
Recently, I developed a sudden interest in getting a better picture of the Dutch ecosystem of data related meetups and their attendees. This is mostly inspired by the somewhat sudden appearance of a Big Data, Amsterdam meetup group that managed to receive more than 250 positive RSVPs on the very first event that they organized. What is this new group and how does it compare to existing groups that discuss big data, data science, machine learning, database systems and other data related topics? In this post I will share what I gathered from poking at the Meetup.com API and creating a number of visualizations.
So, we do meetups
People from GoDataDriven have involvement as co-ogranizers in several meetups, including The Amsterdam Applied Machine Learning Meetup Group, the Netherlands Hadoop User Group, Data Donderdag, Graph Database Amsterdam and DataMission. Previously, we were also co-organizing the NoSQL Netherlands Meetup Group, founded in 2010. Other than that, some of our staff are regularly to be found speaking at other events, ranging from Python meetups in Amsterdam to the Hadoop User Group in Stockholm. I think it is safe to say that we have had our fair share of involvement in the meetup communities.
We organize meetups because we care about sharing knowledge both internally and externally and we believe that it is beneficial to the our market as a whole to make knowledge on these subjects more accessible. In an attempt to keep meetups relevant to our intended audience of practitioners and technologists, we tend to be quite strict on what content makes it to the meetup. For example, for the Hadoop User Group, I apply two very simple rules when it comes to speakers:
- If the talk is about a particular technology product or project, the speaker has to be one of the engineers that works on that project (whether open source or otherwise).
- If the talk is about a use case, the speaker has to be one of the people who realized the use case.
This approach basically rules out all technical evangelism and technical sales people from speaking at the meetup. In the past exceptions were made to these rules and feedback was received. We've learned. Content is the one reason our audience attends meetups; free pizza and beer have become a commodity.
We, GoDataDriven as a company, also sponsor meetups by buying pizza and beers. When there is money being paid, there must be a commercial goal as well; we are not a filantropic organisation. Our commercial goal is very simple: we want the community of practitioners of data science, machine learning and builders of distributed big data systems to know about us. We are a services company. This means that the quality and skills of our people are the primary differentiator between us and the competition. We like the best people in the community to know who we are, such that if they ever change jobs, they know that GoDataDriven is well worth considering. If we hire one colleague who got in touch with us through the meetups instead of a recruiter, this easily saves us in excess of 20K Euro. That's a lot of pizza and beer. Because we cannot force these people to come and have pizza and beers with us, we sponsor meetups that get good talks. Do keep in mind that the reason for sponsoring the meetups and the reason for organising the meetups are different ones.
No, everyone is doing meetups
In the past twenty days I have received fifteen announcements from meetup.com telling me about a newly created group in The Netherlands. Two of these were big data or data science related. There are at least 14 data related meetups in The Netherlands that I know of. It appears everyone wants to have their own group. I can see why. Here are four concrete motivations why people start a new meetup group even when a similar group exists:
- Geographical location: Many meetups are Amsterdam focused, yet it is easier to transport one speaker to Rotterdam than 50+ geeks to Amsterdam. Welcome Rotterdam Data Science Meetup!
- Content or topic: All the data meetups were full of code and math, so people more interested in the business and organisational aspects started Data Donderdag (co-organized by Rob Dielemans of GoDataDriven).
- Control: You don't like the topics or speakers that are invited to existing groups or you have problems with the insanely strict rules that a group applies when it comes to getting your talk hosted, then why not start your own? Many software vendors have gone this way (because some groups weren't accepting their sales people to do talks; apologies for that).
- Commercial goals: This is something new and something that I wasn't readily expecting. As I said, there are distinct reasons for organizing a group and reasons for sponsoring a group. Of course, if an existing group is not prepared to accept your sponsorship or not on your terms, you can always start a new group. But it appears there is a new category of groups that are created with the sole intent of attracting sponsorship. That is, create a meetup group, put effort into marketing it and then charge companies to have their speakers appear there. Meetups are now a economy, not just a community.
