Blog
What is Data Engineering? (Based on a Boring Oil Analogy)

You've probably heard that "data is the new oil" before. That’s a really cool analogy – said somebody in 2006. In 2021, this perspective has become a trope. It's boring and repetitive. Yet… it still depicts what Data Engineering is really well. That’s why in this blog post, we’re going to disappoint – and tell the story of Data Engineering with some gasoline analogies once again.
We’re very sorry in advance.
But if you can stomach this, we promise a comprehensive (yet short) look into Data Engineering – including its definition, use cases, and benefits.
One of the key elements of Data Engineering is the Data Pipeline.
What is Data Engineering?
Let’s start with a general overview. Data Engineering is the central foundation of any advanced data project. Its role is to empower full-fledged data-driven operations in areas like AI, Data Science, or Data Visualization.
According to QuantHub, the key to understanding Data Engineering correctly is the “engineering” element. Engineers design and build things. Similarly, Data Engineers design and build data solutions. These solutions are dedicated to transforming (and transporting) data into a format suitable for further use – usually by Data Scientists.
Real Python adds that Data Engineering aims at providing a consistent and organized data flow. Data Engineering can take different paths to achieve this data flow, however, there is a common pattern: the data pipeline. A data pipeline is a system of programs that do operations on collected information, thus being able to deliver relevant business benefits in the data-driven areas mentioned above.
Yet, Data Engineering is a broad discipline that can have many specific names. In some organizations, it may even not have any. That’s precisely why it’s best to define the specifics of Data Engineering from the perspective of final goals and desired outcomes.
To grasp this perspective and determine what Data Engineering is (and what it isn’t), we’re going to approach the topic like a start-up would – step by step – … and start the gasoline-related examples.
Don’t say we didn’t warn you.
How To Get Started with Data Engineering?
Even if somebody doesn’t know much about data-driven decision making (DDDM), it shouldn’t be difficult to intuitively name some of its components. The main one will be, of course, data. As trivial as it may sound, collecting the right information is always the first (and often tricky) step. Without data, there won’t be any fuel to empower your operations in this department.
But before you start gathering this information, you need to find a useful source.
Now, let’s start off with this analogy – imagine you’re the owner of a new petrol enterprise like BP or Shell. You have funds to start mining some oil-rich lands, but... you don’t know where to find them. So, looking for it is where you need to start.
Identifying Data (Oil?) Sources
To kickstart your oil mining, you will probably need some seismic vibrators. They will generate seismic signals to identify potential oil areas under the earth. That way, you’ll know where to dig.
In the IT world, Data Engineering does something similar – it helps identify potential data sources that are vital to achieving specific business goals. After all, not all the data is useful in a given situation. On the contrary – most will be as useful as desert sand when you’re in need of petroleum*. Relevant data may be tricky to find, just like oil underground.
But once you know where the vital data lies, your Data Engineers can add it to the data pipeline. That way, you will know where to look for useful information.
*Unrelated fun fact: did you know that desert sand is so useless that it isn't even any good for construction purposes? Surprisingly, it's too smooth. As a result, countries like the UAE, which seemingly have limitless supplies of sand, need to import it from elsewhere.
Expanding Data Acquisition
Now, the next step is to access these new data sources with no complications. A custom pipeline is essential for achieving this in an efficient manner. And through more and more new data, Data Engineering will be able to deliver even more output.
More data will be able to reveal the larger picture of your operations. As a result, the 1st and 2nd steps are somewhat of a repeating cycle; with new data, a new need to add it to the pipeline will arise.
From the perspective of our fuel analogy, you now have found your oil underground, and it’s time to start mining; data engineering serves as your pumpjack on an oil well. And when you find new oil sources, you will have to do the same in the new location.
Transforming and Formatting Data
When you already have your data, it would be a great idea to make use of it. Unfortunately, raw data is nearly impossible to analyze – especially when it comes from multiple different sources. Approaching this data manually is out of the question; there's usually too much of it for a person to process. Luckily, Data Engineering can help – by configuring a unique ELT (extract, load, and transform) or ETL (extract, transform and load) pipeline, it’s possible to automate the entire process and produce a comprehensible, sensible output. That way, the data will be able to deliver the benefits it was supposed to.
