
Building data warehouses and doing analytics is still an unsolved problem at many companies. Luckily, life is getting easier in the current age of ETL ELT. Cloud providers provide scalable databases like Snowflake and BigQuery, there is less work in loading data with tools like Stitch, and there are many BI tools. dbt is an analytics engineering tool and is one of the pieces of this puzzle. This tutorial gives an introduction to dbt with Google BigQuery and shows a basic project.
dbt helps with the transformation phase: it aims to "enable data analysts and engineers to transform data in their warehouses more effectively". In the last years, the gap between data engineers and data analysts has become bigger. Engineers are using more complex tools and write, for instance, data pipelines using Apache Spark in Scala. On the other hand, analysts still prefer SQL and use no-code tooling that don't support engineering best practices like code versioning. dbt closes the gap by extending SQL and providing tooling around data transformation models.
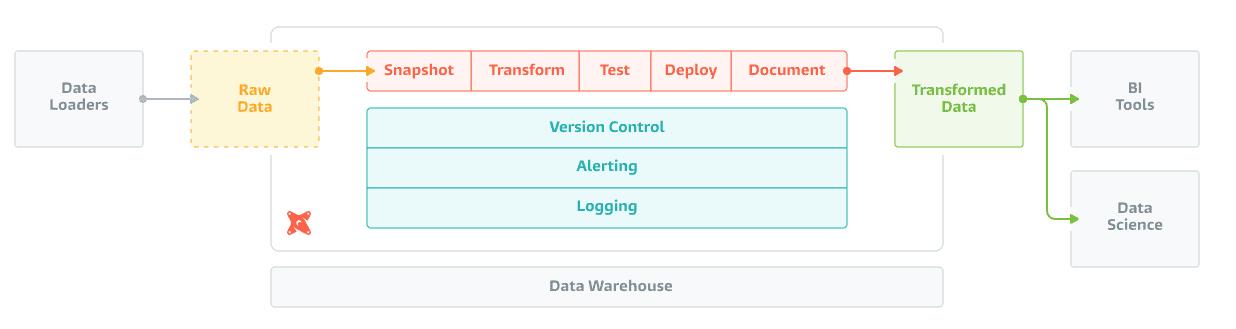
Load data in BigQuery
First, set up the data in the landing zone. Clone the repository and navigate to flights_data/. There are three CSVes with flight data from the U.S. Department of Transportation. One CSV contains flight statistics and the other two map airport IDs and carrier IDs to their names. Create a new project in Google Cloud, make a new bucket in Cloud Storage, and upload the CSVes.
The next step is to load the CSVes as tables in BigQuery. Create a new dataset landing_zone_flights in BigQuery and create tables for each of the files. Schema detection will go fine for airports.csv and flights.csv. For carriers.csv you will have to manually set Code and Description as column names, and set it to skip 1 header row under Advanced Options. Keep on clicking and create two more datasets to the project for our DEV and PRD environment: flights_prd and flights_dev_hg. (Replace hg by your own initials and check the location for both datasets.)
The data and tables have been set up. You should now have three datasets and three tables in landing_zone_flights:
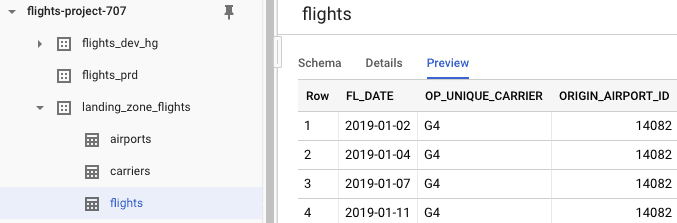
Set up development environment
With your data set up, it is time to set up the development environment. Create a new Python virtual environment with dbt installed via pip or conda. Open your dbt profile located at ~/.dbt/profiles.yml and change it so that it points to your PRD and DEV environments. Check the documentation for profile configuration instructions for BigQuery (don't forget the authorization!).
