Blog
Through the Looking Glass: Exploring the Wonderland of Testing AI Systems

Artificial Intelligence (AI) systems are becoming ubiquitous: from self-driving cars to risk assessments to large language models (LLMs). As we depend more on these systems, testing should be a top priority during deployment.
Leaving software untested is like writing a cheque without verifying the amount or recipient; you can do it right the first time, but you'd rather check twice to avoid nasty surprises or even catastrophic results. Take, for example, the code bug that bankrupted Knight Capital Group by making them lose USD 460M in less than an hour. AI systems are even more vulnerable as, besides code, they leverage data and algorithms, so you need to test all the components to avoid whammies.
However, AI is the domain of data scientists, who are not renowned for their test-writing abilities—boring details compared to science. They should be helped to test in multidisciplinary teams, as these systems are built and maintained across departments.
To avoid slowdowns, testers need end-to-end ownership, focusing on where the business need and risk is more acute. This approach ensures precious buy-in. This article explains where to start and what is required to avoid overdosing on chamomile to sleep at night.
Artificial Intelligence (AI) and Machine Learning (ML) systems are becoming ubiquitous: from self-driving cars to risk assessments to large language models (LLMs). As we grow more dependent on these systems, testing should be a top priority for organizations and governments using them. Leaving them unchecked is akin to writing a cheque without validating the amount or recipient. Checking can be annoying, but making a mistake can be fatal.
Dutch parents with dual nationality know this well. An AI system trained by the government to spot childcare benefits fraud ended up discriminating against this parental group. The outcome for the families discriminated against was tragic. Some had to sell their homes and belongings. The Dutch cabinet ended up stepping down amidst the fallout.
Tests prevent surprises
To avoid surprises, AI systems should be tested by feeding them real-world-like data.
When a new system version is ready, the tests ensure it still functions correctly. And testing software is essential for governments and businesses alike. In 2012, Knight Capital Group lost USD 460M (EUR 360M at the time) due to a mistake in its trading software. With no one able to spot the error, chaos quickly ensued: within one hour, the company went bankrupt. Today, all that is left is a Wikipedia entry, hardly the legacy for a group with an income of hundreds of millions of dollars. It has now become a prime example of why to test software.
Why, then, isn't the practice more widespread?
AI systems are knottier than software alone; they contain data, code, and algorithms. The algorithm is a mathematical procedure that describes how to go from data to output. For example, to know how much taxes we owe, the tax office applies an algorithm to convert our gross income into a lesser version of itself (the net income). The gap, how much we owe, is the algorithm's output. The code is the algorithm's translation into orders that a computer can understand and perform. In machine learning, there is another ingredient: algorithms are tweaked based on the patterns in the data. For example, if the patterns are biased, the outcome will also be biased—as in the Dutch childcare benefits fraud case.