You will observe a similar process in our oil analogy. Right after mining, the oil won’t be very useful – it will have to be processed in an oil refinery, which will deliver usable products – like gasoline or diesel fuel.
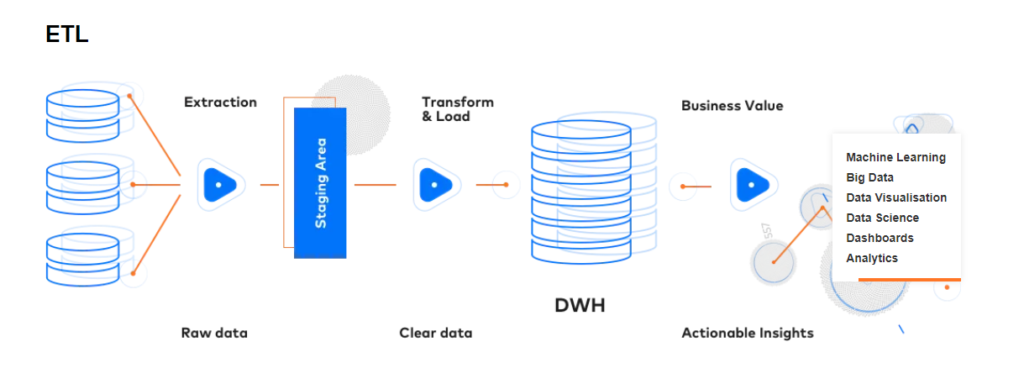
That's how an ETL Data Pipeline looks like.
Storing Data
Now, finally, all data must be stored somewhere. With growing volumes of historical data, data warehouses and lakes are vital for easily accessing data from your analytics solutions. Paired with the Cloud, providing a storage solution that’s both accessible and cost-optimized is crucial. Needless to say, without Data Engineering, it wouldn’t be possible.
And at this point, we won’t waste your time with a trivial petroleum example, so we’ll just say – gasoline also needs to be stored somewhere.
Data Engineering Software
Clearly, none of the data engineering responsibilities we’ve mentioned in this article could be possible without the right tooling.
The internet is filled with hundreds (thousands?) of data engineering technologies and tools. So much so, that someone even created a website – Is it Pokémon or Big Data? But joking aside, the world of data engineering software is indeed incredibly diversified. The mentioned big data alone has a mind-blowing number of dedicated tools (and the most popular ones are developed by just one company/foundation).
As a result, if you’re just beginning your data engineering journey, it might be difficult to pick the optimal tooling. To help you navigate through this technical maze, our data expert set up a list of the most useful (and popular) data engineering tools and technologies. Make sure to read our last article about it to learn more.
What is the Value of Data Engineering?
So, as you can tell, the general goal of data engineering is to create a consistent data pipeline from different data sources. Most companies produce vast amounts of raw data, but it often lacks consistency in structure and formatting; data engineering aims at overcoming this challenge.
In short, the overarching goal of data engineering is to deliver an organized, consistent data flow that will enable data-driven operations. These operations include, for example:
- training Machine Learning (ML) models,
- performing exploratory data analysis,
- populating fields in an application with outside data.
These fields can deliver multiple benefits in many industries – and Data Engineering makes it possible.
But Why is Data Important Anyway?
You would probably expect such a paragraph at the very beginning of this article. However, we didn’t want to bore you to death in case you’ve already heard about this topic a hundred times.
Yet, if you didn’t: to summarize, in today’s landscape data is a key enabler for nearly all operations in the digital world. Data helps to make better decisions and solve problems. Thus, you don’t have to rely (that much) on your gut feeling anymore.
Sure, business intuition helps; even the best information won’t solve all of your issues. However, it can become a key enabler and signpost. For example, it can find you new customers, increase their retention, boost marketing, or even predict sales trends. Moreover, good information also helps to understand processes and track key performance indicators (KPI), which is immensely useful if you’re offering any kind of digital service.
So, regarding our petroleum jokes from before, it’s no surprise that data experts (and everyone else) say that data is the new oil. In truth, although repetitive, this analogy perfectly depicts the mechanism – information fuels modern businesses.
Written by
Xebia Author




Contact