My profile is flights and my default run target is dev. You will have to change (at least) the project and dataset. Make sure that the location matches the location of your BigQuery datasets.
flights:
outputs:
prd:
type: bigquery
method: oauth
project: flights-project-707
dataset: flights_prd
location: EU # Optional, one of US or EU
dev:
type: bigquery
method: oauth
project: flights-project-707
dataset: flights_dev_hg
location: EU # Optional, one of US or EU
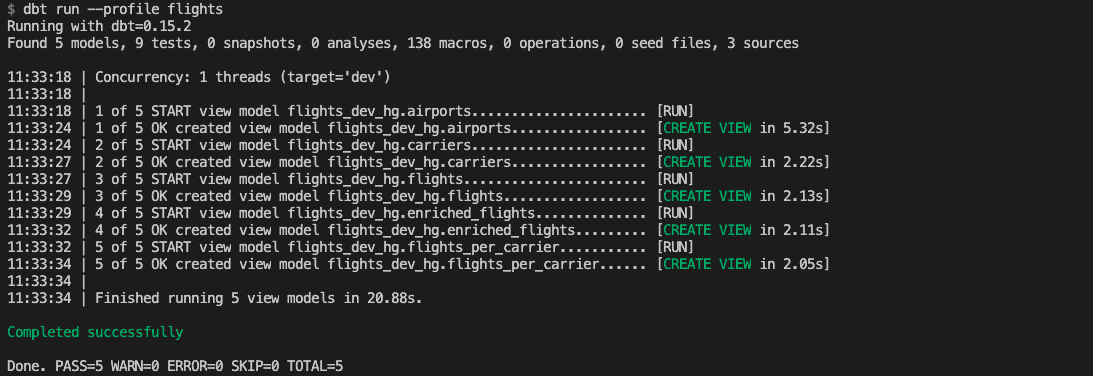
target: devYour environment is now ready to go. Run dbt run --profile flights to populate our data warehouse. This instructs dbt to compile and execute the data models defined in models/. It should complete successfully:
Load and test data sources
The first step of the transformation phase is harmonizing column names and fixing any incorrect types. The extract and load phase were done manually via uploading the data in Cloud Storage and creating the landing zone tables in BigQuery.
Navigate to models/base and inspect the SQL files. The code is fairly straightforward. Each file contains a SELECT statement that loads a table and renames columns if needed. You will also see the first piece of dbt magic: there are Jinja templates in our SQL queries!
Statements like {{ source('landing_zone_flights', 'flights') }} refer to your source tables: the BigQuery tables. These tables are defined in schema.yml that documents and tests your data models. landing_zone_flights is a source with definitions and documentation for the three BigQuery tables. Some columns are also tested for uniqueness, absence of nulls values, and relations within tables. Tests help you make sure that your data model is not only defined, but also correct.
Navigate to flights.sql. This file contains a nice trick to limit the processed data when developing. The if-statement uses a variable to check the statement is run in development or in production. Flights data is limited to 2019-01-03 because you don't need all data during development. This is another example of how dbt uses Jinja so to do things you normally cannot do in SQL.
The source tables are (re)created as views in BigQuery if you run dbt run --profile flights. Similarly, run tests with dbt test --profile flights:
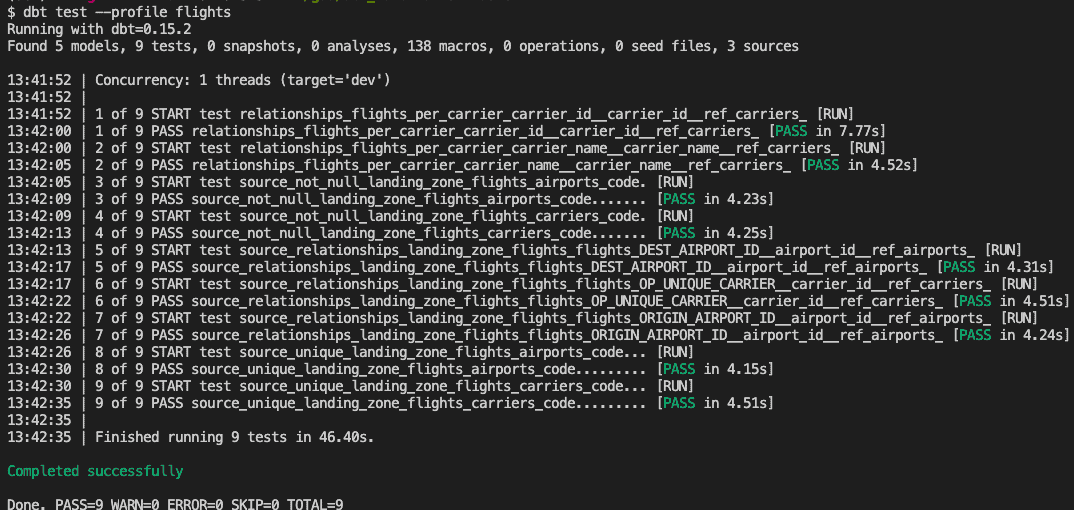
You have now loaded the data in the DEV environment and can validate incoming data. Try populating the PRD environment by changing the --target in the dbt run command. The next step is transforming the data into something interesting!