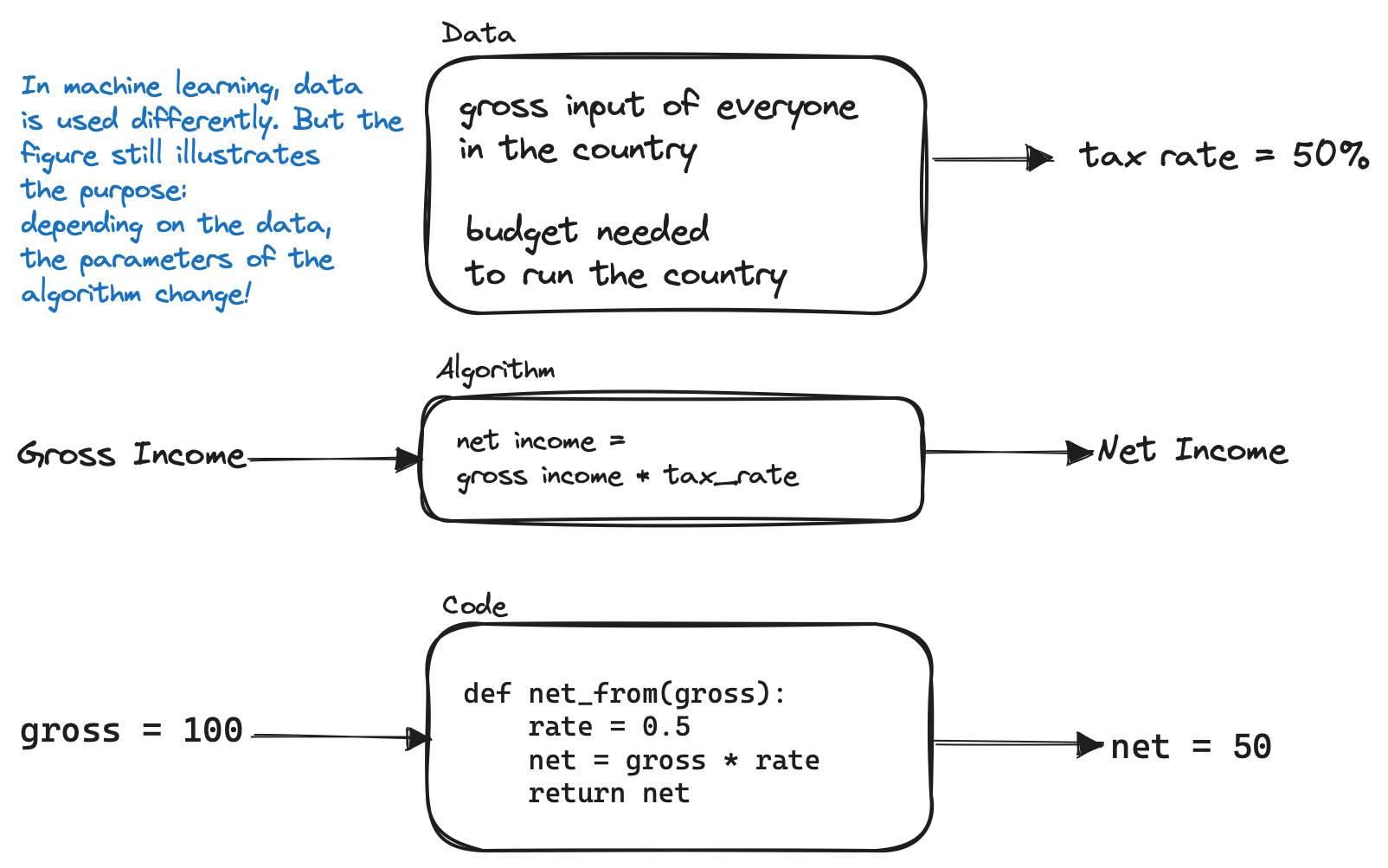
Test the data, code, and algorithm.
All three components—data, code, and algorithm—need to be tested to ensure the system properly works.
Let's start with data. Among the things that could go wrong, we have:
- Bias in the data — as a lack of representation for a minority group.
- We might interpret variables wrongly — is the "Amount" in USD or EUR?
- The underlying data might drift -- maybe a competitor enters the market, destroying the sales forecast accuracy. Catching these performance drifts early is underrated.
On the code side, we could have bugs that could be as simple as switching revenue and costs when computing the profit.
And on the algorithm side, common issues include:
- Using an algorithm unfit for the data. Statistical properties of the data, such as the average and median, might exclude some algorithm classes.
- Forgetting to explore if different parameters improve the model performance.
These lists are, unfortunately, not exhaustive. Suresh and Guttag, two researchers at MIT, have recently published a paper that focused on the effect of bias in ML systems. The result was an outline of seven areas of the ML life cycle that are influenced by bias.
For a more technical overview, Sato, Wider, and Windheuser, three ML practitioners working at Thoughtworks and Databricks, have written a comprehensive article about Continuous Delivery of ML applications.
What about LLMs?
The recent interest in LLMs has highlighted that they bring extra challenges to the table since:
- Natural Language Processing is ambiguous, and since LLMs do not understand what we tell them, reproducibility doesn't come out of the box.
- Backward compatibility is not guaranteed; you might need extra work to ensure things don't break in production. For example, if the developers behind the LLM you're leveraging add some checks to refuse to answer a class of questions, your system might break if you don't catch the change early.
Even Microsoft, today the uncontested leader in the space thanks to the partnership with OpenAI, was bitten by unwanted behavior in their Bing AI chatbot shortly after its launch. They learned their lessons, though, and introduced the proper checks and balances—tests!—to ensure new versions wouldn't exhibit the same quirks.
A daunting prospect
The breadth and width of the issue seem daunting, especially when considering the main force behind AI systems: data scientists. Their role recently emerged. As the name suggests, most come from academia, where software tests aren't exactly fashionable, unlike publishing papers. And to successfully publish, the work needs to be better than previous papers. All attention goes, therefore, to the logic and methodology and not to the correctness of the code. Testing becomes an irrelevant nuisance. In the industry, however, the main goal is not performance but the value the model generates. A machine learning model 5% less accurate than the competition is still useful; companies make up for the difference elsewhere. But to avoid surprises, as what happened to Knight Capital Group, tests are needed.
The problem for data scientists with an academic background is exacerbated—as we routinely observe in our practice—by managers who focus on new features and see tests as a hindrance. Add to that a widespread inexperience on how to test well, and a picture where all the stakeholders point their fingers at each other emerges.

And it's not just data scientists that should test.
