
The Challenges of Custom Model Pipelines in Data Science
Are you tired of dealing with confusion and duplicative work on your data science team?
With the rise of data lakes, more and more teams are relying on custom pipelines for data preprocessing and feature engineering. But this can lead to a major problem: it becomes harder to reuse features or even compare similar features across different teams.
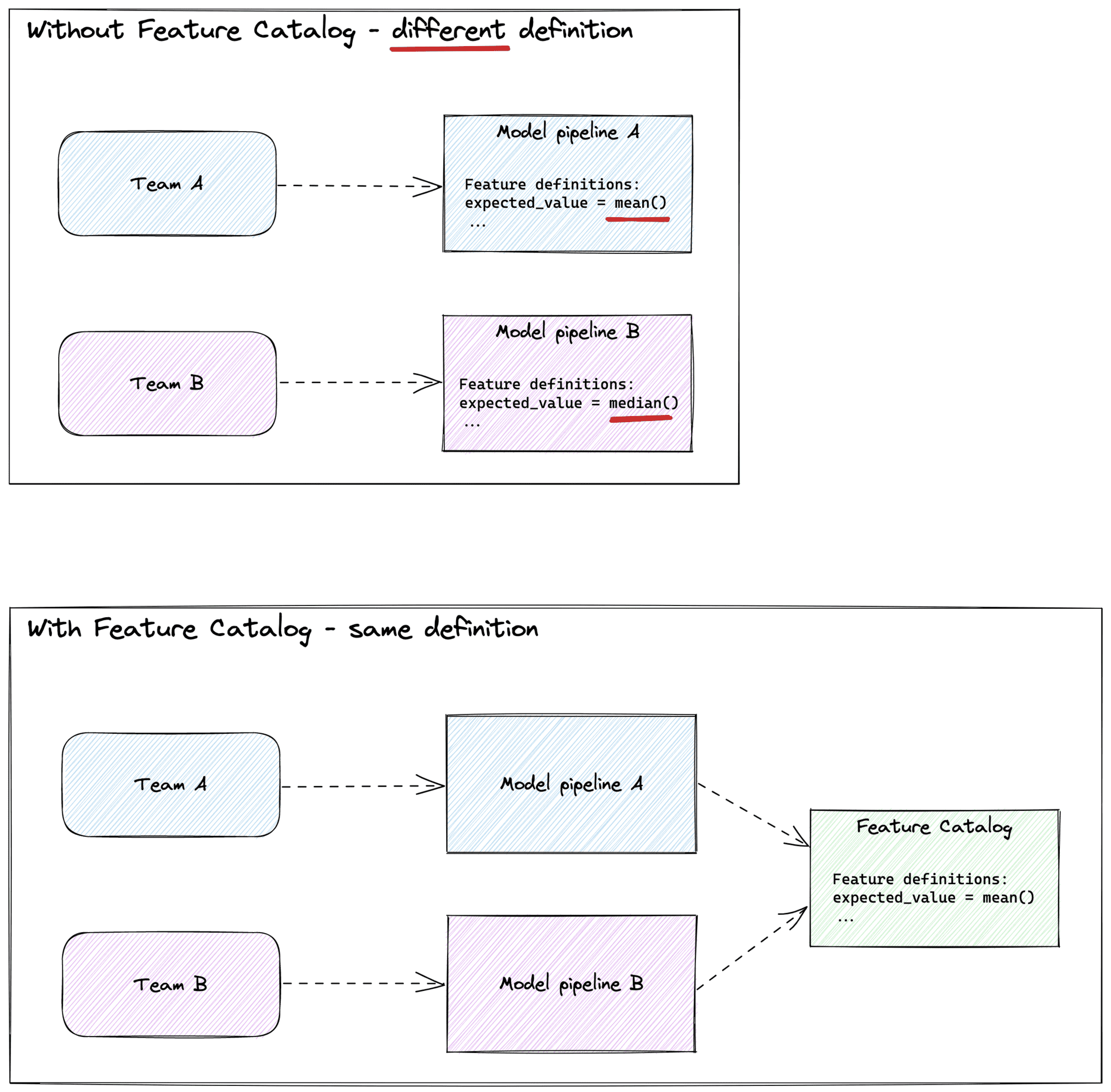
Imagine two teams both reporting an average click-rate to the marketing team, but one team excludes clicks made by robots and the other doesn't. Without realising this difference in interpretation, the marketing team could make some majorly incorrect decisions.