As it turns out, the new kid on the block, Big Data, Amsterdam, is there because of this fourth reason. The driving force behind the group is a company called Dataconomy, a portal for articles about data related subjects supported by online advertising. The physical manifestation of Dataconomy is apparently the meetup group that attracts a lot of people and subsequently charges companies to have their speakers appear there. There is nothing new to this model. Event organization has long been a viable business (e.g. O'Reilly, InfoQ, etc.); I just wasn't expecting to see this on meetup.com. Or perhaps not so soon.
Mine is bigger than yours
Whenever you hear people name dropping a particular meetup group, the response is pretty much always related to that group's size. This seems important, so let's have a look at the group sizes in our Dutch data meetups ecosystem:
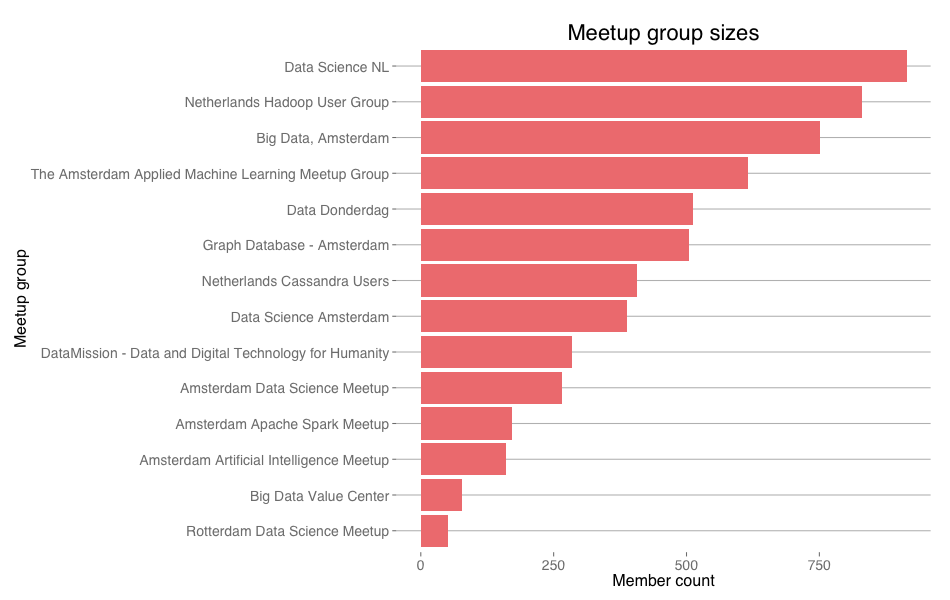
Meetup group sizes per mid March, 2015.
Data Science NL is on top. Not very surprising. It was the earliest data science related group in The Netherlands and all of their events have had high quality content. An important factor when it comes to group size is age:
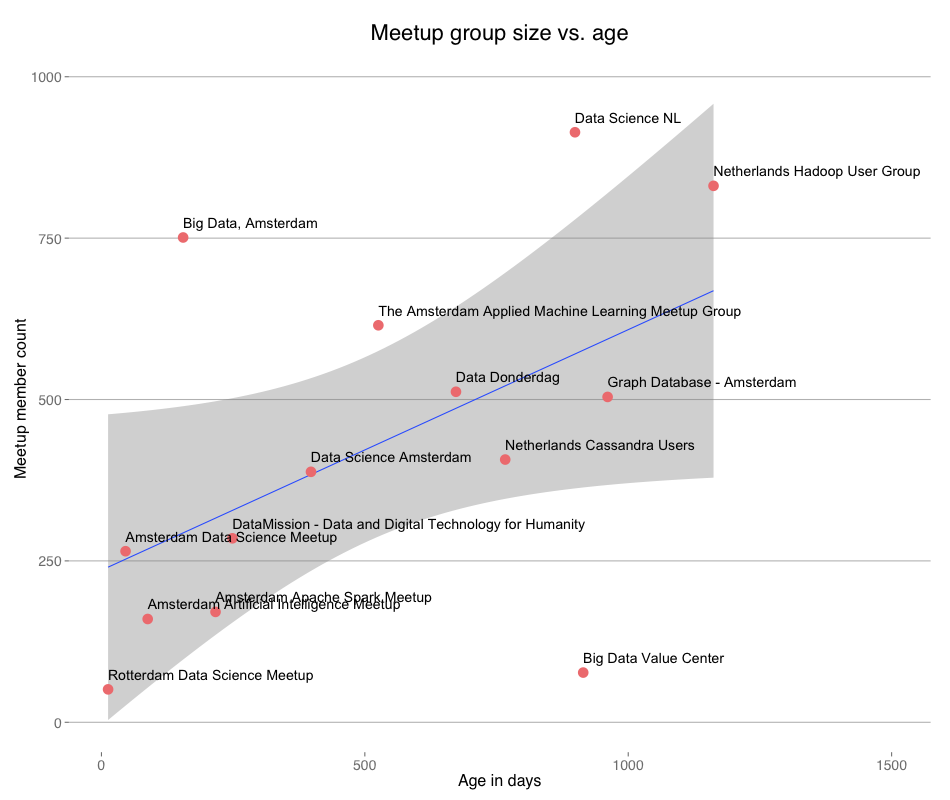
Meetup group sizes vs. age per mid March, 2015. Want a bigger group? Just wait…
Meetup groups more or less organically grow over time. There could be many reasons for this. Word of mouth is one thing, but there is also the recommender system that meetup.com uses to send e-mails to users letting them know about groups they might like and meetup groups usually put some effort into marketing their events themselves. In any case, persistence is key to creating a larger group, unless, of course, your group is Big Data, Amsterdam. It's a clear outlier on the upside. One reason for this could be that there was a big marketing effort behind it. If this was the case, I have completely missed it. Another reason could be that the group attracts a different crowd than the other groups. Posibly a larger one. Then, I might not be the intended audience. Before we go into that, let's look at another important aspect of meetup groups: of all those members, how many are actually attending events?