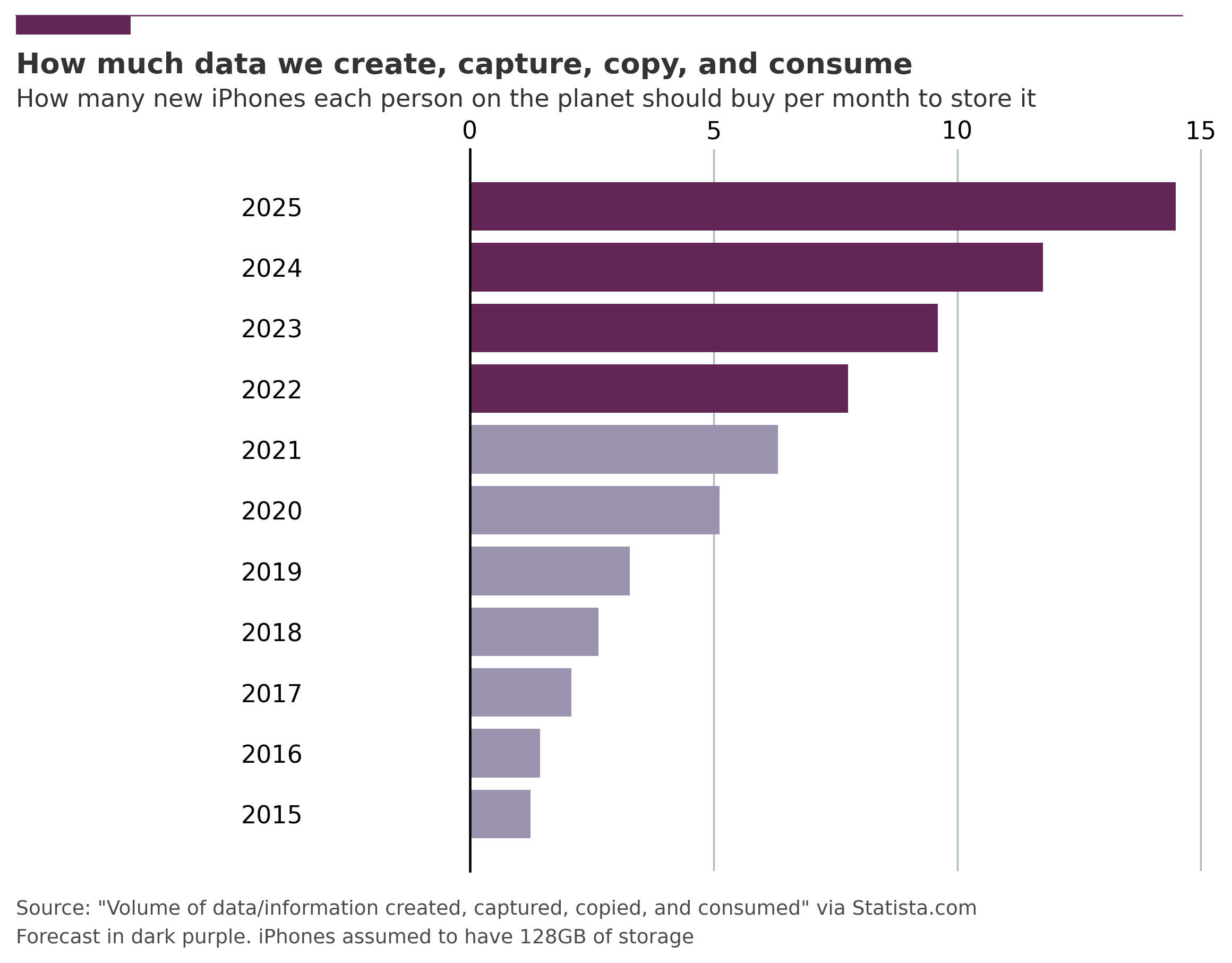
As AI systems span across departments, multiple roles contribute to proper testing: Software and platform engineers for the code and the platform it runs on and data engineers (a particular type of engineer specialized in data-intensive applications) for the data. Unfortunately, these profiles don't always understand each other. If data scientists struggle to grasp why you should test, engineers often fail to realize how ML systems differ from pure software systems and how to deal with them. And everyone should be aware that testing data is a challenge that is only becoming more important, especially considering how much we produce (see Data Volume Forecast figure). Companies are investing in data literacy programs to alleviate the ensuing babel and ensure mutual understanding when talking data & AI.
Testing end-to-end
An AI system usually touches upon multiple components: Data resides in databases, the code and algorithm in central repositories (specialized databases), and the knowledge of the data and processes around it with business stakeholders. And not from a single department: sales data might be used in machine learning models used by the finance department to allocate marketing spending better.
These octopus-like systems, though, are more efficient when a single team tests them end-to-end without external blockers.
To achieve this, internal barriers and the silo mentality should be broken. Cynics will argue that keeping a snowman in the desert from melting is easier, but ignoring the challenge means burying our heads in those desert sands. A top-down approach might prove more practical: if the executives sketch the plan, the organization will break those rigid barriers and be more fluid— hopefully unlike our snowman.
Win the skeptics over
Changing the organization to ensure AI systems are safe seems daunting.
But just like an apprentice is slowly initiated into their craft, companies do not need to change everything at once. They can start where the impact is higher and the risk smaller and iterate. Some components might initially be tested manually or with other departments — at the cost of speed. As the organization's trust increases, take an extra step. Automate a manual process away or increase the ownership of the team. If the AI system is vital for a department, make them your partner. Being open and explaining why testing is necessary (you're free to refer them to this article) will win many skeptics over. Tell them what could go wrong if things go south. And if all else fails, ask them whether they'll be the ones to bankrupt the company because of their stubbornness.
Written by
Giovanni Lanzani




Contact