In this blog post, we'll explore ways to overcome these challenges and improve collaboration, consistency and speed within your data science team.
Below a schematic overview of two teams using different definitions and how a Feature Catalog can solve this.
A Feature Catalog: The Solution to Organised and Efficient Feature Computation
A messy and disorganised feature pipeline can be a thing of the past with the use of a Feature Catalog. This catalog offers a centralised location for feature definitions and a user-friendly way to use it; streamlining your process.
I've worked on an implementation of such a Feature Catalog in the form of a Python package. It allowed for easy grouping of similar features and efficient reuse of logic. Plus, it struck a balance between complexity, readability, and speed. As a bonus it was able to automatically generate diagrams to visualise the data dependencies. This is possible if you structure your code and create a simple script (e.g. called in your CI pipeline) which automatically keeps your documentation and diagrams up to date.
The Benefits of a Feature Catalog
A Feature Catalog can help in many ways. It gives you one place where all feature definitions are kept. This helps make sure that how the business sees a feature matches how it's written in code. This also makes it easier for teams to share and reuse feature definitions. It saves time and improves the quality of the features. Plus, it makes it quicker to test new ideas for analytics or machine learning use cases.
A Feature Catalog can make calculating features faster. This is because you can reuse the same logic and intermediate results, instead of having to start from scratch each time. If you structure your code well it will be easier to understand how the data is being used. And it will also make it easier to maintain the code.
A Feature Catalog is different from a Feature Store, but they can both be part of a bigger thing called a Feature Platform. If you want to know more about it, check out this blog post here. In simple terms, a Feature Catalog tells you how to make features and a Feature Store is where the finished features are saved so they can be used quickly.