Size isn't everything
Here we see the number of people that RSVP YES to meetup events per group. Because we know now that groups tend to grow over time, the spread of the distribution can't really be used to compare groups of different ages, which is why the individual events are also plotted. The events are colored according to recency, so we should expect the lighter colored dots on the right side of the plot, unless there was an outlier event of some sort or the group size doesn't really say anything about how many show up for events. For example there is the lighter one near the mean for the Hadoop User Group and the darker colored extreme for the same group, which was probably the meetup that came the night before the Hadoop Summit in Amsterdam.
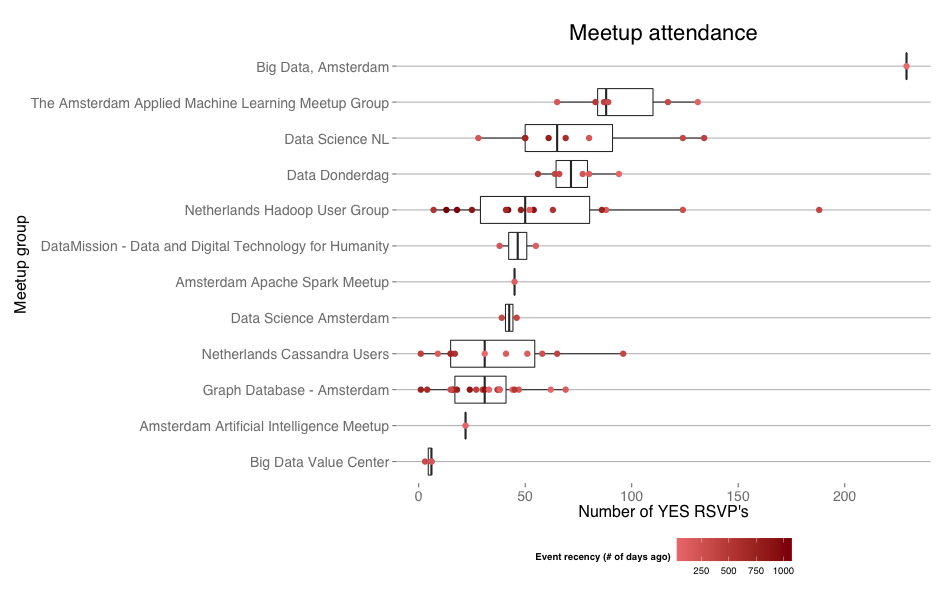
Number of YES RSVPs per mid March, 2015
Looking at the plot above, there is no obvious relation between a group's age / number of members and the size of the actual events. So if new people join all the time, where do they go then? It turns out that most of the people who visit a group's event, will never come back for a second event. Below we see the fraction of one time visitors versus the return visitors. Most people don't stick. Note that the groups in this plot are ordered by age, youngest group on top. Older groups converge to a fraction of about 30%—40% of the people that ever visited coming more than once. Most of the people coming to your meetup will not come a second time. Once more, persistence is key to getting a steady group of return visitors (the usual crowd in your group). Of course for the new groups that have only had one event up until now, we don't know anything about return visitors yet.