Transform data
Our queries in models/transform are quite similar to our load queries. The biggest different is that now ref() is used to reference to data models: this is the most important function in dbt. enriched_flights.sql enriches the flights table by combining the sources tables and flights_per_carriers.sql. The schema definition is missing definitions and tests for enriched_flights, not agreeing with the dbt coding conventions -- my bad!
dbt also has a documentation tool to inspect your transformations. Run the following commands to generate and serve the documentation:
$ dbt docs generate --profile flights
$ dbt docs serve --port 8001 --profile flights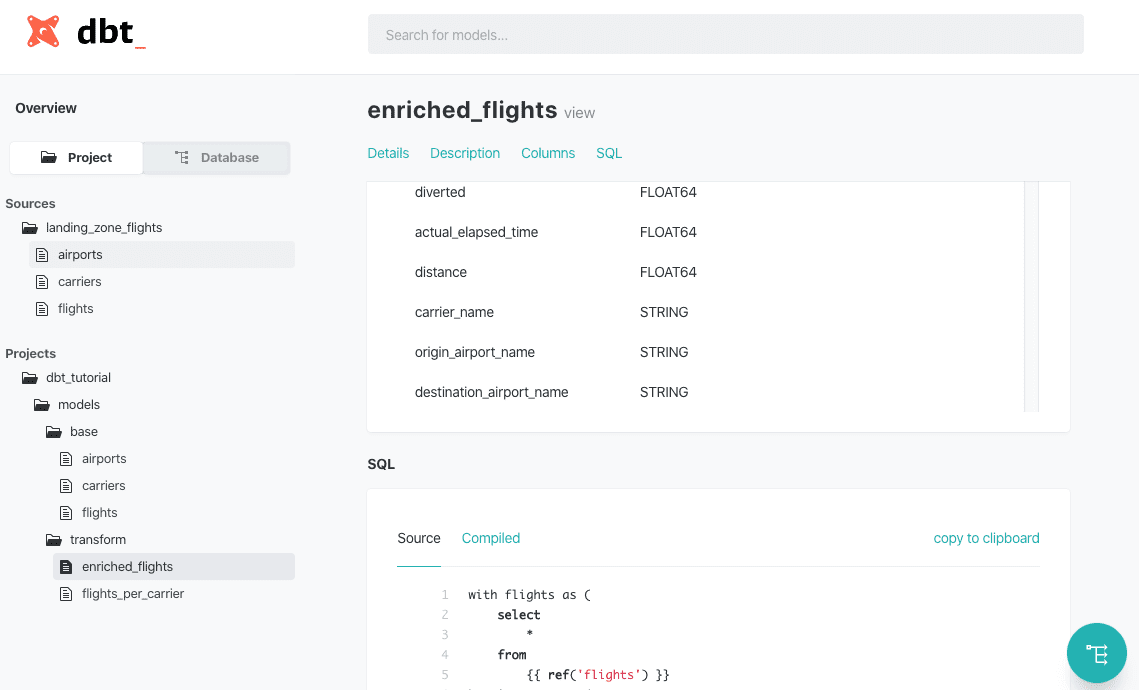
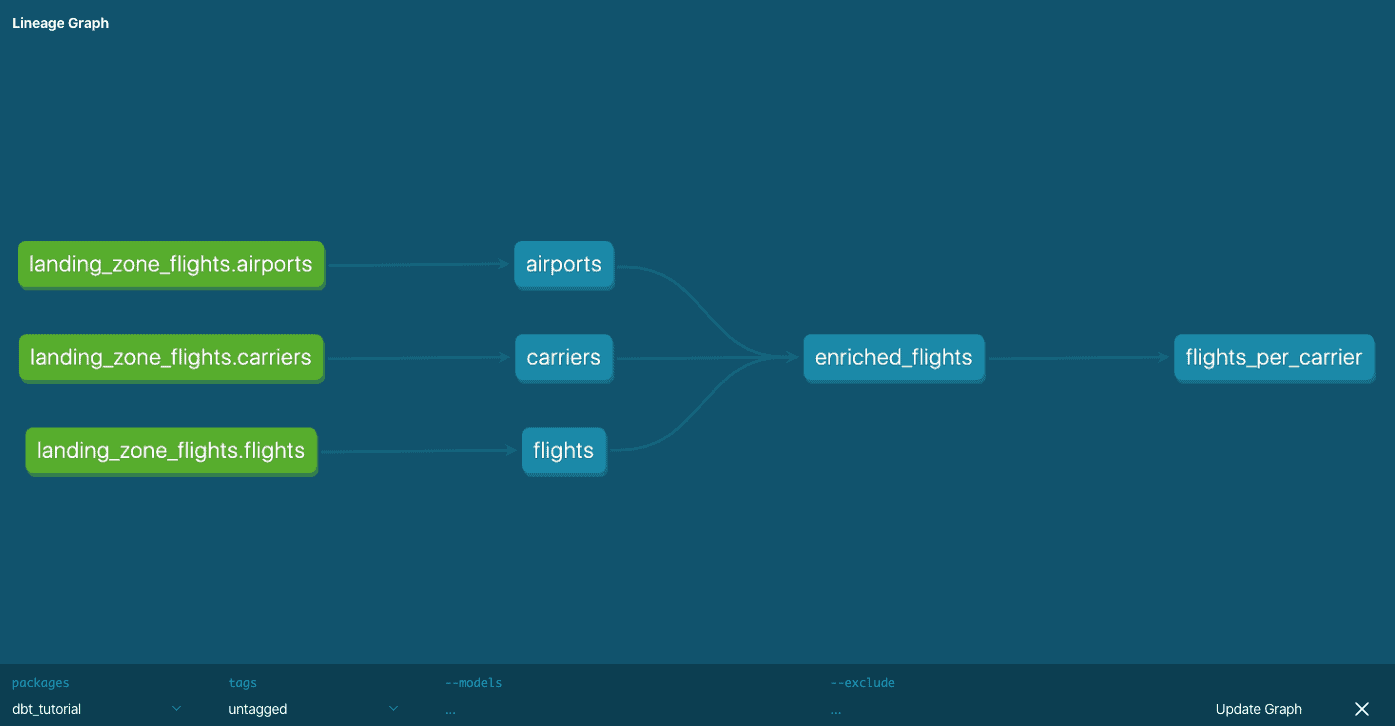
A new browser tab should open with documentation on the project and the resulting database. The project overview shows the sources and models that are defined in the SQL files. This overview gives documentation and column definitions, but also the original SQL queries and the compiled versions. The database overview gives the same results but shows it like a database explorer. All the way in the bottom-right corner you can find the lineage tool, giving an overview of how models or tables related to each other. The documentation is just exported as a static HTML page, so this can be easily shared with the whole organization.
Conclusion
This tutorial showed you the basics of dbt with BigQuery. dbt supports many other databases and technologies like Presto, Microsoft SQL Server and Postgres. Our team has recently extended the Spark functionality (and even our CTO has chimed in). Read the dbt blog for more background, check out how The Telegraph uses it, or go directly to the documentation. You can find the code and data for this tutorial here.
Shout out to Robert rodger and Daniël heres for reviewing this blog!
Do you like dbt, but need to maintain bigger pipelines? ? Join us to find out how Apache Spark can help you accomplish that.
Written by
Henk Griffioen
Our Ideas
Explore More Blogs




Contact