A Feature Catalog has many benefits, even if you don't have a full Feature Platform. It will make it easier to build a Feature Store later on if you need it. But not every company needs a Feature Store. That's only useful if you use the same features a lot or if you need them right away (i.e. no computation delay). Only then the extra complexity of a Feature Store is worth it.
Kickstart Your Feature Catalog with This Template
If you need to process a lot of data using something like Spark, you can use this template on GitHub to make your own Feature Catalog. It has the following properties:
- Simple to use to get the features you want
- Limited repetition and improved speed by grouping features that need the same
groupbybut perform a different aggregation - Allows for different aggregation levels without duplicating logic/code
- Doesn't use extra steps like caching or temporary tables to make it easier to maintain and let Spark's optimisers work more efficiently
- Lets you (re)use features as a starting point for other features without having to calculate them again
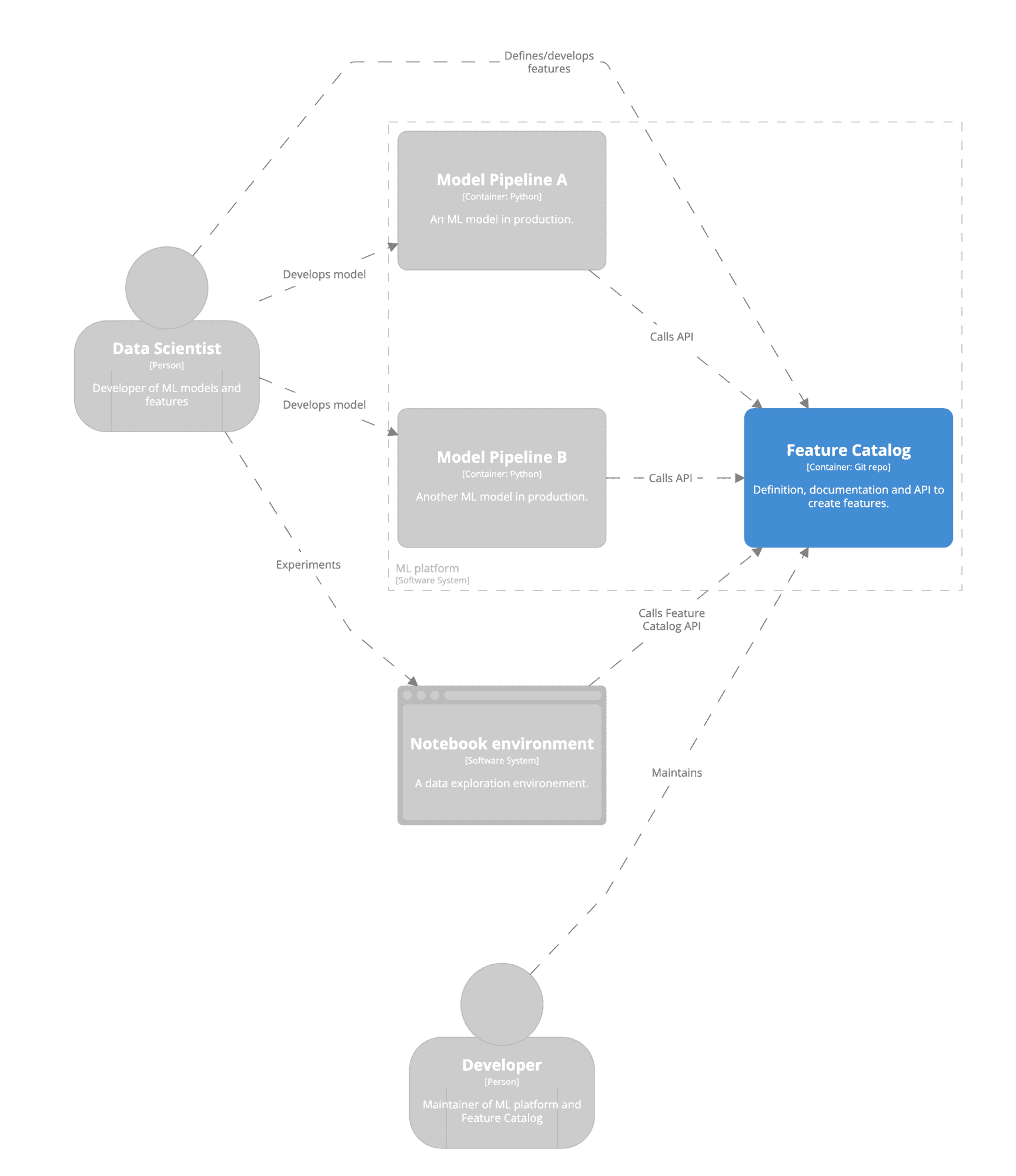
- Includes a C4 architecture design
- Includes a graph that shows dependencies between features, which can be automatically generated from the code
Here is an example of how to create features using this repository (also see the example notebook in the repo). It computes two features, called "darkshore_count" and "total_count", for all avatars present in the data set.
all_avatars = spark.read.parquet("data/wow.parquet").select("avatarId").distinct()
features = compute_features(
spark=spark,
scope=all_avatars,
feature_groups=[
Zone(
features_of_interest=["darkshore_count", "total_count"],
aggregation_level="avatarId"
),
])
> avatarId darkshore_count total_count
> 0 0 76
> 1 0 19
> 2 0 192
Below you see part of the C4 model architecture which is included in the shared template. This gives a schematic overview of how the Feature Catalog can be positioned in your data science workflow.
Feel free to make use of this code and also reach out if you have any questions or ideas for improvements. And of course pull requests are welcomed.
Wrap Up
A Feature Catalog can help data science teams work together better. Using less time on repeating work and make better features that are easy to use and maintain. This without adding the extra complexity of a Feature Store. If you have similar problems, you can use the template to start your own Feature Catalog.
Written by

Roel




Contact