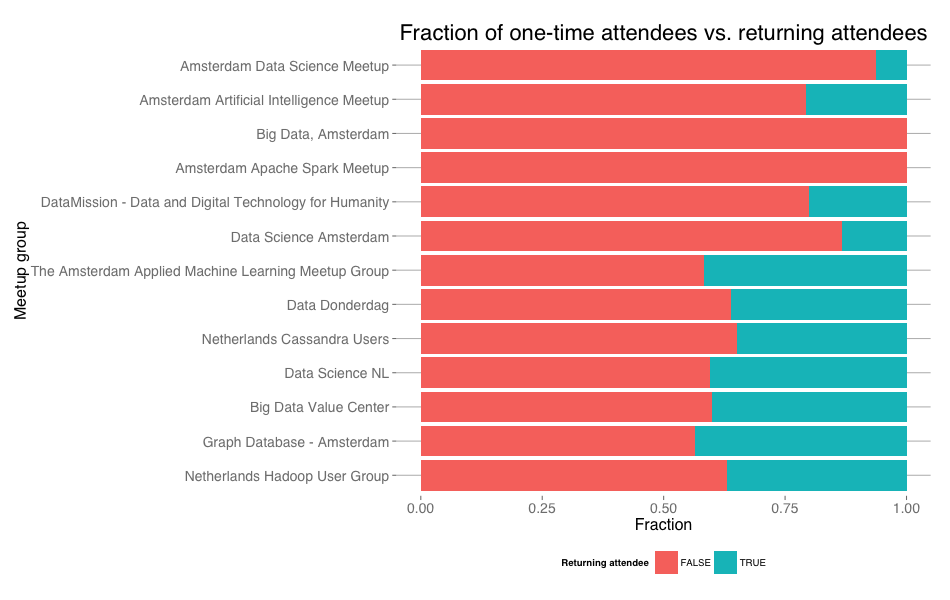
One-timers vs. return visitors. Note the ordering of groups is according to age, youngest group on top.
My kind of people
Here are two representative slides from a presentation given at the Big Data, Amsterdam meetup. Below there are two representative slides from a presentation given at the Amsterdam Applied Machine Learning meetup.
Slides from a talk by Lars Trieloff, source: Automated decision making with big data big data vienna.


Slides from a talk by Thomas Mensink, source: Staff.science.uva.nl/~tmensink/docs/meetup.pdf. (The obvious difference is that at the machine learning group, slides have page numbers.)
It's up to you to choose which of these talks is right for you, but obviously these presentations are targeted at different crowds. This would imply that there are different crowds, even though all the meetups are about data in some sense. If so, how many are there and what do they look like? Below is an attempt to visualize this. This is the network of data related meetups and their members who have RSVPed YES at least once to a meetup (so non-active members are removed). Members are grouped into different communities. The community detection was run on a meta-graph of this graph, which is created by directly connecting two members if they have a meetup group in common; the weight of the relation between two members is determined by how many meetups they have in common and how often they have RSVPed YES for those meetups. This leads to a total of five communities, while there are more than a dozen meetups.

