store is to unify the way batch and online features are computed thereby addressing train-serve skew. Train-serve skew can still occur if you use a feature that was computed by two distinct pipelines. Implementing an offline and online feature store is far from straight-forward and requires expert knowledge in the domain of data engineering.
Solves:
- Fetch features that are not provided through customer input
- Prevent duplicating feature development work
- Prevent duplicating computations
- Train-serve skew
Solution space
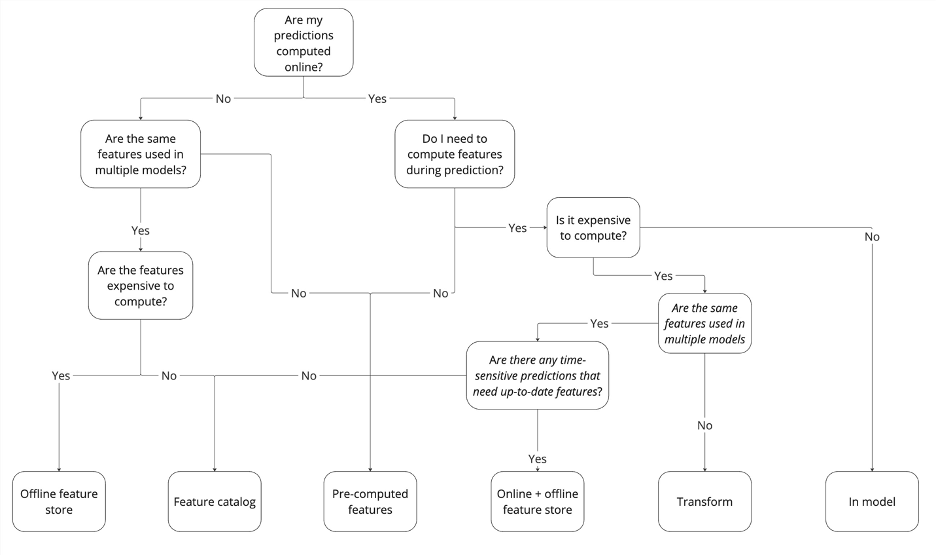
We explored six patterns that address the four reasons to adopt a feature store. We have discussed when each of the individual patterns can be applied and their drawbacks. This was put together in the tree chart below to guide your decision making. Deciding which pattern to use is much more nuanced than a simple yes and no. The chart will aid in distinguishing between the patterns thereby easing decision making.
Last words
In this blog post we distilled the essence of what a feature store is by focusing on the common problems it helps you solve. We showed that the feature store term is convoluted. There are different challenges to be accounted for when adopting them. It’s important to focus on the problem you are trying to solve. By doing this you avoid buying into unnecessary complexity introducing tech debt that inevitably has to be paid off. There often are much simpler solutions to a feature store depending on the problem you are trying to solve. This blog post emphasizes the trade-offs in each of the solutions. It is important to understand the problem you are trying to solve and the trade-offs of its possible solution so you can make the right decision.
Banner image at top of page by Tobias Fischer on Unsplash
Written by
Roy van Santen
Our Ideas
Explore More Blogs




Contact