Meetups and their members. Color according to community assignment. Community detection done using igraph's fast greedy method for modularity optimization on the graph of member-member connections created from mutual meetup membership and attendance. Protip: the image is an SVG; if you right click and open in a new tab / window, you can zoom all the way in to get all the details.
The next obvious question: if there are five communities and more than a dozen meetups, how do the communities divide their attention over these different meetups? Here's how. This is once more according to actual meetup attendance, not just membership. Note that the colors in the plot below match the colors of the communities in the graph above.
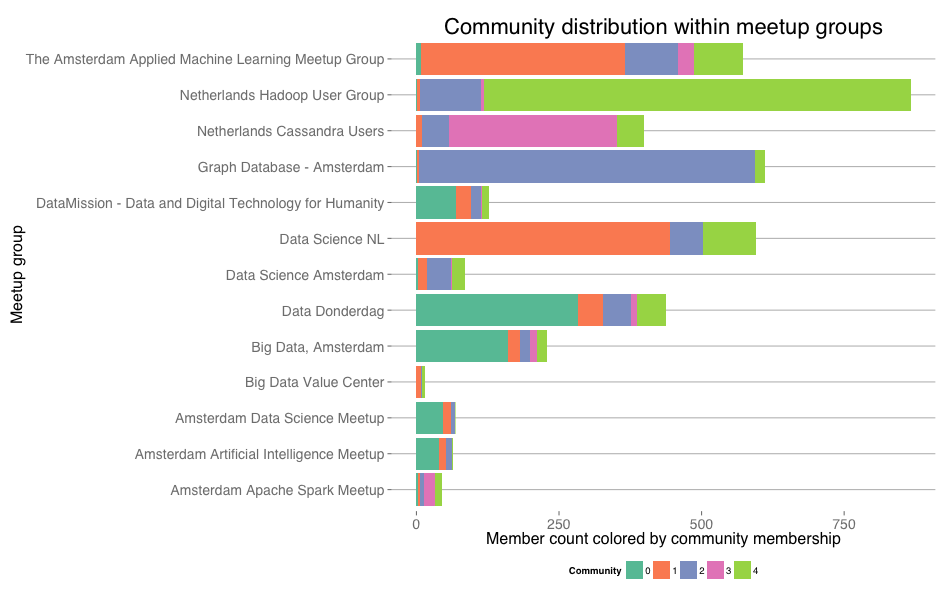
Distribution of members from different communities over meetup groups. Colors match the coloring of communities in the graph visualisation above.
The next next obvious question: how can we describe these communities? We will try to answer that by looking at the different topics that individual members have expressed interest in. On meetup.com, every now and then members are asked which topics interest them (typically when joining a new group). We use the topics selected by members of each community to see which topics discriminate a community from the entire population and use this as a description of the community. For each topic we determine the ratio of likelihood of seeing that topic in the entire population versus seeing that topic within a community. In order to remove outliers and extremely rare topics, we only look at topics that are present at least once in each community. This is not in the least because otherwise, for some reason, 'Swinger Parties' keeps popping up as a highly descriptive topic for one of the communities (I'll leave it as an exercise to the reader to figure out which one). Another approach would have been to discard the bottom n-precentile topics in the entire set, which is arguably more fair, because it doesn't discard topics that are not present in all communities at least once and hence could bring up more descriptive topics for a community. However, it looks like our approach works well enough when qualitatively judging the results, so we stick with it. Here are the top 20 topics for each community (according to likelihood ratio):
Community 0 Positive Thinking — Digital Marketing — Graphic Design — Knowledge Sharing — Inspirational — JQuery — Leadership — Sci-Fi/Fantasy — Cycling — Investing — Business Development — Film — Communication Skills — Water Sports — Geek Culture — Reading — Japanese Culture — Game Night — E-Commerce — Online Marketing
Community 1 Creative Industries — Camping — Literature — Creative Writing — Psychology — Information Technology — IT Professionals — 20's & 30's Social — Philosophy — Collaboration — Writing — Intellectual Discussion — Japanese Language — JavaScript Frameworks — Investing — Artificial Intelligence — Adventure — Self-Empowerment — App developers — Django
Community 2 Neo4j — Graph Databases — Electronic Music — Test Driven Development — Scala Programming — Introduction to Functional Programming in R — System Administration — node.js — Sustainability — Data Center and Operations Automation — Gaming — nodeJS — Makers — Arduino — Django — Software — Musicians — Game Development — Locals & New in Town — New In Town
Community 3 Object Oriented programming — Landscape Photography — Game Development — Game Design — Google Technology User Group — Football — Website Optimization — Agile Coaching — House Music — Java — Android Development — Inspirational — Web Performance — High Scalability Computing — iOS Development — Test Driven Development — Scala — Kanban — JQuery — 3D Printing
Community 4 Indie — Advertising — Small Business Marketing Strategy — Rich Internet Applications — Amazon Web Services — MapReduce — Hadoop — E-Commerce — Foodie — SaaS (Software as a Service) — mongoDB — Internet Professionals — High Performance Computing — High Scalability Computing — NoSQL — Exercise — Bitcoin — Cycling — Freelance — Reading
Because the number of topics is a lot larger than the number of communities, there is a bias toward relatively rare topics (n is small in the tail of the topic distribution), but apart from those the actual topics that are prevalent within a community also surface. For the sake of presentation and reasoning it is usually a good idea to put some qualitative label on these communities. We can do this using the high ranking topics. This makes it easier to reason about conslusions. With your permission, I'd like to propose these community labels:
Community 0: creative business people Community 1: tech savvy intellectuals (with a keen interest in Artificial Intelligence) Community 2: tinkering programmers Community 3: professional programmers Community 4: scalable systems engineers
You can use your own labels if you disagree. Just substitute them in your head while you read on. Also, I have no opinion on whether tinkering is or is not better than professionalism. They are disjoint for the sake of our conclusion.
Conclusion
So, which meetup should I go to? Well, it depends on the kind of people you'd like to meet. Big Data, Amsterdam and Data Donderdag are full of creative business people, while the Hadopo User Group is full of scalable systems engineers and if you want to meet tech savvy intellectuals, go to Data Science NL or The Amsterdam Applied Machine Learning group, etc. Similarly, these communities are helpful in deciding which meetups you should approach with sponsorship offerings and if you are a meetup organizer, this can help you approach sponsors (if your meetup is full of people from community 1 or 4, GoDataDriven might be willing to buy you some pizza and beer!).
With the introduction of for profit events, you have to be aware, just as with online advertising supported websites, that you are the product. This doesn't necessarily mean that the talks will not be interesting. Quite likely to the contrary as retention is a business goal for these events, so they put effort in making sure that speakers are entertaining enough. It mostly means that the talks are going to be biased toward successes of the technology being presented; this is not the same at a user group.
That said, starting yet another meetup group isn't very likely going to create an additional community. At best it will save people some travel time or get that one talk that someone else isn't inviting on a stage somewhere. At worst is will make it harder for people to choose where to go and put some additional stress on meetup.com's recommender system. Free pizza and beer are still a commodity. Nonetheless, it is very likely that there are going to be even more meetup groups, because trends do not often reverse overnight.
As a result of this, we should think of ways to make it easier for people to choose which events to visit. I am working on something for that. If it ever receives enough energy to see the light of day, I will keep you posted… This analysis was part of confirming some of my ideas about the meetup ecosystem and I thought it was interesting enough to share. I hope you enjoyed it.
Goodies
You can download a R notebook with the first plots from here (HTML version). The network community detection is in a Python notebook that you can get here (HTML version).
The notebooks use a Neo4j database which contains the meetup network for the selected groups). The database was created using a custom script consisting of code that I am not particularly proud of, so you'll have to create your own version of that for doing the same. The script uses the Meetup API to gather information from a list of groups that I am a member of. This dataset contains real names of people who didn't give their consent for putting that information on the internet, so I do not provide a downloadable version of the database.
Our Ideas
Explore More Blogs




Contact